(一)背景介绍
最近网络上流传的华为方舟编译器很火,随着热度的提高,华为也将技术原理做了简单披露。我们来看官方的描述,原文链接:https://baijiahao.baidu.com/s?id=1632292071046828780&wfr=spider&for=pc。此时此刻,这套编译器华为还没有开源。

作为安全行业的从业者,我想大家很清楚安卓下的所谓C语言就是JNI(JAVA Native Interface)。安全开发者为了实现关键的安全防护功能自我保护,我们通常将功能实现在JNI里,然后用NDK编译成so文件,再通过对so加壳或者虚拟机化,进一步自我保护,这样可以极大增强上图提到的“安全性”。上图传达出的第二条信息是,该编译器将java和C(JNI)编译成一套可执行文件,到底是什么可执行文件呢?我们再往下看

什么是干掉虚拟机?我们知道,语言分成编译型语言和解释型语言,前者的典型是C,苹果是ObjectC,编译器将C语言直接编译成机器指令后由CPU执行,后者的典型就是Java语言,即由JVM里的解释器来执行java字节码,这个解释器就是虚拟机的核心之一。
所以我们不妨大胆猜测:所谓“干掉虚拟机”,是指将java代码转换成C代码,即将解释执行转换成编译后执行,由于C的执行速度比Java语言快,因为编译执行总是快于解释执行,从而实现了性能的提升。

上图传达出的信号是:这套编译框架甚至还可以优化java语言的执行效率,也就是java代码的编译优化。

上图所反映的法律和知识产权问题,据说谷歌和华为真正的老板其实是同一群(个)人,不多谈。
所以总结下来:华为的所谓“方舟”编译框架是:输入用户源代码,先将其中java语言进行优化,之后将它转换为C语言(JNI),从而提高执行效率。所以这套编译器的本质,我的猜测是:JAVA to C,或者JAVA to JNI,方舟编译器的本质是,一个基于编译器的语言解释器。
其实国外有很多成熟的JAVA to C/Native编译框架,不论是商用的还是开源的,比如Toba,Vortex,Marmot,IBM High performancefor Java Compiler,TowerJ
,superCede等等,都可以是可以提供大量的借鉴的。搜索java native compiler了解更多。另外国内很多安全厂商,据说几年前就能提供类似的且比较成熟的方案,不排除华为“借鉴”了友商的方案,工程框架确定后,凭借数量众多的工程师和强大的执行力,自身的产业号召力和国家资本的帮助迅速将其商业化和产业化。但是能否如华为宣传的数据如此之漂亮, 实际性能,用户的实际体验究竟能提升多少,作为从业人员,我本人并不那么乐观。而且这种转换很有可能降低系统的稳定性和兼容性。
那么接下来才是本文的重点:作为技术人员,我们要如何实现这套编译器呢?在这里,我提出一种方案,可以完整覆盖上述的所有特性,一样可以实现华为所宣传的方案,希望能抛砖引玉,分享不同的思路的效果。条条大路通罗马。
(二)JAVA语言的编译优化
第一步要实现华为宣称的“一个好的编译器,开发者一行代码都不需要修改,性能提升10%-20%”。

绝大部分安卓APP超过99%的代码都是JAVA语言写的,所以对JAVA的优化尤为重要。我们使用soot框架来优化,Soot是什么呢?它是由加拿大麦吉尔大学Sable Reasearch Group维护的,用来优化java程序的一套成熟的框架,这套框架的文档非常之全,可以让新人快速上手。

正如上图所说:java有很多优秀特性,但执行效率不如C/C++,为了优化java执行效率,soot应运而生。
Soot的Github地址是https://github.com/Sable/soot,文档不限于以下https://github.com/Sable/soot/wiki/Tutorials
Soot的原理是什么呢?和LLVM相似,编译框架会将原始代码转换成一种中间语言。由于中间语言相当于一款编译器前端和后端的“桥梁”,无论是学习Soot还是LLVM,透彻了解他们的中间语言无疑是非常必要的工作。 Soot共有4种中间语言:BafBody,GrimpBody ,ShimpleBody 和 JimpleBody,每一种中间语言都可以进行优化。

BafBody:一种字节流形式的java字节码表示方法,易于操作和维护;
Jimple:一种规范的三地址码形式的中间表示;
Grimple:一种更加适合反编译的Jimple表示形式
对于Baf的表示如下所述

Baf是基于栈的表示,是一种较为初级的IR

在Jimple语言中,用的最多的就是statement型语句,这15种如上图所述。我们知道在java字节码中,总共有将近200多种指令,而现在的Jinple却只有15种statement,是不是大大简化了?并不是只有15中,而是其他种的指令要少很多,用到频率低。
那么soot的中间语言Jiimple长什么样的呢? 我们再看一个例子

这是转换之前的java源代码

这是转换之后的Jimple代码
是不是很容易就能看懂呢?我们可以简单总结一下Jimple的语法特性:
1.使用$开头的局部变量表示的是一个栈内的地址,它不表示一个真实的局部变量。而不以$开头的才是真正的局部变量。以$开头的变量由于不是原java代码里真实的变量,存在于堆中,所以是一种“堆媒介”
2类似int x = (f.bar(21) +a) * 长指令会被分隔成$i4 = $i3 + i0 和 i2 = $i4 * i1这样的三地址形式的指令。 什么是三地址码?就是形如x = y op z 型的指令
3参数值和this指针使用IdentityStmt形式的表达式被分配到一个具体的局部变量中,比如i0 := @parameter0: int; 以及r0:= @this: Foo。进一步讲,由于x := @parameter0符合形如identityStmt下的local := @paramrtern:type可知paramrter0就是第一个参数,local代表局部变量(或者立即数)了
要想继续推进,首先要对jimple代码足够熟悉。

上面的两个表,详细阐述了jimple语法的规范,从上面我们可以看到上面所说的15种statemnt和其他的几种指令,不得不说文档很齐全很细致,比我之前用的JS编译框架esprima好很多。总之只要根据官方提供的手册,可以很清楚搞清楚java和jimple的一一对应关系,自然就熟悉了Jimple语法。
这种形式的中间语言优势很多,因此也是很多自定义优化步骤和自由化工具处理的对象。我们的节点转换器也不例外,就是以Jimple代码为基础进行转换的
如果您熟悉编译器的优化,相信您已经被三地址码这种简洁又规整的形式吸引了。没错,但是soot还提供了一种更加适合编译优化的语言:shimple。它是一种静态单赋值型的语言(SSA),它保证了每一个局部变量只有一个赋值,将极大简化分析。除此之外,他和Jimple还有一个巨大的区别是它还引入了Phi节点,所以它是特别适合用来做优化和分析的一种语言了。但是这里我们不做过多介绍,编译优化,有大量成熟的算法可供借鉴,这里我们不多谈,我们还是选择Jimple作为转换对象.
关于Jimple的语法规范,官网上有详细的文档供查阅。
(三)JAVA to C
现在尝试去实现华为宣传的第二个特性:彻底抛开虚拟机。

只要能将java字节码由解释器解释执行,转换为编译后直接由CPU执行,是不是自然就实现了上面的功能呢?就“干掉”虚拟机呢?但是怎么转化呢?由于前面已经能够将200多种字节码指令转换成20多种指令,如果我们将这不超过20种指令的JImple,做个等价转换,也就是一个节点(node)的解释器,是不是就可以实现JAVA toC呢?也就是说,首先将java代码进行简化,分成有限的几种指令,接着只要根据每一种指令,转换成JNI语法,最后再编译成so,让原本的java字节码指令转为执行so里的JNI,就实现了从java代码到C代码的转换
转换成JNI后的代码不仅更加安全,还能提高执行效率,和上述完全吻合!
现在我们简单的看一两个转换示例:
假设我们有一个被测试的类,如下所示:
|
1
2
3
4
5
6
7
|
package demo;
public class have_a_try {
public static void main(String[] args) {
System.out.println("Hello World");
return ;
}
}
|
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
public static void main(java.lang.String[])
{
java.lang.String[] r0;
java.io.PrintStream $r1;
r0 := @parameter0: java.lang.String[];
$r1 = <java.lang.System: java.io.PrintStream out>;
virtualinvoke $r1.<java.io.PrintStream: void println(java.lang.String)>("Hello World");
return;
}
|
现在开始转换,由于涉及很多技术细节,比较敏感不详细解释。首先,将类下的方法名称 转换成JNI能识别的形式,
JNIEXPORT jobject JNICALL Java_demo_have_1a_1try_main
我们看后面的Java_demo_have_1a_1try_main,静态加载时,由于需要具体指明类所在的路径,会采取这种形式,这样就免去了动态加载时使用JNIOnload注册函数步骤,但需要注意,要避免重名,命名的不合法,区别构造函数,,一些特殊字符也需要特殊处理等等。从函数名到JNI函数名要不断试错,找出合适的命名规则
然后在参数传入this指针,JNI环境env,对象jobject,JNIEnv类型实际上代表了Java环境,通过这个JNIEnv* 指针,就可以对Java端的代码进行操作。
简单提一句:如果方法名里有各种特殊字符呢?该怎么处理?如果方法名里有$,在啊JNI里等价的对应着_00024
然后就是参数的转换了。需要注意这个方法是不是重载方法,是不是静态方法。重载方法需要在JNI里体现区别,一般JNI方法都有两个固定的参数,一个是JNIEnv *env 还有一个是this指针,但this需要根据静态方法和非静态方法区分成jobject this 和 jclass this .因为静态方法只返回类本身jclass,而不是类的实例jobject。
至于传入的数据类型,我们可以看下面的表格,对照下表翻译,更详细的可以看jni.h文件,具体的JNI函数如何写,这里不详细讲解。
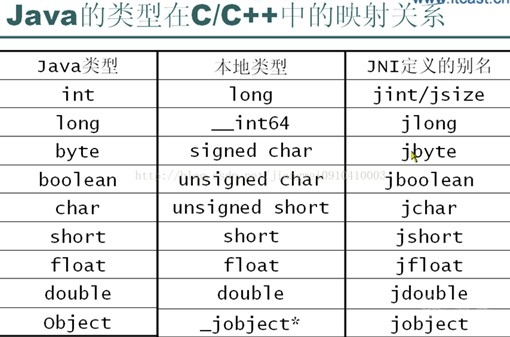
上述操作只是给JNI函数的壳,但里面的怎么写,还需要更加深入的了解Soot框架,我想挑几个典型的数据结构,简单介绍一下soot的使用
由于使用了值工厂设计模式(value Factory design pattern),主要包含Chain,Scene,SootClass,SootField,SootMethod,Body,Local,Trap,Unit,Type,Modifier,Value,Box等一一系列数据结构,都是被封装好的数据结构,每一种结构都提供了一系列的属性和方法,可以供用户来做细致的操作。
这套框架比较完备的地方不仅如此,它甚至允许你定义自己的转换规则,就类似于LLVM的PASS,或者JS的babel编译器里的插件的概念,soot里叫做pack
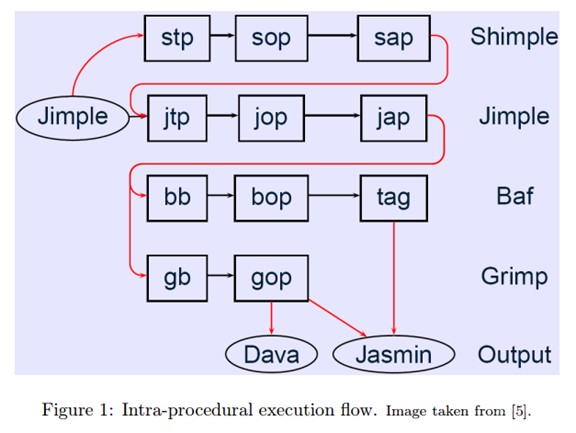
上图中的第一个字母代表被转换对象:s 代表Shimple, j 代表 Jimple, b 代表 Baf , g 代表 Grimp
第二个参数代表pack的角色:b表示创建body,t代表用户自定义转换,o代表优化,a代表注释。最后一个参数p就是pack的意思,是不是很简单呢。第二行里先经过用户自定义转化,再优化,再注释,是不是就能实现华为宣称的优化10%-20%呢?
soot将每一条指令都封装成类似抽象语法树(AST)样式的结构(不是真正的AST结构,只是类似),这棵语法树里包括了很多的“子节点”,soot还提供了对这棵“语法树”各个子节点的增删改查功能。只要你熟悉编译器前端,一定会快速适应这种操作方式。
经过对官方文档的阅读,相信你已经熟悉了jimple的语法,下面,如何将它转换成JNI?这里也是最核心的地方了,必须同时对JAVA和JNI大量经验且能深入了解上述两种语言特性的,并且熟悉安卓源码的开发人员才能胜任,但这并不是难如登天的
Soot框架下该如何定义自己的遍历转换规则呢?看一下官方文档给出来的例子
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
public static void main(String[] args) {
PackManager.v().getPack("jap").add(
new Transform("jap.myTransform", new BodyTransformer() {
protected void internalTransform(Body body, String phase, Map options) {
for (Unit u : body.getUnits()) {
System.out.println(u.getTags());
}
}
}));
Options.v().set_verbose(true);
PhaseOptions.v().setPhaseOption("jap.npc", "on");
soot.Main.main(args);
}
|
按照这个格式就能定义自己的pack了,转换规则就在新建的BodyTransformer类里,入口点是internalTransform。
(四)Soot的几个关键数据结构
(1) SootMethod
Soot提供了大量的API,用于对Jimple指令做颗粒度更细的操作,在soot的API里,有专门用于存储method的数据结构,叫SootMethod。可以先从官方文档中看一下,SootMethod这个下面的方法和属性。sooMethod用于表示JAVA里的的方法,通过geName等方法可以快速获取

从上图可知,这个类里包含了方法所对应的很多属性和方法。但是由于仍然不直观,我们截取了调试窗口,查看这个数据结构:
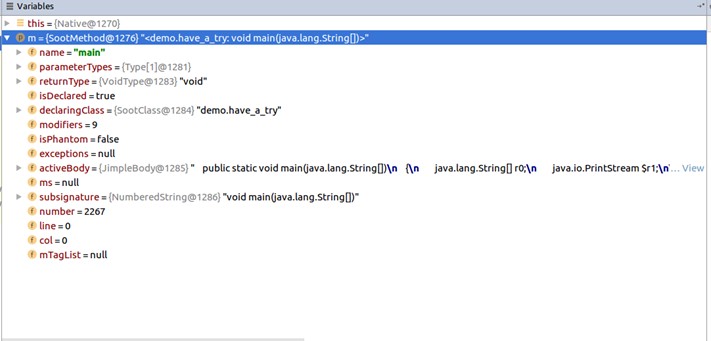
观察可知其实,这里的SootMethod是<demo.have_a_try: void main(java.lang.String[])>,然后这个字符串又被分割成一个一个颗粒度更小的元素。比如SootMethod.getName获取方法名,main,调试窗口里也显示name属性的值是main
(2) unit
再看第二个数据结构unit:unit就是一条单独的jimple语句。老规矩先看文档:

具体包含哪些方法呢?如下:


我们可以这样使用:
|
1
|
Chain<Unit> units = b.getUnits();
|
我们使用b.getUnits 方法来获取一个包含了所有unit的数组,这里的b是指body,一个更上层的数据结构。b.getUnits结果会返回一个链表,包含了这个body里所有的unit,这个链表的数据结构Chain如下图所示
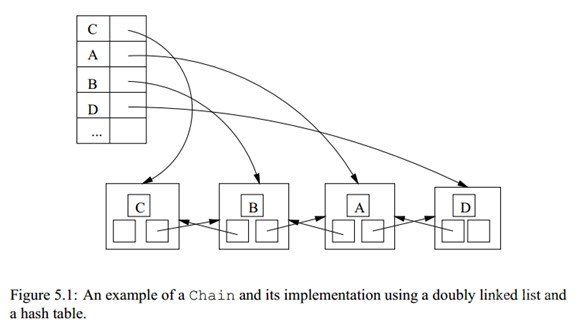
再接着
|
1
|
Iterator var4 = units.iterator();
|
接着使用迭代器来遍历每一个unit,即表示我们能拿到每一条jimple语句,可以进行转换了;
最后列举几个Unit对象关键API:
public List<ValueBox> getUseBoxes();//返回Unit中使用的Value的引用
public List<ValueBox> getDefBoxes();//返回Unit中定义的Value的引用
public List<ValueBox> getUseAndDefBox();//返回Unit中定义并使用的Value的引用
public List geUnitBoxes();//获得被这个unit跳转到的UnitxBox的List
public List getBoxesPointingTothis();//获得该unit作为跳转对象时,所有跳转本身的UnitBox
public boolean fallsThrough();//如果接下来执行后面挨着的unit,则为true
public boolean branches();//如果执行时会跳转到其他别的unit,则返回true。如:IfStmt、GotoStmt
public void rediectJumpsToThisTo(Unit newLocation);//该方法把跳转到该unit重定向到newLocation
其实soot就只有几种数据结构,上面的两个用到的比较多,也比较直观,剩下的种结构去慢慢熟悉就可以了。
(四)遍历与转换
只要是编译框架,一定会提供便遍历功能,比如JS的babel编译器里的traverse函数,每一种编译框架都有自己的遍历方法,soot里提供了一种十分方便的方法 apply,它可对每一个节点进行遍历,我们自定义的转换操作也是在这里面
首先是系统定义了一个接口类,如下图所示

到这你应该感到很眼熟了。之前说过,jimple代码是以15种stmt类型指令为主的,将200多种java字节码转化成近20种指令,已经大大简化了,而上面的15条指令正好对应着15种statement!
那么这个抽象接口是用来干嘛的?大家应该猜到了,是soot框架提供的,用于自定义pack的编写用的
如果我们重写这个抽象接口,就能定义自己的转换规则了!
当然
仅仅重写这一个接口是不够用的,还有一系列接口要重写,如下:
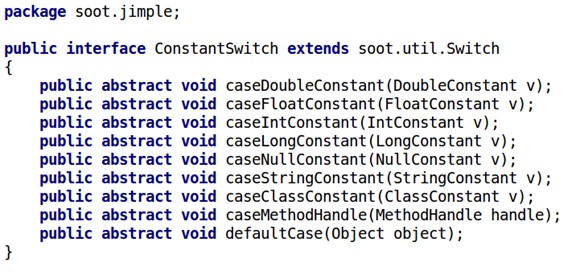
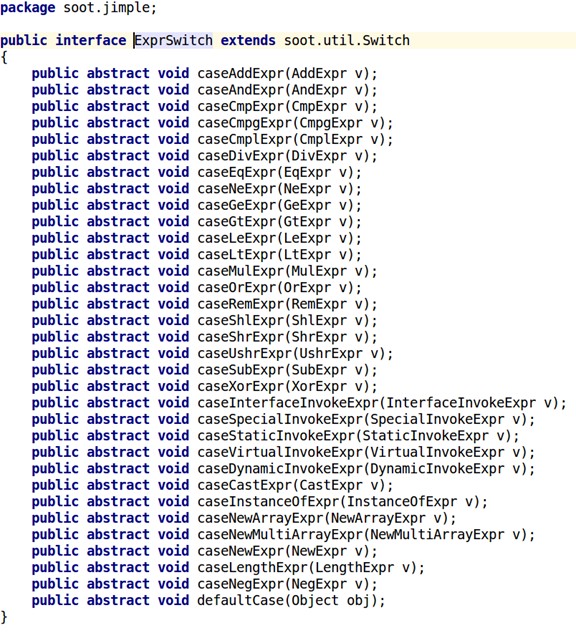

这些接口已经覆盖了上面那张Jimple语法表里全部的指令,重写里面的方法,以JImple指令: virtualinvoke $r1.<java.io.PrintStream: void println(java.lang.String)>("Hello World") 为例,调试器里表现为:

最终转换成
kanxue_CallVoidMethod(env, kanxue _locals[1],"java/io/PrintStream","println", "(Ljava/lang/String;)V", kanxue _s0)
这里由于比较敏感kanxue_CallVoidMethod函数的细节就不公开了。总之就是提前写好一些封装了调用逻辑的库函数,然后把参数从jimple语法中提取或者转译后,填入这个函数中,再从库里调用就可以了。
(五) 修改函数的名字并用NDK编译
最后只要把函数名改成native方法名之后,再编译成so即可。 过五一了,写的比较仓促,以后还会慢慢完善的。 我先去玩了。
结语
综上,通过soot的中间代码实现的优化和转义,是一种JavatoC的思路。其实这种方式不仅仅能提高执行速度,还可以提升安全性,所以还是挺有前景的技术,现在华为要开源,如果真走上述技术路线的话,对安全圈也是一大利好。
可以看到,这样我们就实现了了华为方舟编译器所宣传的所有功能项。其实从头到尾,我们一直使用别人的成熟的技术,即使是最关键的转化规则也可以通过时间积累,慢慢完善。编译器其实还是挺有意思的。
[培训]《安卓高级研修班(网课)》月薪三万计划
最后于 2019-5-9 13:43 被r0Cat编辑 ,原因:












 junkboy
junkboy
