BBR原理导读
BBR原理导读 https://mp.weixin.qq.com/s/j10wc2TZG9ddbio7UeYUaQ
BBR原理导读
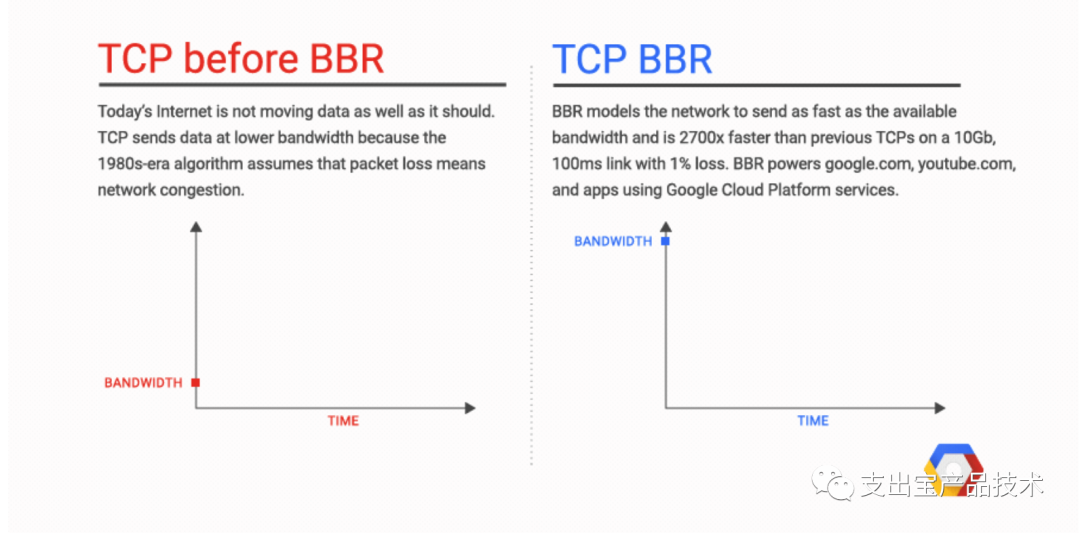
最近在排查网络问题时,发现在服务器上部署了Linux 4.9 的 TCP BBR拥塞控制算法以后,访问速度得到了成倍的提示,顿时觉得⼗分神奇,在⽹上查询了BBR相关资料,阅读了BBR的论⽂,下⾯基于该论⽂向⼤家简要分析⼀下BBR的来⻰去脉。
什么是BBR
2016年底google的开发者Neal Cardwell等5个⼤⽜在acmqueue上发表了论⽂BBR: Congestion-Based Congestion Control,提出了TCP拥塞控制的BBR算法。BBR即Bottleneck Bandwidth andRound-trip propagation time,正如其名,它是⼀种基于瓶颈带宽和往返传播时间的拥塞控制算法。
背景
基于丢包的拥塞控制算法的缺陷
-
丢包≠拥塞
在tcp拥塞控制算法提出的20世纪80年代,直接把丢包等价于发⽣了拥塞,需要降低发送 速率。受限于硬件的发展⽔平和⽹络普及程度,这在过去的很⻓⼀段时间都是⼗分适⽤的。然⽽30多年 过去了,⽹络的带宽从⼏Mbps已经发展到了⼏Gbps,⽹络上的⽹卡、交换机和路由器的内存也从⼏ KB发展到了⼏GB。并且⽹络的复杂程度也原超当年,各种跨洋跨⼤洲的通信链路以及⽆线⽹络使得⽹ 络丢包和⽹络拥塞的关系越来越稀薄。在实际情况中,⾼速⼴域⽹内的传输错误丢包是不能忽略的,特 别是在⽆线⽹络的情况下,整个链路的不稳定性导致的丢包更是⾮常常⻅。如果简单的认为丢包就是拥 塞所引起,从⽽降低⼀半的速率,将会导致⽹络吞吐变低。
-
缓冲区膨胀(bufferbloat)
⽹络中的各种设备基本都有⾃⼰的缓存,基于丢包的拥塞控制算法⾸先会填 满⽹络中的缓存,当缓存填满以后出现了丢包才开始降低发送速率。如果⽹络瓶颈的缓存⽐较⼤时,这278就可能造成极⼤的延时。要解决上⾯的问题,就需要另外⼀种思路,不是基于丢包来估计⽹络发⽣了拥堵。
原理
tcp拥塞控制的初衷是为了在保证通信质量的前提下尽可能⾼的利⽤通信链路的带宽。⼀个tcp链接就如同⼀条条管道,评价⼀条tcp链路的传输性能主要依靠2个参数:RTprop (round-trip propagation time)往返传播时间和 BtlBw (bottleneck bandwidth)瓶颈带宽,就如同现实管道中的管道⻓度和最⼩直径。
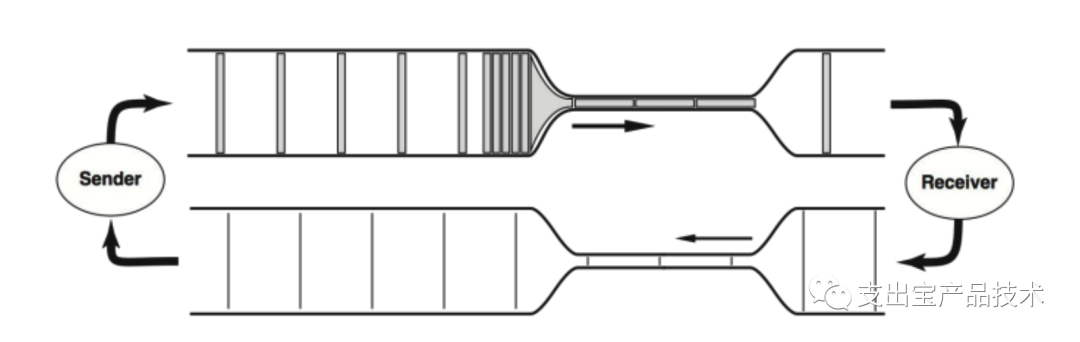
当⽹络中数据包不多,还没有填满瓶颈链路的管道时,RTprop决定着链路的性能。随着投递率的增加,往 返时延不发⽣变化。在1979 Leonard Kleinrock证明了,当数据包刚好填满管道时,即满⾜最⼤带宽BtlBw和最⼩时延RTprop,⽆论是单独链接还是整个⽹络来说是最优⼯作点。定义带宽时延积BDP=BtlBw × RTprop,则在最优点⽹络中的数据包数量=BDP。继续增加⽹络中的数据包,超出BDP的数据包会占⽤buffer,达到瓶颈带宽的⽹络的投递率不再发射变化,RTT会增加。继续增加数据包,buffer会被填满从⽽发⽣丢包。故在BDP线的右侧,⽹络拥塞持续作⽤。过去基于丢包的拥塞控制算法⼯作在bandwidth-limited区域的右侧边界,将瓶颈链路管道填满后继续填充buffer,直到buffer填满发⽣丢包,拥塞控制算法发现丢包,将发送窗⼝减半后再线性增加。过去存储器昂贵,buffer的容量只⽐BDP稍⼤,增加的时延不明显,随着内存价格的下降导致buffer容量远⼤于BDP,增加的时延就很显著了。
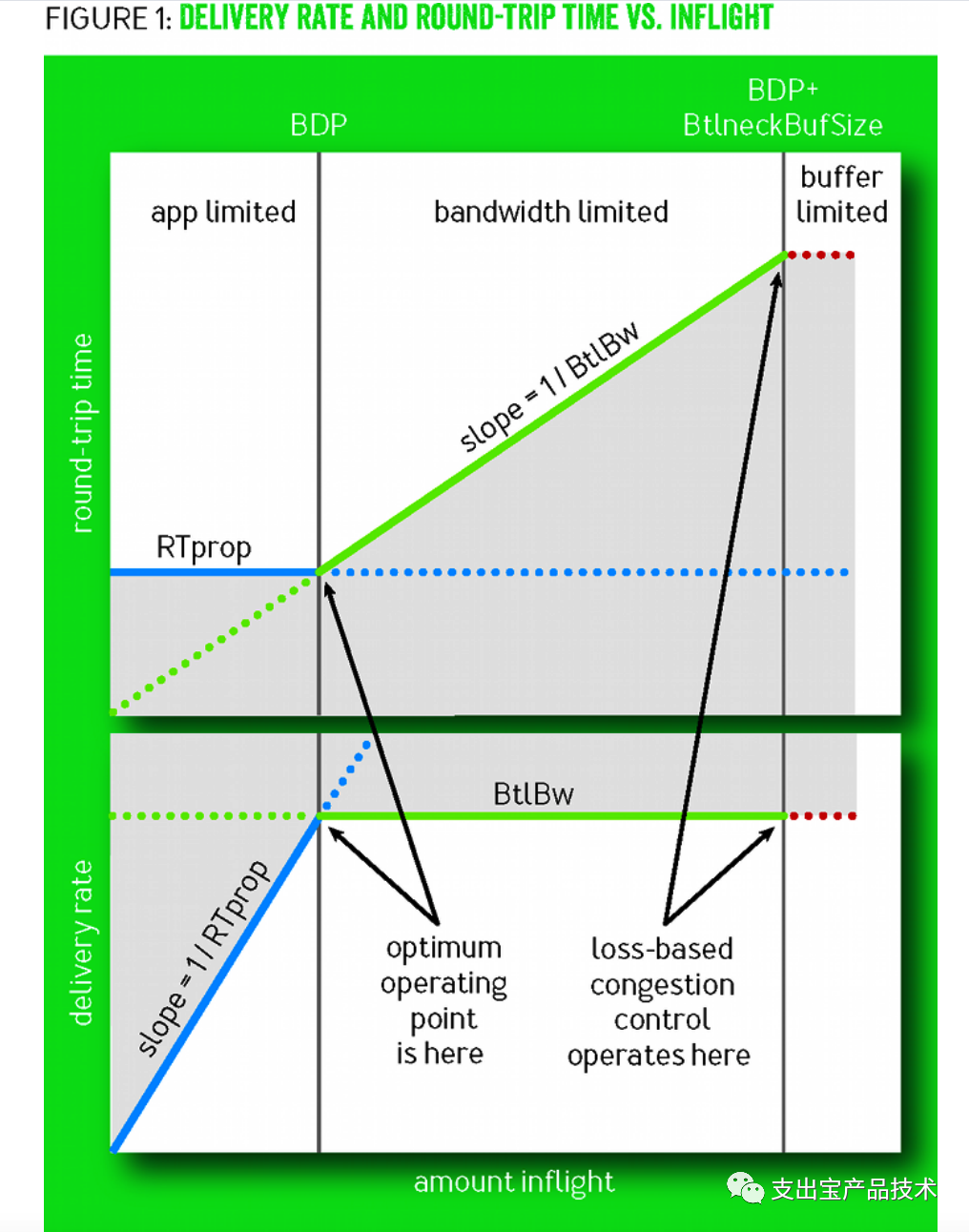
针对上述的问题,BBR采⽤了完全不同的⽅案:既然丢包不能等同于拥塞,那就忽略丢包,通过观测和量化链路的瓶颈带宽和往返时延来让拥塞控制算法处理真正的⽹络拥塞,从⽽尽可能的让⽹络传输达到Kleinrock所提出来的最优⼯作点。
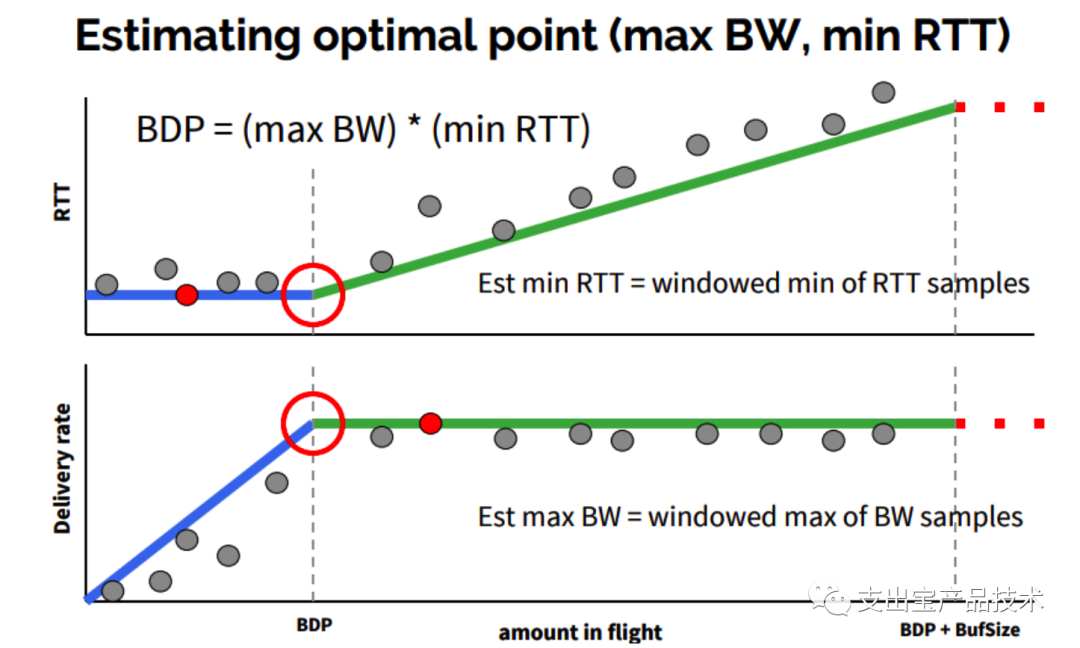
然⽽另外⼀个问题随之⽽来了,同样在20世纪80年代,Jeffrey M. Jaffe就证明了没有什么算法能同时计算出这个最佳⼯作点。要测量最低延迟(min RTT),就必须要排空缓存,⽹络中的数据包越少越好,⽽此时 带宽是较低的。要测量最⼤带宽(max BW),就要把链路瓶颈填满,在buffer中有⼀定的数据包,⽽此时延 时⼜是较⾼的。
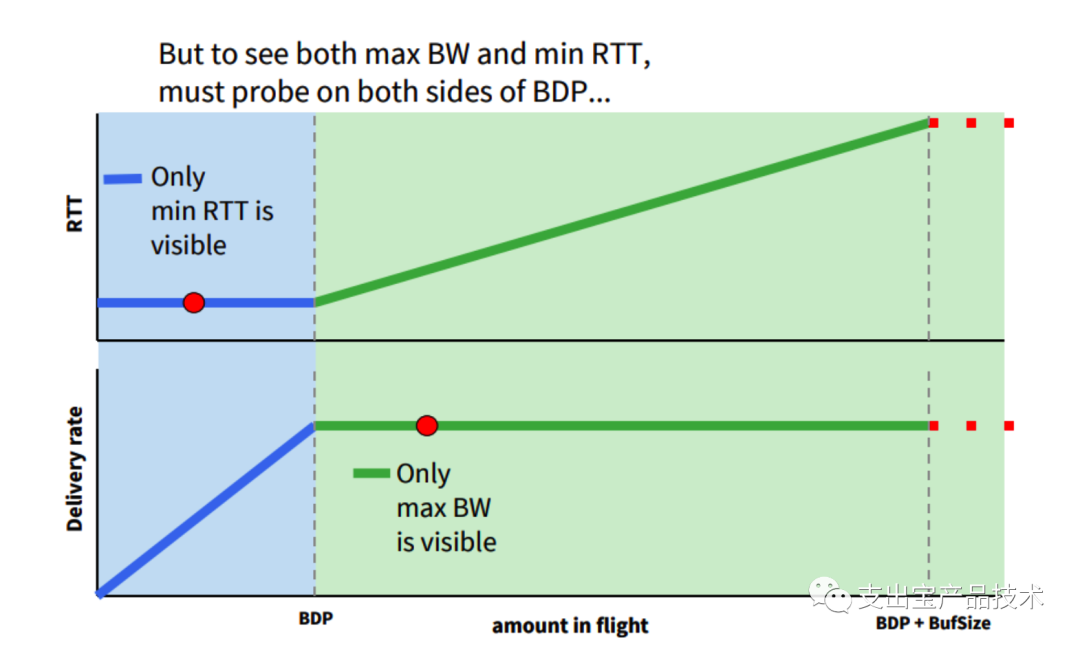
针对测不准的问题,BBR算法采⽤的⽅案是,交替测量带宽和延迟,⽤⼀段时间内的带宽极⼤值和延迟极⼩值作为估计值,动态更新测量值,最终控制发送速率,避免⽹络拥塞。
实现
BBR启动以后主要分为四个阶段:
-
启动阶段
BBR采⽤类似标准TCP的slow start,指数的⽅式来探测⽹络的带宽,⽬的也 是尽可能快的占满管道,经过三次发现投递率不再增⻓,说明管道被填满,开始占⽤buffer。

-
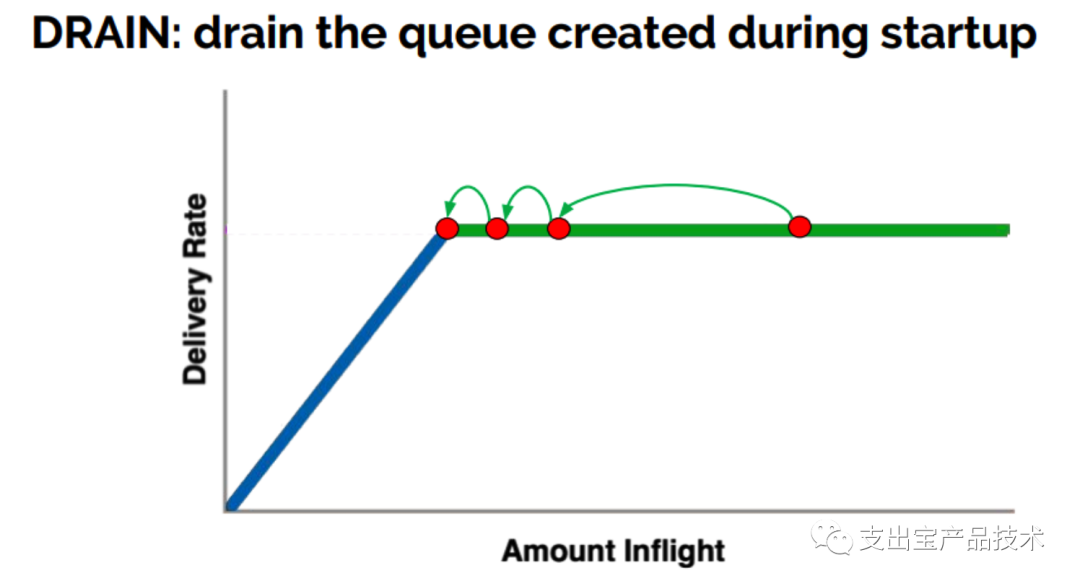
排空阶段
指数降低发送速率,相当于是startup的逆过程,将多占的buffer慢慢排空。
-
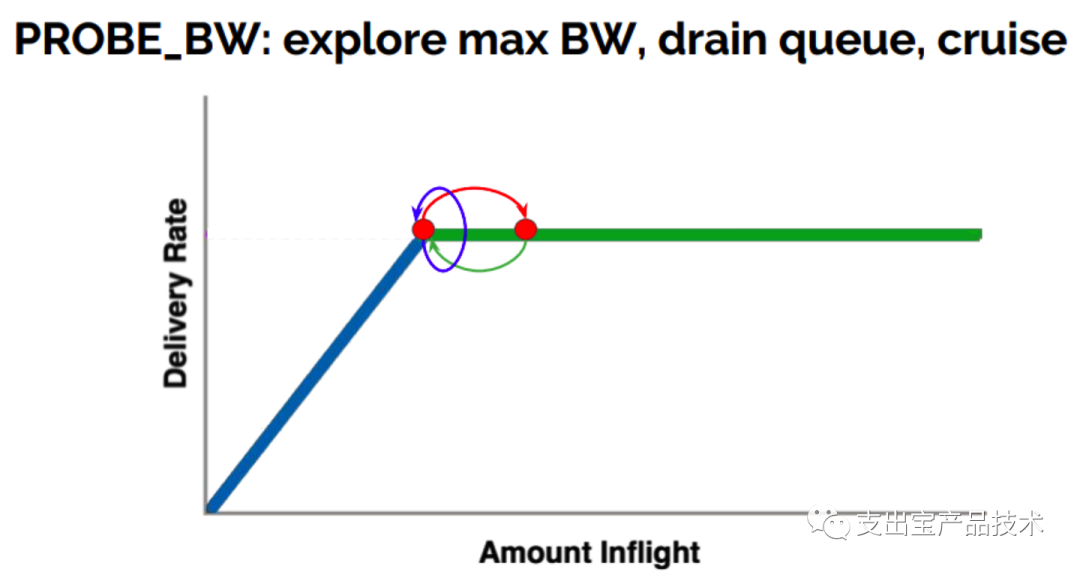
PROBE_BW:
在之后,BBR进⼊稳定⼯作状态。BBR会不断的通过改变发送速率进⾏带宽探测,先在 ⼀个RTT时间内增加发送速率探测最⼤带宽,如果RTT没有变化,后减⼩发送速率排空前⼀个RTT多发 出来地包,后⾯6个周期使⽤更新后的估计带宽发包
-
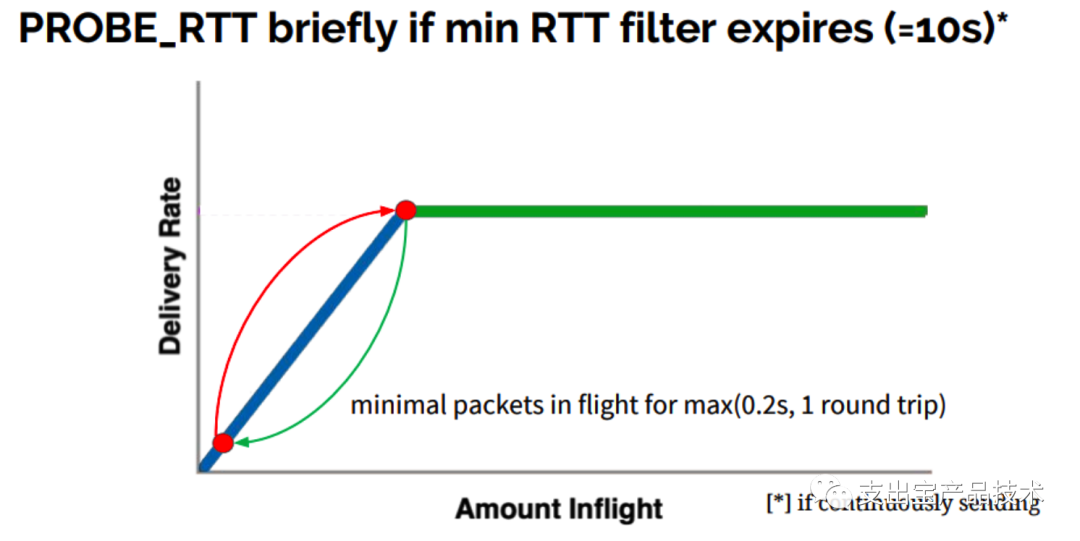
PROBE_RTT:
延迟探测阶段,BBR设定了min RTT的超时时间为10秒,每过10秒,会进⼊⾮常短暂延 迟探测阶段,为了探测最⼩延迟,BBR在这段时间内仅发送最少量的包。
在稳定⼯作的情况下,BBR会交替的进⾏带宽探测和延时探测,并且越98%时间都处于带宽探测阶段,带宽探测阶段时定期尝试增加发包速率,如果收到确认的速率也增加了,就进⼀步增加发包速率。下图展示了在第20s时⽹络带宽增加⼀倍时⽹络的⾏为。向上的尖峰表明它增加发送速率来探测带宽变化, 向下的尖峰表明它降低发送速率排空数据。如果带宽不变,增加发送速率肯定会使RTT增加。如果带宽增 加,则增加发包速率时RTT不变。这样经过三个周期之后,估计的带宽增加了1.95倍。284⽽在第40s时⽹络带宽减半,因为发送速率不变,inflight(在途数据包)增加,多出来的数据包占⽤了 buffer,RTT会显著增加,带宽的估计是滑动窗⼝时间内的极⼤值,当之前的估计值超时之后,降低⼀半 后的有效带宽就会变成新的估计带宽从⽽减⼩发送速率,经过4秒后,BBR逐渐收敛。
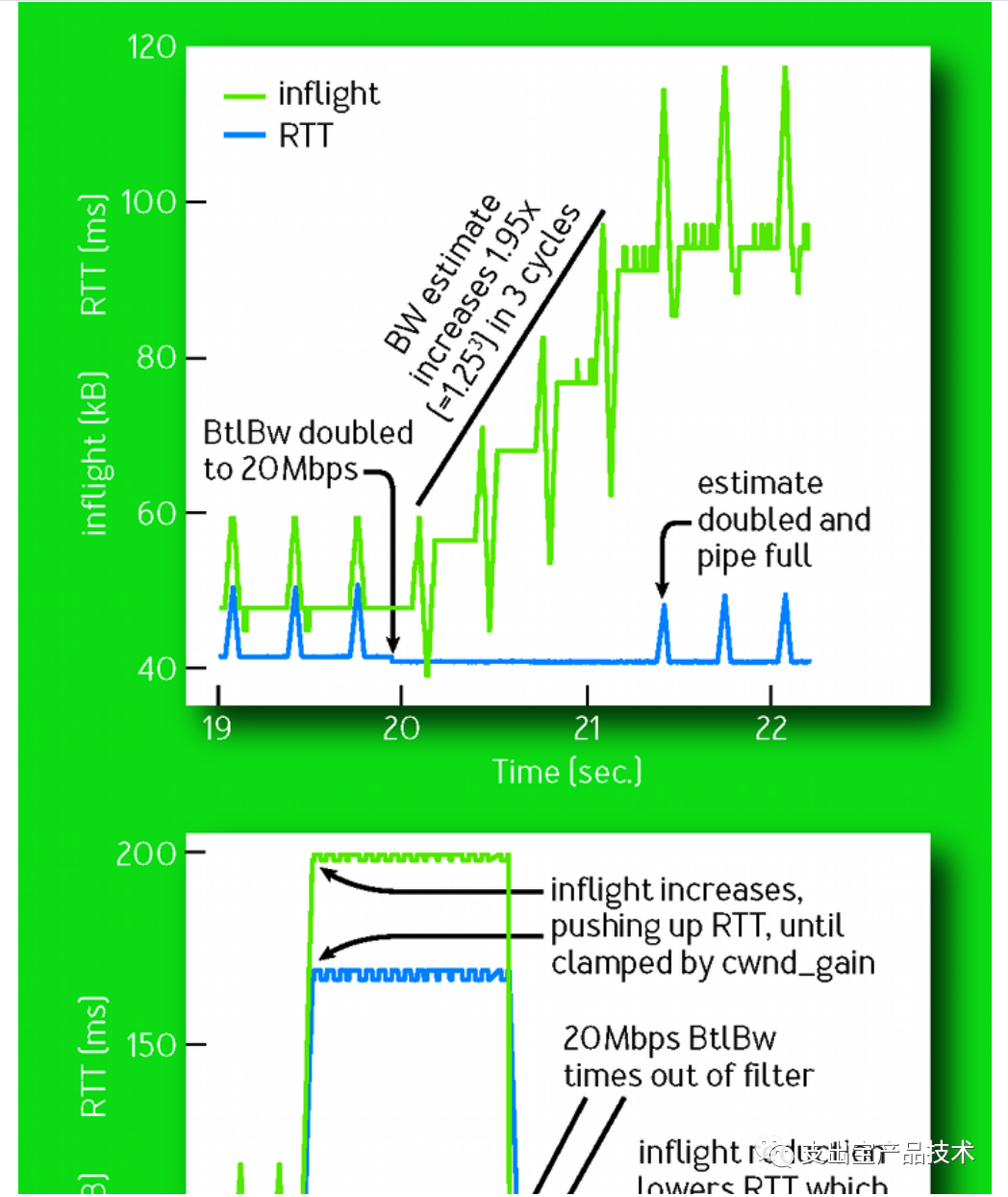
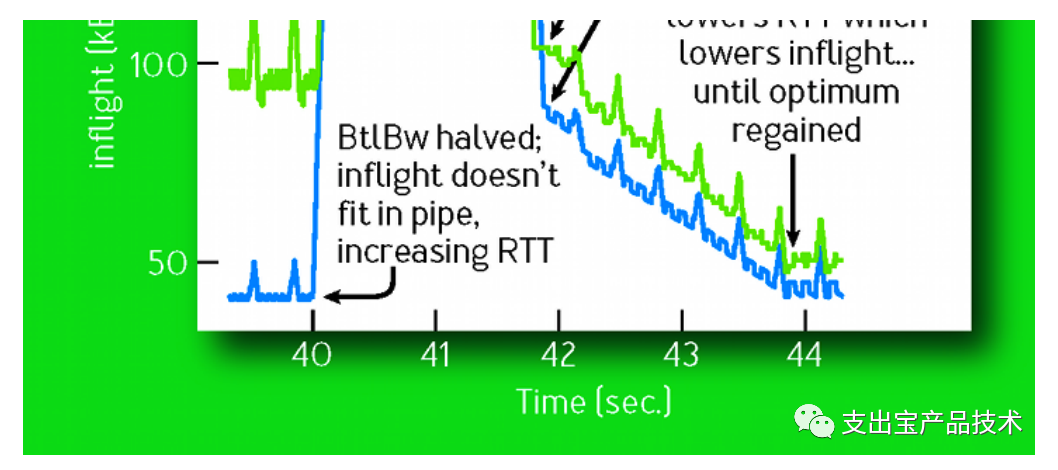
效果
我们回过头再来看BBR要解决的2个问题
-
优化在⾼丢包率下⽹络的吞吐率:
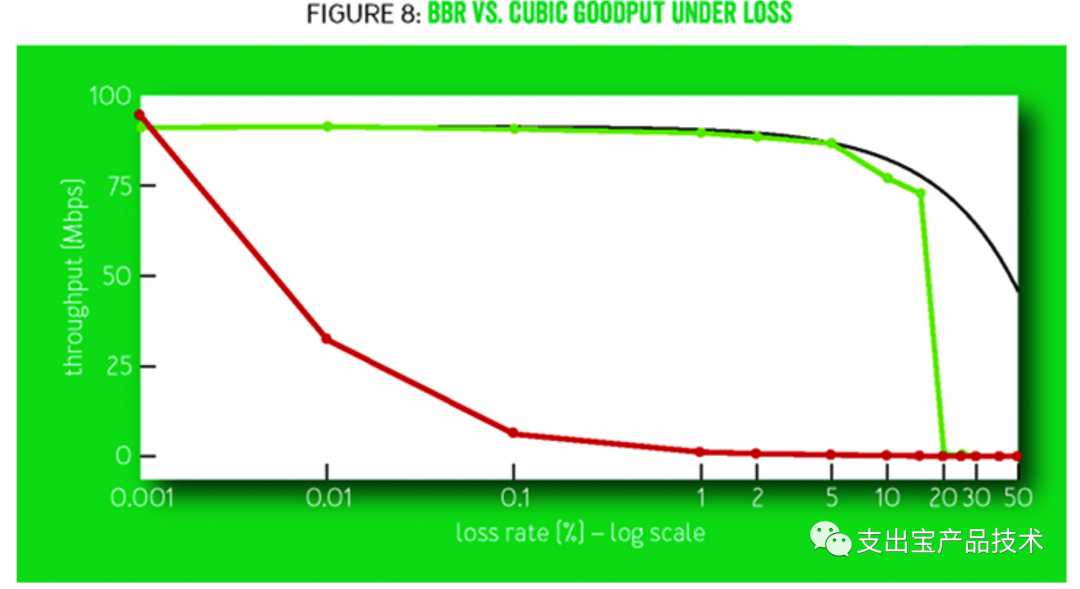
上图可以看到,传统的TCP CUBIC在随着丢包率的增加性能急剧下降,在千分之⼀的丢包率情况下,系统吞吐量就下降到⽹络的百分之⼗,⽽BBR则在百分之五以下的丢包率的情况下,基本没有性能损失。
-
减少缓冲区膨胀,降低⾼缓存导致的延迟
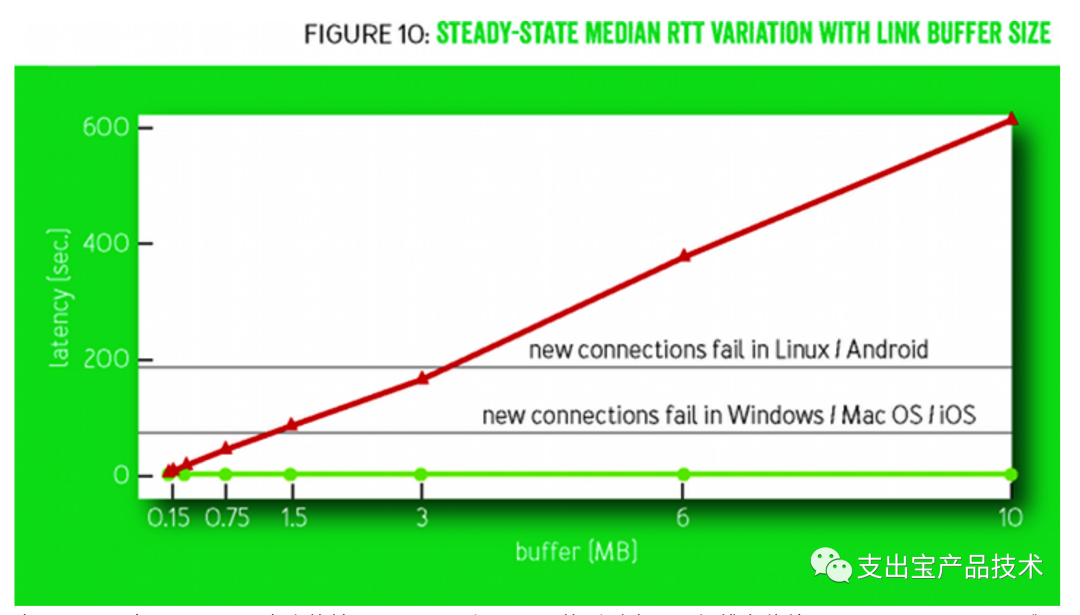
上图展示了在不同buffer⼤⼩的情况下,BBR和CUBIC的延时表现。红线为传统TCP CUBIC,CUBIC倾向于填满buffer,这也导致延迟基本随着buffer的增⼤线性增⻓,⽽延时过⻓可能直接导致系统建⽴连接超时。⽽BBR基本保持发送队列为最⼩,随着buffer的增加⽹络延迟基本不变。所以BBR能在存在⼀定丢包率的的⽹络环境中充分利⽤带宽,⼗分的适合在跨区域的⾼延迟⾼速⽹络。当 然BBR也不是万能的,许多测试和实际应⽤也发现了BBR存在在⽹络状况变化较⼤的情况下测不准导致⼤ 量丢包,交替测量导致波动较⼤,收敛较慢导致的公平问题等。Google也在持续优化BBR算法,在2018年 公布的BBR 2.0研究进展中就包含了:
-
提⾼与基于丢包的拥塞算法(Reno/Cubic)的共存能⼒。降低BBR算法的抢占性,提⾼不同算法之间的公平性。
-
减⼩排队丢包和排队时延的情况。这⾥主要根据丢包率和标记ECN⽐例来设置inflight的两个⻔限值,inflight_hi和inflight_lo。
-
加快min_rtt的收敛性,增加是将进⼊Probe_RTT模式的频率由10s设置到2.5s。
-
减⼩Probe_RTT模式带来的带宽的波动。
参考⽂献
[1] Neal Cardwell. "TCP BBR congestion control comes to GCP – your Internet just got faster"
[2] Neal Cardwell, et al. "BBR: Congestion-Based Congestion Control."
[3] Yuchung Cheng, Neal Cardwell. "Making Linux TCP Fast"
[4] Neal Cardwell. "BBR Congestion Control Work at Google IETF 102 Update"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号