ZFS
GitHub - openzfs/zfs: OpenZFS on Linux and FreeBSD https://github.com/openzfs/zfs
ZFS_百度百科 https://baike.baidu.com/item/ZFS/4367733
ZFS文件系统的英文名称为Zettabyte File System,也叫动态文件系统(Dynamic File System),是第一个128位文件系统。最初是由Sun公司为Solaris 10操作系统开发的文件系统。作为OpenSolaris开源计划的一部分,ZFS于2005年11月发布,被Sun称为是终极文件系统,经历了 10 年的活跃开发。而最新的开发将全面开放,并重新命名为 OpenZFS
- 中文名
- ZFS(Zettabyte File System)
- 开发公司
- Sun
- 发布时间
- 2005年11月
- 别 名
- 动态文件系统
ZFS的设计与开发由Sun公司的Jeff Bonwick所领导的一支团队完成。最早宣布于2004年9月14日,于2005年10月31日并入了Solaris开发的主干源代码。并在2005年11月16日作为OpenSolaris build 27的一部分发布。Sun在OpenSolaris社区开张1年后的2006年六月,将ZFS集成进了Solaris 10 6/06版本更新。
ZFS的命名来源发想于"ZettabyteFile System"的首字母缩写。但 ZFS 本身并不具备任何的缩写意涵,只是作者想阐述做为一个具备高扩充容量文件系统且还有支持许多延伸功能的一个产品。
ZFS是一款128bit文件系统,总容量是现有64bit文件系统的1.84x10^19倍,其支持的单个存储卷容量达到16EiB(2^64byte,即 16x1024x1024TB);一个zpool存储池可以拥有2^64个卷,总容量最大256ZiB(2^78byte);整个系统又可以拥有2^64个存储 池。可以说在相当长的未来时间内,ZFS几乎不太可能出现存储空间不足的问题。另外,它还拥有自优化,自动校验数据完整性,存储池/卷系统易管理等诸多优点。较ext3系统有较大运行速率,提高大约30%-40%。
 ZFS
ZFS什么是ZFS
ZFS 文件系统是一个革命性的全新的文件系统,它从根本上改变了文件系统的管理方式,这个文件系统的特色和其带来的好处至今没有其他文件系统可以与之媲美,ZFS 被设计成强大的、可升级并易于管理的。
ZFS 用“存储池”的概念来管理物理存储空间。过去,文件系统都是构建在物理设备之上的。为了管理这些物理设备,并为数据提供冗余,“卷管理”的概念提供了一个单设备的映像。但是这种设计增加了复杂性,同时根本没法使文件系统向更高层次发展,因为文件系统不能跨越数据的物理位置。
ZFS 完全抛弃了“卷管理”,不再创建虚拟的卷,而是把所有设备集中到一个存储池中来进行管理!“存储池”描述了存储的物理特征(设备的布局,数据的冗余等等),并扮演一个能够创建文件系统的专门存储空间。从此,文件系统不再局限于单独的物理设备,而且文件系统还允许物理设备把他们自带的那些文件系统共享到这个“池”中。你也不再需要预先规划好文件系统的大小,因为文件系统可以在“池”的空间内自动的增大。当增加新的存贮介质时,所有“池”中的所有文件系统能立即使用新增的空间,而不需要额外的操作。在很多情况下,存储池扮演了一个虚拟内存。
ZFS使用一种写时拷贝事务模型技术。所有文件系统中的块指针都包括256位的能在读时被重新校验的关于目标块的校验和。含有活动数据的块从来不被覆盖;而是分配一个新块,并把修改过的数据写在新块上。所有与该块相关的元数据块都被重新读、分配和重写。为了减少该过程的开销,多次读写更新被归纳为一个事件组,并且在必要的时候使用日志来同步写操作。
利用写时拷贝使ZFS的快照和事物功能的实现变得更简单和自然,快照功能更灵活。缺点是,COW使碎片化问题更加严重,对于顺序写生成的大文件,如果以后随机的对其中的一部分进行了更改,那么这个文件在硬盘上的物理地址就变得不再连续,未来的顺序读会变得性能比较差。
创建一个池的例子
|
1
|
#zpoolcreatetankmirrorc1t0d0c1t1d0 |
这是一个被镜像了的池,名叫“tank”。如果命令中的设备包含有其他的文件系统或者以别的形式被使用,那么命令不能执行。
要查看池是否成功创建,用 zpool list 命令,例如:
|
1
2
3
|
#zpoollistNAMESIZEUSEDAVAILCAPHEALTHALTROOTtank80G137K80G0%ONLINE- |
不同于传统文件系统需要驻留于单独设备或者需要一个卷管理系统去使用一个以上的设备,ZFS创建在虚拟的,被称为“zpools”的存储池之上(存储池最早在AdvFS实现,并且加到后来的Btrfs)。每个存储池由若干虚拟设备(virtual devices,vdevs)组成。这些虚拟设备可以是原始磁盘,也可能是一个RAID1镜像设备,或是非标准RAID等级的多磁盘组。于是zpool上的文件系统可以使用这些虚拟设备的总存储容量。
可以使用磁盘限额以及设置磁盘预留空间来限制存储池中单个文件系统所占用的空间。
ZFS是一个128位的文件系统,这意味着它能存储1800亿亿(18.4 × 10)倍于当前64位文件系统的数据。ZFS的设计如此超前以至于这个极限就当前现实实际可能永远无法遇到。项目领导Bonwick曾说:“要填满一个128位的文件系统,将耗尽地球上所有存储设备。除非你拥有煮沸整个海洋的能量,不然你不可能将其填满。(Populating 128-bit file systems would exceed the quantum limits of earth-based storage. You couldn't fill a 128-bit storage pool without boiling the oceans.)”
以下是ZFS的一些理论极限:
· 2—任意文件系统的快照数量(2 × 10)
· 2—任何单独文件系统的文件数(2 × 10)
· 16exabytes (2byte)—文件系统最大尺寸
· 16exabytes (2byte)—最大单个文件尺寸
· 16exabytes (2byte)—最大属性大小
· 128Zettabytes (2byte)—最大zpool大小
· 2—单个文件的属性数量(受ZFS文件数量的约束,实际为2)
· 2—单个目录的文件数(受ZFS文件数量的约束,实际为2)
· 2—单一zpool的设备数
· 2—系统的zpools数量
· 2—单一zpool的文件系统数量
作为对这些数字的感性认识,假设每秒钟创建1,000个新文件,达到ZFS文件数极限需要大约9,000年。
在辩解填满ZFS与煮沸海洋的关系时,Bonwick写到:
尽管我们都希望摩尔定律永远延续,但是量子力学给定了任何物理设备上计算速率(computation rate)与信息量的理论极限。举例而言,一个质量为1公斤,体积为1升的物体,每秒至多在10位信息上进行10次运算。一个完全的128位存储池将包含2个块= 2字节= 2位;应此,保存这些数据位至少需要(2位) / (10位/公斤) = 1360亿公斤的物质。
ZFS使用一种写时拷贝事务模型技术。所有文件系统中的块指针都包括256位的能在读时被重新校验的关于目标块的校验和。含有活动数据的块从来不被覆盖;而是分配一个新块,并把修改过的数据写在新块上。所有与该块相关的元数据块都被重新读、分配和重写。为了减少该过程的开销,多次读写更新被归纳为一个事件组,并且在必要的时候使用日志来同步写操作。
利用写时拷贝使ZFS的快照和事物功能的实现变得更简单和自然,快照功能更灵活。缺点是,COW使碎片化问题更加严重,对于顺序写生成的大文件,如果以后随机的对其中的一部分进行了更改,那么这个文件在硬盘上的物理地址就变得不再连续,未来的顺序读会变得性能比较差。
ZFS使用写时拷贝技术的一个优势在于,写新数据时,包含旧数据的块被保留着,提供了一个可以被保留的文件系统的快照版本。由于ZFS在读写操作中已经存储了所有构建快照的数据,所以快照的创建非常快。而且由于任何文件的修改都是在文件系统和它的快照之间共享的,所以ZFS的快照也是空间优化的。
可写快照("克隆")也可以被创建。结果就是两个独立的文件系统共享一些列的块。当任何一个克隆版本的文件系统被改变时,新的数据块为了反映这些改变而创建,但是不管有多少克隆版本的存在,未改变的块仍然在其他的克隆版本中共享
ZFS能动态条带化所有设备以最大化吞吐量。当额外的设备被加入到zpool中的时候,条带宽度会自动扩展以包含这些设备。这使得存储池中的所有磁盘都被用到,同时负载被平摊到所有的磁盘上。
ZFS使用可变大小的块,最大可至128KB。现有的代码允许管理员调整最大块大小,这在大块效果不好的时候有用。未来也许能做到自动调整适合工作量的块大小。
ZFS的可变大小的块与BtrFS和Ext4的extent不同。在ZFS中,在一个文件中所有数据块的逻辑长度必须是相同的,不同文件之间的块大小可以不同,因此ZFS可以用直接映射(direct map)的方式(同ufs/ffs/ext2/ext3)来来搜索间接块的数据指针数组(blkptr)。BtrFS和Ext4的extent方式在同一个文件中每个数据快的大小都可以不相同,因此需要用B+ Tree或者类B Tree的方式来组织间接块的数据。
虽然直接映射方式比B+ Tree的查找速度快,但是这种方式的缺点也非常明显,如:元数据开销过大、顺序IO的大文件性能不好、删除比较慢等等,因此在现代文件系统中映射方式逐渐被extent变长块取代。
如果数据压缩(LZJB)被启用,可变块大小需要被用到。如果一个数据块可被压缩至一个更小的数据块,则小的数据块将使用更少的存储和提高吞吐量(代价是增加CPU压缩和解压缩的负担)。
· Sun Solaris
· Illumos发行版
· FreeBSD
· Mac OS X Server 10.5
· NetBSD
· Linux(通过用户空间文件系统或原生第三方内核可加载核心模组支持)
不管层次如何,根总是池的名字。
⒈为每个用户及项目创建一个文件系统是个不错的办法!
⒉ZFS可以为文件系统分组,属于同一组的文件系统具有相似的性质,这有点像用户组的概念!相似的文件系统能够使用一个共同的名字。
创建一个文件系统
|
1
|
#zfscreatetank/home |
下一步,就可以创建各个文件系统,把它们都归组到 home 这个文件系统中。
同时可以设置home的特性,让组内的其他文件系统继承的它的这些特性。
当一个文件系统层次创建之后,可以为这个文件系统设置一些特性,这些特性将被所有的用户共享:
|
1
2
3
4
5
6
|
#zfssetmountpoint=/export/zfstank/home#zfssetsharenfs=ontank/home#zfssetcompression=ontank/home#zfsgetcompressiontank/homeNAMEPROPERTYVALUESOURCEtank/homecompressiononlocal |
⒋创建单个的文件系统
注意:这些文件系统如果被创建好,他们的特性的改变将被限制在home级别,所有的特性能够在文件系统的使用过程中动态的改变。
|
1
2
|
#zfscreatetank/home/bonwick#zfscreatetank/home/billm |
bonwick、billm文件系统从父文件系统home中继承了特性,因此他们被自动的mount到/export/zfs/user 同时作为被共享的NFS。管理员根本不需要再手工去编辑 /etc/vfstab 或 /etc/dfs/dfstab 文件。
每个文件系统除了继承特性外,还可以有自己的特性,如果用户bonwick的磁盘空间要限制在10G。
|
1
|
#zfssetquota=10Gtank/home/bonwick |
⒌用 zfs list 命令查看可获得的文件系统的信息,类似于过去的 df -k 命令了,呵呵 .
|
1
2
3
4
5
6
|
#zfslistNAMEUSEDAVAILREFERMOUNTPOINTtank92.0K67.0G9.5K/tanktank/home24.0K67.0G8K/export/zfstank/home/billm8K67.0G8K/export/zfs/billmtank/home/bonwick8K10.0G8K/export/zfs/bonwick |
-
传统的文件系统被限制在单个磁盘设备之内,它们的尺寸是不能超越单个磁盘设备。
-
过去的文件系统是被影射到一个物理存储单元,如:分区;所有的ZFS文件系统共享池内的可获得的存储空间。
-
ZFS 文件系统不需要通过编辑/etc/vfstab 文件来维护。
ZFS已经抛弃了卷管理,逻辑卷可以不再使用。因为ZFS在使用和管理raw设备能够有更好的表现。
Components of a ZFS Storage Pool
组成ZFS存储池的元件有:磁盘、文件、虚拟设备,其中磁盘可以是整个硬盘(c1t0d0),也可以是单个slice(c0t0d0s7)。推荐使用整个硬盘,这样可以省去分区操作(format)。
RAID-Z 跟 RAID-5的区别
传统的raid-5都存在着“写漏洞”,就是说如果raid-5的stripe在正写数据时,如果这时候电源中断,那么奇偶校验数据将跟该部分数据不同步,因此前边的写无效;RAID-Z用了“variable-width RAID stripes”技术,因此所有的写都是full-stripe writes。之所以能实现这种技术,就是因为ZFS集成了文件系统和设备管理,使得文件系统的元数据有足够的信息来控制“variable-width RAID stripes”
理论上说,创建RAID-Z需要至少三块磁盘,这跟raid-5差不多。例如:
raidz c1t0d0 c2t0d0 c3t0d0
还可以更加复杂一点,例如:
raidz c1t0d0 c2t0d0 c3t0d0 c4t0d0 c5t0d0 c6t0d0 c7t0d0 raidz c8t0d0 c9t0d0 c10t0d0 c11t0d0 c12t0d0 c13t0d0 c14t0d0
上边这个例子创建了14个磁盘的RAID-Z , 这14个盘被分成了两组,但下边这句话有点不大明白:
RAID-Z configurations with single-digit groupings of disks should perform better.
(我的理解是:相对于大于10个硬盘组成的RAID-Z,少于10个(single-digit 即1位数)硬盘组成的RAID-Z的性能会更好) 奇数个硬盘(>3)组成的RAID-Z在理论上来说会表现的更好(实际测试中也是,同RAID-5)
(我认为原文说的意思是,RAID-Z的设置属性是这些磁盘划在一个组里性能更好。//loong)
RAID-Z具有自动修复数据的功能
当有损坏的数据块被检测到,ZFS不但能从备份中找到相同的正确的数据,而且还能自动的用正确数据修复损坏的数据。
⒈创建一个基本的存储池,方法很简单:
|
1
|
#zpoolcreatetankc1t0d0c1t1d0 |
这时可以在 /dev/dsk 目录下看到一个大的slice,数据动态的stripe跨过所有磁盘!
⒉创建一个镜像的存储池
也是很简单,只要在上边命令基础上增加“mirror”关键字就可以了,下边是创建一个两路(two-way)镜像的例子:
|
1
|
#zpoolcreatetankmirrorc1d0c2d0mirrorc3d0c4d0 |
⒊创建RAID-Z存储池
使用“raidz”关键字就可以了,例如:
|
1
|
#zpoolcreatetankraidzc1t0d0c2t0d0c3t0d0c4t0d0/dev/dsk/c5t0d0 |
这里/dev/dsk/c5t0d0其实跟用c5t0d0是一样的,由此可以看出,在创建ZFS的时候,磁盘完全可以用物理设备名就可以,不需要指出全路径。
⒋检测正在使用的设备
在格式化设备之前,ZFS首先决定磁盘是否已经在用或者是否装有操作系统,如果磁盘在用了,那么将会出现下边的错误提示:
|
1
2
3
4
5
6
7
|
#zpoolcreatetankc1t0d0c1t1d0invalidvdevspecificationuse’-f’tooverridethefollowingerrors:/dev/dsk/c1t0d0s0iscurrentlymountedondev/dsk/c1t0d0s1iscurrentlymountedonswap/dev/dsk/c1t1d0s0ispartofactiveZFSpool’zeepool’Pleaseseezpool(1M) |
有些错误可以用 -f 选项来强制覆盖,但是大多错误是不能的。下边给出不能用-f覆盖的错误情况,这时只能手工纠正错误:
|
1
2
3
4
|
MountedfilesystemThediskoroneofitsslicescontainsafilesystemthatiscurrentlymounted.Tocorrectthiserror,usetheumountcommand.Filesystemin/etc/vfstabThediskcontainsafilesystemthatislistedinthe/etc/vfstabfile,butthefilesystemisnotcurrentlymounted.Tocorrectthiserror,removeorcommentoutthelineinthe/etc/vfstabfile.DedicateddumpdeviceThediskisinuseasthededicateddumpdeviceforthesystem.Tocorrectthiserror,usethedumpadmcommand.PartofaZFSpoolThediskorfileispartofanactiveZFSstoragepool.Tocorrectthiserror,usethezpoolcommandtodestroythepool. |
⒌创建存储池时默认的mount点
在创建存储池时,如果mount点所在目录不存在,系统会自动创建,如果存在,根数据集(root dataset)会自动mount到这个目录上。
To create a pool with a different default mount point,use the -m option of the zpool create command:
# zpool create home c1t0d0
default mountpoint ’/home’ exists and is not empty
use ’-m’ option to specifya different default
# zpool create -m /export/zfs home c1t0d0
This command creates a new pool home and the home dataset with a mount point of /export/zfs.
⒍删除存储池
Pools are destroyed by using the zpool destroy command. This command destroys the pool even if it contains mounted datasets.
# zpool destroy tank
⒈增加设备到存储池
用户可以通过增加一个新的顶级虚拟设备的方法动态给存储池增加空间,这个空间立即对空间中的所有数据集(dataset)有效。要增加一个虚拟设备到池中,用“zpool add”命令,例如:
# zpool add zeepool mirror c2t1d0 c2t2d0
该命令也可以用 -n选项进行预览,例如:
|
1
2
3
4
5
6
7
8
9
10
11
12
|
#zpooladd-nzeepoolmirrorc3t1d0c3t2d0wouldupdate’zeepool’tothefollowingconfiguration:zeepoolmirrorc1t0d0c1t1d0mirrorc2t1d0c2t2d0mirrorc3t1d0c3t2d0 |
⒉增加和减少一路镜像
用“zpool attach”命令增加一路镜像,例如:
# zpool attach zeepool c1t1d0 c2t1d0
在这个例子中,假设 zeepool 是第一点里的那个zeepool(已经是两路镜像),那么这个命令将把zeepool升级成三路镜像。
用“zpool detach”命令来分离一路镜像
# zpool detach zeepool c2t1d0
如果池中不存在镜像,这个才操作将被拒绝。错误提示如下边这个例子:
# zpool detach newpool c1t2d0 cannot detach c1t2d0: onlyapplicable to mirror and replacing vdevs
⒊管理设备的“上线”和“下线”
ZFS允许个别的设备处于offline或者online状态。当硬件不可靠或者还没有完全不能用的时候,ZFS会继续向设备读写数据,但不过是临时这么做,因为设备还能将就使用。一旦设备不能使用,就要指示ZFS忽略该设备,并让这个坏掉的设备下线。ZFS不会向offline的设备发送任何请求。
注意:如 果只是为了更换设备(被换设备并没有出问题),不 需要把他们offline。如果offline设备,然 后换了一个新设备上去,再 把新设备online,这 么做会出错!
用“zpool offline”命令让设备下线。例如:
# zpool offline tank c1t0d0
bringing device c1t0d0 offline
下边这句话没怎么看懂:
You cannot take a pool offline to the point where it becomes faulted. For example,you cannot take offline two devices out of a RAID-Z configuration,nor can you take offline a top-level virtual device.
# zpool offline tank c1t0d0
cannot offline c1t0d0: no valid replicas
默认情况下,offline设备将永久保持offline状态,直到系统重新启动。
要临时offline一个设备,用-t选项,例如:
# zpool offline -t tank c1t0d0
bringing device ’c1t0d0’ offline
用“zpool onine”命令使设备上线
# zpool online tank c1t0d0
bringing device c1t0d0 online
注意:如果只是为了更换设备(被换设备并没有出问题),不需要把他们offline。如果offline设备,然后换了一个新设备上去,再把新设备online,这么做会出错!在这个问题上文档是这么说的:(但愿我没理解错)
Note that you cannot use device onlining to replace a disk. If you offline a
device,replace the drive,and try to bring it online,it remains in the faulted state.
⒋清扫存储池设备
如果设备因为出现错误,被offline了,可以用“zpool clear”命令清扫错误。
如果没有特别指定,zpool clear命令清扫池里所有设备。例如:
# zpool clear tank
如果要清扫指定设备,例如:
# zpool clear tank c1t0d0
⒌替换存储池里的设备
用“zpool replace”命令替换池中设备,例如:
# zpool replace tank c1t1d0 c1t2d0
c1t1d0 被 c1t2d0 替换
注意:如果是mirror或者RAID-Z,替换设备的容量必须大于或等于所有设备最小容量!
⒈ZFS存储池的基本信息
用“zpool list”命令查看存储池的基本信息,例如:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
#zpoollistNAMESIZEUSEDAVAILCAPHEALTHALTROOTtank80.0G22.3G47.7G28%ONLINE-dozer1.2T384G816G32%ONLINE-NAME:Thenameofthepool.SIZE:Thetotalsizeofthepool,equaltothesumofthesizeofalltop-levelvirtualdevices.USED:Theamountofspaceallocatedbyalldatasetsandinternalmetadata.Notethatthisamountisdifferentfromtheamountofspaceasreportedatthefilesystemlevel.AVAILABLE:Theamountofunallocatedspaceinthepool.CAPACITY(CAP):Theamountofspaceused,expressedasapercentageoftotalspace.HEALTH:Thecurrenthealthstatusofthepool.ALTROOT:Thealternaterootofthepool,ifany. |
可以通过指定名字来查看某一个池的状态,例如:
|
1
2
3
|
#zpoollisttankNAMESIZEUSEDAVAILCAPHEALTHALTROOTtank80.0G22.3G47.7G28%ONLINE- |
如果要有选择看状态列表,可以用-o选项
|
1
2
3
4
5
|
#zpoollist-oname,sizeNAMESIZEtank80.0Gdozer1.2TScriptingZFSStoragePoolOutput |
The default output for the zpool list command is designed for readability,and is not easy to use as art of a shell script. To aid programmatic uses of the command,the -H option can be used to uppress the column headings and separate fields by tabs,rather than by spaces. For example,to request a simple list of all pool names on the system:
|
1
2
3
4
5
6
7
|
#zpoollist-HonametankdozerHereisanotherexample:#zpoollist-H-oname,sizetank80.0Gdozer1.2T |
⒉查看存储池的I/O状态
用“zpool iostat”命令查看存储池的I/O状态,例如:
|
1
2
3
4
5
6
|
#zpooliostatcapacityoperationsbandwidthpoolusedavailreadwritereadwrite----------------------------------------tank100G20.0G1.2M102K1.2M3.45Kdozer12.3G67.7G132K15.2K32.1K1.20K |
⒊ZFS存储池的健康状态
用“zpool status”查看健康状态
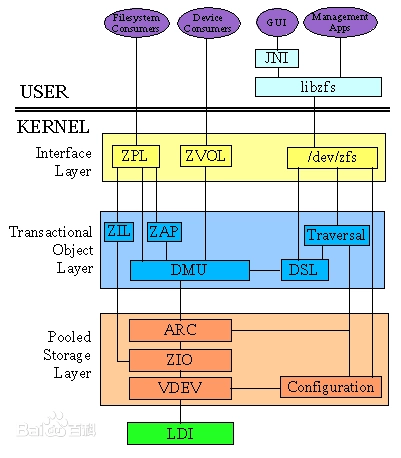
ZFS是把存储设备建立成为一个存储池,在这个池中,还可以建立更小的池。每个同等级池之间的关系可以使各种raid关系;而子父级之间的关系,就和 存储设备和存储池之间 一样。可以在下图中清楚看到这种管理方式是如何存在的。
命令 zpool = zfs
一般过程是先查看有哪些设备连接了,FreeBSD或solaris中的linux命令
1 $ fdisk -l
是无效的,要列出连接的硬盘,我选择
1 $ format
命令,记录下所有设备编号,如VMware下就是c5t0d0,c5t1d0,c5t2d0,….
查看zfs状态的命令
1 $ zpool status
可以看到系统内所有存储池状态和硬盘健康度,可以在status后面加 -x 参数看所有存储池是否健康
类似的可以查看存储池总容量(包括冗余)情况的命令
1 $ zpool list
用来搭配使用的
1 $ df -h poolname
检查容量实际使用情况
zfs建立一个存储池的命令是
1 $ zpool create poolname raidz1 c5t0d0 c5t1d0 c5t2d0
将会把c5t1~3d0 3个硬盘建立一个名字为poolname的raidz1模式(raid5)的存储池。
删除销毁一个存储池命令是
1 $ zpool destroy poolname
将zfs的存储池挂载和卸载的命令,如同mount/unmount的是
1 $ zpool import/export poolname
这个一般是在恢复日志历史镜像等应用时使用。也可以恢复被destroy的存储池,使用
1 $ zpool import -D poolname
要看存储池的实时读写状态命令
1 $ zpool iostat 1
重中之重的replace命令,
1 $ zpool replace poolname c5t0d0 c6t0d0
就是将接入但没使用的c6t0d0替换了正在使用的c5t0d0,这时使用zpool status应该会看到这两个盘正在replacing,或者rebuild,这在替换报错error/fault的硬盘,或者使用更大的容量替换老硬盘的时候都有用。
当一个raid内所有硬盘都替换为新的更大容量的硬盘后,可以使用
1 $ zpool set autoexpand=on poolname
开启存储池自动扩展的属性(默认为禁止),或
1 $ zpool online -e poolname c6t0d0
对一个已经存在的设备使用online命令来达到扩容的目的,再次zpool list查看容量应该可以看到真个raid容量已经扩大了。
其中online命令对应的是offline,zfs中常这样使用
1 $ zpool offline poolname c6t0d0
当然zfs支持raid中的热备份,可以在create的时候添加spare设备,例如
1 $ zpool create raidz1 poolname c5t0d0 c5t1d0 c5t2d0 spare c6t0d0
c6t0d0就成为了热备份设备,要删除这个热备份设备(或日志,高速缓存),就要使用命令
1 $ zpool remove c6t0d0
而对应的zpool add命令却使用很有限,因为这个add只能在现有容量上扩充,也就是加入现有的存储池形成raid0,这很有风险,比如poolname中有c5t1~3d0 3个硬盘形成的raidz1 容量为20G的存储池,使用
1 $ zpool add -f poolname mirror c6t0d0 c6t1d0
这条命令的意义就是 先将c6t0d0 c6t1d0两盘镜像即raid1,例容量15G,再加入poolname中和已有的c5t1~3d0 raidz1的20G容量再raid0,衔接后面,之后存储池poolname中的总容量就等于20G+15G =35G。如果一个盘坏了,c5t0d0坏了,就会对前面一个raidz1形成影响,变成degraded降级状态,后面一个镜像的c6t0d0 c6t1d0则没有影响。如果后面的两个不是镜像,而是raid0模式,如果一个坏了offline,直接就导致这个raid0失败不可访问,间接的导致整个存储池不可访问,哪怕这个存储池中有一部分的容量自身有备份。
所以add命令必须搭配 -f 参数,意思是强制添加容量到存储池后面,加上zfs只能增加容量不能缩小的特性,为了保险起见,所有add加入的容量必须自身足够安全(比如自身就是raid),否则一旦损坏会出现上面这样的导致所有存储不可访问的问题。这个风险你应该在使用add命令的时候就非常清楚。zfs中不推荐使用raid0模式,除了万不得已。
最好的最安全的扩容就是在raidz1或者raidz2(raid5/raid6)基础上,用大容量设备replace旧的小容量设备,等重建替换完成后,挨个把存储池内所有存储设备升级替换,所有完成后使用前面的扩容命令自动扩容。
zfs文件系统除了方便扩容,方便管理,安全简单以外,当然性能也同样不能太低。而一些朋友常常争论,究竟raid 0+1还是raidz1/raidz2更快,我觉得是没有意义的,因为常常最终管理的存储的容量和速度是成反比的,只要安全,访问速度快慢就交给缓存来解决。zfs在更新数个版本后,缓存管理已经非常优秀了,基本上在只有内存做缓存的系统上,除去基本的4G RAM系统最低要求,每增加10G常用数据,就要增加1G RAM来保证命中和速度,比如后面是100G的常用数据,那么就需要100/10+4G=14G内存来保证较高的读取速度。内存价格偏高,且不容易扩展的时候,就出现了使用SSD固态硬盘来做缓存的技术,形成了CPU->RAM->SSD cache->HDD ZFS的三层结构。在FreeNAS中这点做得很好,设置很方便,有文章指出,4G系统内存下,网络访问速度约为400Mbit/sec read + 300Mbit/sec write,而8G内存+64G SSD的缓存结构下,可以达到900Mbit/sec read + 600Mbit/sec write,跑满千兆网络,同时iSCSI性能飞升,生产环境中也应该这样搭建使用。命令也很简单,只需要在create的时候增加cache SSD0,也可以单独使用命令
1 $ zpool add poolname cache SSD0 SSD1
来增加一个或多个缓存,此缓存设备可以通过前面提到的remove命令轻松删除。
到这里已经差不多了,对于存储池内数据的完整性,通过命令
1 $ zpool scrub poolname
达到校验的目的,这一般会花费很长的时间,可以通过zpool status查看校验进度,最好在硬件出现问题,解决后都校验一次以保证一切正常。
观察近两年的发展,FreeBSD的活跃度已经渐渐赶上Linux的开发速度了,相互之间的借鉴也越来越多,而在此之上的solaris也被广泛使用,作为数据服务器的首选。
1)ZPOOL,一个动态可扩展的存储池
其对外提供一个虚拟的设备,可以动态的添加磁盘,移除坏盘,做mirror, raid0, raidz 等。 基于这个动态调节的ZFS Pool之上的新的逻辑硬盘可以被文件系统使用,并且会自动的选择最优化的参数。
这个有点像SAN ,SAN 对外提供的也是一个虚拟磁盘,该磁盘时可以跨网络的, ZFS是本地文件系统,只能实现本地磁盘。
2)Copy-on-write 技术。 这个技术并不复杂,也不难理解。但是这个技术是有严重的performance的问题的。
有人说有了这个后,就不需要fsck, scandisk了,这个说法是不对的。 事实上,有了日志文件系(journal filesystem) 后,就不需要fsck这个ugly的东西了。
Copy-on-Write 技术是可以认为是另一个journal 的实现,和日志不同的是,它不是re-do 日志,而是直接修改文件的block的指针。它对于文件本身的数据的完整性是没有问题的,当写一个新的block 时,没有performance的影响,当些一个旧的block时,需要先copy一份,性能可想要大跌。对于元数据,性能损失就更加明显了。
总之,通过这个技术,和Transaction技术一起,确实可以对数据的一致性得到比较好的保护,但是性能的损失如何去弥补,这是一个问题。
3)智能预读取(Intelligent Prefetch)
prefetch 技术是顺序读的一个性能优化的很好的技术。 ZFS实现了更智能的预定模式。
目 前预取技术就是对顺序读比较有效。对于其它类型的访问模式,一是模式检测比较难,其次即使检测出来,由于性能的 bottleneck 可能在别的地方,性能优化并不理想。 ZFS的预取技术,增加了Strip模式的预取,这在ZFS模式下是有效的,其它的模式并没有看到。其次目 前都是针对单流预取,针对多流很少。
4)Dynamic Striping
所谓的动态striping,就是可以再不同设备上分配 block,不同设备上当然是并发的写入, 可以认为是一种strip操作。 和 static striping 不同,是需要事前设置。 这个是ZFS的动态存储池本身的架构带来的优势。
5)增加了数据的Checksum校验
这个技术是小技巧,没啥可评价的,看下面的介绍。
由于ZFS所有的数据操作都是基于Transaction(事务),一组相应的操作会被ZFS解析为一个事务操作,事务的操作就代表着一组操作要么一起失败,要么一起成功。而且如前所说,ZFS对 所有的操作是基于COW(Copy on Write), 从而保证设备上的数据始终都是有效的,再也不会因为系统崩溃或者意外掉电导致数据文件的inconsistent。
还有一种潜在威胁数据的可能是来自于硬件设备的问题,比如磁盘,RAID卡的硬件问题或者驱动bug。现有文件系统通常遇到这个问题,往往只是简单的把错误数据直接交给上层应用,通常我们把这个问题称作 Silent Data Corruption。而在ZFS中,对所有数据不管是用户数据还是文件系统自身的metadata数据都进行256位的Checksum(校验),当ZFS在提交数据时会进行校验,彻底杜绝这种Silent Data Corruption情况。
值得注意的是,ZFS通过COW技术和Chumsum技术有效的保护了数据的完整性。
6)Extent的概念:支持多种 大小的数据块(Multiple Block Size)
目前最新的思想,都是丢弃block的概念,引入Extent的概念,Extent就是连续的多个block,注意Extent的block是变长的。多种Block Size 对大文件和 小文件都可以有很好的优化。这个只是剩如何实现了。
7)自我修复功能 ZFS Mirror 和 RAID-Z
传统的硬盘Mirror及RAID 4,RAID 5阵列方式都会遇到前面提到过的问题:Silent Data Corruption。如果发生了某块硬盘物理问题导致数据错误,现有的Mirror,包括RAID 4,RAID 5阵列会默默地把这个错误数据提交给上层应用。如果这个错误发生在Metadata中,则会直接导致系统的Panic。而且还有一种更为严重的情况是:在 RAID 4和RAID 5阵列中,如果系统正在计算Parity数值,并再次写入新数据和新Parity值的时候发生断电,那么整个阵列的所有存储的数据都毫无意义了。
在ZFS中则提出了相对应的ZFS Mirror和RAID-Z方式,它在负责读取数据的时候会自动和256位校验码进行校验,会主动发现这种Silent Data Corruption,然后通过相应的Mirror硬盘或者通过RAID-Z阵列中其他硬盘得到正确的数据返回给上层应用,并且同时自动修复原硬盘的 Data Corruption 。
8)提供许多企业级别的超强功能:Quota(配额), Reservation(预留), Compression(压 缩), Snapshot(快照),Clone(克隆)。并且速度非常快。
对于本地文件系统系统,支持Quota,Reservation,Compression 并不难,对于用COW技术,Snapshot,Clone几乎是COW的附带的产品,实现都很容易。
9)ZFS的容量无限制。
他是如何做到的呢?一个就是ZPOOL, 这使得容量可以动态扩展,其次,元数据也是动态分配的,也就是inode也是动态分配的。 对于本地文件系统,我们说的扩展性,这的是容量线性扩展, performance的线性扩展,包括IOPS 和 Bandwidth , 对于ZFS,声称可以实现线性扩展。
-
Sun Solaris
-
Illumos发行版
-
Mac OS X Server 10.5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号