贝壳IM群聊优化之路
贝壳IM群聊优化之路 https://mp.weixin.qq.com/s/ybzq5etos8Y7HE_p3Z95Sg
贝壳IM群聊优化之路
介绍
贝壳IM为贝壳找房提供了70%以上的线上商机。为上百万的经纪人提供了快捷的线上获客渠道。日新增会话300万+。其既有互联网TO C产品的属性,又具有浓厚的房地产行业特色,是贝壳找房所属的产业互联网中重要的一环。
IM系统相比其他服务有其特殊的特点,主要包括实时性、有序性、可靠性(不重复不丢失)、一致性(多端漫游同步)、安全性。为保证这些特性的实现,良好的性能是必不可少的。本文主要阐述了针对贝壳IM单聊群聊消息的优化思路,通过压测、寻找瓶颈点、提出优化方案、验证优化方案、代码实现的多轮次迭代,最终实现了20倍以上的性能提升。
背景
2020年底的时候有业务方提出使用群聊消息进行推广活动,该场景预估300人大群需要满足100QPS的性能要求。接到需求,我们首先对群聊场景进行了摸底压测,效果为300人大群QPS为15的时候系统内消息处理就会出现积压,投递能力到达瓶颈。因此拉开了优化的序幕。
IM系统整体概览
我们首先简要介绍下贝壳IM的整体架构,一是便于理解IM消息服务难在哪,二是便于看出IM消息服务的瓶颈点在哪。
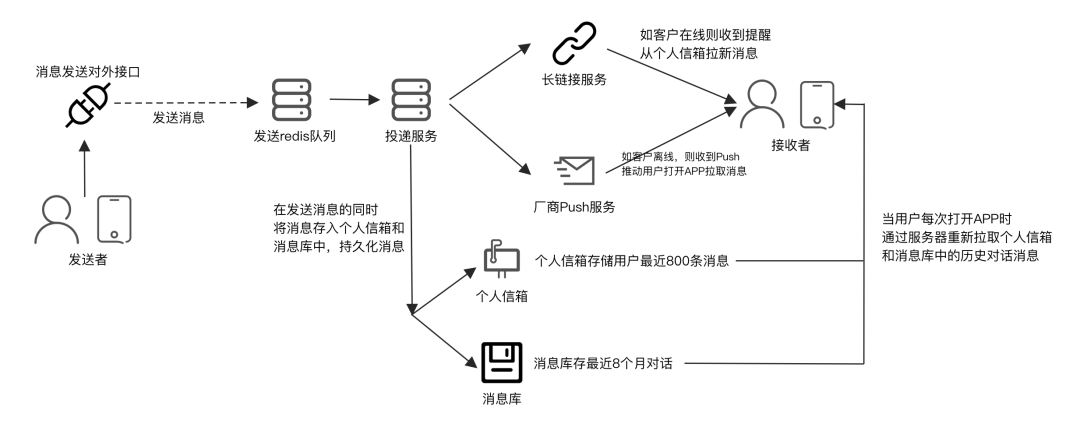
上图是IM消息发送的整体流程:
发送者通过http接口发送消息,接口处理完成写入发送队列后返回给用户成功信息。此时后台的投递服务实时从队列获取待投递消息,然后进行如下四步操作:
-
写入用户的收件箱
-
个人信箱通过Redis的zset实现,只保存用户最近800条消息,历史消息需要通过消息库查询。注意此处是一个写扩散的过程,每个用户都有一个自己的收件箱,300人的大群,任意一人发送消息,在此处都会写入群中300人的收件箱,相当于1次写入扩散为300次,因此300人大群,如果要达到300QPS,那么写扩散后在Redis层就是一个300*300=90000的QPS,记住这个数字,下文会继续提到
-
写入持久化的历史消息库
-
通过长连接服务通知接收者拉取消息
-
通过PUSH服务通知接收者有消息到达
-
用户在线可以通过长连接通知,如果用户离线,则只能通过PUSH通知
通过贝壳IM架构,可以看到消息发送到消息送达整体是一个异步服务,分为两个部分,一是接口层,二是投递服务,两者之间通过队列通信。接口层只需要写入队列即返回成功,无状态可以横向扩展,不会成为群聊的瓶颈。投递服务功能复杂并且会直接影响消息处理的及时性、可靠性。
了解过IM的同学可能会问,是否可以将写扩散模式更改为读扩散,即300人大群中发送一条消息之后,不再写入每个人的收件箱,而是只记录到一个发件箱中,读取的时候每个人去发件箱中读取。读扩散方式下,假设一个人加入了100个群,那么读取时需要将100个群的发件箱都读取一遍,而之前的写扩散模式,只需要在收件箱中按序列号读取一次即可。两者各有优劣势,通过调研发现云厂商以及微信服务群聊均是在写扩散模式下实现,证明写扩散可行,并且对贝壳IM来说,继续使用写扩散成本可控。因此在整体架构不变的情形下我们进行了一系列优化,最终也达到了预期效果。
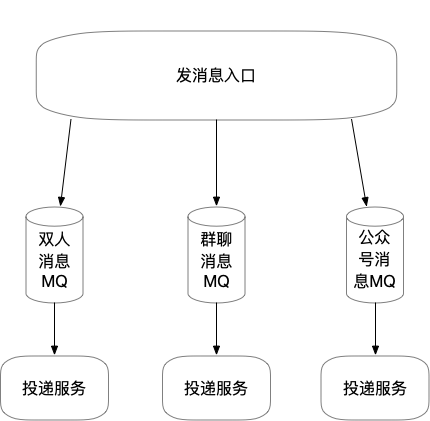
优化措施一: 业务隔离
IM的消息按照业务属性主要分为三种:
-
单聊消息,即双人聊天会话,包括C2B和B2B,涉及商机获取,最核心的功能
-
群聊消息,即多人聊天会话, 特点是参与人数多,涉及活动推广及消息通知
-
公众号消息,即各种业务公众号群发消息,推送量大,已经做了隔离,并且历史消息库使用TiDB
消息投递服务负责从redis队列消费用户发送的消息,进行处理。举个例子, A/B/C三人在同一会话中, A向会话中发送一条消息, 投递服务需要保证这条消息被写入A/B/C三人各自的收件箱和历史消息库, 并通过(push/长连接)通知A/B/C。第一次摸底压测出现redis队列积压,会导致用户不能及时收到消息,这个是不可接受的。在业务侧,针对我们公司的业务场景特点,最重要的是客户和经纪人的单聊消息。从业务隔离角度考量,进行的第一个优化措施,是对单聊和群聊进行垂直拆分,分级隔离后的效果图如下:
优化措施二: 提高并发
我们继续深入投递服务的细节,看看投递服务的代码实现逻辑。总体来看,投递服务消费一条消息后,会经历两个阶段,每个阶段分别由对应的goroutine来完成, 阶段一有256个goroutine, 阶段二 有1000个goroutine,两个处理流程之间通过channel进行通信。两阶段的流程图如下:
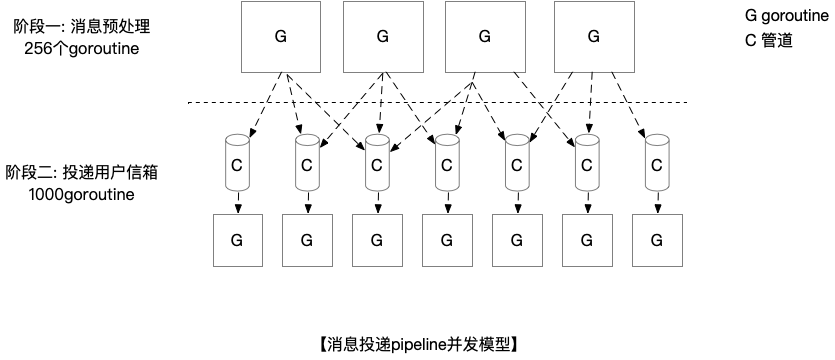
还是以一个300人的群GroupA为例,假设发送者 SenderA发送了一个消息,阶段一获取到的消息是会话维度,即GroupA(会话ID标识)的SenderA(UCID标识)发送了一条内容为xxx的消息,阶段一的主要工作是根据会话ID获取到群内的所有成员UCID,然后将UCID哈希之后打散放到1000个channel中,此时channel中的消息是用户维度,即用户ReceiveB收到了一条内容为xxx的消息。注意阶段一此时还进行了一个扩散操作,即将每个收件人的未读数计数进行了更新操作。阶段二从channel中获取消息之后将其放入群内300个成员各自的收件箱,然后给每个人发送push以及长连接信息,通知收件人拉取消息。
可以看到阶段一是会话消息维度的处理,IO操作较少,写扩散主要有两步,一是进行一个内存channel的写入,二是以收件人维度进行了未读数的更新。阶段二是收件人维度的消息处理,并发度更大(1000个goroutine),IO操作也较多,例如写入收件人收件箱,更新会话顺序,向每个收件人都发送push通知和长连接通知。
优化措施
压测时观察到只有发送Redis队列有积压,channel队列没有积压,并且阶段二并发能力更强,考虑将阶段一中比较耗时的更新用户未读数操作放在在阶段二进行。
效果
通过将更新用户未读数放到阶段二,其实相当于增大了处理未读数的并发能力,上线后进行压测,数据为300人群,群聊消息发送可以达到75QPS,有5倍的性能提升。当300人大群发送QPS达到70时,Redis侧QPS为21000,此时IM中使用的一组缓存redis cpu被打满,单核使用率达到92%(注意redis6.0版本之前只能使用单核,因此单核cpu使用率是redis一个很重要的观察维度)。
优化措施三: 减少计算
进行第二项优化后,300人的群聊可以达到75QPS,此时一组缓存的redis实例cpu基本被打满。该组redis主要负责存储用户关系, 在投递服务阶段二发送push的业务逻辑中会大量使用。
问题
以投递一条消息到300人的大群为例,假设群为GroupA,发送者 SenderA发送了一个消息,阶段二中给每个收件人发送push的业务逻辑中存在重复获取数据的情况,例如:
-
SenderA的用户信息:会针对群内每个成员获取一次,即获取了300次SenderA的用户信息。
-
GroupA的会话信息:会针对群内每个成员获取一次,即获取了300次会话信息。
-
用户是否设置了免打扰:会针对群内每个成员获取一次,即获取了300次免打扰设置。
由于群聊是从单聊代码改造而来,可以看到简单重复单聊的逻辑,会造成写扩散的放大。
优化措施
针对重复获取数据,进行相应的优化措施,SenderA的用户信息和GroupA的会话信息可以提前获取一次,发送push时直接使用。用户是否设置了免打扰,原来是从用户到群组的映射关系,通过增加一个群组到用户的反向映射关系,可以通过一个群组直接获取到全部设置了免打扰的用户,减少计算量。
效果
通过合并业务数据,相当于减少了业务处理的计算量,该改进上线后进行压测,300人群, 发消息150QPS,对比优化二有了2倍的性能提升,对比初始值有10倍的性能提升。此时写入信箱QPS可以达到45k。
此时,IM使用的另一组Redis出现了告警,单核CPU使用率超出90%,并且有大量redis慢查和超时报警。通过监控发现,CPU被打满时,redis每秒建连数达到8k/s, 总连接数增长至20k,QPS为45k,通过和DBA同学沟通,这种情况下redis有一大部分cpu都被消耗在连接的建立与销毁。奇怪的是IM中使用了Redis连接池,为什么还会有大量的新建连接呢?Redis的极限QPS能够达到多少?
优化措施四: Redis连接池优化
排查过程
贝壳IM中redis库是使用连接池,目的就是为了避免新建销毁连接带来的消耗。目前使用的redis库比较老,结合之前线上存在偶发的redis慢查报错,首先怀疑是连接池的实现问题。
验证
为了方便在测试环境模拟复现redis大量建连问题,开发了一个模拟投递程序可以指定发消息qps和参与会话人数。
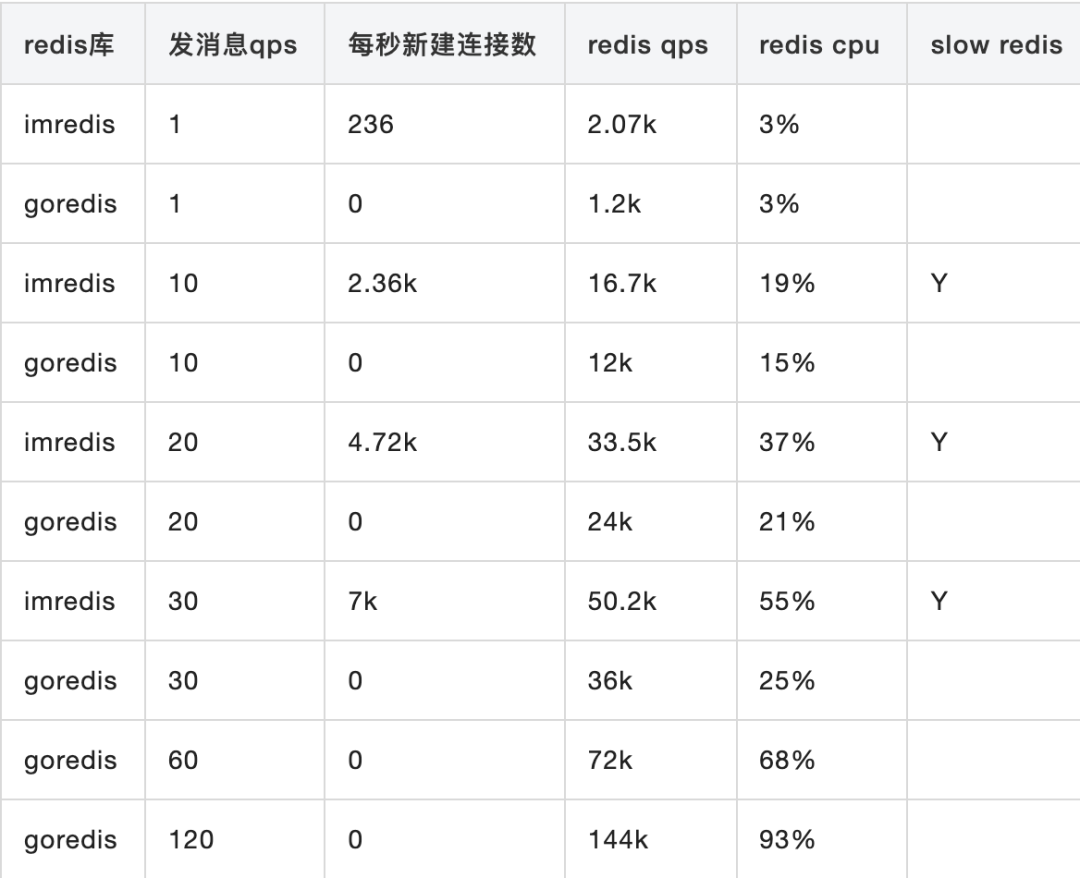
如下是im使用的redis库(简写为imredis)与业界比较成熟的goredis库数据对比
通过测试数据发现如下三点:
-
在发送端qps相同的情况下,如果没有大量的新建连接,则redis CPU使用率会大幅下降
-
发送端qps到达120时,使用goredis,此时CPU使用率93%,接近打满,redis qps 144k。(注意此处的模拟程序只使用了一个redis实例。IM线上服务首先按功能分组,每组Redis一般是4个实例起步。分组和分实例的逻辑都在imredis代码中实现)
-
通过模拟测试,可以证明imredis库连接池实现确实有问题,并且验证出redis在我们的场景下极限QPS可以达到140k。因此通过改造连接池,可以达到优化效果。
连接池缺陷
// Get retrieves an available redis client. If there are none available it will
// create a new one on the fly
func (p *Pool) Get() (*redis.Client, error) {
select {
case conn := <-p.pool:
return conn, nil
default:
return p.df(p.Network, p.Addr, p.Auth, p.Db, p.Timeout)
}
}
通过查看imredis连接池代码,发现虽然初始化时会指定最大连接数量,但当QPS升高并且接池中获取不到连接时,会新建连接进行处理。
优化措施
参考goredis和其他连接池实现, 采取以下优化措施:
备用连接池。大小是默认连接池的10倍,如果默认连接池满了, 连接会暂时存放在备用连接池,每过固定时间对备用连接池内的连接进行释放。避免在大量并发时频繁新建和关闭连接。
对新建连接通过令牌桶进行限制,避免短时间内无限制大量建立连接,导致拖垮服务。
最终效果
压测验证300人大群可以达到320qps左右。投递能力较优化三有两倍的性能提升,较去年年底有20倍的性能提升
总结
群聊300人大群达到320qps,已经能够满足未来两年内的业务需求。并且随着群聊的优化,尤其是Redis连接池的优化,单聊的性能也有了显著提升,从年初的2000达到了12000。未来如果有继续提高性能的需求,只需要对redis进行双倍扩容,并且将投递服务也进行扩容即可。
通过本次优化,可以看到,大部分的性能优化只需要进行代码层面的改造,通过压测找到瓶颈点,摸清整个链路的短板并改造这个短板。此时QPS就只是一个数值。需要更高的QPS时只需要扩容、扩容、再扩容即可。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号