一次嵌套读锁引发的死锁排查过程 https://mp.weixin.qq.com/s/ea4sq77TQZFdpYuhWly8eg
作者: andorccao(曹灿)、alonlong(龙武)
并发编程经常需要和锁打交道,读写锁允许并发读和独占写,能提高并发性。但使用不当容易引发死锁问题。
微保业务使用的微服务架构。随着业务发展,原有的nginx/haproxy等代理服务无法满足复杂多变的需求,API网关应运而生。API网关主要实现负载均衡、路由、鉴权、控制访问、服务代理、监控等功能。
API网关作为C端的统一入口,对性能和稳定性有很高的要求,一次微小的波动就会成倍放大影响到业务服务。本文以微保API网关为例,逐步剖析读写锁嵌套误用引发的一次死锁bug。
微保的核心业务,都有非常完善的监控和告警系统,便于我们快速发现和初步定位问题。本次问题的发现是告警系统发出一连串的超时警告,都指向C端访问后台的config服务超时(超过5秒)。
收到业务告警后,第一反应API网关应该没问题,毕竟网关自身没有收到告警,且API网关作为C端的流量入口,若有问题那其他业务告警早就炸了。打开API网关整体监控视图,并未发现明显异常(其实是监控数据比较分散没有立刻发现)。按照常理,一般超时大概率是网络问题,我们查看了内网网络状态和域名解析情况,均未发现异常。
看来需要根据日志来分析。面对这种大批量超时现象,任意抽一个API网关实例(共8个实例),未发现明显错误日志。
这时候就比较懵了,服务和网关都没有异常。考虑到超时对业务影响非常大,没太多时间深入分析问题。该祭出重启大法了。先重启config服务,未恢复;紧接着重启API网关服务,异常告警终于结束。看来是API网关的问题,接下来我们从多个维度一起分析。
查看所有API网关实例日志,发现其中一个实例异常期间没有日志输出。正常情况下API网关每个请求都会打印日志,那么有几个方向值得怀疑:
-
-
日志库有问题,但日志库作为最常用的组件,不应该此时暴露出来(同时了解到近期没有更新)
-
由于没有保留现场和任何日志作为参考,定位难度很大,我们从外围熟悉的信息着手分析,缩小范围,然后再根据源码来定位(API网关使用的开源组件很多,这个方向会比较复杂)。
3.1 链路分析
-
-
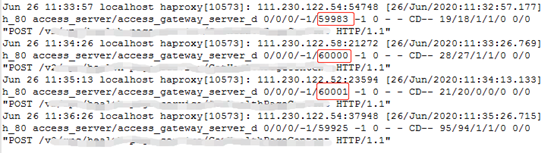
CLB是腾讯云提供的负载均衡服务。一般情况下CLB日志处于关闭状态。我们优先看第一条数据流,下图是haproxy的日志。
发现haproxy调用API网关的请求存在60s超时(CLB配置超时时间是60s),说明异常期间是API网关未响应导致的链路超时。
这里有个疑问:CLB有健康检查机制,管理的实例异常后会被CLB踢掉,为啥没有触发?
3.2 CLB健康检查
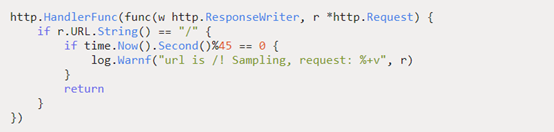
CLB每5秒发送一次GET请求,连续3次未收到就会踢掉异常后端服务,API网关未被踢掉表示这段时间能正常处理GET请求。再来看API网关健康检查适配代码:
这里能正常运行,说明请求已触达业务层面,不是框架层面的问题。其实这里有个关键点忽略了。正常情况要打印Warn日志的,与没日志的现象不符,所以日志库有问题(事后证明符合)。
3.3 监控视图分析
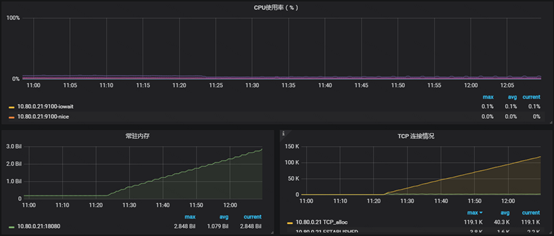
上图是异常实例的基础状态视图,异常期间内存、TCP alloc数明显增加,CPU没啥变化。解释下这些指标的含义:
-
-
TCP alloc一直增加说明服务能正常接收新的请求,但未调用close,无法正常关闭请求
-
-
异常期间其他实例正常,说明网关转发的后台服务没有异常
-
异常实例所处的机器其他服务正常,说明机器处于正常状态
综合上面的推论猜测是API网关服务自身处于假死状态,无法正常处理请求,且应该是请求入口处就卡死(没有日志)。
常见的假死原因有:机器资源异常(IO异常、CPU、内存 100%),死循环,服务死锁。上面的分析可以排除机器资源问题。接下来重点分析服务假死的情况。
4.1 模拟死循环现象
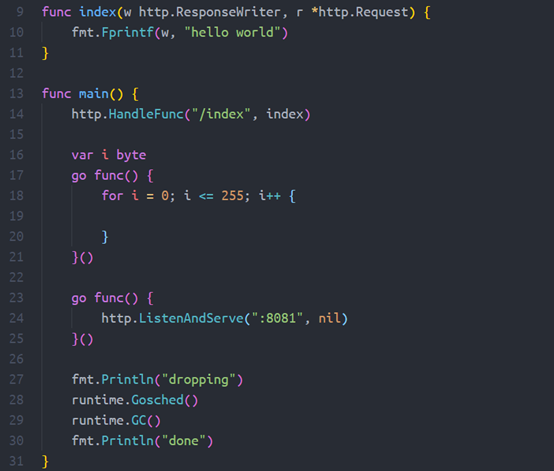
一般死循环会导致CPU很高,但我们还是需要验证下golang协程死循环的表现是否一致。
上面这份代码。在golang 1.11之前的版本,存在死循环然后触发协程调度后,会导致服务假死。这种状态下TCP alloc,内存都会增加,CPU也会增加,与API网关异常的表现不一样。
4.2 全局资源死锁
先从容易排查定位。我们使用的是golang语言,常见的全局对象锁有sync.Map,如下图sync.Map的使用方式。经验证,即使doSomething函数阻塞也不影响Load函数执行。排除了全局资源不当使用的问题(其他全局资源没有显示使用锁)。
4.3 组件死锁
API网关使用的组件比较多,我们根据已知信息分批查看每个组件的源码。异常期间没有任何日志输出,日志库由我们自己实现,引入了较多的特性,是值得优先排查的方向。仔细阅读后,发现日志库有嵌套锁的使用(新特性误用锁导致嵌套)。众所周知,不同语言的锁机制支持程度有区别。查看golang中读写锁的文档,有明确说明禁止嵌套使用读写锁。
If a goroutine holds a RWMutex for reading and another goroutine might call Lock, no goroutine should expect to be able to acquire a read lock until the initial read lock is released. In particular, this prohibits recursive read locking. This is to ensure that the lock eventually becomes available; a blocked Lock call excludes new readers from acquiring the lock
其实异常期间没有日志,我们早应该怀疑日志库的问题(被常识误导了)。接着对日志库进行压测,证明确实会触发死锁。日志库死锁触发的概率是极低的,需要同时满足下面情况:
-
服务一个协程写日志时,刚好执行完嵌套读锁的第一个读锁
-
此时日志库写文件超过限定大小触发写日志翻转,这里会有一个写锁
-
至此找到API网关假死的原因,日志死锁满足前面的一切异常现象。
为什么嵌套读就会触发死锁呢?读写锁实现原理是什么,这里根据官方源码来一起阅读下。读写锁实现代码(仅保留关键逻辑)如下:
-
-
第一次Lock时,写锁需要等全部读结束才能继续,此时会等待读解锁,对应(图5.1)注释2
-
第二次RLock时,已经处于写锁中,需要等待数据写结束才能继续,此时会等待写解锁,对应(图5.1)注释3
-
这种状态下读锁和写锁互相等待对方发送信号(RUnlock和Unlock会释放信号),产生死锁
在无现场无关键日志的情况下,我们从多个维度排查,通过不断的抽丝剥茧和逻辑推理,终于找到了问题点。有几点经验同大家分享下。
-
出现问题后,在初步解决过程中尽量保留现场,这对一些小概率bug的定位很有帮助
-
核心业务要不断建设监控视图,有效且多角度的监控可以反映问题根源
-





 浙公网安备 33010602011771号
浙公网安备 33010602011771号