代码复用:DDD视角下的平衡艺术
代码复用:DDD视角下的平衡艺术 https://mp.weixin.qq.com/s/5gIBJByRZfNPbh6yjAvj9w
代码复用:DDD视角下的平衡艺术
这是2024年的第76篇文章
( 本文阅读时间:15分钟 )
01
引言
刚工作时,代码写得不太好,师兄每次 CR 代码,总是会指着屏幕里的一坨代码说 “把它抽成一个类或函数”;“为什么呢?写在一起不是挺好的吗?” 我反问道;师兄老道地回答 “为了方便复用”;我仿佛若有所得,回到工位上把那些很长的代码全部抽象成了类和函数,感觉今天又有所成长。
但是随着工作经验的增加,我对此又产生了困惑。随着业务发展得越来越复杂,我当初写的那个类被大量复用,为了适应不同的场景,里面充满了 if...else...;最能代表复用的业务中台,因为分支太多,发布和开发无比复杂,很小的一个改动却需要拉一堆团队讨论。
所以类和函数的存在究竟是为了什么?只有站在更高的视角才能解决我的困惑,这也是本文的内容。
根据奥卡姆剃刀原则,本文其实用一句话就能概括, 它也是 《复杂软件设计之道》 中我最喜欢的一句话 :类和函数不是为了复用而存在,而是他们本来就 “应该” 在那里。
如果您对这句话已经意会了,可以直接跳到评论区聊一聊看法了。
下文中主要结合历史上各位软件泰斗的观点,分别从成本和效益角度聊聊 “应该” 一词的含义。
02
DRY vs 重复代码:谁更好吗?设计模式的 DRY 原则(Don't Repeat Yourself)让我们尽可能地不要编写重复的代码。
但是在复杂工程中导致的问题就是,DRY 的函数会被大量的地方引用,导致其内部逻辑需要考虑各种情况,逻辑及其复杂,修改风险也极高。
这么看来,DRY 也没有那么好,重复代码反而可以降低后续的修改风险,日后可以根据业务需要再进行灵活整合。
在 《架构整洁之道》中提到,“拖延决策” 也是优秀架构设计的特点之一。因为随着软件的开发和业务的迭代,我们掌握的信息越来越多,后期做出的决策肯定比项目早期的草率决定要靠谱。《复杂软件设计之道》中吐槽道:架构师们总是在只掌握 20% 信息的情况下,就已经做出了 80% 的决策。
大师们的原则常常是相互矛盾的,没有什么绝对的更好或者更坏。下表简要总结了下 DRY 与重复代码各自的优缺点:
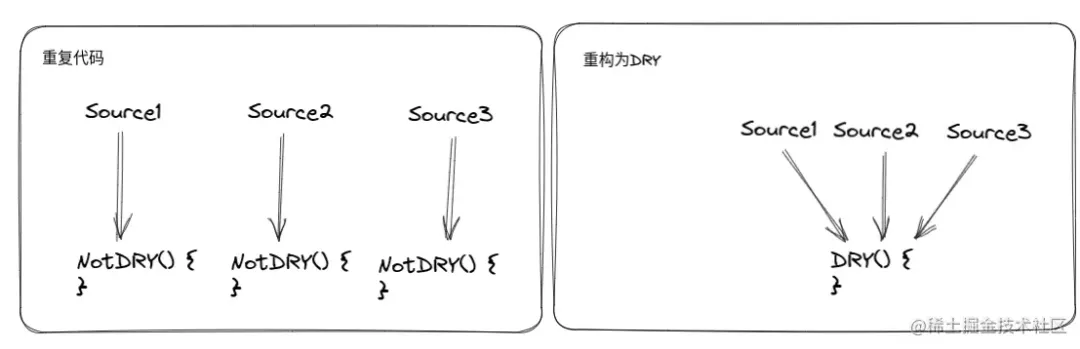
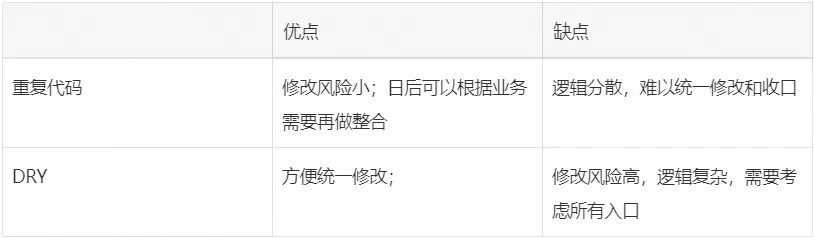
从上表可以看出,重复代码和 DRY 很难说孰优孰劣,有时候费了半天劲抽取代码,反而系统复杂性更高了。符合设计原则的代码不一定是好代码,不符合设计原则的代码不一定是坏代码。
通过纯粹设计原则的角度是看不出来软件设计决策是否正确的,必须从更高的视角出发才行。
03
复用是一个权衡
我们常常被教育复用的好处,而忽视了复用的成本。为了复用一个代码模块:- 首先我需要知道可复用构件的存在
- 然后了解其中的结构和接口
- 对接模块的接口,并且测试无误
- 最后,只是会用还不够,如果线上出现,我必须保证自己对它有足够的了解,可以去排查该模块的问题
而只要有成本的东西就是需要权衡的。没人愿意花费 10 元价格,只买回来一个价值 8 元的产品。
复用软件的好处众所周知,但我认为可以进一步拆分成两种:
- 降低开发成本。通过整合业务中台已有的支付,供应链等能力,可以快速支撑新的业务上线。
- 提升软件产品的核心竞争力。已有的模块经过线上检验,其中积累了过去成功的经验, 并且未来还会继续积累,直接复用能够大大提升产品的竞争力。
第一点是从成本角度,而第二点是从效益角度。
下文分别从这个两个角度与成本进行比较, 引出两位大师的观点,就能更好地得出软件复用的结论。
04
深浅模块:成本角度谈复用
谈到文件系统,或者数据库,应用肯定都是直接复用现有的开源软件,或者公司内专业团队定制的。不可能复制一份数据库代码到应用中。一方面是没这实力,更重要是不划算。文件系统对上层提供了非常简单的文件模型,数据库对应用也提供了非常好理解的表模型。而他们的实现非常复杂,需要考虑并发,数据完整性,事务等一系列问题。相比理解他们的实现,学习模型和接口成本几乎可以忽略不计。

学习 SQL 相比学习 数据库实现 的成本,从相关书籍的厚度上就能看出一二,更何况它们的阅读难度相差也很大。
上面的案例有共同的特点,即模块的接口很简单,但是提供的功能却是深刻的。这个时候复用就非常的合算。
这刚好就是 John Ousterhout 教授(Raft 的发明者)在其著作 《软件设计哲学》中提到 深模块 的概念。
深模块在简单的接口后隐藏了许多功能。深模块代表很好的抽象,其内部复杂性只有很小一部分对其用户可见。
其反例就是浅模块, 浅模块接口很复杂,提供的功能却不多。在项目中经常会下面这样的代码:
public void addParameter(List<String> params, String param) {params.add(param);}
它接收两个参数,却只实现了一个最简单的列表增加元素功能,寻找和复用它的成本已经超过了复用的好处。
浅模块的接口复杂度和实现复杂度接近,与其去了解模块的接口,开发人员还不如自己重新实现一遍。
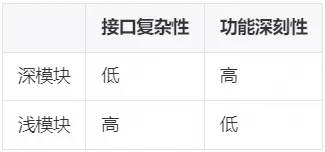
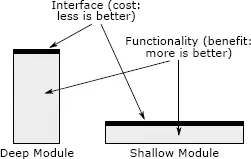
《软件设计哲学》书中的配图,方块的宽度代表模块接口的复杂程度,深度代表功能的深刻程度,接口应该越简单越好,功能应该越深刻越好。深模块就是接口简单但是功能深刻的模块。
05
塑造产品的核心竞争力:效益角度谈复用
什么情况下,复用能够提升产品的核心竞争力呢?Supercell 游戏公司将之前的爆款中备受玩家欢迎的风格,素材和程序逻辑沉淀下来,通过复用之前积累,可以快速产出新的爆款。
钉钉的审批流程配置功能经过多年的迭代,操作习惯已经深入人心。后来钉钉又推出 CRM 应用,直接复用这套配置界面和逻辑, 虽然需要开发一些适配逻辑,但大大降低了用户的学习成本, 提升了竞争力。
上面的两个例子刚好就代表了两种提升产品核心竞争力的逻辑:
- 复用之前具有竞争力的技术模块,让过去的成功经验助力未来的产品成功
- 给用户提供一致的体验,考虑用户的使用习惯,降低学习成本
复用不同模块能取得效果的程度也是不同的,复用什么样模块更有可能获得上述两点效果呢?DDD 中对子域的划分或许能够给我们答案,在 DDD 中软件存在三种子域:
- 核心子域
- 特点:能够给公司带来核心竞争力的领域模块,拥有很高的复杂度和差异化价值
- 案例:比如滴滴的司机调度算法,支付宝的交易系统,钉钉的 IM 系统等等
- 复用策略:属于该子域的模块应该尽可能地复用, 将其竞争力也注入到其他产品,甚至投入精兵强将,提升其可扩展性,进一步拉开和竞争对手差距
- 支持子域
- 特点:用来支撑核心子域,但是不能带来竞争力
- 案例:比如运营管理系统,后台排查系统等等
- 复用策略:因为不能带来核心竞争力,不如各个业务根据自己需求,使用脚手架快速搭建,定制起来还更加方便
- 通用子域
- 特点:通用的业务或者技术问题领域, 比较复杂, 却不能给企业带来核心竞争力。好在一般有现成的解决方案,可以直接采购
- 案例:比如财务系统,可以直接采购用友,金蝶;分库分表,消息队列可以直接使用开源软件,或者购买云上解决方案
- 复用策略:尽可能复用,但是复用的目的与核心子域不同,主要是为了降低研发成本
以 DDD 中经典的货运管理系统为例(简化):
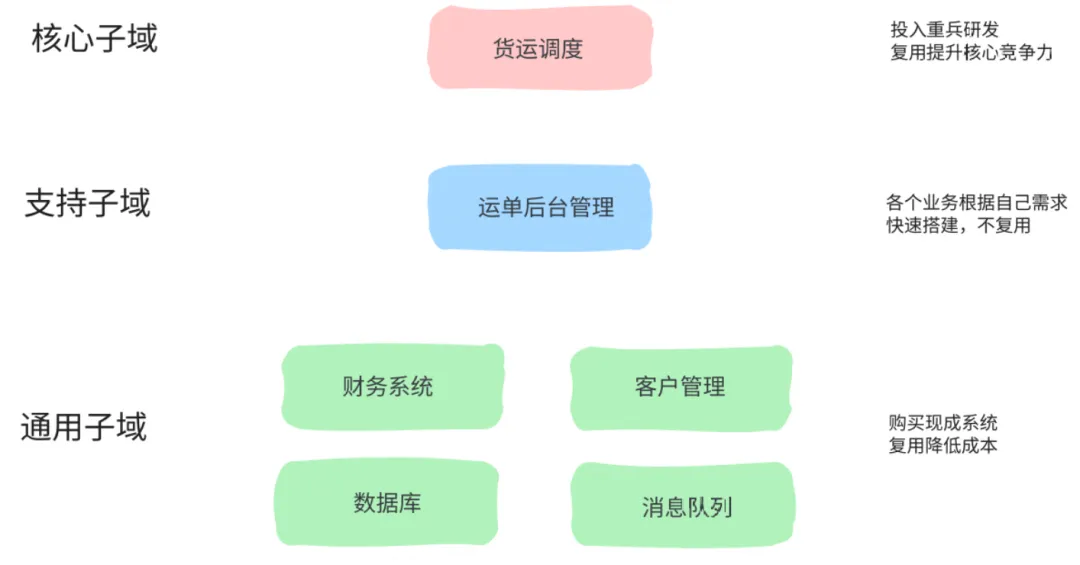
相比对于业务的助力,复用的成本就显得微不足道了。
因此 DDD 要求技术和业务深度结合,如果不了解业务的话,单从设计原则角度,很难理解为什么要复用一个技术模块。
成功的设计来自对业务问题的深刻理解。最符合其业务子域的地方,才是类/函数 应该 在的地方。
06
总结
世上只有一种英雄主义,就是在认清生活真相之后依然热爱生活工程师对技术也只有一种热爱,就是当发现任何技术都无法代替对业务的深入认知后,依旧热爱代码。
DDD 的思想和工具能够帮我们站在更高的视角,从业务分析的视角看待复用的成本和效益,帮助我们更好地做出决策。

参考书目
[01] 《复杂软件设计之道》https://book.douban.com/subject/35216922/[02] 《架构整洁之道》
https://book.douban.com/subject/30333919/
[03] 《软件设计哲学》
https://yingang.github.io/aposd-zh/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号