
并发编程
并发编程,为什么选Go? https://mp.weixin.qq.com/s/IVAM7mejrUjp3Ol78S6KIw
并发编程,为什么选Go?

导语 | 代码的稳健、可读和高效是我们每一个coder的共同追求。本文将结合Go语言特性,为书写高效的代码,力争从并发方面给出相关建议。让我们一起学习Go高性能编程的技法吧~
在上篇《再不Go就来不及了!Go高性能编程技法解读》中我们结合Go语言特性,为书写高效的代码,从常用数据结构、内存管理两个方面给出相关建议,本篇将深入并发这部分进行阐述。
一、并发编程
(一)关于锁
-
无锁化
加锁是为了避免在并发环境下,同时访问共享资源产生的安全问题。那么,在并发环境下,是否必须加锁?答案是否定的。并非所有的并发都需要加锁。适当地降低锁的粒度,甚至采用无锁化的设计,更能提升并发能力。
无锁化主要有两种实现,无锁数据结构和串行无锁。
-
无锁数据结构
利用硬件支持的原子操作可以实现无锁的数据结构,原子操作可以在lock-free的情况下保证并发安全,并且它的性能也能做到随CPU个数的增多而线性扩展。很多语言都提供CAS原子操作(如Go中的atomic包和C++11中的atomic库),可以用于实现无锁数据结构,如无锁链表。
我们以一个简单的线程安全单向链表的插入操作来看下无锁编程和普通加锁的区别。
package listimport ("fmt""sync""sync/atomic""golang.org/x/sync/errgroup")// Node 链表节点type Node struct {Value interface{}Next *Node}//// 有锁单向链表的简单实现//// WithLockList 有锁单向链表type WithLockList struct {Head *Nodemu sync.Mutex}// Push 将元素插入到链表的首部func (l *WithLockList) Push(v interface{}) {l.mu.Lock()defer l.mu.Unlock()n := &Node{Value: v,Next: l.Head,}l.Head = n}// String 有锁链表的字符串形式输出func (l WithLockList) String() string {s := ""cur := l.Headfor {if cur == nil {break}if s != "" {s += ","}s += fmt.Sprintf("%v", cur.Value)cur = cur.Next}return s}//// 无锁单向链表的简单实现//// LockFreeList 无锁单向链表type LockFreeList struct {Head atomic.Value}// Push 有锁func (l *LockFreeList) Push(v interface{}) {for {head := l.Head.Load()headNode, _ := head.(*Node)n := &Node{Value: v,Next: headNode,}if l.Head.CompareAndSwap(head, n) {break}}}// String 有锁链表的字符串形式输出func (l LockFreeList) String() string {s := ""cur := l.Head.Load().(*Node)for {if cur == nil {break}if s != "" {s += ","}s += fmt.Sprintf("%v", cur.Value)cur = cur.Next}return s}
上面的实现有几点需要注意一下:
-
无锁单向链表实现时在插入时需要进行CAS操作,即调用CompareAndSwap()方法进行插入,如果插入失败则进行for循环多次尝试,直至成功。
-
为了方便打印链表内容,实现一个String()方法遍历链表,且使用值作为接收者,避免打印对象指针时无法生效。
If an operand implements method String() string, that method will be invoked to convert the object to a string, which will then be formatted as required by the verb (if any).
我们分别对两种链表做一个并发写入的操作验证一下其功能。
package mainimport ("fmt""main/list")// ConcurWriteWithLockList 并发写入有锁链表func ConcurWriteWithLockList(l *WithLockList) {var g errgroup.Group// 10 个协程并发写入链表for i := 0; i < 10; i++ {i := ig.Go(func() error {l.Push(i)return nil})}_ = g.Wait()}// ConcurWriteLockFreeList 并发写入无锁链表func ConcurWriteLockFreeList(l *LockFreeList) {var g errgroup.Group// 10 个协程并发写入链表for i := 0; i < 10; i++ {i := ig.Go(func() error {l.Push(i)return nil})}_ = g.Wait()}func main() {// 并发写入与遍历打印有锁链表l1 := &list.WithLockList{}list.ConcurWriteWithLockList(l1)fmt.Println(l1)// 并发写入与遍历打印无锁链表l2 := &list.LockFreeList{}list.ConcurWriteLockFreeList(l2)fmt.Println(l2)}
注意,多次运行上面的main()函数的结果可能会不相同,因为并发是无序的。
8,7,6,9,5,4,3,1,2,09,8,7,6,5,4,3,2,0,1
下面再看一下链表Push操作的基准测试,对比一下有锁与无锁的性能差异。
func BenchmarkWriteWithLockList(b *testing.B) {l := &WithLockList{}for n := 0; n < b.N; n++ {l.Push(n)}}BenchmarkWriteWithLockList-8 14234166 83.58 ns/opfunc BenchmarkWriteLockFreeList(b *testing.B) {l := &LockFreeList{}for n := 0; n < b.N; n++ {l.Push(n)}}BenchmarkWriteLockFreeList-8 15219405 73.15 ns/op
可以看出无锁版本比有锁版本性能高一些。
-
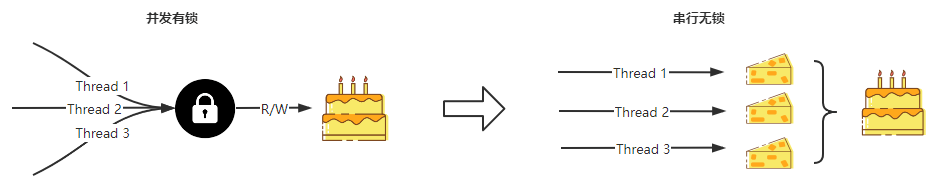
串行无锁
串行无锁是一种思想,就是避免对共享资源的并发访问,改为每个并发操作访问自己独占的资源,达到串行访问资源的效果,来避免使用锁。不同的场景有不同的实现方式。比如网络I/O场景下将单Reactor多线程模型改为主从Reactor多线程模型,避免对同一个消息队列锁读取。
这里我介绍的是后台微服务开发经常遇到的一种情况。我们经常需要并发拉取多方面的信息,汇聚到一个变量上。那么此时就存在对同一个变量互斥写入的情况。比如批量并发拉取用户信息写入到一个map。此时我们可以将每个协程拉取的结果写入到一个临时对象,这样便将并发地协程与同一个变量解绑,然后再将其汇聚到一起,这样便可以不用使用锁。即独立处理,然后合并。
为了模拟上面的情况,简单地写个示例程序,对比下性能。
import ("sync""golang.org/x/sync/errgroup")// ConcurWriteMapWithLock 有锁并发写入 mapfunc ConcurWriteMapWithLock() map[int]int {m := make(map[int]int)var mu sync.Mutexvar g errgroup.Group// 10 个协程并发写入 mapfor i := 0; i < 10; i++ {i := ig.Go(func() error {mu.Lock()defer mu.Unlock()m[i] = i * ireturn nil})}_ = g.Wait()return m}// ConcurWriteMapLockFree 无锁并发写入 mapfunc ConcurWriteMapLockFree() map[int]int {m := make(map[int]int)// 每个协程独占一 valuevalues := make([]int, 10)// 10 个协程并发写入 mapvar g errgroup.Groupfor i := 0; i < 10; i++ {i := ig.Go(func() error {values[i] = i * ireturn nil})}_ = g.Wait()// 汇聚结果到 mapfor i, v := range values {m[i] = v}return m}
看下二者的性能差异:
func BenchmarkConcurWriteMapWithLock(b *testing.B) {for n := 0; n < b.N; n++ {_ = ConcurWriteMapWithLock()}}BenchmarkConcurWriteMapWithLock-8 218673 5089 ns/opfunc BenchmarkConcurWriteMapLockFree(b *testing.B) {for n := 0; n < b.N; n++ {_ = ConcurWriteMapLockFree()}}BenchmarkConcurWriteMapLockFree-8 316635 4048 ns/op
-
减少锁竞争
如果加锁无法避免,则可以采用分片的形式,减少对资源加锁的次数,这样也可以提高整体的性能。
比如Golang优秀的本地缓存组件bigcache、go-cache、freecache都实现了分片功能,每个分片一把锁,采用分片存储的方式减少加锁的次数从而提高整体性能。
以一个简单的示例,通过对map[uint64]struct{}分片前后并发写入的对比,来看下减少锁竞争带来的性能提升。
var (num = 1000000m0 = make(map[int]struct{}, num)mu0 = sync.RWMutex{}m1 = make(map[int]struct{}, num)mu1 = sync.RWMutex{})// ConWriteMapNoShard 不分片写入一个 map。func ConWriteMapNoShard() {g := errgroup.Group{}for i := 0; i < num; i++ {g.Go(func() error {mu0.Lock()defer mu0.Unlock()m0[i] = struct{}{}return nil})}_ = g.Wait()}// ConWriteMapTwoShard 分片写入两个 map。func ConWriteMapTwoShard() {g := errgroup.Group{}for i := 0; i < num; i++ {g.Go(func() error {if i&1 == 0 {mu0.Lock()defer mu0.Unlock()m0[i] = struct{}{}return nil}mu1.Lock()defer mu1.Unlock()m1[i] = struct{}{}return nil})}_ = g.Wait()}
看下二者的性能差异:
func BenchmarkConWriteMapNoShard(b *testing.B) {for i := 0; i < b.N; i++ {ConWriteMapNoShard()}}BenchmarkConWriteMapNoShard-12 3 472063245 ns/opfunc BenchmarkConWriteMapTwoShard(b *testing.B) {for i := 0; i < b.N; i++ {ConWriteMapTwoShard()}}BenchmarkConWriteMapTwoShard-12 4 310588155 ns/op
可以看到,通过对分共享资源的分片处理,减少了锁竞争,能明显地提高程序的并发性能。可以预见的是,随着分片粒度地变小,性能差距会越来越大。当然,分片粒度不是越小越好。因为每一个分片都要配一把锁,那么会带来很多额外的不必要的开销。可以选择一个不太大的值,在性能和花销上寻找一个平衡。
-
优先使用共享锁而非互斥锁
如果并发无法做到无锁化,优先使用共享锁而非互斥锁。
所谓互斥锁,指锁只能被一个Goroutine获得。共享锁指可以同时被多个Goroutine获得的锁。
Go标准库sync提供了两种锁,互斥锁(sync.Mutex)和读写锁(sync.RWMutex),读写锁便是共享锁的一种具体实现。
-
sync.Mutex
互斥锁的作用是保证共享资源同一时刻只能被一个Goroutine占用,一个Goroutine占用了,其他的Goroutine则阻塞等待。
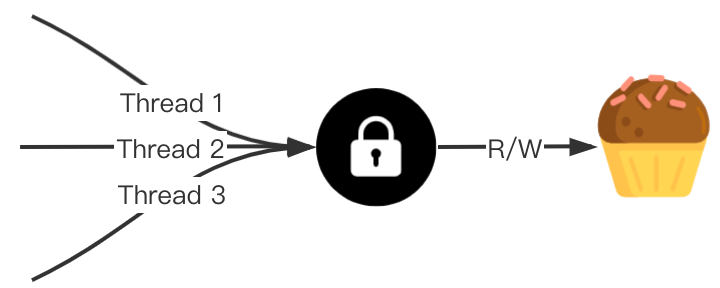
sync.Mutex提供了两个导出方法用来使用锁。
Lock() // 加锁Unlock() // 释放锁
我们可以通过在访问共享资源前前用Lock方法对资源进行上锁,在访问共享资源后调用Unlock方法来释放锁,也可以用defer语句来保证互斥锁一定会被解锁。在一个Go协程调用Lock方法获得锁后,其他请求锁的协程都会阻塞在Lock方法,直到锁被释放。
-
sync.RWMutex
读写锁是一种共享锁,也称之为多读单写锁 (multiple readers, single writer lock)。在使用锁时,对获取锁的目的操作做了区分,一种是读操作,一种是写操作。因为同一时刻允许多个Gorouine获取读锁,所以是一种共享锁。但写锁是互斥的。
一般来说,有如下几种情况:
-
读锁之间不互斥,没有写锁的情况下,读锁是无阻塞的,多个协程可以同时获得读锁。
-
写锁之间是互斥的,存在写锁,其他写锁阻塞。
-
写锁与读锁是互斥的,如果存在读锁,写锁阻塞,如果存在写锁,读锁阻塞。
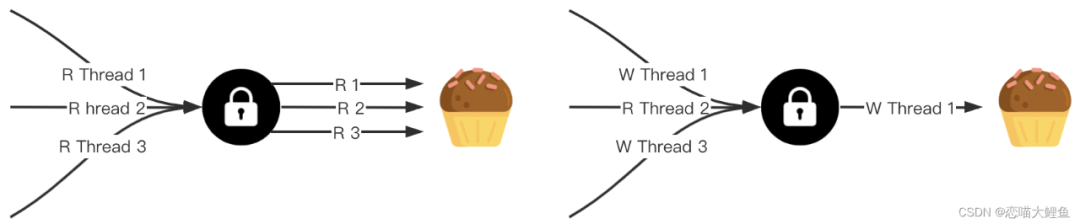
sync.RWMutex提供了五个导出方法用来使用锁。
Lock() // 加写锁Unlock() // 释放写锁RLock() // 加读锁RUnlock() // 释放读锁RLocker() Locker // 返回读锁,使用 Lock() 和 Unlock() 进行 RLock() 和 RUnlock()
读写锁的存在是为了解决读多写少时的性能问题,读场景较多时,读写锁可有效地减少锁阻塞的时间。
-
性能对比
大部分业务场景是读多写少,所以使用读写锁可有效提高对共享数据的访问效率。最坏的情况,只有写请求,那么读写锁顶多退化成互斥锁。所以优先使用读写锁而非互斥锁,可以提高程序的并发性能。
接下来,我们测试三种情景下,互斥锁和读写锁的性能差异。
-
读多写少(读占80%)
-
读写一致(各占50%)
-
读少写多(读占20%)
首先根据互斥锁和读写锁分别实现对共享map的并发读写。
// OpMapWithMutex 使用互斥锁读写 map。// rpct 为读操作占比。func OpMapWithMutex(rpct int) {m := make(map[int]struct{})mu := sync.Mutex{}var wg sync.WaitGroupfor i := 0; i < 100; i++ {i := iwg.Add(1)go func() {defer wg.Done()mu.Lock()defer mu.Unlock()// 写操作。if i >= rpct {m[i] = struct{}{}time.Sleep(time.Microsecond)return}// 读操作。_ = m[i]time.Sleep(time.Microsecond)}()}wg.Wait()}// OpMapWithRWMutex 使用读写锁读写 map。// rpct 为读操作占比。func OpMapWithRWMutex(rpct int) {m := make(map[int]struct{})mu := sync.RWMutex{}var wg sync.WaitGroupfor i := 0; i < 100; i++ {i := iwg.Add(1)go func() {defer wg.Done()// 写操作。if i >= rpct {mu.Lock()defer mu.Unlock()m[i] = struct{}{}time.Sleep(time.Microsecond)return}// 读操作。mu.RLock()defer mu.RUnlock()_ = m[i]time.Sleep(time.Microsecond)}()}wg.Wait()}
入参rpct用来调节读操作的占比,来模拟读写占比不同的场景。rpct设为80表示读多写少(读占80%),rpct设为50表示读写一致(各占50%),rpct设为20表示读少写多(读占20%)。
func BenchmarkMutexReadMore(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithMutex(80)}}func BenchmarkRWMutexReadMore(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithRWMutex(80)}}func BenchmarkMutexRWEqual(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithMutex(50)}}func BenchmarkRWMutexRWEqual(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithRWMutex(50)}}func BenchmarkMutexWriteMore(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithMutex(20)}}func BenchmarkRWMutexWriteMore(b *testing.B) {for i := 0; i < b.N; i++ {OpMapWithRWMutex(20)}}
执行当前包下的所有基准测试,结果如下:
goos: darwingoarch: amd64pkg: main/mutexcpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzPASSok main/mutex 9.532s
可见读多写少的场景,使用读写锁并发性能会更优。可以预见的是如果写占比更低,那么读写锁带的并发效果会更优。
这里需要注意的是,因为每次读写map的操作耗时很短,所以每次睡眠一微秒(百万分之一秒)来增加耗时,不然对共享资源的访问耗时,小于锁处理的本身耗时,那么使用读写锁带来的性能优化效果将变得不那么明显,甚至会降低性能。
(二)限制协程数量
-
协程数过多的问题
-
程序崩溃
Go程(goroutine)是由Go运行时管理的轻量级线程。通过它我们可以轻松实现并发编程。但是当我们无限开辟协程时,将会遇到致命的问题。
func main() {var wg sync.WaitGroupfor i := 0; i < math.MaxInt32; i++ {wg.Add(1)go func(i int) {defer wg.Done()fmt.Println(i)time.Sleep(time.Second)}(i)}wg.Wait()}
这个例子实现了math.MaxInt32个协程的并发,2^31-1约为20亿个,每个协程内部几乎没有做什么事情。正常的情况下呢,这个程序会乱序输出0~2^31-1个数字。
程序会像预期的那样顺利的运行吗?
go run main.go...1086681142025panic: too many concurrent operations on a single file or socket (max 1048575)goroutine 1158408 [running]:internal/poll.(*fdMutex).rwlock(0xc0000ae060, 0x0)/usr/local/go/src/internal/poll/fd_mutex.go:147 +0x11binternal/poll.(*FD).writeLock(...)/usr/local/go/src/internal/poll/fd_mutex.go:239internal/poll.(*FD).Write(0xc0000ae060, {0xc12cadf690, 0x8, 0x8})/usr/local/go/src/internal/poll/fd_unix.go:262 +0x72os.(*File).write(...)/usr/local/go/src/os/file_posix.go:49os.(*File).Write(0xc0000ac008, {0xc12cadf690, 0x1, 0xc12ea62f50})/usr/local/go/src/os/file.go:176 +0x65fmt.Fprintln({0x10c00e0, 0xc0000ac008}, {0xc12ea62f90, 0x1, 0x1})/usr/local/go/src/fmt/print.go:265 +0x75fmt.Println(...)/usr/local/go/src/fmt/print.go:274main.main.func1(0x0)/Users/dablelv/work/code/test/main.go:16 +0x8f...
运行的结果是程序直接崩溃了,关键的报错信息是:
panic: too many concurrent operations on a single file or socket (max 1048575)
对单个file/socket的并发操作个数超过了系统上限,这个报错是fmt.Printf函数引起的,fmt.Printf将格式化后的字符串打印到屏幕,即标准输出。在Linux系统中,标准输出也可以视为文件,内核(Kernel)利用文件描述符(File Descriptor)来访问文件,标准输出的文件描述符为1,错误输出文件描述符为2,标准输入的文件描述符为0。
简而言之,系统的资源被耗尽了。
那如果我们将fmt.Printf这行代码去掉呢?那程序很可能会因为内存不足而崩溃。这一点更好理解,每个协程至少需要消耗2KB的空间,那么假设计算机的内存是4GB,那么至多允许4GB/2KB=1M个协程同时存在。那如果协程中还存在着其他需要分配内存的操作,那么允许并发执行的协程将会数量级地减少。
-
协程的代价
前面的例子过于极端,一般情况下程序也不会无限开辟协程,旨在说明协程数量是有限制的,不能无限开辟。
如果我们开辟很多协程,但不会导致程序崩溃,可以吗?如果真要这么做的话,我们应该清楚地知道,协程虽然轻量,但仍有开销。
Go的开销主要是三个方面:创建(占用内存)、调度(增加调度器负担)和删除(增加GC压力)。
-
内存开销
空间上,一个Go程占用约2K的内存,在源码src/runtime/runtime2.go里面,我们可以找到Go程的结构定义type g struct。
-
调度开销
时间上,协程调度也会有CPU开销。我们可以利用runntime.Gosched()让当前协程主动让出CPU去执行另外一个协程,下面看一下协程之间切换的耗时。
const NUM = 10000func cal() {for i := 0; i < NUM; i++ {runtime.Gosched()}}func main() {// 只设置一个 Processorruntime.GOMAXPROCS(1)start := time.Now().UnixNano()go cal()for i := 0; i < NUM; i++ {runtime.Gosched()}end := time.Now().UnixNano()fmt.Printf("total %vns per %vns", end-start, (end-start)/NUM)}
运行输出:
total 997200ns per 99ns
可见一次协程的切换,耗时大概在100ns,相对于线程的微秒级耗时切换,性能表现非常优秀,但是仍有开销。
-
GC开销
创建Go程到运行结束,占用的内存资源是需要由GC来回收,如果无休止地创建大量Go程后,势必会造成对GC的压力。
package mainimport ("fmt""runtime""runtime/debug""sync""time")func createLargeNumGoroutine(num int, wg *sync.WaitGroup) {wg.Add(num)for i := 0; i < num; i++ {go func() {defer wg.Done()}()}}func main() {// 只设置一个 Processor 保证 Go 程串行执行runtime.GOMAXPROCS(1)// 关闭GC改为手动执行debug.SetGCPercent(-1)var wg sync.WaitGroupcreateLargeNumGoroutine(1000, &wg)wg.Wait()t := time.Now()runtime.GC() // 手动GCcost := time.Since(t)fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 1000)createLargeNumGoroutine(10000, &wg)wg.Wait()t = time.Now()runtime.GC() // 手动GCcost = time.Since(t)fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 10000)createLargeNumGoroutine(100000, &wg)wg.Wait()t = time.Now()runtime.GC() // 手动GCcost = time.Since(t)fmt.Printf("GC cost %v when goroutine num is %v\n", cost, 100000)}
运行输出:
GC cost 0s when goroutine num is 1000GC cost 2.0027ms when goroutine num is 10000GC cost 30.9523ms when goroutine num is 100000
当创建的Go程数量越多,GC耗时越大。
上面的分析目的是为了尽可能地量化Goroutine的开销。虽然官方宣称用 Golang写并发程序的时候随便起个成千上万的Goroutine毫无压力,但当我们起十万、百万甚至千万个Goroutine呢?Goroutine轻量的开销将被放大。
-
限制协程数量
系统地资源是有限,协程是有代价的,为了保护程序,提高性能,我们应主动限制并发的协程数量。
可以利用信道channel的缓冲区大小来实现。
func main() {var wg sync.WaitGroupch := make(chan struct{}, 3)for i := 0; i < 10; i++ {ch <- struct{}{}wg.Add(1)go func(i int) {defer wg.Done()log.Println(i)time.Sleep(time.Second)<-ch}(i)}wg.Wait()}
上例中创建了缓冲区大小为3的channel,在没有被接收的情况下,至多发送3个消息则被阻塞。开启协程前,调用ch<- struct{}{},若缓存区满,则阻塞。协程任务结束,调用<-ch释放缓冲区。
sync.WaitGroup并不是必须的,例如Http服务,每个请求天然是并发的,此时使用channel控制并发处理的任务数量,就不需要 sync.WaitGroup。
运行结果如下:
2022/03/06 20:37:02 02022/03/06 20:37:02 22022/03/06 20:37:02 12022/03/06 20:37:03 32022/03/06 20:37:03 42022/03/06 20:37:03 52022/03/06 20:37:04 62022/03/06 20:37:04 72022/03/06 20:37:04 82022/03/06 20:37:05 9
从日志中可以很容易看到,每秒钟只并发执行了3个任务,达到了协程并发控制的目的。
-
协程池化
上面的例子只是简单地限制了协程开辟的数量。在此基础之上,基于对象复用的思想,我们可以重复利用已开辟的协程,避免协程的重复创建销毁,达到池化的效果。
协程池化,我们可以自己写一个协程池,但不推荐这么做。因为已经有成熟的开源库可供使用,无需再重复造轮子。目前有很多第三方库实现了协程池,可以很方便地用来控制协程的并发数量,比较受欢迎的有:
-
Jeffail/tunny
-
panjf2000/ants
下面以panjf2000/ants为例,简单介绍其使用。
ants是一个简单易用的高性能Goroutine池,实现了对大规模Goroutine的调度管理和复用,允许使用者在开发并发程序的时候限制Goroutine数量,复用协程,达到更高效执行任务的效果。
package mainimport ("fmt""time""github.com/panjf2000/ants")func main() {// Use the common poolfor i := 0; i < 10; i++ {i := iants.Submit(func() {fmt.Println(i)})}time.Sleep(time.Second)}
使用ants,我们简单地使用其默认的协程池,直接将任务提交并发执行。默认协程池的缺省容量math.MaxInt32。
如果自定义协程池容量大小,可以调用NewPool方法来实例化具有给定容量的池,如下所示:
// Set 10000 the size of goroutine poolp, _ := ants.NewPool(10000)
-
小结
Golang为并发而生。Goroutine是由Go运行时管理的轻量级线程,通过它我们可以轻松实现并发编程。Go虽然轻量,但天下没有免费的午餐,无休止地开辟大量Go程势必会带来性能影响,甚至程序崩溃。所以,我们应尽可能的控制协程数量,如果有需要,请复用它。
(三)使用sync.Once避免重复执行
-
简介
sync.Once是Go标准库提供的使函数只执行一次的实现,常应用于单例模式,例如初始化配置、保持数据库连接等。作用与init函数类似,但有区别。
-
init函数是当所在的package首次被加载时执行,若迟迟未被使用,则既浪费了内存,又延长了程序加载时间。
-
sync.Once可以在代码的任意位置初始化和调用,因此可以延迟到使用时再执行,并发场景下是线程安全的。
在多数情况下,sync.Once被用于控制变量的初始化,这个变量的读写满足如下三个条件:
-
当且仅当第一次访问某个变量时,进行初始化(写);
-
变量初始化过程中,所有读都被阻塞,直到初始化完成;
-
变量仅初始化一次,初始化完成后驻留在内存里。
-
原理
sync.Once用来保证函数只执行一次。要达到这个效果,需要做到两点:
-
计数器,统计函数执行次数;
-
线程安全,保障在多Go程的情况下,函数仍然只执行一次,比如锁。
-
源码
下面看一下sync.Once结构,其有两个变量。使用done统计函数执行次数,使用锁m实现线程安全。果不其然,和上面的猜想一致。
// Once is an object that will perform exactly one action.//// A Once must not be copied after first use.type Once struct {// done indicates whether the action has been performed.// It is first in the struct because it is used in the hot path.// The hot path is inlined at every call site.// Placing done first allows more compact instructions on some architectures (amd64/386),// and fewer instructions (to calculate offset) on other architectures.done uint32m Mutex}
sync.Once仅提供了一个导出方法Do(),参数f是只会被执行一次的函数,一般为对象初始化函数。
// go version go1.17 darwin/amd64// Do calls the function f if and only if Do is being called for the// first time for this instance of Once. In other words, given// var once Once// if once.Do(f) is called multiple times, only the first call will invoke f,// even if f has a different value in each invocation. A new instance of// Once is required for each function to execute.//// Do is intended for initialization that must be run exactly once. Since f// is niladic, it may be necessary to use a function literal to capture the// arguments to a function to be invoked by Do:// config.once.Do(func() { config.init(filename) })//// Because no call to Do returns until the one call to f returns, if f causes// Do to be called, it will deadlock.//// If f panics, Do considers it to have returned; future calls of Do return// without calling f.//func (o *Once) Do(f func()) {// Note: Here is an incorrect implementation of Do://// if atomic.CompareAndSwapUint32(&o.done, 0, 1) {// f()// }//// Do guarantees that when it returns, f has finished.// This implementation would not implement that guarantee:// given two simultaneous calls, the winner of the cas would// call f, and the second would return immediately, without// waiting for the first's call to f to complete.// This is why the slow path falls back to a mutex, and why// the atomic.StoreUint32 must be delayed until after f returns.if atomic.LoadUint32(&o.done) == 0 {// Outlined slow-path to allow inlining of the fast-path.o.doSlow(f)}}func (o *Once) doSlow(f func()) {o.m.Lock()defer o.m.Unlock()if o.done == 0 {defer atomic.StoreUint32(&o.done, 1)f()}}
抛去大段的注释,可以看到sync.Once实现非常简洁。Do()函数中,通过对成员变量done的判断,来决定是否执行传入的任务函数。执行任务函数前,通过锁保证任务函数的执行和done的修改是一个互斥操作。在执行任务函数前,对done做一个二次判断,来保证任务函数只会被执行一次,done只会被修改一次。
-
done为什么是第一个字段
从字段done前有一段注释,说明了done为什么是第一个字段。
done在热路径中,done放在第一个字段,能够减少CPU指令,也就是说,这样做能够提升性能。
热路径(hot path)是程序非常频繁执行的一系列指令,sync.Once绝大部分场景都会访问o.done,在热路径上是比较好理解的。如果hot path 编译后的机器码指令更少,更直接,必然是能够提升性能的。
为什么放在第一个字段就能够减少指令呢?因为结构体第一个字段的地址和结构体的指针是相同的,如果是第一个字段,直接对结构体的指针解引用即可。如果是其他的字段,除了结构体指针外,还需要计算与第一个值的偏移(calculate offset)。在机器码中,偏移量是随指令传递的附加值,CPU需要做一次偏移值与指针的加法运算,才能获取要访问的值的地址。因为,访问第一个字段的机器代码更紧凑,速度更快。
-
性能差异
我们以一个简单示例,来说明使用sync.Once保证函数只会被执行一次和多次执行,二者的性能差异。
考虑一个简单的场景,函数ReadConfig需要读取环境变量,并转换为对应的配置。环境变量在程序执行前已经确定,执行过程中不会发生改变。ReadConfig可能会被多个协程并发调用,为了提升性能(减少执行时间和内存占用),使用sync.Once是一个比较好的方式。
type Config struct {GoRoot stringGoPath string}var (once sync.Onceconfig *Config)func ReadConfigWithOnce() *Config {once.Do(func() {config = &Config{GoRoot: os.Getenv("GOROOT"),GoPath: os.Getenv("GOPATH"),}})return config}func ReadConfig() *Config {return &Config{GoRoot: os.Getenv("GOROOT"),GoPath: os.Getenv("GOPATH"),}}
我们看下二者的性能差异。
func BenchmarkReadConfigWithOnce(b *testing.B) {for i := 0; i < b.N; i++ {_ = ReadConfigWithOnce()}}func BenchmarkReadConfig(b *testing.B) {for i := 0; i < b.N; i++ {_ = ReadConfig()}}
执行测试结果如下:
go test -bench=. main/oncegoos: darwingoarch: amd64pkg: main/oncecpu: Intel(R) Core(TM) i7-9750H CPU @ 2.60GHzPASSok main/once 3.006s
sync.Once中保证了Config初始化函数仅执行了一次,避免了多次重复初始化,在并发环境下很有用。
(四)使用sync.Cond通知协程
-
简介
sync.Cond是基于互斥锁/读写锁实现的条件变量,用来协调想要访问共享资源的那些Goroutine,当共享资源的状态发生变化的时候,sync.Cond 可以用来通知等待条件发生而阻塞的Goroutine。
sync.Cond基于互斥锁/读写锁,它和互斥锁的区别是什么呢?
互斥锁sync.Mutex通常用来保护共享的临界资源,条件变量sync.Cond 用来协调想要访问共享资源的Goroutine。当共享资源的状态发生变化时,sync.Cond可以用来通知被阻塞的Goroutine。
-
使用场景
sync.Cond经常用在多个Goroutine等待,一个Goroutine通知(事件发生)的场景。如果是一个通知,一个等待,使用互斥锁或channel就能搞定了。
我们想象一个非常简单的场景:
有一个协程在异步地接收数据,剩下的多个协程必须等待这个协程接收完数据,才能读取到正确的数据。在这种情况下,如果单纯使用chan或互斥锁,那么只能有一个协程可以等待,并读取到数据,没办法通知其他的协程也读取数据。
这个时候,就需要有个全局的变量来标志第一个协程数据是否接受完毕,剩下的协程,反复检查该变量的值,直到满足要求。或者创建多个channel,每个协程阻塞在一个channel上,由接收数据的协程在数据接收完毕后,逐个通知。总之,需要额外的复杂度来完成这件事。
Go语言在标准库sync中内置一个sync.Cond用来解决这类问题。
-
原理
sync.Cond内部维护了一个等待队列,队列中存放的是所有在等待这个 sync.Cond的Go程,即保存了一个通知列表。sync.Cond可以用来唤醒一个或所有因等待条件变量而阻塞的Go程,以此来实现多个Go程间的同步。
sync.Cond的定义如下:
// Cond implements a condition variable, a rendezvous point// for goroutines waiting for or announcing the occurrence// of an event.//// Each Cond has an associated Locker L (often a *Mutex or *RWMutex),// which must be held when changing the condition and// when calling the Wait method.//// A Cond must not be copied after first use.type Cond struct {noCopy noCopy// L is held while observing or changing the conditionL Lockernotify notifyListchecker copyChecker}
每个Cond实例都会关联一个锁L(互斥锁Mutex,或读写锁RWMutex),当修改条件或者调用Wait方法时,必须加锁。
sync.Cond的四个成员函数定义如下:
// NewCond returns a new Cond with Locker l.func NewCond(l Locker) *Cond {return &Cond{L: l}}
NewCond创建Cond实例时,需要关联一个锁。
// Wait atomically unlocks c.L and suspends execution// of the calling goroutine. After later resuming execution,// Wait locks c.L before returning. Unlike in other systems,// Wait cannot return unless awoken by Broadcast or Signal.//// Because c.L is not locked when Wait first resumes, the caller// typically cannot assume that the condition is true when// Wait returns. Instead, the caller should Wait in a loop://// c.L.Lock()// for !condition() {// c.Wait()// }// ... make use of condition ...// c.L.Unlock()//func (c *Cond) Wait() {c.checker.check()t := runtime_notifyListAdd(&c.notify)c.L.Unlock()runtime_notifyListWait(&c.notify, t)c.L.Lock()}
Wait用于阻塞调用者,等待通知。调用Wait会自动释放锁c.L,并挂起调用者所在的goroutine。如果其他协程调用了Signal或Broadcast唤醒了该协程,那么Wait方法在结束阻塞时,会重新给c.L加锁,并且继续执行Wait后面的代码。
对条件的检查,使用了for !condition()而非if,是因为当前协程被唤醒时,条件不一定符合要求,需要再次Wait等待下次被唤醒。为了保险起,使用for能够确保条件符合要求后,再执行后续的代码。
// Signal wakes one goroutine waiting on c, if there is any.//// It is allowed but not required for the caller to hold c.L// during the call.func (c *Cond) Signal() {c.checker.check()runtime_notifyListNotifyOne(&c.notify)}// Broadcast wakes all goroutines waiting on c.//// It is allowed but not required for the caller to hold c.L// during the call.func (c *Cond) Broadcast() {c.checker.check()runtime_notifyListNotifyAll(&c.notify)}
Signal只唤醒任意1个等待条件变量c的goroutine,无需锁保护。Broadcast唤醒所有等待条件变量c的goroutine,无需锁保护。
-
使用示例
我们实现一个简单的例子,三个协程调用Wait()等待,另一个协程调用Broadcast()唤醒所有等待的协程。
var done = falsefunc read(name string, c *sync.Cond) {c.L.Lock()for !done {c.Wait()}log.Println(name, "starts reading")c.L.Unlock()}func write(name string, c *sync.Cond) {log.Println(name, "starts writing")time.Sleep(time.Second)done = truelog.Println(name, "wakes all")c.Broadcast()}func main() {cond := sync.NewCond(&sync.Mutex{})go read("reader1", cond)go read("reader2", cond)go read("reader3", cond)write("writer", cond)time.Sleep(time.Second * 3)}
done即多个Goroutine 阻塞等待的条件。
read()调用Wait()等待通知,直到done为true。
write()接收数据,接收完成后,将done置为true,调用Broadcast()通知所有等待的协程。
write()中的暂停了1s,一方面是模拟耗时,另一方面是确保前面的3个 read协程都执行到Wait(),处于等待状态。main函数最后暂停了3s,确保所有操作执行完毕。
运行输出:
go run main.go2022/03/07 17:20:09 writer starts writing2022/03/07 17:20:10 writer wakes all2022/03/07 17:20:10 reader3 starts reading2022/03/07 17:20:10 reader1 starts reading2022/03/07 17:20:10 reader2 starts reading
-
注意事项
-
sync.Cond不能被复制
sync.Cond不能被复制的原因,并不是因为其内部嵌套了Locker。因为 NewCond时传入的Mutex/RWMutex指针,对于Mutex指针复制是没有问题的。
主要原因是sync.Cond内部是维护着一个Goroutine通知队列 notifyList。如果这个队列被复制的话,那么就在并发场景下导致不同 Goroutine之间操作的notifyList.wait、notifyList.notify并不是同一个,这会导致出现有些Goroutine会一直阻塞。
-
唤醒顺序
从等待队列中按照顺序唤醒,先进入等待队列,先被唤醒。
-
调用Wait()前要加锁
调用Wait()函数前,需要先获得条件变量的成员锁,原因是需要互斥地变更条件变量的等待队列。在Wait()返回前,会重新上锁。
参考资料:
1.github.com/uber-go/guide
2.go-proverbs
3.github/dgryski/go-perfbook
4.High Performance Go Workshop - Dave Cheney
5.atomic 的原理与使用场景
6.极客兔兔.Go 语言高性能编程
7.深度解密Go 语言之sync.Pool-Stefno-博客园
8.Golang内存分配逃逸分析-Gopherzhang
9.Go语言的内存逃逸分析-Golang梦工厂
作者简介

吕吕
腾讯后台开发工程师
腾讯后台开发工程师,毕业于华南理工大学。目前负责NokNok后台开发工作,有丰富的分布式后台开发经验。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号