GB2312 编码占用的字节数 1 byte 8 bit 1 sh 1 bit 中文字符编码 2. 字符与编码在程序中的实现 变长编码 Unicode UTF-8 转换 在网络上传输 保存到磁盘上 bytes
小结:
1、UNICODE 字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等;
2
服务器->网页 utf-8
文本->内存 unicode
3
python ord-chr作用
def chr(*args, **kwargs): # real signature unknown
""" Return a Unicode string of one character with ordinal i; 0 <= i <= 0x10ffff. """
pass
chr(25991)
ord('文')
def ord(*args, **kwargs): # real signature unknown
""" Return the Unicode code point for a one-character string. """
pass
Unicode整数~字符 互相转换
计算机系统基础(一):程序的表示、转换与链接-模块二 第5讲 非数值数据的编码表示-网易公开课 https://open.163.com/newview/movie/free?pid=WFVPGEQSL&mid=TFVPGF03G


4
ASCII Unicode UTF-8
ASCII编码下,为1字节,8位,256个字符;
Unicode编码下,统一为2字节;
UTF-8编码下,ASCII字符编码同ASCII编码且仍为1字节,中文为3字节,24位;
https://en.wikipedia.org/wiki/Shannon_(unit)
- 1字节(英语:Byte)=8比特(英语:bit)
The shannon (symbol Sh), also known as a bit, is a unit of information and of entropy defined by IEC 80000-13. One shannon is the information content of an event occurring when its probability is one half.[1] It is also the entropy of a system with two equiprobable states. If a message is made of a sequence of bits, with all possible bit strings equally likely, the message's information content expressed in shannons is equal to the number of bits in the sequence.[2] For this and historical reasons, a shannon is more commonly known as a bit, despite that "bit" is also used as a unit of data (or of computer storage, equal to 1/8 of a byte).[3]
The shannon is named after Claude Shannon.
https://en.wikipedia.org/wiki/Bit
Byte History
https://en.wikipedia.org/wiki/Byte
The term byte was coined by Werner Buchholz in July 1956, during the early design phase for the IBM Stretch[7][8] computer, which had addressing to the bit and variable field length (VFL) instructions with a byte size encoded in the instruction. It is a deliberate respelling of bite to avoid accidental mutation to bit.[1]
Early computers used a variety of four-bit binary coded decimal (BCD) representations and the six-bit codes for printable graphic patterns common in the U.S. Army (Fieldata) and Navy. These representations included alphanumeric characters and special graphical symbols. These sets were expanded in 1963 to seven bits of coding, called the American Standard Code for Information Interchange (ASCII) as the Federal Information Processing Standard, which replaced the incompatible teleprinter codes in use by different branches of the U.S. government and universities during the 1960s. ASCII included the distinction of upper- and lowercase alphabets and a set of control characters to facilitate the transmission of written language as well as printing device functions, such as page advance and line feed, and the physical or logical control of data flow over the transmission media. During the early 1960s, while also active in ASCII standardization, IBM simultaneously introduced in its product line of System/360 the eight-bitExtended Binary Coded Decimal Interchange Code (EBCDIC), an expansion of their six-bit binary-coded decimal (BCDIC) representation used in earlier card punches.[9] The prominence of the System/360 led to the ubiquitous adoption of the eight-bit storage size, while in detail the EBCDIC and ASCII encoding schemes are different.
In the early 1960s, AT&T introduced digital telephony first on long-distance trunk lines. These used the eight-bit µ-law encoding. This large investment promised to reduce transmission costs for eight-bit data.
The development of eight-bit microprocessors in the 1970s popularized this storage size. Microprocessors such as the Intel 8008, the direct predecessor of the 8080 and the 8086, used in early personal computers, could also perform a small number of operations on the four-bit pairs in a byte, such as the decimal-add-adjust (DAA) instruction. A four-bit quantity is often called a nibble, also nybble, which is conveniently represented by a single hexadecimal digit.
The term octet is used to unambiguously specify a size of eight bits. It is used extensively in protocol definitions.
Historically, the term octad or octade was used to denote eight bits as well at least in Western Europe;[6][5] however, this usage is no longer common today. The exact origin of the term is unclear, but it can be found in British, Dutch and German sources of the 1960s and 1970s, and throughout the documentation of Philips mainframe computers.
//4-6-7-bit
//Syetem/360 8-bit storage size
http://www.regexlab.com/zh/encoding.htm
1.2 字符,字节,字符串
理解编码的关键,是要把字符的概念和字节的概念理解准确。这两个概念容易混淆,我们在此做一下区分:
| 概念描述 | 举例 | |
| 字符 | 人们使用的记号,抽象意义上的一个符号。 | '1', '中', 'a', '$', '¥', …… |
| 字节 | 计算机中存储数据的单元,一个8位的二进制数,是一个很具体的存储空间。 | 0x01, 0x45, 0xFA, …… |
| ANSI 字符串 | 在内存中,如果“字符”是以 ANSI 编码形式存在的,一个字符可能使用一个字节或多个字节来表示,那么我们称这种字符串为 ANSI 字符串或者多字节字符串。 | "中文123" (占7字节) |
| UNICODE 字符串 | 在内存中,如果“字符”是以在 UNICODE 中的序号存在的,那么我们称这种字符串为UNICODE 字符串或者宽字节字符串。 | L"中文123" (占10字节) |
由于不同 ANSI 编码所规定的标准是不相同的,因此,对于一个给定的多字节字符串,我们必须知道它采用的是哪一种编码规则,才能够知道它包含了哪些“字符”。而对于 UNICODE 字符串来说,不管在什么环境下,它所代表的“字符”内容总是不变的。
1.3 字符集与编码
各个国家和地区所制定的不同 ANSI 编码标准中,都只规定了各自语言所需的“字符”。比如:汉字标准(GB2312)中没有规定韩国语字符怎样存储。这些 ANSI 编码标准所规定的内容包含两层含义:
- 使用哪些字符。也就是说哪些汉字,字母和符号会被收入标准中。所包含“字符”的集合就叫做“字符集”。
- 规定每个“字符”分别用一个字节还是多个字节存储,用哪些字节来存储,这个规定就叫做“编码”。
各个国家和地区在制定编码标准的时候,“字符的集合”和“编码”一般都是同时制定的。因此,平常我们所说的“字符集”,比如:GB2312, GBK, JIS 等,除了有“字符的集合”这层含义外,同时也包含了“编码”的含义。
“UNICODE 字符集”包含了各种语言中使用到的所有“字符”。用来给 UNICODE 字符集编码的标准有很多种,比如:UTF-8, UTF-7, UTF-16, UnicodeLittle, UnicodeBig 等。
1.1 字符与编码的发展
从计算机对多国语言的支持角度看,大致可以分为三个阶段:
| 系统内码 | 说明 | 系统 | |
| 阶段一 | ASCII | 计算机刚开始只支持英语,其它语言不能够在计算机上存储和显示。 | 英文 DOS |
| 阶段二 | ANSI编码 (本地化) | 为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。比如:汉字 '中' 在中文操作系统中,使用 [0xD6,0xD0] 这两个字节存储。 不同的国家和地区制定了不同的标准,由此产生了 GB2312, BIG5, JIS 等各自的编码标准。这些使用 2 个字节来代表一个字符的各种汉字延伸编码方式,称为 ANSI 编码。在简体中文系统下,ANSI 编码代表 GB2312 编码,在日文操作系统下,ANSI 编码代表 JIS 编码。 不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。 |
中文 DOS,中文 Windows 95/98,日文 Windows 95/98 |
| 阶段三 | UNICODE (国际化) | 为了使国际间信息交流更加方便,国际组织制定了 UNICODE 字符集,为各种语言中的每一个字符设定了统一并且唯一的数字编号,以满足跨语言、跨平台进行文本转换、处理的要求。 | Windows NT/2000/XP,Linux,Java |
字符串在内存中的存放方法:
在 ASCII 阶段,单字节字符串使用一个字节存放一个字符(SBCS)。比如,"Bob123" 在内存中为:
| 42 | 6F | 62 | 31 | 32 | 33 | 00 |
| B | o | b | 1 | 2 | 3 | \0 |
在使用 ANSI 编码支持多种语言阶段,每个字符使用一个字节或多个字节来表示(MBCS),因此,这种方式存放的字符也被称作多字节字符。比如,"中文123" 在中文 Windows 95 内存中为7个字节,每个汉字占2个字节,每个英文和数字字符占1个字节:
| D6 | D0 | CE | C4 | 31 | 32 | 33 | 00 |
| 中 | 文 | 1 | 2 | 3 | \0 | ||
在 UNICODE 被采用之后,计算机存放字符串时,改为存放每个字符在 UNICODE 字符集中的序号。目前计算机一般使用 2 个字节(16 位)来存放一个序号(DBCS),因此,这种方式存放的字符也被称作宽字节字符。比如,字符串 "中文123" 在 Windows 2000 下,内存中实际存放的是 5 个序号:
| 2D | 4E | 87 | 65 | 31 | 00 | 32 | 00 | 33 | 00 | 00 | 00 | ← 在 x86 CPU 中,低字节在前 |
| 中 | 文 | 1 | 2 | 3 | \0 | |||||||
一共占 10 个字节。
2. 字符与编码在程序中的实现
2.1 程序中的字符与字节
在 C++ 和 Java 中,用来代表“字符”和“字节”的数据类型,以及进行编码的方法:
| 类型或操作 | C++ | Java |
| 字符 | wchar_t | char |
| 字节 | char | byte |
| ANSI 字符串 | char[] | byte[] |
| UNICODE 字符串 | wchar_t[] | String |
| 字节串→字符串 | mbstowcs(), MultiByteToWideChar() | string = new String(bytes, "encoding") |
| 字符串→字节串 | wcstombs(), WideCharToMultiByte() | bytes = string.getBytes("encoding") |
以上需要注意几点:
- Java 中的 char 代表一个“UNICODE 字符(宽字节字符)”,而 C++ 中的 char 代表一个字节。
- MultiByteToWideChar() 和 WideCharToMultiByte() 是 Windows API 函数。
2.2 C++ 中相关实现方法
声明一段字符串常量:
| // ANSI 字符串,内容长度 7 字节 char sz[20] = "中文123"; // UNICODE 字符串,内容长度 5 个 wchar_t(10 字节) wchar_t wsz[20] = L"\x4E2D\x6587\x0031\x0032\x0033"; |
UNICODE 字符串的 I/O 操作,字符与字节的转换操作:
| // 运行时设定当前 ANSI 编码,VC 格式 setlocale(LC_ALL, ".936"); // GCC 中格式 setlocale(LC_ALL, "zh_CN.GBK"); // Visual C++ 中使用小写 %s,按照 setlocale 指定编码输出到文件 // GCC 中使用大写 %S fwprintf(fp, L"%s\n", wsz); // 把 UNICODE 字符串按照 setlocale 指定的编码转换成字节 wcstombs(sz, wsz, 20); // 把字节串按照 setlocale 指定的编码转换成 UNICODE 字符串 mbstowcs(wsz, sz, 20); |
在 Visual C++ 中,UNICODE 字符串常量有更简单的表示方法。如果源程序的编码与当前默认 ANSI 编码不符,则需要使用 #pragma setlocale,告诉编译器源程序使用的编码:
| // 如果源程序的编码与当前默认 ANSI 编码不一致, // 则需要此行,编译时用来指明当前源程序使用的编码 #pragma setlocale(".936") // UNICODE 字符串常量,内容长度 10 字节 wchar_t wsz[20] = L"中文123"; |
以上需要注意 #pragma setlocale 与 setlocale(LC_ALL, "") 的作用是不同的,#pragma setlocale 在编译时起作用,setlocale() 在运行时起作用。
2.3 Java 中相关实现方法
字符串类 String 中的内容是 UNICODE 字符串:
| // Java 代码,直接写中文 String string = "中文123"; // 得到长度为 5,因为是 5 个字符 System.out.println(string.length()); |
字符串 I/O 操作,字符与字节转换操作。在 Java 包 java.io.* 中,以“Stream”结尾的类一般是用来操作“字节串”的类,以“Reader”,“Writer”结尾的类一般是用来操作“字符串”的类。
| // 字符串与字节串间相互转化 // 按照 GB2312 得到字节(得到多字节字符串) byte [] bytes = string.getBytes("GB2312"); // 从字节按照 GB2312 得到 UNICODE 字符串 string = new String(bytes, "GB2312"); // 要将 String 按照某种编码写入文本文件,有两种方法: // 第一种办法:用 Stream 类写入已经按照指定编码转化好的字节串 OutputStream os = new FileOutputStream("1.txt"); os.write(bytes); os.close(); // 第二种办法:构造指定编码的 Writer 来写入字符串 Writer ow = new OutputStreamWriter(new FileOutputStream("2.txt"), "GB2312"); ow.write(string); ow.close(); /* 最后得到的 1.txt 和 2.txt 都是 7 个字节 */ |
如果 java 的源程序编码与当前默认 ANSI 编码不符,则在编译的时候,需要指明一下源程序的编码。比如:
| E:\>javac -encoding BIG5 Hello.java |
以上需要注意区分源程序的编码与 I/O 操作的编码,前者是在编译时起作用,后者是在运行时起作用。
3. 几种误解,以及乱码产生的原因和解决办法
3.1 容易产生的误解
| 对编码的误解 | |
| 误解一 | 在将“字节串”转化成“UNICODE 字符串”时,比如在读取文本文件时,或者通过网络传输文本时,容易将“字节串”简单地作为单字节字符串,采用每“一个字节”就是“一个字符”的方法进行转化。 而实际上,在非英文的环境中,应该将“字节串”作为 ANSI 字符串,采用适当的编码来得到 UNICODE 字符串,有可能“多个字节”才能得到“一个字符”。 通常,一直在英文环境下做开发的程序员们,容易有这种误解。 |
| 误解二 | 在 DOS,Windows 98 等非 UNICODE 环境下,字符串都是以 ANSI 编码的字节形式存在的。这种以字节形式存在的字符串,必须知道是哪种编码才能被正确地使用。这使我们形成了一个惯性思维:“字符串的编码”。 当 UNICODE 被支持后,Java 中的 String 是以字符的“序号”来存储的,不是以“某种编码的字节”来存储的,因此已经不存在“字符串的编码”这个概念了。只有在“字符串”与“字节串”转化时,或者,将一个“字节串”当成一个 ANSI 字符串时,才有编码的概念。 不少的人都有这个误解。 |
第一种误解,往往是导致乱码产生的原因。第二种误解,往往导致本来容易纠正的乱码问题变得更复杂。
3.2 非 UNICODE 程序在不同语言环境间移植时的乱码
非 UNICODE 程序中的字符串,都是以某种 ANSI 编码形式存在的。如果程序运行时的语言环境与开发时的语言环境不同,将会导致 ANSI 字符串的显示失败。
比如,在日文环境下开发的非 UNICODE 的日文程序界面,拿到中文环境下运行时,界面上将显示乱码。如果这个日文程序界面改为采用 UNICODE 来记录字符串,那么当在中文环境下运行时,界面上将可以显示正常的日文。
由于客观原因,有时候我们必须在中文操作系统下运行非 UNICODE 的日文软件,这时我们可以采用一些工具,比如,南极星,AppLocale 等,暂时的模拟不同的语言环境
3.3 网页提交字符串
当页面中的表单提交字符串时,首先把字符串按照当前页面的编码,转化成字节串。然后再将每个字节转化成 "%XX" 的格式提交到 Web 服务器。比如,一个编码为 GB2312 的页面,提交 "中" 这个字符串时,提交给服务器的内容为 "%D6%D0"。
在服务器端,Web 服务器把收到的 "%D6%D0" 转化成 [0xD6, 0xD0] 两个字节,然后再根据 GB2312 编码规则得到 "中" 字。
在 Tomcat 服务器中,request.getParameter() 得到乱码时,常常是因为前面提到的“误解一”造成的。默认情况下,当提交 "%D6%D0" 给 Tomcat 服务器时,request.getParameter() 将返回 [0x00D6, 0x00D0] 两个 UNICODE 字符,而不是返回一个 "中" 字符。因此,我们需要使用 bytes = string.getBytes("iso-8859-1") 得到原始的字节串,再用 string = new String(bytes, "GB2312") 重新得到正确的字符串 "中"。
3.4 从数据库读取字符串
通过数据库客户端(比如 ODBC 或 JDBC)从数据库服务器中读取字符串时,客户端需要从服务器获知所使用的 ANSI 编码。当数据库服务器发送字节流给客户端时,客户端负责将字节流按照正确的编码转化成 UNICODE 字符串。
如果从数据库读取字符串时得到乱码,而数据库中存放的数据又是正确的,那么往往还是因为前面提到的“误解一”造成的。解决的办法还是通过 string = new String( string.getBytes("iso-8859-1"), "GB2312") 的方法,重新得到原始的字节串,再重新使用正确的编码转化成字符串。
3.5 电子邮件中的字符串
当一段 Text 或者 HTML 通过电子邮件传送时,发送的内容首先通过一种指定的字符编码转化成“字节串”,然后再把“字节串”通过一种指定的传输编码(Content-Transfer-Encoding)进行转化得到另一串“字节串”。比如,打开一封电子邮件源代码,可以看到类似的内容:
| Content-Type: text/plain; charset="gb2312" Content-Transfer-Encoding: base64 sbG+qcrQuqO17cf4yee74bGjz9W7+b3wudzA7dbQ0MQNCg0KvPKzxqO6uqO17cnnsaPW0NDEDQoNCg== |
最常用的 Content-Transfer-Encoding 有 Base64 和 Quoted-Printable 两种。在对二进制文件或者中文文本进行转化时,Base64 得到的“字节串”比 Quoted-Printable 更短。在对英文文本进行转化时,Quoted-Printable 得到的“字节串”比 Base64 更短。
邮件的标题,用了一种更简短的格式来标注“字符编码”和“传输编码”。比如,标题内容为 "中",则在邮件源代码中表示为:
| // 正确的标题格式 Subject: =?GB2312?B?1tA=?= |
其中,
- 第一个“=?”与“?”中间的部分指定了字符编码,在这个例子中指定的是 GB2312。
- “?”与“?”中间的“B”代表 Base64。如果是“Q”则代表 Quoted-Printable。
- 最后“?”与“?=”之间的部分,就是经过 GB2312 转化成字节串,再经过 Base64 转化后的标题内容。
如果“传输编码”改为 Quoted-Printable,同样,如果标题内容为 "中":
| // 正确的标题格式 Subject: =?GB2312?Q?=D6=D0?= |
如果阅读邮件时出现乱码,一般是因为“字符编码”或“传输编码”指定有误,或者是没有指定。比如,有的发邮件组件在发送邮件时,标题 "中":
| // 错误的标题格式 Subject: =?ISO-8859-1?Q?=D6=D0?= |
这样的表示,实际上是明确指明了标题为 [0x00D6, 0x00D0],即 "ÖÐ",而不是 "中"。
4. 几种错误理解的纠正
误解:“ISO-8859-1 是国际编码?”
非也。iso-8859-1 只是单字节字符集中最简单的一种,也就是“字节编号”与“UNICODE 字符编号”一致的那种编码规则。当我们要把一个“字节串”转化成“字符串”,而又不知道它是哪一种 ANSI 编码时,先暂时地把“每一个字节”作为“一个字符”进行转化,不会造成信息丢失。然后再使用 bytes = string.getBytes("iso-8859-1") 的方法可恢复到原始的字节串。
误解:“Java 中,怎样知道某个字符串的内码?”
Java 中,字符串类 java.lang.String 处理的是 UNICODE 字符串,不是 ANSI 字符串。我们只需要把字符串作为“抽象的符号的串”来看待。因此不存在字符串的内码的问题。
字符串和编码 - 廖雪峰的官方网站 https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
在,捋一捋ASCII编码和Unicode编码的区别:ASCII编码是1个字节,而Unicode编码通常是2个字节。
字母A用ASCII编码是十进制的65,二进制的01000001;
字符0用ASCII编码是十进制的48,二进制的00110000,注意字符'0'和整数0是不同的;
汉字中已经超出了ASCII编码的范围,用Unicode编码是十进制的20013,二进制的01001110 00101101。
你可以猜测,如果把ASCII编码的A用Unicode编码,只需要在前面补0就可以,因此,A的Unicode编码是00000000 01000001。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode和UTF-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
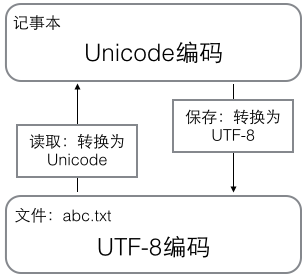
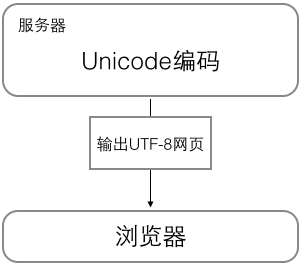
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
Unicode码_百度百科 https://baike.baidu.com/item/Unicode%E7%A0%81/7704811?fr=aladdin
Unicode码扩展自ASCII字元集。在严格的ASCII中,每个字元用7位元表示,或者电脑上普遍使用的每字元有8位元宽;而Unicode使用全16位元字元集。这使得Unicode能够表示世界上所有的书写语言中可能用於电脑通讯的字元、象形文字和其他符号。Unicode最初打算作为ASCII的补充,可能的话,最终将代替它。考虑到ASCII是电脑中最具支配地位的标准,所以这的确是一个很高的目标。
Python的字符串
搞清楚了令人头疼的字符编码问题后,我们再来研究Python的字符串。
在最新的Python 3版本中,字符串是以Unicode编码的,也就是说,Python的字符串支持多语言,例如:
>>> print('包含中文的str')
包含中文的str
对于单个字符的编码,Python提供了ord()函数获取字符的整数表示,chr()函数把编码转换为对应的字符:
>>> ord('A')
65
>>> ord('中')
20013
>>> chr(66)
'B'
>>> chr(25991)
'文'
如果知道字符的整数编码,还可以用十六进制这么写str:
>>> '\u4e2d\u6587'
'中文'
两种写法完全是等价的。
由于Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
Python对bytes类型的数据用带b前缀的单引号或双引号表示:
x = b'ABC'
要注意区分'ABC'和b'ABC',前者是str,后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
以Unicode表示的str通过encode()方法可以编码为指定的bytes,例如:
>>> 'ABC'.encode('ascii')
b'ABC'
>>> '中文'.encode('utf-8')
b'\xe4\xb8\xad\xe6\x96\x87'
>>> '中文'.encode('ascii')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1: ordinal not in range(128)
纯英文的str可以用ASCII编码为bytes,内容是一样的,含有中文的str可以用UTF-8编码为bytes。含有中文的str无法用ASCII编码,因为中文编码的范围超过了ASCII编码的范围,Python会报错。
在bytes中,无法显示为ASCII字符的字节,用\x##显示。
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
>>> b'ABC'.decode('ascii')
'ABC'
>>> b'\xe4\xb8\xad\xe6\x96\x87'.decode('utf-8')
'中文'
如果bytes中包含无法解码的字节,decode()方法会报错:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8')
Traceback (most recent call last):
...
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 3: invalid start byte
如果bytes中只有一小部分无效的字节,可以传入errors='ignore'忽略错误的字节:
>>> b'\xe4\xb8\xad\xff'.decode('utf-8', errors='ignore')
'中'
要计算str包含多少个字符,可以用len()函数:
>>> len('ABC')
3
>>> len('中文')
2
len()函数计算的是str的字符数,如果换成bytes,len()函数就计算字节数:
>>> len(b'ABC')
3
>>> len(b'\xe4\xb8\xad\xe6\x96\x87')
6
>>> len('中文'.encode('utf-8'))
6
可见,1个中文字符经过UTF-8编码后通常会占用3个字节,而1个英文字符只占用1个字节。
在操作字符串时,我们经常遇到str和bytes的互相转换。为了避免乱码问题,应当始终坚持使用UTF-8编码对str和bytes进行转换。
由于Python源代码也是一个文本文件,所以,当你的源代码中包含中文的时候,在保存源代码时,就需要务必指定保存为UTF-8编码。当Python解释器读取源代码时,为了让它按UTF-8编码读取,我们通常在文件开头写上这两行:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
第一行注释是为了告诉Linux/OS X系统,这是一个Python可执行程序,Windows系统会忽略这个注释;
第二行注释是为了告诉Python解释器,按照UTF-8编码读取源代码,否则,你在源代码中写的中文输出可能会有乱码。
申明了UTF-8编码并不意味着你的.py文件就是UTF-8编码的,必须并且要确保文本编辑器正在使用UTF-8 without BOM编码:
如果.py文件本身使用UTF-8编码,并且也申明了# -*- coding: utf-8 -*-,打开命令提示符测试就可以正常显示中文:
程序员必备:彻底弄懂常见的7种中文字符编码 - 知乎 https://zhuanlan.zhihu.com/p/46216008

 浙公网安备 33010602011771号
浙公网安备 33010602011771号