
并行算法的设计 评估并行程序的性能
5. 如何设计一个并行程序 — python-parallel-programming-cookbook-cn 1.0 文档 https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/chapter1/05_How_to_design_a_parallel_program.html
5. 如何设计一个并行程序
并行算法的设计是基于一系列操作的,在编程的过程中必须执行这些操作来准确地完成工作而不会产生部分结果或错误结果。并行算法地大致操作如下:
- 任务分解 (Task decomposition)
- 任务分配 (Task assignment)
- 聚合 (Agglomeration)
- 映射 (Mapping)
5.1. 任务分解
第一阶段,将软件程序分解为可以在不同处理器执行的多个任务或一系列指令以实现并行性。下面展示了两个方法来实现程序分解:
- 按范围分解 (Domain decomposition):使用这个分解方法,程序所需的数据会被分解;处理器会使用同一个程序处理不同的数据。这个方法一般在需要处理大量数据的情况下使用。
- 按功能分解 (Functional decomposition):使用这个分解方法会将问题分解为几个任务,每个任务会对可利用的数据执行不同的操作。
5.2. 任务分配
在这个步骤中,并行程序将任务分配给各种处理器的机制是确定的。这个阶段非常重要,因为在这阶段会向各个处理器之间分配工作。负载均衡是这个阶段的关键,所有处理器都应该保持工作状态,避免长时间的空闲。为了实现这个效果,程序员必须考虑异构系统的可能性,异构系统会尝试将任务分配给相对更适合的处理器。最后,为了让并行程序有更高的效率,必须尽量减少处理器之间的通讯,因为处理器之间的通讯通常是程序变慢和资源消耗的源头。
5.3. 聚合
聚合,就是为了提升性能将小任务合并成大任务的过程。如果设计过程的前两个阶段是将分解问题得到的任务数量大大超过处理器可接受的程度,或者计算机不是专门设计用于处理大量小任务 (如GPU的架构就非常适合处理数百万甚至上亿任务),那么过分解会导致严重的效率下降。一般情况下,这是因为任务需要跟处理它的处理器或线程进行通讯。大多数的通讯的消耗不仅包括跟传输数据量相称的部分,还包括进行通讯的固定部分 (如建立 TCP 连接的延迟)。如果分解的任务过小,固定消耗可能比数据量还大,可以说这样的设计是低效的。
5.4. 映射
在并行算法设计的映射阶段,会指定任务由哪个处理器处理。这阶段的目标是减少总体的执行时间。在这里需要经常做取舍,因为下面两个相互矛盾的策略:
- 需要频繁通讯的任务应该由同一个处理器处理以增强局部性。
- 可以并行执行的任务应该由多个处理器处理以增强并行性。
这就是所谓的映射问题,也是一个NP完全问题——一般情况下不能再多项式时间内解决的问题。在大小相等和通讯模式容易定义的任务中,映射很直接 (在这里也可以执行聚合的步骤来合并映射到相同处理器的任务)。但是如果任务的通讯模式难以预测或者每个任务的工作量都不一样,设计一个高效的映射和聚合架构就会变得有难度。由于存在这些问题,负载均衡算法会在运行时识别聚合和映射策略。最难的问题是在程序执行期间通信量或任务数量改变的问题。针对这些问题,可以使用在执行过程中周期性运行的动态负载均衡算法。
5.5. 动态映射
无论是全局还是局部,对于不同的问题都有不同的负载均衡算法。全局算法需要对即将指向的计算有全局的认识,这样通常会增加很多开销。局部算法只需要依靠正在解决的问题的局部信息,对比全局算法能够减少很多开销,但在寻找最佳聚合和映射的能力较差。然而,即使映射的结果较差,节省的开销一般还是能减少执行时间。如果任务除了执行开始和结束几乎不和其它任务进行通讯,那么可以使用任务调度算法简单地把任务分配给空转的处理器。在任务调度算法中,会维护一个任务池,任务池中包含了待执行的任务,工作单元 (一般是处理器) 会从中取出任务执行。
接下来会解释这个模型中的三个通用方法。
5.6. 管理单元/工作单元 (Manager/worker)
这是一个基础的动态映射架构,在这个架构中工作单元会连接到一个中央管理单元中。管理单元不停发送任务给工作单元并收集运算结果。这个策略在处理器数量相对较小的情况下表现最好。
5.7. 分层的管理单元/工作单元 (Hierarchical manager/worker)
这是拥有半分布式布局的管理单元/工作单元的变种;工作单元会按组划分,每一组都有器管理单元。当工作单元从组管理单元获取任务时,组管理单元会和中央管理单元通讯 (或者组管理单元之间直接通讯)。通过提前获取任务可以提升这个基础策略的性能,这就导致了通讯和计算重迭进行。这样就可以在多个管理单元之间传播负载,如果所有工作单元都向同一个管理单元请求任务,这种策略本身就可以应付大量的处理器。
5.8. 去中心化 (Decentralize)
在这个架构中,所有东西都是去中心化的。每个处理器都维护着自己的任务池并且直接和其它处理器通讯请求任务。处理器有很多种方式选择处理器请求任务,选择哪种方式有待解决的问题决定。
6. 如何评估并行程序的性能 — python-parallel-programming-cookbook-cn 1.0 文档 https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/chapter1/06_How_to_evaluate_the_performance_of_a_parallel_program.html
6. 如何评估并行程序的性能
并行编程的发展产生了对性能指标和并行程序评估软件的需求,通过评估性能才能确定该算法是否方便快捷。实际上,并行计算的重点是在相对较短的时间内解决体量较大的问题。为了能够达到这个目的,需要考虑的因素有:使用的硬件类型,问题的可并行程度和采用的编程模型等。为了加速算法评估过程,引进了基本概念分析,也就是将并行算法和原始的顺序执行做对比。通过分析和确定线程数量和/或使用的处理器数量来确定性能。
为了进行分析,在这里介绍几个性能指标:加速比,效率和扩展性。
阿姆德尔定律 (Ahmdal’s law) 引入了并行计算的极限,来评估串行算法并行化的效率。古斯塔夫森定律 (Gustafson’s law) 也做了相似的评估。
6.1. 加速比
加速比用于衡量使用并行方式解决问题的收益。假设使用单个处理单元解决这个问题需要的时间为 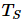 ,使用
,使用 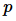 个相同的处理单元解决这个问题的时间为
个相同的处理单元解决这个问题的时间为 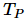 ,那么加速比
,那么加速比 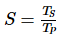 。如果
。如果 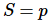 ,加速比为线性,也就是说执行速度随着处理器数量的增加而加快。当然,这只是一个理想状态。当 为最佳串行算法的执行时间,加速比是绝对的,而当 为并行算法在单个处理器上的执行时间,那么加速比是相对的。
,加速比为线性,也就是说执行速度随着处理器数量的增加而加快。当然,这只是一个理想状态。当 为最佳串行算法的执行时间,加速比是绝对的,而当 为并行算法在单个处理器上的执行时间,那么加速比是相对的。
下面概括了上述的情况:
![S=p]() 为线性加速比,也是理想加速比。
为线性加速比,也是理想加速比。![S<p]() 为真实加速比
为真实加速比![S>p]() 为超线性加速比
为超线性加速比
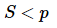 为真实加速比
为真实加速比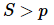 为超线性加速比
为超线性加速比6.2. 效率
在理想状态下,如果一个并行系统有 个处理单元,那么它能提供的加速比等于 。然而,这几乎是不可能达到的。处理单元空转和通讯通常会浪费一些时间。效率通常是用于评价处理器在执行任务时是否被充分利用的性能指标,它跟通讯和同步所耗费的时间作比较。
假设效率为 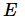 ,可以通过
,可以通过 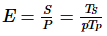 算出。拥有线性加速比的算法的效率
算出。拥有线性加速比的算法的效率 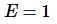 ;在其它情况下, 会小于1。下面会定义三种情况:
;在其它情况下, 会小于1。下面会定义三种情况:
- 当
![E=1]() ,为线性加速比。
,为线性加速比。 - 当
![E<1]() ,为真实情况。
,为真实情况。 - 当
![E<<1]() ,可以确定这是一个有问题的低效并行算法。
,可以确定这是一个有问题的低效并行算法。
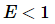 ,为真实情况。
,为真实情况。 ,可以确定这是一个有问题的低效并行算法。
,可以确定这是一个有问题的低效并行算法。6.3. 伸缩性
伸缩性用于度量并行机器高效运行的能力,代表跟处理器数量成比例的计算能力 (执行速度)。如果问题的规模和处理器的数量同时增加,性能不会下降。在依靠各种因素叠加的可伸缩系统中,可以保持相同的效率或者有更高的效率。
6.4. 阿姆德尔定律 (Ahmdal’s law)
阿姆德尔定律广泛使用于处理器设计和并行算法设计。它指出程序能达到的最大加速比被程序的串行部分限制。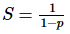 中
中 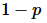 指程序的串行部分。它的意思是,例如一个程序90%的代码都是并行的,但仍存在10%的串行代码,那么系统中即使由无限个处理器能达到的最大加速比仍为9。
指程序的串行部分。它的意思是,例如一个程序90%的代码都是并行的,但仍存在10%的串行代码,那么系统中即使由无限个处理器能达到的最大加速比仍为9。
6.5. 古斯塔夫森定律 (Gustafson’s law)
古斯塔夫森定律在考虑下面的情况之后得出的:
- 当问题的规模增大时,程序的串行部分保持不变。
- 当增加处理器的数量时,每个处理器执行的任务仍然相同。
古斯塔夫森定律指出了加速比 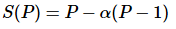 ,
, 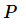 为处理器的数量,
为处理器的数量, 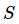 为加速比,
为加速比,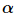 是并行处理器中的非并行的部分。作为对比,阿姆德尔定律将单个处理器的执行时间作为定量跟并行执行时间相比。因此阿姆德尔定律是基于固定的问题规模提出的,它假设程序的整体工作量不会随着机器规模 (也就是处理器数量) 而改变。古斯塔夫森定律补充了阿姆德尔定律没有考虑解决问题所需的资源总量的不足。古斯塔夫森定律解决了这个问题, 它表明设定并行解决方案所允许耗费的时间的最佳方式是考虑所有的计算资源和基于这类信息。
是并行处理器中的非并行的部分。作为对比,阿姆德尔定律将单个处理器的执行时间作为定量跟并行执行时间相比。因此阿姆德尔定律是基于固定的问题规模提出的,它假设程序的整体工作量不会随着机器规模 (也就是处理器数量) 而改变。古斯塔夫森定律补充了阿姆德尔定律没有考虑解决问题所需的资源总量的不足。古斯塔夫森定律解决了这个问题, 它表明设定并行解决方案所允许耗费的时间的最佳方式是考虑所有的计算资源和基于这类信息。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号