浅谈搜索展现层场景化技术-tanGo实践 算子化
浅谈搜索展现层场景化技术-tanGo实践 https://mp.weixin.qq.com/s/nVy9SYRIaaqZWgOHKTMQ4Q
introduction本文为搜索展现层相关技术,主线会先通过介绍搜索阿拉丁的产品形态,让读者初步了解什么是阿拉丁,及相关展现概念。之后会聚焦场景化产品,场景化是搜索构建沉浸式完美体验(重新组合整页阿拉丁和自然结果)的方案之一,相关检索技术繁多,不能完全覆盖到,本文主要介绍下背后的开发框架支撑 tanGo,会详细介绍下建设过程中的思考、遇到的问题及对应的解决方案。希望读者读完本文,有所收获。
全文4412字,预计阅读时间12分钟。
GEEK TALK
01
相关背景介绍
了解下什么是阿拉丁,阿拉丁是百度搜索推出的垂直化产品,用户使用搜索的过程中,提到的如百科、天气、POI、影视、体育、股票、汉语、翻译等等 Query 需求(如下示例了部分产品),都在不同程度的召回阿拉丁产品。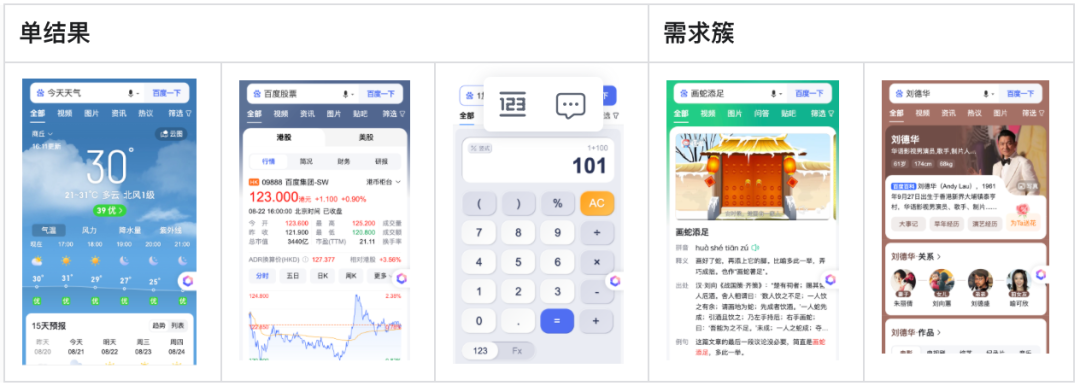
上面是搜索对单需求,需求簇(相同需求的多个单结果聚合)的满足样式,对于更复杂的场景,如高考、奥运会等大事件场景,搜索需要能进行场景的识别,进而召回不同的需求簇。
 另技术上垂类部分业务也在做 PHP 迁移 Go,在这样的产品和技术背景下,搜索产研团队孵化设计了 tanGo 业务框架,下面会从需求分析->业务抽象->整体设计及核心能力点抽象逻辑等方面展开,介绍下整个框架建设和应用过程中遇到的一些问题和思考。在此之前集团、搜索也已经积累了一些比较成熟的基础网络框架、 lib (含 cgo)资产,基于这些基础,在实际落地的过程中,也提升了很多效率。一个业务框架,要回答好:为什么做?(解决业务问题)怎么做?(设计、落地)怎么衡量?(指标建设),下面讲下具体实践。
另技术上垂类部分业务也在做 PHP 迁移 Go,在这样的产品和技术背景下,搜索产研团队孵化设计了 tanGo 业务框架,下面会从需求分析->业务抽象->整体设计及核心能力点抽象逻辑等方面展开,介绍下整个框架建设和应用过程中遇到的一些问题和思考。在此之前集团、搜索也已经积累了一些比较成熟的基础网络框架、 lib (含 cgo)资产,基于这些基础,在实际落地的过程中,也提升了很多效率。一个业务框架,要回答好:为什么做?(解决业务问题)怎么做?(设计、落地)怎么衡量?(指标建设),下面讲下具体实践。
GEEK TALK
02
需求分析
下面从搜索概念上,理解下场景化产品需要满足的不同场景:
1、单结果:召回1条结果,搜索召回的基本单元。比如:资源型召回。查影视、小说等;计算型召回。日历、计算器等。
2、需求簇:相同需求的多个单结果聚合。比如:人物示例『刘德华』里面的百科、人物关系、作品。
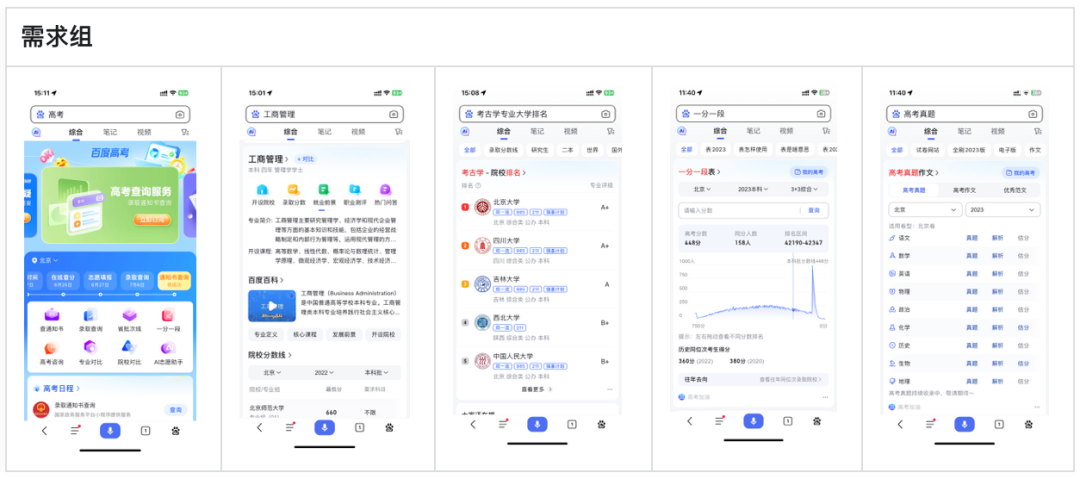
3、需求组:多个需求簇的集合。比如:大事件场景高考(主会场、高考日程、批次线、真题、一分一段),每个都是独立的需求簇需求,其他奥运会等大场景都是。
4、结果页:query 对应的整体返回结果。可能包含多需求,即会多个需求组。(例如q=三亚旅游,即包含旅游需求,也包含金融需求)。
GEEK TALK
03
tanGo设计思路与实践
3.1 业务抽象
3.1.1 场景化产品抽象
从展现技术上看,需求簇和需求组均为单结果的集合,纬度粒度不同,整体将检索请求处理过程,抽象为基础的几个阶段,对各阶段实体化抽象。
1、资源:召回摘要的表示单位,这里的资源可能是从各种检索引擎或者数据库检索出的摘要
-
资源实体抽象:前置策略(资源),检索解析(资源),检索召回,数据映射
2、卡片:检索展现的最小单位。完成资源调度召回,组装摘要到前端模板的映射
-
卡片实体抽象:前置策略(卡),检索解析(卡),资源召回调度(负责卡片下的资源列表的图化调度),前端模板组装
3、场景:检索需要依据 query 解析识别出要展示的子场景,完成不同的需求组的召回
-
调度层:请求级
-
场景实体抽象:请求前置策略,Q 解析场景计算,卡片调度(负责执行需求簇下卡片集合图化调度),召回后置策略,组织回包
3.1.2 框架建设技术思路
业务流程处理标准化,处理流程核心考虑点
1、协议转换
-
支持http/nshead等多种协议
-
支持pb/json等多种数据协议转换
-
考虑同步、异步检索,能力覆盖结果页、异步情景页、小程序、独立站等开发场景
2、配置化:考虑运维成本,检索请求配置化,可视化
3、组件化,算子化:方便后续共建
4、图化资源调度:卡片调度、资源调度
建立标准化组件共建机制
1、定义标准化数据、检索、策略组件接口
2、组件贡献机制
建立标准化类库共建机制
1、标准 Lib 贡献标准。比如:抽样、DAG、Trace、算法、字符串、协议转换、加减密等等
2、标准 Lib 索引页
其他关键点
1、开发阶段:一键生成、可视化编程、用户手册提升研发效率
2、测试阶段:编译加速、QATest、0级拦截等保障交付
3、上线后:监控体系配套:建设普罗米修斯,业务、下游、检索调度等面板
3.1.3 衡量指标
规模:
-
应用规模,团队覆盖面
效率:
-
新项目创建成本
-
新产品交付周期
-
新人培养学习成本
-
通用组件、Lib的数量,及组件沉淀带来的代码行数节约
-
团队效率,团队交付效率的提升反馈
用户满意度:
-
NPS,定期的用户满意度反馈
3.2 框架技术框图
基于前面对业务场景的抽象和技术抽象,构建了如下框架建设框图。主要核心点:
1、易用性:端到端打造工具链
2、框架分层结构:业务流程、组件、Lib
3、业务流程:同步检索、异步检索、数据处理

3.3 核心点设计
3.3.1 检索流程设计
设计目标:
一套标准处理流程,抽象检索各阶段
-
请求级处理
-
卡片级处理
-
资源级处理
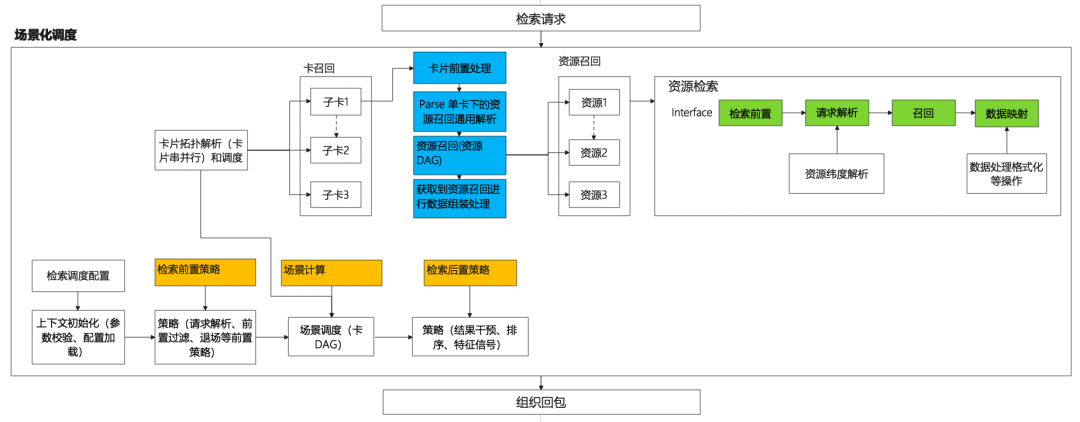
上图是检索请求的处理过程,各阶段以组件形式组织,组件为架构和业务同学共同开发,不同类型组件在检索的各个的阶段会被调度,业务同学可专注领域组件的研发,其他协议的封装转换框架研发统一提供和对接。
3.3.2 配置化设计
设计目标:
-
检索过程需在一份配置即可描述
-
控制学习成本,语法必须简洁、简单
关键技术点:
-
流程拓扑抽象:三层拓扑(策略、卡片、资源)
-
组件管理:实现对组件的生命周期的管理和同时对 gc 友好,使用了go反射、对象池等原生能力
-
配置热加载:实现配置的动态更新
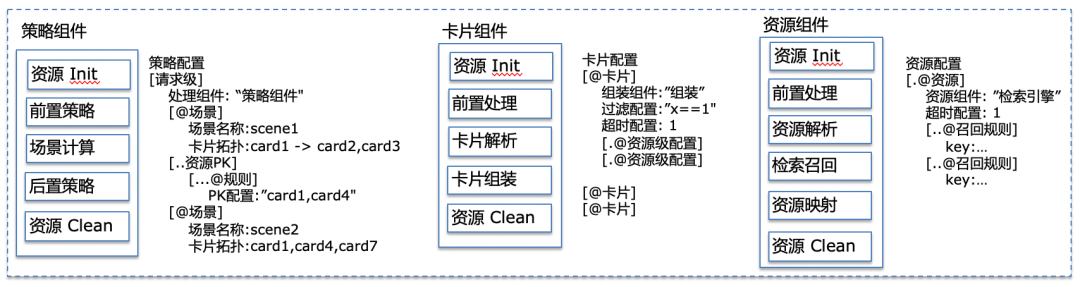
上图是对不同阶段组件配置化的具体化示例,配置化带来的优点:检索过程透明可见;运维成本可控;学习和接受成本低。
3.3.3 资源调度设计
从前面介绍到的场景化处理流程、配置化中可见,在场景计算过程中的卡片调度,卡片处理过程中的资源调度,都用到了串并行拓扑调度,因为需要为框架设计一套简易 DAG 执行引擎。
设计目标:
1、基于 DAG ,设计一套简易语法规则,实现资源调度引擎
2、可以对程序异常、超时等进行捕获和错误信息记录
关键技术点:
1、设计一套简易满足需求的DAG规则语法
-
基础的流程控制:串行、并行、条件控制语法
-
异常控制:程序异常、超时等捕获处理
-
语法简单,上手成本低
2、DAG调度引擎:基于配置的DAG规则执行图谱调度
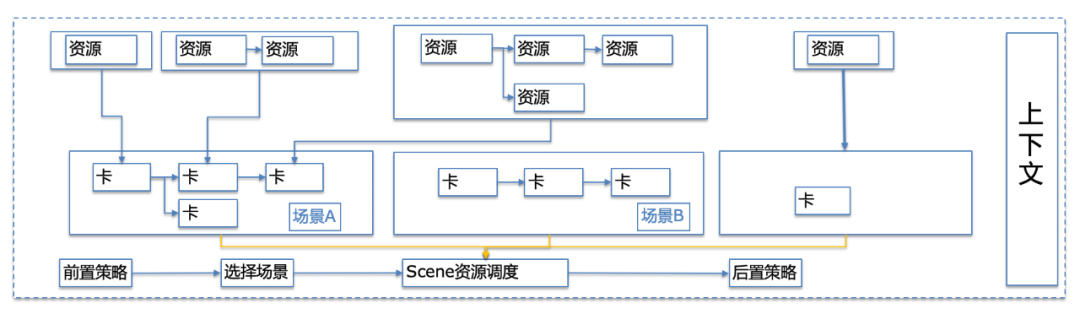
从图上,可以看到检索请求的处理过程中,会根据用户场景的需求识别,进行着场景、卡片的图化调度,以实现用户对复杂需求的召回响应,组件之间通过上下文串联通信。
3.3.4 共建机制打造
检索流程设计时,考虑框架的可持续性和可扩展性,提取抽象出了组件的概念,上面检索流程处理里面,在不同的阶段调度着各种处理组件响应检索,包含请求级、卡片级、资源级,这些都是可扩展的调度阶段。
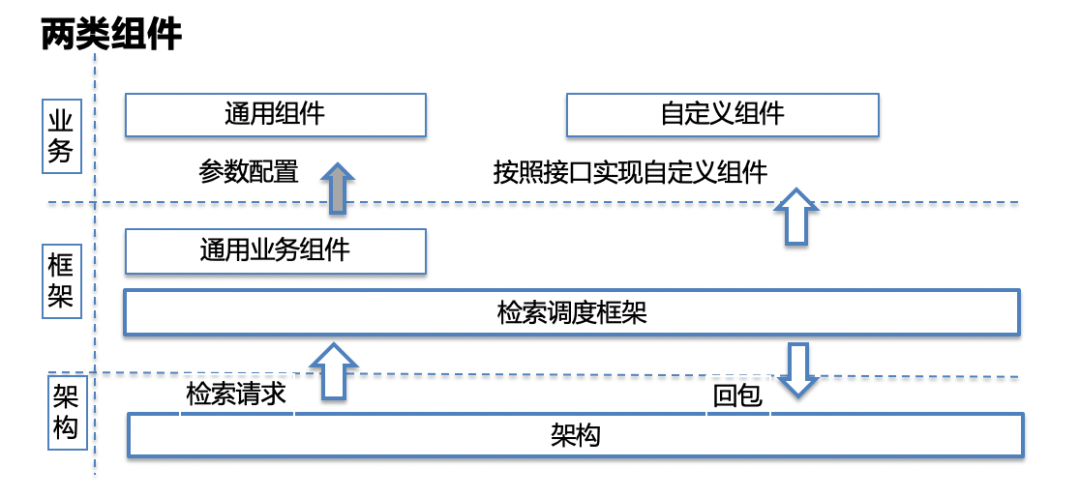
整体思路,如图拆分为2类组件,架构和业务共同建设,最大程度的实现可复用、且业务可扩展。
1、架构组件,通用场景,架构统一抽象,最大化垂类之间可复用
2、业务组件,业务根据自己的业务场景自定义的组件
3.3.5 易用性打造
完成了框架的建设后,面临怎么做才能更贴近业务,怎么才能更易用?下面是在易用性方向的建设。
易用性是落地和规模化非常重要的一步,需要站在一线研发视角,端到端看交付全流程问题,然后针对各阶段的问题,配套建设工具链,提高运行效率。

上图是研发不同的阶段,框架团队提供的部分支持,一方面是保障接入、开发效率,同时也积极的例行收集反馈,以更好的改进完善。
GEEK TALK
04
结论以及展望
本文从介绍搜索阿拉丁产品形态开始,延伸出场景化,并基于搜索场景化产品特点,抽象了 tanGo 框架。接下来聚焦系统详细的分享了 tanGo 框架的技术设计思路与实践,并尽可能表达了其中的核心思考和核心设计点,篇幅不能覆盖所有的设计点,框架也仍然有缺点和不足,后续会持续的进行优化迭代。后续,框架会更多聚焦产研“全流程”,通过完善框架的能力,对整个研发、测试阶段、上线后进行更全面的支持和覆盖,例如框架通过与代码托管服务的整合,在创建代码库阶段就提升易用性,编译发布标准化,框架与持续集成服务整合,提升上线后可测性等等能力,对研发全流程覆盖的更全面。
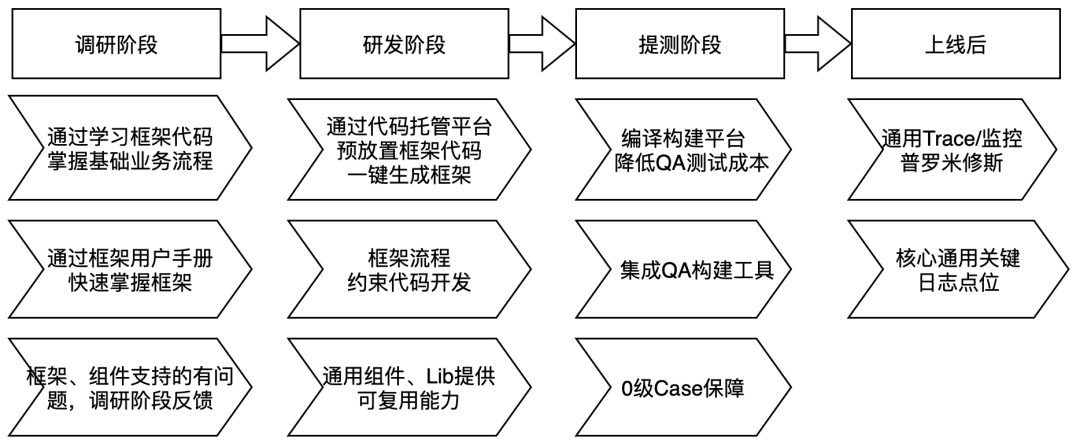
一个项目从需求构建到工程落地,再到应用及规模化,各个阶段,细节问题还是比较多的,大家如感兴趣搜索阿拉丁产品或者感兴趣搜索展现技术问题,可以留言交流。
目前『搜索产品研发工程师』岗位正在热招,主要为搜索产研后端,AI应用与架构方向工作。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号