一个可读取的二进制流操作 流式输出 流式渲染 分块传输编码 Transfer-Encoding: chunked 在页面流式输出聊天内容
实践:
参考
TextDecoder - Web APIs | MDN https://developer.mozilla.org/en-US/docs/web/api/textdecoder
https://developer.mozilla.org/zh-CN/docs/Web/API/ReadableStream
文本解码器
async function getStreamAndHandle(query) {
fetch('http://xx/dev-stream', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Token': "xxxx"
},
body: JSON.stringify({
Q: query
})
})
.then((response) => response.body)
.then((rb) => {
const reader = rb.getReader();
const decoder = new TextDecoder();
return new ReadableStream({
start(controller) {
// The following function handles each data chunk
function push() {
// "done" is a Boolean and value a "Uint8Array"
reader.read().then(({ done, value }) => {
// If there is no more data to read
if (done) {
console.log('done', done);
controller.close();
return;
}
// Get the data and send it to the browser via the controller
controller.enqueue(value);
// Check chunks by logging to the console
console.log(done, value);
const chunkValue = decoder.decode(value);
console.log("value", value);
console.log("chunkValue", chunkValue);
push();
});
}
push();
},
});
})
.then((stream) =>
// Respond with our stream
new Response(stream, { headers: { 'Content-Type': 'text/html' } }).text()
)
.then((result) => {
// Do things with result
console.log(result);
// txtEle.innerHTML = result;
txtEle.innerHTML += result;
});
}
const chunkValue = decoder.decode(value);
文本解码器处理后,获取到了字符串
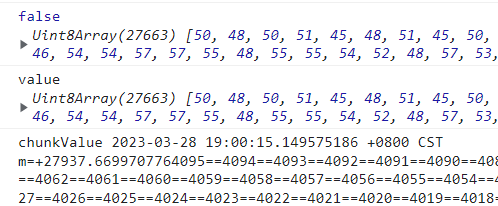
服务端
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title></title>
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no">
</head>
<body>
<button id="btnStream">Stream-流式输入-流式渲染</button>
<button id="btnStreamOnce">Stream-流式输入-一次渲染</button>
<button id="btnNotStream">非流式输入</button>
<div style="width:200px;">
<div>
<div id="txtId">
</div>
</div>
<div>
<div id="txtId1">
</div>
</div>
</div>
</body>
</html>
<script type="text/javascript">
console.log("IN-script");
const btnStream = document.getElementById('btnStream');
btnStream.addEventListener('click', Stream);
const btnStreamOnce = document.getElementById('btnStreamOnce');
btnStreamOnce.addEventListener('click', StreamOnce);
const btnNotStream = document.getElementById('btnNotStream');
btnNotStream.addEventListener('click', NotStream);
const txtEle = document.getElementById('txtId');
const txtEle1 = document.getElementById('txtId1');
function Stream(e) {
console.log(e);
console.log("IN-Stream-1");
getStreamAndHandle("q=Stream")
console.log("IN-Stream-2");
};
function StreamOnce(e) {
console.log(e);
console.log("IN-StreamOnce-1");
getStreamAndHandleAwait("q=StreamOnce")
console.log("IN-StreamOnce-2");
};
function NotStream(e) {
console.log(e);
console.log("IN-1");
txtEle.innerHTML = 'in-NotStream';
getResponseNotStream("123").then((response) => {
console.log("response=", response);
txtEle.innerHTML = "notStream" + response;
});
console.log("IN-2");
};
async function getStreamAndHandle(query) {
const response = await fetch('http://1.2.3.4/dev-stream', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Token': "xx"
},
body: JSON.stringify({
Prompt: query
})
});
const data = response.body;
const reader = data.getReader();
const decoder = new TextDecoder();
let done = false;
let isFirst = true;
let text = '';
while (!done) {
const { value, done: doneReading } = await reader.read();
done = doneReading;
const chunkValue = decoder.decode(value);
text += chunkValue;
// txtEle.innerHTML = result;
text += '<br>-from-FE-' + (new Date().getSeconds()) + ":" + (new Date().getMilliseconds()) + ";";
txtEle.innerHTML = text;
}
}
async function getStreamAndHandleAwait(query) {
fetch('http://1.2.3.4/dev-stream', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Token': "xx"
},
body: JSON.stringify({
Prompt: query
})
})
.then((response) => response.body)
.then((rb) => {
const reader = rb.getReader();
const decoder = new TextDecoder();
return new ReadableStream({
start(controller) {
// The following function handles each data chunk
function push() {
// "done" is a Boolean and value a "Uint8Array"
reader.read().then(({ done, value }) => {
// If there is no more data to read
if (done) {
console.log('done', done);
controller.close();
return;
}
// Get the data and send it to the browser via the controller
controller.enqueue(value);
// Check chunks by logging to the console
console.log(done, value);
const chunkValue = decoder.decode(value);
console.log("value", value);
console.log("chunkValue", chunkValue);
push();
});
}
push();
},
});
})
.then((stream) =>
// Respond with our stream
new Response(stream, { headers: { 'Content-Type': 'text/html' } }).text()
)
.then((result) => {
// Do things with result
console.log(result);
// txtEle.innerHTML = result;
txtEle.innerHTML += result;
});
}
async function getResponseNotStream(query) {
try {
const response = await fetch('http://1.2.3.4/dev-not-stream', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-Token': "xx"
},
body: JSON.stringify({
Prompt: query
})
});
const txt = await response.text();
return txt;
} catch (error) {
console.error('There was a problem with the fetch operation:', error);
}
}
</script>
流式输出至页面
小结:
1、
反应式编程/响应式编程(Reactive Programming)是一种基于事件模型编程范式,
众所周知异步编程模式中通常有两种获得上一个任务执行结果的方式,一个就是主动轮训,我们把它称为Proactive方式。
另一个就是被动接收反馈,我们称为Reactive。
简单来说,在Reactive方式中,上一个任务的结果的反馈就是一个事件,这个事件的到来将会触发下一个任务的执行。
这也就是Reactive的内涵。我们把处理和发出事件的主体称为Reactor,
它可以接收事件并处理,也可以在处理完事件后,发出下一个事件给其他Reactor。
2、分块传输编码
Transfer-Encoding: chunked
3、 HTTP SSE协议
SSE(Server Send Events)是HTTP的标准协议,是服务端向客户端发送事件流式的方式。
在客户端中为一些事件类型绑定监听函数,从而做业务逻辑处理。这里要注意的是SEE是单向的,只能服务器向客户端发送事件流。
4、
Websocket是区别于HTTP的另外一种协议,是全双工通信
SSE是标准的HTTP协议,是半双工通信
5、聊天内容
长文本,尝试文本返回,非JSON形式。
ReadableStream - Web APIs | MDN https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream
流操作 API 中的ReadableStream 接口呈现了一个可读取的二进制流操作。Fetch API 通过 Response 的属性 body (en-US) 提供了一个具体的 ReadableStream 对象。
构造函数
ReadableStream()-
创建并从给定的 Handler 返回一个可读流对象。
属性
ReadableStream.locked只读-
locked返回该可读流是否被锁定到一个 reader。
方法
ReadableStream.cancel()-
取消读取流,读取方发出一个信号,表示对这束流失去兴趣。可以传入 reason 参数表示取消原因,这个原因将传回给调用方。
ReadableStream.getReader()-
创建一个读取器并将流锁定于其上。一旦流被锁定,其他读取器将不能读取它,直到它被释放。
ReadableStream.pipeThrough()-
提供将当前流管道输出到一个 transform 流或 writable/readable 流对的链式方法。
ReadableStream.pipeTo()-
将当前 ReadableStream 管道输出到给定的
WritableStream,并返回一个 promise,输出过程成功时返回 fulfilled,在发生错误时返回 rejected。 ReadableStream.tee()-
tee方法(tee 本意是将高尔夫球放置在球座上)tees 了可读流,返回包含两个ReadableStream实例分支的数组,每个元素接收了相同的传输数据。
示例
Fetch stream
下面的例子,创建了一个智能的 Response 将从另一个资源获取的 HTML 片段流式的传输到浏览器。
它演示了 ReadableStream 与 Uint8Array (en-US) 的协同用法。
fetch('https://www.example.org')
.then((response) => response.body)
.then((rb) => {
const reader = rb.getReader();
return new ReadableStream({
start(controller) {
// The following function handles each data chunk
function push() {
// "done" is a Boolean and value a "Uint8Array"
reader.read().then(({ done, value }) => {
// If there is no more data to read
if (done) {
console.log('done', done);
controller.close();
return;
}
// Get the data and send it to the browser via the controller
controller.enqueue(value);
// Check chunks by logging to the console
console.log(done, value);
push();
});
}
push();
},
});
})
.then((stream) =>
// Respond with our stream
new Response(stream, { headers: { 'Content-Type': 'text/html' } }).text()
)
.then((result) => {
// Do things with result
console.log(result);
});
Async iterator to stream
将(async)迭代器转换为可读流:
function iteratorToStream(iterator) {
return new ReadableStream({
async pull(controller) {
const { value, done } = await iterator.next();
if (done) {
controller.close();
} else {
controller.enqueue(value);
}
},
});
}
这适用于异步和非异步的迭代器。
ReadableStream - Web APIs | MDN https://developer.mozilla.org/en-US/docs/Web/API/ReadableStream
ReadableStream
The ReadableStream interface of the Streams API represents a readable stream of byte data. The Fetch API offers a concrete instance of a ReadableStream through the body property of a Response object.
ReadableStream is a transferable object.
Constructor
ReadableStream()-
Creates and returns a readable stream object from the given handlers.
Instance properties
ReadableStream.lockedRead only-
Returns a boolean indicating whether or not the readable stream is locked to a reader.
Instance methods
ReadableStream.cancel()-
Returns a
Promisethat resolves when the stream is canceled. Calling this method signals a loss of interest in the stream by a consumer. The suppliedreasonargument will be given to the underlying source, which may or may not use it. ReadableStream.getReader()-
Creates a reader and locks the stream to it. While the stream is locked, no other reader can be acquired until this one is released.
ReadableStream.pipeThrough()-
Provides a chainable way of piping the current stream through a transform stream or any other writable/readable pair.
ReadableStream.pipeTo()-
Pipes the current ReadableStream to a given
WritableStreamand returns aPromisethat fulfills when the piping process completes successfully, or rejects if any errors were encountered. ReadableStream.tee()-
The
teemethod tees this readable stream, returning a two-element array containing the two resulting branches as newReadableStreaminstances. Each of those streams receives the same incoming data.
Async iteration
ReadableStream implements the async iterable protocol. This enables asynchronous iteration over the chunks in a stream using the for await...of syntax:
const stream = new ReadableStream(getSomeSource());
for await (const chunk of stream) {
// Do something with each 'chunk'
}
The async iterator consumes the stream until it runs out of data or otherwise terminates. The loop can also exit early due to a break, throw, or return statement.
While iterating, the stream is locked to prevent other consumers from acquiring a reader (attempting to iterate over a stream that is already locked will throw a TypeError). This lock is released when the loop exits.
By default, exiting the loop will also cancel the stream, so that it can no longer be used. To continue to use a stream after exiting the loop, pass { preventCancel: true } to the stream's values() method:
for await (const chunk of stream.values({ preventCancel: true })) {
// Do something with 'chunk'
break;
}
// Acquire a reader for the stream and continue reading ...
Examples
Fetch stream
In the following example, an artificial Response is created to stream HTML fragments fetched from another resource to the browser.
It demonstrates the usage of a ReadableStream in combination with a Uint8Array.
fetch("https://www.example.org")
.then((response) => response.body)
.then((rb) => {
const reader = rb.getReader();
return new ReadableStream({
start(controller) {
// The following function handles each data chunk
function push() {
// "done" is a Boolean and value a "Uint8Array"
reader.read().then(({ done, value }) => {
// If there is no more data to read
if (done) {
console.log("done", done);
controller.close();
return;
}
// Get the data and send it to the browser via the controller
controller.enqueue(value);
// Check chunks by logging to the console
console.log(done, value);
push();
});
}
push();
},
});
})
.then((stream) =>
// Respond with our stream
new Response(stream, { headers: { "Content-Type": "text/html" } }).text()
)
.then((result) => {
// Do things with result
console.log(result);
});
Convert async iterator to stream
Converting an (async) iterator to a readable stream:
function iteratorToStream(iterator) {
return new ReadableStream({
async pull(controller) {
const { value, done } = await iterator.next();
if (done) {
controller.close();
} else {
controller.enqueue(value);
}
},
});
}
This works with both async and non-async iterators.
Async iteration of a stream using for await...of
This example shows how you can process the fetch() response using a for await...of loop to iterate through the arriving chunks.
const response = await fetch("https://www.example.org");
let total = 0;
// Iterate response.body (a ReadableStream) asynchronously
for await (const chunk of response.body) {
// Do something with each chunk
// Here we just accumulate the size of the response.
total += chunk.length;
}
// Do something with the total
console.log(total);https://github.com/mckaywrigley/chatbot-ui
https://github.com/mckaywrigley/chatbot-ui/blob/main/pages/index.tsx
const handleSend = async (message: Message, deleteCount = 0) => {
if (selectedConversation) {
let updatedConversation: Conversation;
if (deleteCount) {
const updatedMessages = [...selectedConversation.messages];
for (let i = 0; i < deleteCount; i++) {
updatedMessages.pop();
}
updatedConversation = {
...selectedConversation,
messages: [...updatedMessages, message],
};
} else {
updatedConversation = {
...selectedConversation,
messages: [...selectedConversation.messages, message],
};
}
setSelectedConversation(updatedConversation);
setLoading(true);
setMessageIsStreaming(true);
setMessageError(false);
const chatBody: ChatBody = {
model: updatedConversation.model,
messages: updatedConversation.messages,
key: apiKey,
prompt: updatedConversation.prompt,
};
const controller = new AbortController();
const response = await fetch('/api/chat', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
},
signal: controller.signal,
body: JSON.stringify(chatBody),
});
if (!response.ok) {
setLoading(false);
setMessageIsStreaming(false);
setMessageError(true);
return;
}
const data = response.body;
if (!data) {
setLoading(false);
setMessageIsStreaming(false);
setMessageError(true);
return;
}
if (updatedConversation.messages.length === 1) {
const { content } = message;
const customName =
content.length > 30 ? content.substring(0, 30) + '...' : content;
updatedConversation = {
...updatedConversation,
name: customName,
};
}
setLoading(false);
const reader = data.getReader();
const decoder = new TextDecoder();
let done = false;
let isFirst = true;
let text = '';
while (!done) {
if (stopConversationRef.current === true) {
controller.abort();
done = true;
break;
}
const { value, done: doneReading } = await reader.read();
done = doneReading;
const chunkValue = decoder.decode(value);
text += chunkValue;
if (isFirst) {
isFirst = false;
const updatedMessages: Message[] = [
...updatedConversation.messages,
{ role: 'assistant', content: chunkValue },
];
updatedConversation = {
...updatedConversation,
messages: updatedMessages,
};
setSelectedConversation(updatedConversation);
} else {
const updatedMessages: Message[] = updatedConversation.messages.map(
(message, index) => {
if (index === updatedConversation.messages.length - 1) {
return {
...message,
content: text,
};
}
return message;
},
);
updatedConversation = {
...updatedConversation,
messages: updatedMessages,
};
setSelectedConversation(updatedConversation);
}
}
saveConversation(updatedConversation);
const updatedConversations: Conversation[] = conversations.map(
(conversation) => {
if (conversation.id === selectedConversation.id) {
return updatedConversation;
}
return conversation;
},
);
if (updatedConversations.length === 0) {
updatedConversations.push(updatedConversation);
}
setConversations(updatedConversations);
saveConversations(updatedConversations);
setMessageIsStreaming(false);
}
};
https://github.com/mckaywrigley/chatbot-ui/blob/main/pages/api/chat.ts
const handler = async (req: Request): Promise<Response> => {
try {
const { model, messages, key, prompt } = (await req.json()) as ChatBody;
await init((imports) => WebAssembly.instantiate(wasm, imports));
const encoding = new Tiktoken(
tiktokenModel.bpe_ranks,
tiktokenModel.special_tokens,
tiktokenModel.pat_str,
);
const tokenLimit = model.id === OpenAIModelID.GPT_4 ? 6000 : 3000;
let promptToSend = prompt;
if (!promptToSend) {
promptToSend = DEFAULT_SYSTEM_PROMPT;
}
const prompt_tokens = encoding.encode(promptToSend);
let tokenCount = prompt_tokens.length;
let messagesToSend: Message[] = [];
for (let i = messages.length - 1; i >= 0; i--) {
const message = messages[i];
const tokens = encoding.encode(message.content);
if (tokenCount + tokens.length > tokenLimit) {
break;
}
tokenCount += tokens.length;
messagesToSend = [message, ...messagesToSend];
}
encoding.free();
const stream = await OpenAIStream(model, promptToSend, key, messagesToSend);
return new Response(stream);
} catch (error) {
console.error(error);
return new Response('Error', { status: 500 });
}
};
https://github.com/mckaywrigley/chatbot-ui/blob/main/utils/server/index.ts
export const OpenAIStream = async (
model: OpenAIModel,
systemPrompt: string,
key: string,
messages: Message[],
) => {
const res = await fetch(`${OPENAI_API_HOST}/v1/chat/completions`, {
headers: {
'Content-Type': 'application/json',
Authorization: `Bearer ${key ? key : process.env.OPENAI_API_KEY}`,
},
method: 'POST',
body: JSON.stringify({
model: model.id,
messages: [
{
role: 'system',
content: systemPrompt,
},
...messages,
],
max_tokens: 1000,
temperature: 1,
stream: true,
}),
});
if (res.status !== 200) {
const statusText = res.statusText;
throw new Error(`OpenAI API returned an error: ${statusText}`);
}
const encoder = new TextEncoder();
const decoder = new TextDecoder();
const stream = new ReadableStream({
async start(controller) {
const onParse = (event: ParsedEvent | ReconnectInterval) => {
if (event.type === 'event') {
const data = event.data;
if (data === '[DONE]') {
controller.close();
return;
}
try {
const json = JSON.parse(data);
const text = json.choices[0].delta.content;
const queue = encoder.encode(text);
controller.enqueue(queue);
} catch (e) {
controller.error(e);
}
}
};
const parser = createParser(onParse);
for await (const chunk of res.body as any) {
parser.feed(decoder.decode(chunk));
}
},
});
return stream;
};
聊天窗口,长文本,流式输入。
java - HTTP 流式传输 - 个人文章 - SegmentFault 思否 https://segmentfault.com/a/1190000038204810
工作跟分布式存储相关,遇到这样一个业务场景,将大文件通过 HTTP 协议传输到服务端。无法一次加载到内存中,组装到 Request 的 body 中。针对这样的问题,应该怎么解决呢?最简单的思路就是将大文件分成小文件上传,HTTP 流式传输就为我们提供了相应的解决方案。
先来看几个知识点:
KeepAlive模式
大学的知识学完,我对 HTTP 的认知只记住了少数几个关键词:HTTP 是无状态无连接的。
这个意思是指HTTP协议采用“请求-应答”模式,当使用普通模式,即非KeepAlive模式时,每个请求/应答客户和服务器都要新建一个连接,完成之后立即断开连接;
后来 Web 的世界越来越精彩,一个网页中可能嵌套了多种资源,比如图片、视频,为了解决频繁建立 TCP 连接带来的性能损耗,提出了 Keep-Alive 模式。当使用Keep-Alive模式(又称持久连接、连接重用)时,Keep-Alive功能使客户端到服务器端的连接持续有效,当出现对服务器的后继请求时,Keep-Alive功能避免了建立或者重新建立连接。
TCP 的底层实现中包含一个 KeepAlive 定时器,当一条数据流中没有数据通过时,服务端每隔一段时间会向客户端发送一个不带数据的 ACK 请求,如果收到 Client回复,表明连接依然存在。如果没有收到回复,Server会多次 ACK,达到一定次数以后还没有收到回复,默认此连接关闭。

Keep-Alive 模式在HTTP 1.0中默认是关闭的,需要在http头加入"Connection: Keep-Alive",才能启用Keep-Alive;http 1.1中默认启用Keep-Alive,如果加入"Connection: close ",才关闭。但是若想完成一次 Keep-Alive 的连接,仍旧需要 Client 和 Server 端共同支持,如果某一端处理完请求直接关闭了 Socket,神仙也保证不了连接。
解决了不必重复频繁建立连接的问题,第二个问题随之而来,怎么判断数据流的结束?
在请求-响应模式下,每一次 HTTP 请求发送完成,Client 都会主动关闭连接,Server 端在读取完所有的 Body 数据后,就认为此次请求已经完毕,开始在服务端进行处理。但是在 Keep-Alive模式下,这个问题显然就没有这么简单了。举个例子,比如一条 Keep-Alive 的HTTP 连接 ,通过 连接底层的 TCP 通道连续发送了两张图片,对于服务器来说,如何判断这是两张图片?而不是把他们当做同一个文件的数据进行处理呢?再比如,普通模式下,服务端发送完响应,就会关闭连接,客户端读取时会读到 EOF(-1)。但在 Keep-Alive 模式下,服务器不会主动关闭连接,Client 自然也就读不到 EOF。
判断数据流结束的方法
HTTP 为我们提供了两种方式
- Content-Length
这是一个很直观的方式,在要传输的数据前增加一个信息,来告知对端将要传输多少数据,这样在另一侧读取到
这个长度的数据后,可以认为接受已经完成。
如果无法提前预知Content-Length 呢,比如数据源还在不断的生成当中,不知道什么时候会结束。接下来还有第二种办法。
- 使用消息Header 字段,Transfer-Encoding:chunk
如果要一边产生数据,一边发给客户端,服务器就需要使用"Transfer-Encoding: chunked"这样的方式来代替Content-Length。
chunk编码将数据分成一块一块的发生。Chunked编码将使用若干个Chunk串连而成,由一个标明长度为0的chunk标示结束。每个Chunk分为头部和正文两部分,头部内容指定正文的字符总数(十六进制的数字)和数量单位(一般不写),正文部分就是指定长度的实际内容,两部分之间用回车换行(CRLF)隔开。在最后一个长度为0的Chunk中的内容是称为footer的内容,是一些附加的Header信息(通常可以直接忽略)。
抓包验证
百闻不如一见,使用 WireShark 先抓为敬。
chunk 编码方式抓包:
Server 编码:
func indexHandler(w http.ResponseWriter, r *http.Request) {
//fmt.Print(r.Body.Read())
fmt.Fprint(w, "hello world")
}
func main() {
http.HandleFunc("/report", indexHandler)
http.ListenAndServe(":8000", nil)
}
Client 代码
func main() {
pr, rw := io.Pipe()
go func(){
for i := 0; i < 100; i++ {
rw.Write([]byte(fmt.Sprintf("line:%drn", i)))
}
rw.Close()
}()
http.Post("localhost:8000/","text/pain", pr)
}



从结果可以看出,HTTP 协议底层通过同一个 TCP 连接在发送数据。
每一个TCP packet 的内容为我们写入的数据。同时 HTTP 请求
方式二:Content-Length
Client编码
func main() {
count := 10
line := []byte("linern")
pr, rw := io.Pipe()
go func() {
for i := 0; i < count; i++ {
rw.Write(line)
time.Sleep(500 * time.Millisecond)
}
rw.Close()
}()
// 构造request对象
request, err := http.NewRequest("POST", "http://localhost:8000/report", pr)
if err != nil {
log.Fatal(err)
}
// 提前计算出ContentLength
request.ContentLength = int64(len(line) * count)
// 发起请求
http.DefaultClient.Do(request)
}


依然是通过多次 tcp 包传输的。
总结
为了解决不能将大数据一次性拼接到 Request 的 Body 中这个问题,采取了 HTTP 流式传输的方式,即边读进内存,边通过 HTTP 传输。
Keep-Alive 模式,避免了传输多个报文时,TCP 连接重复建立,为流式传输大量数据打好了基础。
Content-Length 和 Transfer-Encoding,两种方式为消息内容的长度判断提供了解决方案。
设置Content-Length的方式,由 Client 端持续将数据通过 HTTP 传输到 Server。
chunk方式,Client 端将数据分片发包到 Server。
什么是流式输出?-阿里云开发者社区 https://developer.aliyun.com/article/781149
作者 | 幽霄
来源 | 阿里技术公众号
一 名词理解
1 流式
流式(Stream)亦称响应式,是一种基于异步数据流研发框架,是一种概念和编程模型,并非一种技术架构,目前在各技术栈都有响应式的技术框架,前端的React.js、RxJs,服务端以RxJava、Reactor,Android端的RXJava。由此而来的即是响应式编程。
2 反应式/响应式编程
反应式编程/响应式编程(Reactive Programming)是一种基于事件模型编程范式,众所周知异步编程模式中通常有两种获得上一个任务执行结果的方式,一个就是主动轮训,我们把它称为Proactive方式。另一个就是被动接收反馈,我们称为Reactive。简单来说,在Reactive方式中,上一个任务的结果的反馈就是一个事件,这个事件的到来将会触发下一个任务的执行。
这也就是Reactive的内涵。我们把处理和发出事件的主体称为Reactor,它可以接收事件并处理,也可以在处理完事件后,发出下一个事件给其他Reactor。
下面是一个Reactive模型的示意图:

当然一种新的编码模式,它的RunTime会减少上下文切流从而提升性能,减少内存消耗,与之相反带来的是代码的可维护性降低。衡量优劣需要根据场景带来的收益来衡量。
3 流式输出
流式输出就比较神奇,源自于团队内部在一次性能大赛结束后的总结中产生,是基于流式的理论基础在页面渲染以及渲染的HTML在网络传输中的具体应用而诞生,也有人也简单的称之为流式渲染。即:将页面拆分成独立的几部分模块,每个模块有单独的数据源和单独的页面模板,在server端流式的操作每个模块进行业务逻辑处理和页面模板的渲染,然后流式的将渲染出来的HTML输出到网络中,接着分块的HTML数据在网络中传输,接着流式的分块的HTML在浏览器逐个渲染展示。具体流程如下:

针对HTML可以如上所述进行流式输出,衍生出针对json数据的流式输出,其实也是如出一辙,无非少了一层渲染的逻辑,数据流式输出流程跟上图类似,不再赘述。这里可以把客户端的请求当做响应式的一个事件,所以总结就是客户端主动发出请求,服务端流式返回数据,即流式输出。
4 端到端响应式
基于流式输出,我们再深入一点,可以发现其实不只是用户端和web server之间的数据可以在网络上进行流式输出,微服务的各个server之间的数据其实也可以在网络上进行流式输出,如下图所示:

数据可以在网络之间的流式传输,再进一步来看,数据在整条请求响应链路上的流式传输会是什么样子,见下图所示:

综上所述我们定义:端到端响应式=流式输出+响应式编程。
二 流式输出理论基础
是什么基础技术理论,支撑我们能够像上述流程那样对数据进行流式输出和接收,下面有几个核心的技术点:
1 HTTP分块传输协议
分块传输编码(Chunked transfer encoding)是超文本传输协议(HTTP)中的一种数据传输机制,允许HTTP由网页服务器发送给客户端应用( 通常是网页浏览器)的数据可以分成多个部分。分块传输编码只在HTTP协议1.1版本(HTTP/1.1)中提供。
如果需要使用分块传输编码的响应格式,我们需要在HTTP响应中设置响应头Transfer-Encoding: chunked。它的具体传输格式是这样的(注意HTTP响应中换行符是\r\n):
HTTP/1.1 200 OK\r\n
\r\n
Transfer-Encoding: chunked\r\n
...\r\n
\r\n
<chunked 1 length>\r\n
<chunked 1 content>\r\n
<chunked 2 length>\r\n
<chunked 2 content>\r\n
...\r\n
0\r\n
\r\n
\r\n具体流程见流式输出名词理解部分,分块传输编码例子:
func handleChunkedHttpResp(conn net.Conn) {
buffer := make([]byte, 1024)
n, err := conn.Read(buffer)
if err != nil {
log.Fatalln(err)
}
fmt.Println(n, string(buffer))
conn.Write([]byte("HTTP/1.1 200 OK\r\n"))
conn.Write([]byte("Transfer-Encoding: chunked\r\n"))
conn.Write([]byte("\r\n"))
conn.Write([]byte("6\r\n"))
conn.Write([]byte("hello,\r\n"))
conn.Write([]byte("8\r\n"))
conn.Write([]byte("chunked!\r\n"))
conn.Write([]byte("0\r\n"))
conn.Write([]byte("\r\n"))
}这里需要注意的是HTTP分块传输对同步HTML输出比较适合(对于浏览器来讲),因为在很多web页面涉及SEO,SEO的TDK元素必须同步输出,所以这种方式比较适合,针对于JSON数据的流式输出通过SSE来实现,具体如下。
2 HTTP SSE协议
sse(Server Send Events)是HTTP的标准协议,是服务端向客户端发送事件流式的方式。在客户端中为一些事件类型绑定监听函数,从而做业务逻辑处理。这里要注意的是SEE是单向的,只能服务器向客户端发送事件流,具体流程如下:

SSE协议中约束了下面几个字段类型
1)event
事件类型。如果指定了该字段,则在客户端接收到该条消息时,会在当前的EventSource对象上触发一个事件,事件类型就是该字段的字段值,你可以使用addEventListener()方法在当前EventSource对象上监听任意类型的命名事件,如果该条消息没有event字段,则会触发onmessage属性上的事件处理函数。
2)data
消息的数据字段。如果该条消息包含多个data字段,则客户端会用换行符把它们连接成一个字符串来作为字段值。
3)id
事件ID,会成为当前EventSource对象的内部属性"最后一个事件ID"的属性值。
4)retry
一个整数值,指定了重新连接的时间(单位为毫秒),如果该字段值不是整数,则会被忽略。
客户端代码示例
// 客户端初始化事件源
const evtSource = new EventSource("//api.example.com/ssedemo.php", { withCredentials: true } );
// 对 message 事件添加一个处理函数开始监听从服务器发出的消息
evtSource.onmessage = function(event) {
const newElement = document.createElement("li");
const eventList = document.getElementById("list");
newElement.innerHTML = "message: " + event.data;
eventList.appendChild(newElement);
}服务器代码示例
date_default_timezone_set("America/New_York");
header("Cache-Control: no-cache");
header("Content-Type: text/event-stream");
$counter = rand(1, 10);
while (true) {
// Every second, send a "ping" event.
echo "event: ping\n";
$curDate = date(DATE_ISO8601);
echo 'data: {"time": "' . $curDate . '"}';
echo "\n\n";
// Send a simple message at random intervals.
$counter--;
if (!$counter) {
echo 'data: This is a message at time ' . $curDate . "\n\n";
$counter = rand(1, 10);
}
ob_end_flush();
flush();
sleep(1);
}效果示例
event: userconnect
data: {"username": "bobby", "time": "02:33:48"}
event: usermessage
data: {"username": "bobby", "time": "02:34:11", "text": "Hi everyone."}
event: userdisconnect
data: {"username": "bobby", "time": "02:34:23"}
event: usermessage
data: {"username": "sean", "time": "02:34:36", "text": "Bye, bobby."}这里需要注意下,在未通过http2使用SSE时,SSE会收到最大连接数限制,此时默认的最大连接数只有6,即同一时间只能建立6个SSE连接,不过这里的限制是对同域名的,跨域的域名可以再建立6个SSE连接。通过HTTP2使用SSE时默认的最大连接数是100。
目前SSE已集成到spring5,Springboot2的webflux其实就是通过SSE的方式进行数据的流式输出。
3 WebSocket
Websocket就比较老生常谈了,这里主要介绍下它与SSE的区别:
- Websocket是区别于HTTP的另外一种协议,是全双工通信,协议相对来说比较中,对代码侵入度比较高。
- SSE是标准的HTTP协议,是半双工通信,支持断线重连和自定义事件和数据类型,相对轻便灵活。
4 RSocket
在微服务架构中,不同服务之间通过应用协议进行数据传输。典型的传输方式包括基于 HTTP 协议的 REST 或 SOAP API 和基于 TCP 字节流的 RPC 等。但是对于HTTP只支持请求响应模式,如果客户端需要获取最新的推送消息,就必须使用轮询,这无疑造成了大量的资源浪费。再者如果某个请求的响应时间过长,会阻塞之后的其他请求的处理;虽然服务器发送事件(Server-Sent Events,SSE)可以用来推送消息,不过 SSE 是一个简单的文本协议,仅提供有限的功能;而WebSocket 可以进行双向数据传输,不过它没有提供应用层协议支持,Rsocket很好的解决了已有协议面临的各种问题。

Rsocket是一个面向反应式应用程序的新型应用网络协议,它工作在网络七层模型中 5/6 层的协议,是 TCP/IP 之上的应用层协议,RSocket 可以使用不同的底层传输层,包括 TCP、WebSocket 和 Aeron。TCP 适用于分布式系统的各个组件之间交互,WebSocket 适用于浏览器和服务器之间的交互,Aeron 是基于 UDP 协议的传输方式,这就保证了 RSocket 可以适应于不同的场景,见上图。然后RSocket 使用二进制格式,保证了传输的高效,节省带宽。而且,通过基于反应式流控保证了消息传输中的双方不会因为请求的压力过大而崩溃。更多详细资料请移步RSocket[1]。雷卷也开源了alibaba-rsocket-broker[2],感兴趣可以去深入了解请教。
Rsocket提供了四种不同的交互模式满足所有场景:

RSocket 提供了不同语言的实现,包括Java、Kotlin、JavaScript、Go、.NET和C++ 等,如下为仅供学习了解的简单Java实现:
import io.rsocket.AbstractRSocket;
import io.rsocket.Payload;
import io.rsocket.RSocket;
import io.rsocket.RSocketFactory;
import io.rsocket.transport.netty.client.TcpClientTransport;
import io.rsocket.transport.netty.server.TcpServerTransport;
import io.rsocket.util.DefaultPayload;
import reactor.core.publisher.Mono;
public class RequestResponseExample {
public static void main(String[] args) {
RSocketFactory.receive()
.acceptor(((setup, sendingSocket) -> Mono.just(
new AbstractRSocket() {
@Override
public Mono<Payload> requestResponse(Payload payload) {
return Mono.just(DefaultPayload.create("ECHO >> " + payload.getDataUtf8()));
}
}
)))
.transport(TcpServerTransport.create("localhost", 7000)) //指定传输层实现
.start() //启动服务器
.subscribe();
RSocket socket = RSocketFactory.connect()
.transport(TcpClientTransport.create("localhost", 7000)) //指定传输层实现
.start() //启动客户端
.block();
socket.requestResponse(DefaultPayload.create("hello"))
.map(Payload::getDataUtf8)
.doOnNext(System.out::println)
.block();
socket.dispose();
}
}5 响应式编程框架
如果要在全链路实现响应式,那响应式编程框架是支撑这个技术的核心技术,这对于开发者来说是一种编程模式的变革,通过使用异步数据流进行编程对于原流程化的编程模式来说变化还很大。
简单示例如下:
@Override
public Single<Integer> remaining() {
return Flowable.fromIterable(LotteryEnum.EFFECTIVE_LOTTERY_TYPE_LIST)
.flatMap(lotteryType -> tairMCReactive.get(generateLotteryKey(lotteryType)))
.filter(Result::isSuccess)
.filter(result -> !ResultCode.DATANOTEXSITS.equals(result.getRc()))
.map(result -> (Integer) result.getValue().getValue())
.reduce((acc, lotteryRemaining) -> acc + lotteryRemaining)
.toSingle(0);
}总的来说通过HTTP分块传输协议和HTTP SSE协议以及RSocket我们可以实现流式输出,通过流式输出和响应式编程端到端的响应式才得以实现。
三 流式输出应用场景
性能、体验和数据是我们日常工作中抓的最紧的三件事情。对于性能来说也一直是我们追求极致和永无止境的核心点,流式输出也是在解决性能体验这个问题而诞生,那是不是所有的场景都适合流式输出呢?当然不是,我们来康康哪些场景适合?

以上为Resource Timing API规范提供的请求生命周期包含的主要阶段,通过上述来看下一下几个场景对于请求生命周期的影响。
1 页面流式输出场景
对于动态页面来说(相对于静态页面)主要由页面样式、页面交互的JS以及页面的动态数据构成,除了上述请求生命周期的各阶段耗时,还有页面渲染耗时阶段。浏览器拿到HTML会先进行DOM树构建、预加载扫描器、CSSOM树构建,Javascript编译执行,在过程中CSS文件的加载和JS文件的加载阻塞页面渲染过程。如果我们将页面按照以下方式进行拆分进行流式输出将会在性能上有很大的收益。
单接口动态页面
对于某些场景比如SEO,页面需要同步渲染输出,此时页面通常是单接口动态页面,就可以将页面拆分成body以上部分和body以下的部分,例如:
<!-- 模块1 -->
<html>
<head>
<meta />
<link />
<style></style>
<script src=""></script>
</head>
<body>
<!-- 模块2 -->
<div>xxx</div>
<div>yyy</div>
<div>zzz</div>
</body>
</html>当模块1到达页面模块2未到达时,模块1渲染后在等待模块2到来的同时可以进行CSS和JS的加载,在几个方面进行了性能提升:
- 到达浏览器的首字节时间(TTFB)
- 数据包到达浏览器下载HTML的时间
- CSS和JS的加载及执行时间
- 拆成模块之后网络传输的时间会有一定的降低
单接口多楼层页面
<!-- 模块1 -->
<html>
<head>
<meta />
<link />
<style></style>
<script src=""></script>
</head>
<body>
<!-- 模块2 -->
<div>xxx1</div>
<div>yyy1</div>
<div>zzz1</div>
<!-- 模块3 -->
<div>xxx2</div>
<div>yyy2</div>
<div>zzz2</div>
<!-- 模块4 -->
<div>xxx3</div>
<div>yyy3</div>
<div>zzz3</div>
</body>
</html>很多场景是一个页面展现多个楼层、譬如首页的四大金刚以及各种导购楼层,detail的信息楼层等等,甚至后面楼层依赖前面楼层的数据,类似这种情况可以将页面楼层拆分成多个模块进行输出,在上述几个方面进行了性能提升之外还有额外的性能提升:楼层之间数据相互依赖的数据处理时间。
多接口多楼层页面
一般情况下大部分页面都是由同步SSR渲染和异步CSR渲染进行,这时会涉及到JS异步加载异步楼层,如果同步渲染部分按照单接口多楼层进行拆分会在上述基础上提前加载运行异步楼层的渲染。
总的来说基于HTTP分块传输协议的流式输出几乎覆盖所有页面场景,供所有页面提升性能体验。
2 数据流式输出场景
单接口大数据
对于APP或者单页面系统更多的是通过异步加载数据的方式进行页面渲染,单个接口会造成单个接口的RT时间较长,以及数据包体太大导致在网络中拆包粘包的损耗较大。如果通过多个异步接口会因网络带宽受限而导致数据请求的延时较高以及网络IO的带来的CPU占有率较高,因此可以通过业务场景进行分析将单接口拆分成多个相互独立或者有一定耦合关系的业务模块,将这些模块的数据进行流式输出,以此带来以下性能体验上的提升。
- 到达浏览器的首字节时间(TTFB)
- 数据包到达端侧下载数据的时间
- 数据在网络传输的时间
多相互依赖接口
但是在大部分场景中我们遇到的业务场景是相互耦合关联的,比方说榜单模块数据依赖它上面的新品模块的数据进行业务逻辑处理,这种情况在服务器侧处理完新品模块数据后对数据进行输出,再接着处理榜单模块数据进行输出,这里接节省了相互依赖等待的时间。
当然日常的业务场景会相对复杂的多,但是通过流式输出都会页面性能和体验会有很大的提升和助力。
四 小结
- 流式输出的前世为流式渲染,今生为端到端的响应式,这些虽然带来了性能体验上的提升,但对研发模式变革的接受程度和运维成本的增加需要加以权衡。
- 简单介绍了几种流式输出的技术方案,适合不同的业务场景。
- 提出了流式输出适合的几种场景,以及对页面和数据进行拆分的方法。
相关链接
[1]https://rsocket.io/
[2]https://github.com/alibaba/alibaba-rsocket-broker

 浙公网安备 33010602011771号
浙公网安备 33010602011771号