深入浅出SQL优化器原理
深入浅出SQL优化器原理 https://mp.weixin.qq.com/s/u7waqx0JhFnrg8I6TJEHDQ
深入浅出SQL优化器原理

摘要
SQL优化器是数据库、数据仓库、大数据等相关领域中最复杂的内核模块之一,它是影响查询性能的关键因素。比如大家熟知的开源产品 MySQL、PostgreSQL、Greenplum DB、Hive、Spark、Presto,都有自己的优化器。本文将由浅入深地带读者了解其中技术原理。
1.起源
1979年,第一款基于 SQL 的商业关系型数据库管理系统 Oracle V2 问世,也标志着第一款商用的 SQL 优化器诞生。理论上,成熟的优化器原型,更早可以追溯到 IBM 的 System-R 项目。现今,很多开源数据库和大数据优化器还是沿用 System-R 原型。
2.从一条SQL开始
SQL(Structured Query Language)是一种结构化的查询语言。它只描述了用户需要什么样的数据,而没有告诉数据库该如何执行。这使得有很多优化空间蕴含在 SQL 改写中,我们来看一个简单的例子:这个查询有两种执行方式。第一种,就是直接按用户写的顺序去执行。先做一个 INNER JOIN 运算,然后进行过滤(只保留五年级学生),最后再对过滤后的数据进行聚合运算(求平均)。第二种,对SQL进行适当的改写后再执行,如下:/* 查询五年级学生的平均年龄 */SELECT avg(s.age)FROM students sJOIN classes c ON s.cls_id = c.idWHERE c.grade = 5
SELECT avg(s.age)FROM students sJOIN (SELECT idFROM classesWHERE grade = 5 /* 下推过滤条件 */) cON s.cls_id = c.id
改写后的 SQL,在 INNER JOIN 运算前就完成了过滤运算。这样参与 JOIN 运算的数据量会更少,查询效率也会更快。这个改写是等价的,因为 JOIN 后的结果只保留五年级的数据,那非五年级的数据是没有必要参与 JOIN 运算的。优化器主要工作就是在保证等价的前提下,尽可能让查询更快执行。它的主要流程如下:
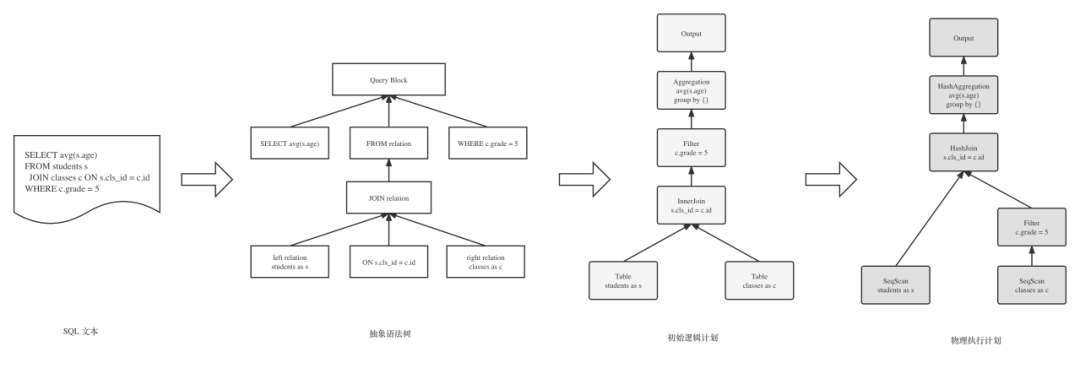 优化器将抽象语法树(Abstract Syntax Tree)先转换为初始的逻辑计划(Logical Plan),一般这个过程中会同时进行基本的检查工作,比如:表存不存在、权限够不够等。逻辑计划经过一系列等价改写,并选择每个算子该如何执行(算子实现可能多种多样),最终得到一个可执行的物理计划(Physical Plan)。到此,优化器的核心工作基本就完成了。优化器中最关键的部分就是从逻辑到物理的过程,下面深入到其中的细节来看下。
优化器将抽象语法树(Abstract Syntax Tree)先转换为初始的逻辑计划(Logical Plan),一般这个过程中会同时进行基本的检查工作,比如:表存不存在、权限够不够等。逻辑计划经过一系列等价改写,并选择每个算子该如何执行(算子实现可能多种多样),最终得到一个可执行的物理计划(Physical Plan)。到此,优化器的核心工作基本就完成了。优化器中最关键的部分就是从逻辑到物理的过程,下面深入到其中的细节来看下。
3.基本优化原理
3.1 基于规则的优化
RBO(Rule-Based Optimizer),优化器中有很大一部分工作是基于规则进行的。简单的说,就是我认为什么样的形式是更优的,我就把 SQL 改写成什么样。比如,上文提到的下推过滤条件,就是一种规则。这类优化有很多,下推、裁剪、简化表达式、解关联等。还可以利用隐藏在 SQL 中的信息,做更深层次的优化。
/* 查询第一个班级学生的平均年龄 */SELECT avg(s.age)FROM students sJOIN classes c ON s.cls_id = c.idWHERE c.id = 1
这个查询我们除了将过滤条件下推外,还可以为 students 表生成一个条件 s.cls_id = 1,因为通过 JOIN 条件,我们知道 s.cls_id 等价于 c.id。这样又可以更早地过滤掉一部分数据,减少 JOIN 运算量。最终改写后 SQL 如下:
SELECT avg(s.age)FROM (SELECT age, cls_idFROM studentsWHERE cls_id = 1 /* 根据等价关系生成的条件 */) sJOIN (SELECT idFROM classesWHERE id = 1 /* 下推过滤条件 */) cON s.cls_id = c.id
相信你一定发现了改写后的SQL仍然不是最优的,因为两张表输出的数据一定能跟另一边完全 JOIN 上。所以 INNER JOIN 条件s.cls_id = c.id产生的查找计算量,以及不需要输出的列都可以进一步省去。这个改写是等价的,如果有一边查询不出数据,那也正好 JOIN 不出结果。
SELECT avg(s.age)FROM (SELECT ageFROM studentsWHERE cls_id = 1) sJOIN (SELECT NULLFROM classesWHERE id = 1) c
到这里,相信你已经对 SQL 优化有了一些基本的感觉。但是这里有一个容易被忽视的问题,就是这两张表进行 JOIN 的时候,到底谁在左,谁在右?
一般来说,我们 INNER JOIN 的实现会有 HASH JOIN。JOIN 右端数据用来构建 HashSet,左端数据用来查找 HashSet,能查到说明这行能匹配上,那这行就需要输出。毋庸置疑,大家一定会把 classes 表放右边。因为 classes 表显然更小,这样 HashSet 构建效率高,占用内存少,查询效率也更快。
但优化器并不知道 students 和 classes 的业务关系,也并不知道它们之间的数据量有数量级的差距。这个时候基于代价的优化就派上用场了。
3.2 基于代价的优化
CBO(Cost-Based Optimizer),SQL优化中大部分收益是来自 CBO 的优化。因为很多很有效的优化手段是没法 100% 确定有收益的,这个时候就需要通过估计执行代价来评估。优化器中 CBO 是标配,不同产品之间,只是实现程度深浅的问题。CBO 中一个很核心的问题,就是怎么估算。这个问题,十几年前就已经研究很透彻了,在商业数据库上也都有成熟的应用。但估算并不是100%准确的,这是一直无法彻底解决的问题。所以现代优化器的很多研究方向是围绕估不准的问题进行,衍生出很多技术方案。
回到上面那个例子,优化器如何知道两张表经过过滤条件后分别剩下多少行呢?这里需要引入统计信息(Statistics)概念。统计信息是事先对表里的数据进行分析,收集到的信息。大部分数据库都是支持手动执行 ANALYZE 命令来收集。像 AnalyticDB 这类商业数据仓库产品,一般都支持自动收集。
这个例子要用到的统计信息是 NDV (The Number of Distinct Values),然后还有一个均匀假设(Uniformity Assumption)。假设学生有1000人,班级有5个,班级人数均匀分布。
那么, 。估算结果:
-
s.cls_id = 1 这个条件的估计结果为
-
c.id = 1这个条件的估计结果为
3.2.1 直方图
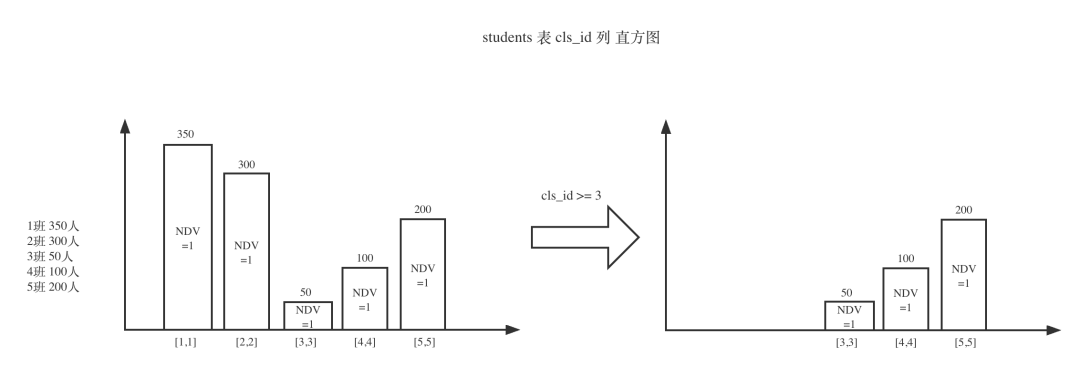
直方图(Histogram)基本是商业数仓必备的能力。有些开源数仓产品也有,但是实现程度上不是很完备。比如,只能用直方图估计 filter,而无法估计 join。直方图一般分为等宽和等高,等高应用等会比较多些,因为能更好应对极值。
上图这个查询条件,如果只使用基本的统计信息(Min=1,Max=5,NDV=5),估计结果为:,严重高估,误差达 71%。使用直方图,估计结果为 350,是完全准确的。这个例子略特殊,因为每种值都用一个桶来描述,所以估计解决肯定是绝对准确的。实际运用中,我们不可能为每种值都建立一个桶(精准直方图),一般会限制桶的数量来减少直方图计算开销和存储开销。这时候多种值会被划入一个桶,划分的方式就是前面提到的等宽与等高。这样的直方图会相对模糊一些,因为每个桶内每种值的具体细节是不清楚的。一般100~300个桶,就能比较好的在估算误差和开销之间权衡了。
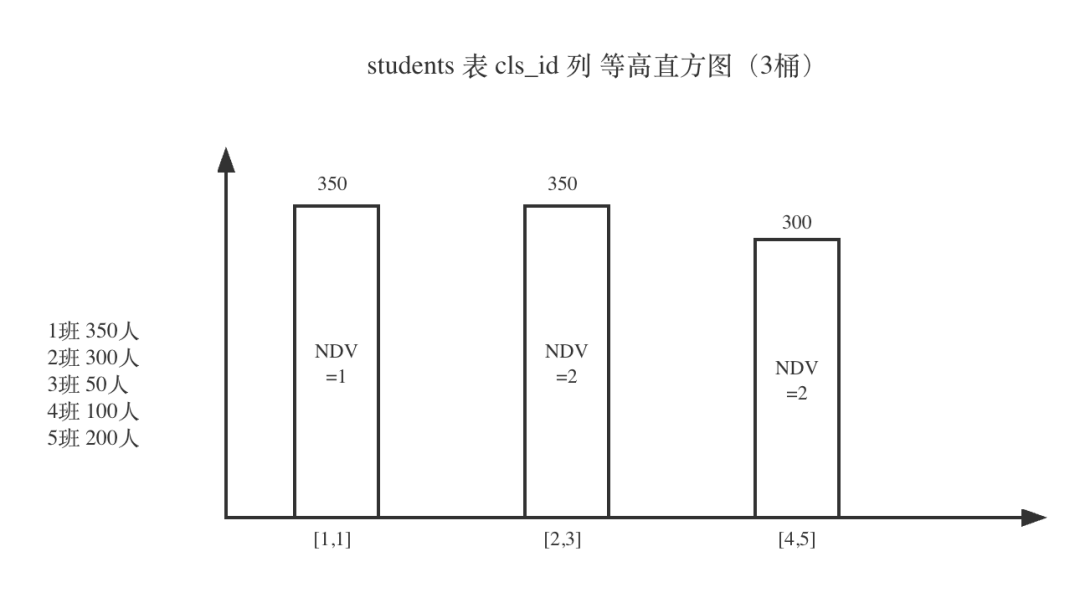
在 AnalyticDB 中会自动识别,选择要建立怎样的直方图。对于上述这种 NDV 很小的情况,建立精准直方图就再合适不过了。即便不建立精准直方图,AnalyticDB 也会识别一些热点值,让它们单独一个桶,以增加估算精度。
3.2.2 低估误差上面简单说了行数怎么估计的,实际中还需要估计范围,NDV等信息的变化,经过每个算子后。这个一般由优化器中叫 Cardinality Estimation (CE) 的模块负责。除此以外,还需要根据CE提供的信息+Cost Model,估计每个算子的代价(CPU/IO/MEM/NET),因为实际的过程并不是简单判定JOIN左右顺序这么简单。JOIN 顺序的可能是阶乘级别的,不同顺序对每个算子的计算量都有影响,不同算子处理同样行数的数据量又是不同的开销。所以,最终优化器需要选出总代价最低的计划,代价估算也是优化器中较复杂的技术之一。
看起来选择代价最低的计划是非常正确的思路,但是这一系列复杂操作下来,有些时候并不一定能选到最优计划。因为代估会有误差,误差大多数来自 CE 模块。导致误差的具体原因,通常是这几个方面:
1.估算能力不足,比如不支持直方图,那就不能有效应对非均匀数据。2.统计信息本身有误差,收集时候使用了近似算法,以及信息的时效性导致。3.列与列之间有一定联系,这层联系不得而知,影响估计结果。4.累积误差,经过每个算子后,推导出的统计信息存在误差,这些误差会层层累积。5.确实难以估计的表达式,比如没有常量前缀的 LIKE 表达式。
虽然有误差,但是误差并不一定会影响计划选择,否则这套理论就不可能成熟应用了。就上面的例子而言,两张表数据量差距本身就很大,即使不引入直方图做相对准确的估计,在误差范围内,他们相对的大小还是稳定的。
不管怎么说,肯定是估计越准越好,解决上述问题的方案也有很多。比如,AnalyticDB 会自动分析 SQL 复杂程度,决定是否对复杂的 filter 进行动态采样,以提高计划质量。同时还有一些运行态自动调整计划的技术(Adaptive Query Processing),可以纠正计划。即便像 JOIN 这种比较难估准的算子,除了传统技术,业界也有一些理论可以利用,来提高估算精度。比如,利用 Wander Join (采样近似计算)来估计 JOIN 中间结果。
3.3 搜索框架
上文提到,我们要选出代价最低的计划。这里就涉及到怎么高效率找出所有可能的计划,并选出代价最低的。最经典的方案是 System-R 风格,也是现在很多开源数据库还在用的方案。该方案主要以 RBO + cost-based join reorder (bottom-up DP) 为主,优点就是简单高效,像 MySQL 这种 OLTP 数据库就采用的这种方案。缺点就是容易陷入局部最优,而非全局最优。比如 join order 的变化,可能会影响 shuffle 的数据量,这些因素都需要混在一起搜索,才可能找到全局最优。商业数据库/数仓和开源产品,基本或多或少是参考 Cascades 理论构建的搜索框架。比如,大家熟知的 SQLServer、Snowflake、GreenplumDB 和 Calcite。Cascades 是目前最成熟的理论,AnalyticDB 的 CBO 也是以该理论为基础来构建的搜索框架。Cascades 跟传统的框架比,主要有这么几个优势:- 搜索方向从 bottom-up 变成 top-down,有更多裁剪机会,效率更高
- 分层搜索(先搜逻辑再搜物理)到统一搜索(逻辑和物理混着一起搜),能更早触发裁剪,效率高
-
框架对优化器工作进行高度抽象后,可并行搜索,扩展性也更强
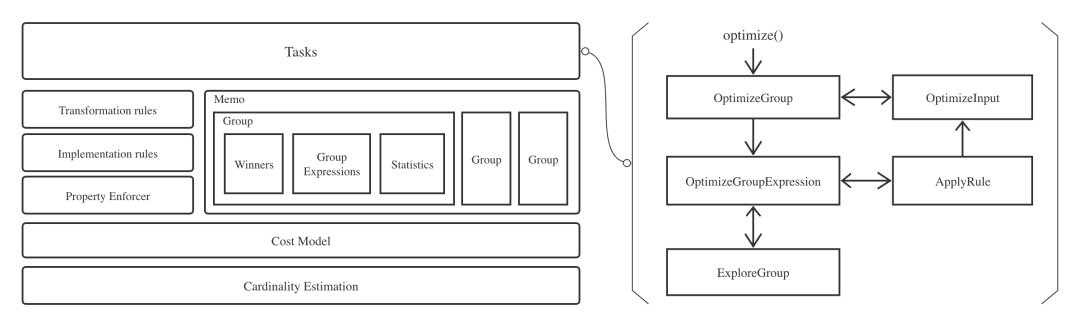
整个 Cascades 工作原理其实就是一个树型 DP (Dynamic Programing),通过记忆化搜索(Memorization Search)方式从上至下(top-down)推进。每个模块工作原理大致如下:
3.3.1 ExpressionExpression 就是算子表达式,比如 JOIN 是一种 Expression,Fillter 是一种 Expression。Expression 的子节点也是 Expression,它们连在一起就形成了计划树。Expression 可以是逻辑的,也可以是物理的。
3.3.2 GroupExpressionGroupExpression 和 Expression 类似,只不过它的子节点是 Group。这样更加抽象,抽象的目的是为了减少表达式数量,如果子节点有10种等价的表示,不需要衍生出10个表达式对象。同样,GroupExpression 有逻辑和物理之分。下文无特殊说明,表达式一般指 GroupExpression。
3.3.3 GroupGroup 就是计划树中的一个点,用来归纳重复的信息到一起,以提升效率。主要包含:1)等价的 GroupExpression,有逻辑也有物理。生成的等价的表达式会被放入同一个 Group。2)一些 Group 逻辑属性:输出的统计信息,代价下限,输出的属性信息(unique, function dependency, ...)3)对于特定请求,已经搜出的最优解(winner),也就是 DP 中某个状态的最优结果。
3.3.4 WinnerWinner 存储了特定请求的最优解,这也是记忆化搜索的体现。这个请求指代的是父节点对子节点的属性要求,比如要求子节点给出“按 (A, B) 两列分布”的最优解。
3.3.5 PropertyEnforcer当子节点无法满足父节点属性要求时,需要强行插入一个算子来满足要求。这个就是 enforcer 干的事,由它来决定具体插入一个怎样的算子以满足属性要求。属性主要包括,分布属性,排序属性等等。
3.3.6 MemoMemo 就是搜索空间,用来存储 Group。当我们生成新的表达式后,都需要去 Memo 中查找是否有一样或者等价的表达式存在,如果有,需要放入同样的 Group。
3.3.7 RULE规则分为两类:● Transformation rules:负责把逻辑表达式转换为等价的逻辑表达式,这步会产生新的逻辑表达式。
● Implementation rules:负责把逻辑表达式转换为物理表达式,这步会产生新的物理表达式。比如 JOIN 的实现可以是 Hash Join,也可以是 Nested Loop Join。
3.3.8 TASK驱动上面这些东西运转的就是各种 Task,这些 Task 本质上是对递归遍历树的过程的一个抽象(递归->手工栈)。使得搜索流程更加独立,更好扩展,并且具备并行执行的能力。
OptimizeGroupOptimizeGroup 对特定 Group 发起特定请求,是每个 Group 优化的入口。这步会逐一遍历 Group 内所有 GroupExpression,逻辑表达式会调用 OptimizeGroupExpression,物理表达式会调用 OptimizeInput 。OptimizeInput 会更先运行,目的是为了更快生产一个物化后的计划,使得获得一个代价上界,用来压缩后续搜索空间。
OptimizeGroupExpressionOptimizeGroupExpression 对特定逻辑表达式进行优化。主要就是应用 transformation 和 implementation 两种规则。对每条可以应用的规则,会调用 ApplyRule。特别的,有时只会应用 transformation 规则,取决于 OptimizeGroupExpression 被调用的场景。由于不同规则需要匹配的 pattern 不同,可能需要继续探索子 Group,才能知道是否有满足 pattern。所以在调用 ApplyRule 之前,如果有必要,会调用 ExploreGroup 来探索子 Group。
ExploreGroupExploreGroup 被 OptimizeGroupExpression 调用。是为了探索 Group 内可能生成的所有等价逻辑表达式,为 ApplyRule 做准备。探索过程就是对 Group 内的所有逻辑表达式应用可以应用的 transformation 规则。这个过程复用 OptimizeGroupExpression 代码,控制只应用 transformation 规则,所以会调用 OptimizeGroupExpression。
ApplyRuleApplyRule 输入是逻辑表达式和规则。根据规则类型不同,最终会得到新的逻辑或者物理表达式。如果生成了物理表达式,会直接调用 OptimizeInput。如果生成了逻辑,会调用 OptimizeGroupExpression。
OptimizeInputOptimizeInput 输入是一个物理表达式和属性要求。OptimizeInput 会根据物理表达式和属性要求,生成对其子 Group 的请求,然后向所有子 Group 发起 OptimizeGroup 请求,子 Group 最终返回满足要求的最优结果 winner。根据这些 winner 的 cost + 当前物理表达式的 cost,就得到了以这个物理表达式为根的子树的 cost。如果最终这个物理表达式无法满足父节点的属性要求,那就需要 PropertyEnforcer 介入,强制插入特定表达式以满足需求。
3.3.9 分支裁剪裁剪是怎么发生的呢?当向子 Group 请求的过程中,不断收集到 winner,如果当前累加的 cost 已经超过上界,那么可以直接停止搜索。上界怎么来的呢?一开始是无穷大,随着第一个物理表达式满足了父节点的要求,会得到一个 cost,被当作初始的上界,并通过请求上下文带给其它任务(不同请求上下文是分开的,上界也是独立的)。一个 Group 内可能有很多物理表达式都可以等价满足要求,每个物理表达式最终都会被调用 OptimizeInput 任务。在这个过程中,有些物理表达式能做到更低的 cost,那么上下文中的上界就会被压缩。有些不能满足上界要求,搜索会直接停止。这个就是上界裁剪,用来减少搜索空间,提高效率。
在上界裁剪的基础上,还有下界裁剪。前面我们提到 OptimizeInput 输入是一个物理表达式,我们对所有子 Group 调用 OptimizeGroup。这个过程中,子 Group 所有可能被探索,最终最低代价的表达式作为 winner 返回。如果探索到某一子 Group 时候,cost 已经超过上界了,那么上界裁剪发生,直接停止后续任何搜索任务。有没有可能我不去探索子 Group,我直接就能知道将来的 cost 一定会超过上界呢?
这个就是下界裁剪,需要根据 cost model + 逻辑属性,直接确定一个 Group 的最小开销(下界)。将来任何可能计算出来的开销都会大于等于这个开销,记为 Group.costLowerBound。如果 sum(subGroup.costLowerBound) + GroupExpression.cost > upper bound成立,那根本不需要对子 Group 进行任何探索,直接就可以停了。
这些裁剪技术都是很有效的,在 AnalyticDB 中都有应用。经过我们测试,在 TPC-DS 中,大部分查询搜索空间都有减少,有些甚至可以减少近 50% 的搜索空间。4.结语
在数据库和大数据等相关领域,查询优化十分重要。实际生产中的问题,远比本文提到的要复杂。篇幅有限,更多技术细节没有深究。AnalyticDB 作为国内领先的云原生数仓和 TPC-DS 世界记录保持者,在查询优化技术上不断投入和创新。对技术感兴趣的同学,欢迎加入 AnalyticDB 社区讨论(云数据仓库ADB-开发者群:钉钉群号 23128105)云原生数据仓库 AnalyticDB MySQL 版(简称 AnalyticDB)是一种支持高并发低延时查询的新一代云原生数据仓库,高度兼容MySQL协议以及SQL标准,可以对海量数据进行即时的多维分析透视和业务探索,快速构建企业云上数据仓库。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号