商家反馈算法
小结:
1、
建设商家反馈工作台,目标是构建体验分析反馈产品,能够识别集中性的突出问题,并形成采集-识别-跟踪-评估的体验治理闭环,各产品反馈达成数据能进来(统一标准)、 能分发到人(精准)、 能高效处理(闭环处理),能反馈回去(触达客户)的效果。
商家反馈算法 https://mp.weixin.qq.com/s/qNcxGpYxyWIa-6lR38Boqw
商家反馈算法
背景
商家反馈
当商户使用具体商家产品时,遇到问题/槽点/阻塞时,会通过很多渠道进行反馈。根据紧急程度、场景、产品载体、商户类型的不同,反馈的渠道以及形式均不同。通过不同渠道进入的反馈数据,落地不同结构化形式的数据,渠道同学需要分别分析问题,并联系责任人去做问题解决推动。上述过程存在如下痛点:
1、多渠道反馈数据多,散点式解决问题,耗费人力多但价值不明确
体验问题突出,反馈渠道多,数据量大,处理问题耗费人力多但价值不明确,或不被PD认可,影响到PD们处理的积极性。需要对繁多的来源于不同渠道的反馈问题做理解和提取,对全局核心问题,重点解决。
2、反馈问题的分发、跟踪、处理和流转机制不健全,反馈问题处理效率低
每个渠道各有问题检测和反馈业务线处理的通道,解决率情况依赖渠道的人线下逐个追作业,缺少整体对商家反馈问题的处理机制和要求,更加缺少过程和结果的度量牵引,不能形成产技处理问题的良性氛围,处理效率极度依赖人肉推进,整体解决率低。
由此可见,商家产品在多渠道各自闭环单点解决问题的被动式解决问题的现状下,投入多&效率低、目标价值不明确,亟需拉平各方,建立能力与机制让产品负责人更高效地解决客户反馈问题,快速分发、触达与度量 ,从整体上去提升问题解决率与效率,提升客户体验。
整体方案
建设商家反馈工作台,目标是构建体验分析反馈产品,能够识别集中性的突出问题,并形成采集-识别-跟踪-评估的体验治理闭环,各产品反馈达成数据能进来(统一标准)、 能分发到人(精准)、 能高效处理(闭环处理),能反馈回去(触达客户)的效果。
商家反馈工作台的核心模块和分别解决的问题如下:
1、反馈数据标准化
开发者、服务商、商家反馈渠道多, 各渠道有自身数据处理闭环机制,各自推进处理,解决效率低,因此需要统一对接各个反馈渠道,方便后续处理流程的统一。
2、反馈数据理解
反馈渠道各自问题推送问题到产品PD或技术侧解决,应接不暇。在这个过程中,PD要面对的核心痛点包括:问题太多不知道优先解决哪个/解决之后的价值不明确/不是我该处理的问题,由于这些痛点的存在,高优先级、共性更强、更加重要的问题不容易显露出来,错误推送的问题容易直接被忽略,无法触达正确的负责人,直接造成了体验问题解决效率低。这都是因为缺少统一对问题归属分发的机制,和优先处理的建议引导机制。
3、反馈工作台
反馈问题在多渠道分别处理,由渠道各自牵引解决,PD/技术需要对接各平台分别去处理反馈问题,比较散且耗费精力,如果能够把产品上对应反馈问题放到一起评估优先级,集中处理,不用跳转各渠道平台,可以大大提升处理效率。
反馈理解-算法部分
为了解决如上业务问题,对于反馈理解的算法部分,建设重点在于:基于对商家产品的深入理解,建立问题分类模型、优先级模型,实现问题的精准分发和优先处理能力。
具体而言,由于业务要求的变化与业务认识的提升,去年所建设的商家反馈平台已经无法满足业务的需求,因此今年对于商家反馈平台数据算法侧进行了一轮彻底的改造和迭代。相较于去年将主要精力放在了问题内容标签分类识别上,新版的商家反馈平台以建立解决问题的闭环流程为首要目标,将用户反馈的问题进行整理,随后有针对性地、准确地推送给具体的负责人。所以新版算法部分的建设,在进行问题内容分类的基础上,要着力实现以下目标:
1.构建有实践意义的商家产品树,产品树上的每个节点有明确的负责人可以对接。建立算法能力,将具体的反馈问题精准分类到产品树上的具体节点,据此可以将用户反馈问题准确推送给可以解决问题的具体负责人。
2.用具有一定概括性的工单取代用户原声反馈信息,算法侧提供同义原声信息聚类能力,将语义基本完全相同的用户原声信息合并为一条工单,使得产品负责人无须自行分析归纳原声数据,帮助负责人将精力聚焦在问题改进上。
3.算法侧制定一套明确的问题优先级评估方案,为每条工单标记不同的优先级,支持工单分类分发,推动高优问题尽快解决。
解决方案及实现
针对上述业务目标,算法侧选取了四个重点方向,逐步解决在问题精准分发过程中的各类突出问题:
a.产品分类任务(产品分类+用户身份判别):这一部分的能力是反馈工作台精准分发问题的依据。尽可能降低产品分类的错误率,也就意味着降低最终问题分发的错误率;
b.问题分类任务(情感分类+内容话题分类+问题类型分类):这一部分的建设部分复用了去年的能力,目的是从多个维度综合评估反馈问题,输出多个标签对问题进行直观而简明扼要的注释,提升阅读效率;
c.优先级评估(严重度+情感+文本信息量评估打分+关联问题数量打分等):这一部分的能力将是反馈工作台分层分策略分发问题的依据,对于高优先级的问题采用更紧急的方法进行推送,对于低优先级的问题则采取缓和的方式推送或不推送。因此准确的优先级评估,能够使PD更有效地关注到重要而亟待解决的问题;
d.聚类(包括筛选历史生成工单与新数据进行合并聚类+新数据独立聚类+不同粒度聚类+信息整理合并输出):这一部分的能力可以尽量减少推送的工单出现重复,从而节省PD进行归纳整理的精力,提升处理问题效率。
其中第三部分的打分依据较为复杂,因此在实现上与第二部分、第四部分有所交叉。
而在总体流程中,产品精准分类与优先级评估两项任务,实现起来具有一定挑战,算法质量又与业务目标联系紧密、息息相关,因此被列为本期建设着力解决的难点。
反馈问题产品分类
算法分类方法
如果能够将反馈数据准确匹配到准确具体的产品概念上(如果用户反馈确实指向了具体产品的话),那么就建立了准确分发工单的基础。然而就实际现状来看,产品标签非常细致,内涵复杂,且在相当程度上会产生语义重叠,给分类任务提出了非常大的挑战。同时也缺乏可直接应用的数据集,必须从头构造。另外,在新版的平台功能上,产品分类并不意味着仅仅给一些反馈数据打上某一个参考标签——分类后的工单是要分门别类推送给对应的产品负责人的,如果分类错误,不仅对负责人造成了骚扰,也会导致问题无法被感知——因此这项业务对于产品分类的准确率要求非常高。
因此,为了更好地解这个问题,在实现上采取了一个类似于混合专家系统的树形结构,串联多级分类bert模型和关键词判别策略,同时增加了用户身份的预测模型和反馈内容的分类模型,辅助区分一些语义极为相近的产品(也用来淘汰与商家动线毫无关联的反馈信息)。这种结构,使得每一个bert模型仅仅从某一个具体而确定的角度学习语义之间的差异,从而获得一系列在某个具体问题上有更准确判别能力的专门模型,随后按照由多个决策树构成的结论统合模块将各个模型的结果整合起来。把各个子模型结果作为特征,由结论整合模块(类似于混合专家系统中的门控模块)进行再次分类,从而取众模型之长,确定最终的产品标签。
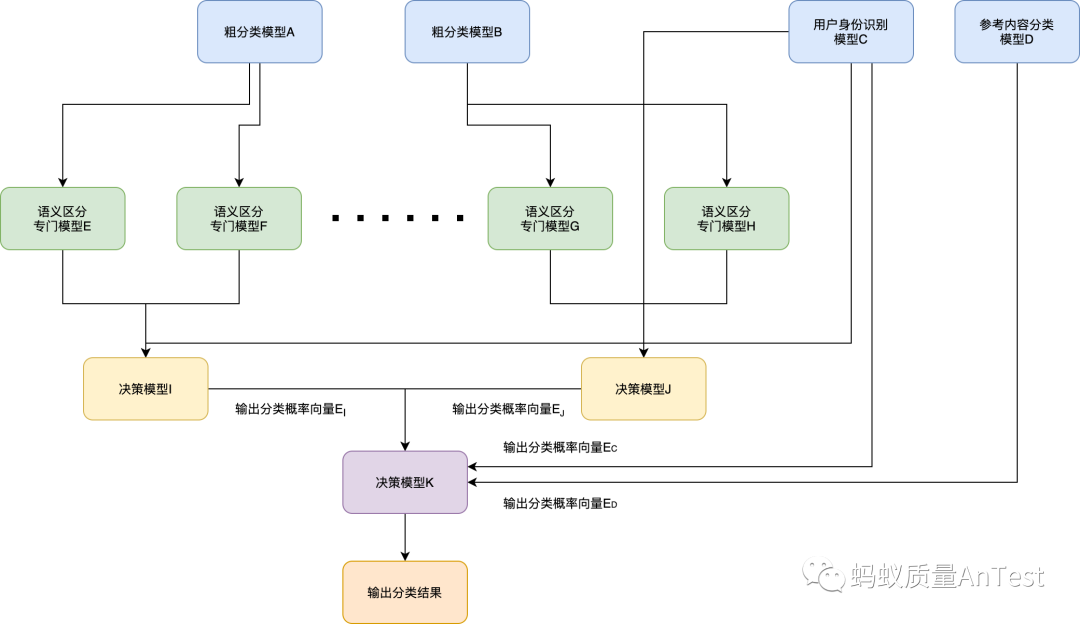
经过评估实际反馈数据上该模型输出的最终结果,发现在这项复杂困难的产品分类任务上,这种结构所获得的最终分类结果的准确率(如下图所示)可以达到0.95以上,是使用单个模型直接进行产品分类难以相比的。
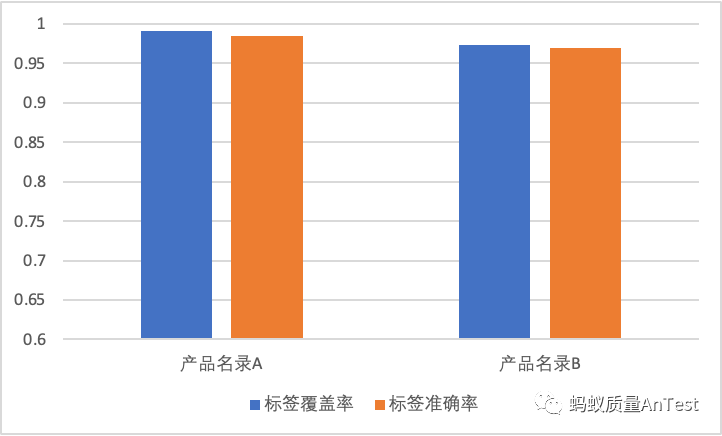
(注:这里标签覆盖率指的是反馈内容确实属于商家产品,应该拥有一个确切的商家产品标签的反馈数据,经算法流程后拥有对应产品分类标签的概率。非商家产品相关的反馈在流程中有专门的模型识别并剔除)
同时,这种树状结构、逐层细化分类的方式,也便于识别出那些未指明具体产品的反馈数据(比如很多只提及了“付款”的反馈,只能确定与支付产品有关,不能确定与具体哪一种支付方式有关),让这些反馈数据具有准确的上级标签(如“支付产品”),而不进行勉强分类。
为了用更低的成本,“喂”出各个专精于某一方面语义判别的预测模型,在构造数据集的时候,为每个模型量体裁衣,采取一些正则匹配策略,预选出不同的基础数据,制定不同的打标问卷,从而获得多个专门的训练数据集,分别提供给该系统中的子模型进行独立训练。
工单优先级评估
为了给平台派发工单及处理闭环系统的策略选择提供依据。使商家反馈数据生成的每一条工单,都将经过计算获得一个优先级等级,表示该工单亟需处理的重要程度。由于本平台的最终目的是为了给产品改进提供依据,更加重视技术性的问题,也更加重视能够通过产品迭代快速提升用户体验的反馈内容。因此在优先级评分的时候,会给予反馈问题语义完整翔实、问题影响严重、以及产品设计自身造成的问题更高的优先级评级,希望这些问题能够尽快得到解决。
为了从各个角度全面、综合地评估工单的优先级,将以下信息经过相应的计算方法,一并纳入到优先级评估过程当中:
聚类来源的指标有以下两个:
1.同内容反馈数量(Ns):表示每个工单下,经过细粒度聚类关联的相同原声反馈数量,做sigmoid变换后标准化到[1,1.5]区间。
2.关联相似问题数量(Nst):表示粗粒度文本聚类后,与该工单同属于一个粗粒度聚类类别的反馈数量,做sigmoid变换后标准化到[1,1.2]区间。
分类来源的指标有以下三个:
3.反馈类型(St):根据反馈类型的分类结果为每条反馈进行打分:(技术)问题反馈>业务投诉>技术方案咨询>业务咨询>体验>建议>与上述均无关。
4.问题严重程度(Su):根据问题语义进行严重度分类,根据分类标签为每条反馈匹配不同的分数:不可用>存在异常阻碍使用>不好用不合理>诈骗骚扰投诉>和这些都无关
5.反馈情感(Se):根据反馈的情感分类结果为每条反馈进行打分:none,sadness,fear,surprise,disgust,anger。然后将分数归一化折算到[1.0,1.175]区间。
另外,为了更好地推送高质量的反馈工单,在评估优先级的时候,还计算了另外一个指标:
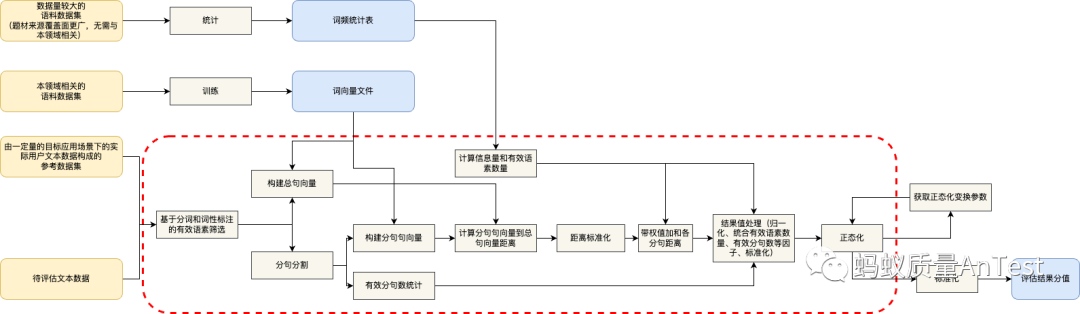
6.文本语义信息量(IF):一个0-1的分数,代表该工单所关联的反馈数据所包含的信息量水平。通过将反馈文本分割成“半句”的集合,计算每个半句对整个文本的语义差异水平,加权每个半句中有效语素(仅保留“动作”和“对象”两种语素)的信息量取平均数,再进行分布调整,得到最终的信息量分值。具体计算流程如下图所示:
求得上述6项指标后,通过一定的数学模型获得最终优先级分值。
随后根据分值,给每个工单标注P0,P1,P2,P3的优先级标签。
业务效果
通过上述算法建设,反馈工作台上显示和推送的工单将具备作为精准推送的产品分类结果和作为分层分发依据的优先级标签,从而有效支持反馈工作台的业务能力。
结语与展望
通过上述技术手段,商家反馈平台成功实现了产品标签的高精度匹配,相同语义反馈合并,工单优先级有效识别等功能,支持了平台进行问题分层分级分发,推动问题解决。目前平台正处于初步试运行阶段,未来将从更多渠道接入商家反馈数据,面对来源各异的数据保持现有算法模型的准确率,形成有效的反馈问题解决机制。算法侧在未来的建设中,也将进一步打通和工程侧的功能衔接,建设商家标签库系统,使算法侧能够输出维度更加丰富、更加面向业务需求的参考标签,通过多标签筛选能力提升问题分发效果和效率。接收平台用户纠错以及产品标签更新信息,实现T+1的模型更新与分类结果响应。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号