Golang 并发编程指南
Golang 并发编程指南 - 知乎 https://zhuanlan.zhihu.com/p/450822514
Golang 并发编程指南
作者:dcguo
分享 Golang 并发基础库,扩展以及三方库的一些常见问题、使用介绍和技巧,以及对一些并发库的选择和优化探讨。
go 原生/扩展库
提倡的原则
不要通过共享内存进行通信;相反,通过通信来共享内存。
Goroutine
goroutine 并发模型
调度器主要结构
主要调度器结构是 M,P,G
- M,内核级别线程,goroutine 基于 M 之上,代表执行者,底层线程,物理线程
- P,处理器,用来执行 goroutine,因此维护了一个 goroutine 队列,里面存储了所有要执行的 goroutine,将等待执行的 G 与 M 对接,它的数目也代表了真正的并发度( 即有多少个 goroutine 可以同时进行 );
- G,goroutine 实现的核心结构,相当于轻量级线程,里面包含了 goroutine 需要的栈,程序计数器,以及所在 M 的信息
P 的数量由环境变量中的 GOMAXPROCS 决定,通常来说和核心数对应。
映射关系
用户空间线程和内核空间线程映射关系有如下三种:
- N:1
- 1:1
- M:N
调度图
关系如图,灰色的 G 则是暂时还未运行的,处于就绪态,等待被调度,这个队列被 P 维护
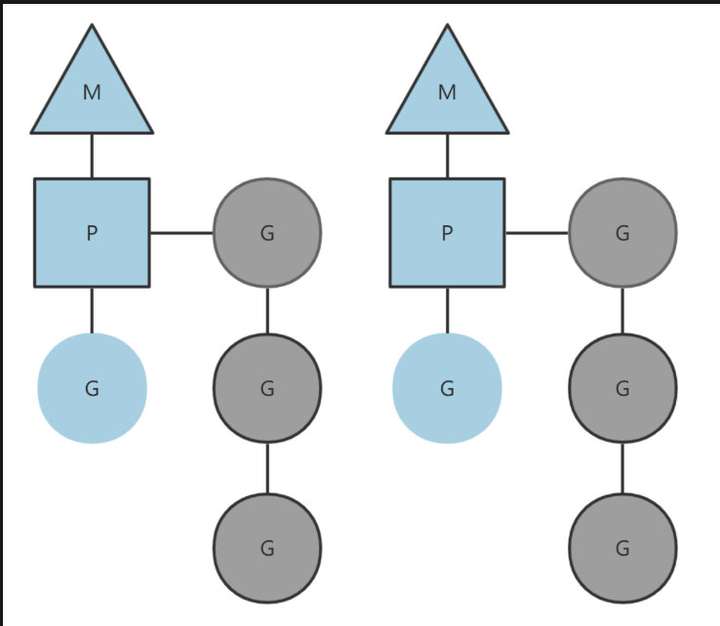
注: 简单调度图如上,有关于 P 再多个 M 中切换,公共 goroutine 队列,M 从线程缓存中创建等步骤没有体现,复杂过程可以参考文章简单了解 goroutine 如何实现。
goroutine 使用
- demo1
go list.Sort() - demo2
funcAnnounce(message string, delay time.Duration) {
gofunc() {
time.Sleep(delay)
fmt.println(message)
}()
}
channel
channel 特性
创建
// 创建 channel
a := make(chan int)
b := make(chan int, 10)
// 单向 channel
c := make(chan<- int)
d := make(<-chan int)
存入/读取/关闭

tip:
v, ok := <-a // 检查是否成功关闭(ok = false:已关闭)
channel 使用/基础
use channel
ci := make(chan int)
cj := make(chan int, 0)
cs := make(chan *os.File, 100)
c := make(chan int)
go func() {
list.Sort()
c <- 1
}()
doSomethingForValue
<- c
func Server(queue chan *Request) {
for req := range queue {
sem <- 1
go func() {
process(req)
<- sem
}()
}
}
func Server(queue chan *Requet) {
for req := range queue {
sem <- 1
go func(req *Request) {
process(req)
<- sem
}(req)
}
}
func Serve(queue chan *Request) {
for req := range queue {
req := req
sem <- 1
go func() {
process(req)
<-sem
}()
}
}channel 使用/技巧
等待一个事件,也可以通过 close 一个 channel 就足够了。。
c := make(chan bool)
go func() {
// close 的 channel 会读到一个零值
close(c)
}()
<-c
阻塞程序
开源项目【是一个支持集群的 im 及实时推送服务】里面的基准测试的案例
取最快结果
func main() {
ret := make(chan string, 3)
for i := 0; i < cap(ret); i++ {
go call(ret)
}
fmt.Println(<-ret)
}
func call(ret chan<- string) {
// do something
// ...
ret <- "result"
}
协同多个 goroutines
注: 协同多个 goroutines 方案很多,这里只展示 channel 的一种。
limits := make(chan struct{}, 2)
for i := 0; i < 10; i++ {
go func() {
// 缓冲区满了就会阻塞在这
limits <- struct{}{}
do()
<-limits
}()
}
搭配 select 操作
for {
select {
case a := <- testChanA:
// todo a
case b, ok := testChanB:
// todo b, 通过 ok 判断 tesChanB 的关闭情况
default:
// 默认分支
}
}
main go routinue 确认 worker goroutinue 真正退出的方式
func worker(testChan chan bool) {
for {
select {
// todo some
// case ...
case <- testChan:
testChan <- true
return
}
}
}
func main() {
testChan := make(chan bool)
go worker(testChan)
testChan <- true
<- testChan
}
关闭的 channel 不会被阻塞
testChan := make(chan bool)
close(testChan)
zeroValue := <- testChan
fmt.Println(zeroValue) // false
testChan <- true // panic: send on closed channel
注: 如果是 buffered channel, 即使被 close, 也可以读到之前存入的值,读取完毕后开始读零值,写入则会触发 panic
nil channel 读取和存入都不会阻塞,close 会 panic
略
range 遍历 channel
for range
c := make(chan int, 20)
go func() {
for i := 0; i < 10; i++ {
c <- i
}
close(c)
}()
// 当 c 被关闭后,取完里面的元素就会跳出循环
for x := range c {
fmt.Println(x)
}
例: 唯一 id
func newUniqueIdService() <-chan string {
id := make(chan string)
go func() {
var counter int64 = 0
for {
id <- fmt.Sprintf("%x", counter)
counter += 1
}
}()
return id
}
func newUniqueIdServerMain() {
id := newUniqueIdService()
for i := 0; i < 10; i++ {
fmt.Println(<- id)
}
}
带缓冲队列构造
略
超时 timeout 和心跳 heart beat
- 超时控制
funcmain() {
done := do()
select {
case <-done:
// logic
case <-time.After(3 * time.Second):
// timeout
}
}
demo
开源 im/goim 项目中的应用

心跳
done := make(chan bool)
defer func() {
close(done)
}()
ticker := time.NewTicker(10 * time.Second)
go func() {
for {
select {
case <-done:
ticker.Stop()
return
case <-ticker.C:
message.Touch()
}
}
}()
}
多个 goroutine 同步响应
func main() {
c := make(chan struct{})
for i := 0; i < 5; i++ {
go do(c)
}
close(c)
}
func do(c <-chan struct{}) {
// 会阻塞直到收到 close
<-c
fmt.Println("hello")
}
利用 channel 阻塞的特性和带缓冲的 channel 来实现控制并发数量
func channel() {
count := 10 // 最大并发
sum := 100 // 总数
c := make(chan struct{}, count)
sc := make(chan struct{}, sum)
defer close(c)
defer close(sc)
for i:=0; i<sum; i++ {
c <- struct{}
go func(j int) {
fmt.Println(j)
<- c // 执行完毕,释放资源
sc <- struct {}{} // 记录到执行总数
}
}
for i:=sum; i>0; i++ {
<- sc
}
}
go 并发编程(基础库)
这块东西为什么放到 channel 之后,因为这里包含了一些低级库,实际业务代码中除了 context 之外用到都较少(比如一些锁 mutex,或者一些原子库 atomic),实际并发编程代码中可以用 channel 就用 channel,这也是 go 一直比较推崇得做法 Share memory by communicating; don’t communicate by sharing memory
Mutex/RWMutex
锁,使用简单,保护临界区数据
使用的时候注意锁粒度,每次加锁后都要记得解锁
Mutex demo
package main
import (
"fmt"
"sync"
"time"
)
func main() {
var mutex sync.Mutex
wait := sync.WaitGroup{}
now := time.Now()
for i := 1; i <= 3; i++ {
wait.Add(1)
go func(i int) {
mutex.Lock()
time.Sleep(time.Second)
mutex.Unlock()
defer wait.Done()
}(i)
}
wait.Wait()
duration := time.Since(now)
fmt.Print(duration)
}
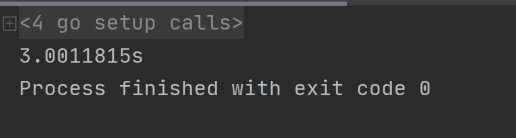
结果: 可以看到整个执行持续了 3 s 多,内部多个协程已经被 “锁” 住了。
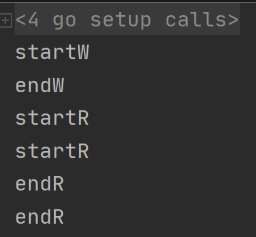
RWMutex demo
注意: 这东西可以并发读,不可以并发读写/并发写写,不过现在即便场景是读多写少也很少用到这,一般集群环境都得分布式锁了。
package main
import (
"fmt"
"sync"
"time"
)
var m *sync.RWMutex
func init() {
m = new(sync.RWMutex)
}
func main() {
go read()
go read()
go write()
time.Sleep(time.Second * 3)
}
func read() {
m.RLock()
fmt.Println("startR")
time.Sleep(time.Second)
fmt.Println("endR")
m.RUnlock()
}
func write() {
m.Lock()
fmt.Println("startW")
time.Sleep(time.Second)
fmt.Println("endW")
m.Unlock()
}
输出:
Atomic
- 可以对简单类型进行原子操作
- int32
- int64
- uint32
- uint64
- uintptr
- unsafe.Pointer
- 可以进行得原子操作如下
- 增/减
- 比较并且交换
假定被操作的值未曾被改变, 并一旦确定这个假设的真实性就立即进行值替换 - 载入
为了原子的读取某个值(防止写操作未完成就发生了一个读操作) - 存储
原子的值存储函数 - 交换
原子交换
demo:增
package main
import (
"fmt"
"sync"
"sync/atomic"
)
func main() {
var sum uint64
var wg sync.WaitGroup
for i := 0; i < 100; i++ {
wg.Add(1)
go func() {
for c := 0; c < 100; c++ {
atomic.AddUint64(&sum, 1)
}
defer wg.Done()
}()
}
wg.Wait()
fmt.Println(sum)
}
结果:

WaitGroup/ErrGroup
waitGroup 是一个 waitGroup 对象可以等待一组 goroutinue 结束,但是他对错误传递,goroutinue 出错时不再等待其他 goroutinue(减少资源浪费) 都不能很好的解决,那么 errGroup 可以解决这部分问题。
注意
- errGroup 中如果多个 goroutinue 错误,只会获取第一个出错的 goroutinue 的错误信息,后面的则不会被感知到;
- errGroup 里面没有做 panic 处理,代码要保持健壮
demo: errGroup
package main
import (
"golang.org/x/sync/errgroup"
"log"
"net/http"
)
func main() {
var g errgroup.Group
var urls = []string{
"https://km.woa.com//",
"errUrl",
}
for _, url := range urls {
url := url
g.Go(func() error {
resp, err := http.Get(url)
if err == nil {
_ = resp.Body.Close()
}
return err
})
}
err := g.Wait()
if err != nil {
log.Fatal("getErr", err)
return
}
}
结果:

once
保证了传入的函数只会执行一次,这常用在单例模式,配置文件加载,初始化这些场景下。
demo:
times := 10
var (
o sync.Once
wg sync.WaitGroup
)
wg.Add(times)
for i := 0; i < times; i++ {
go func(i int) {
defer wg.Done()
o.Do(func() {
fmt.Println(i)
})
}(i)
}
wg.Wait()
结果:
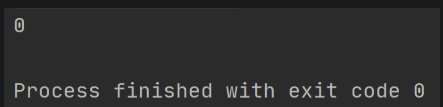
Context
go 开发已经对他了解了太多
可以再多个 goroutinue 设置截止日期,同步信号,传递相关请求值
对他的说明文章太多了,详细可以跳转看这篇 一文理解 golang context
这边列一个遇到得问题:
- grpc 多服务调用,级联 cancel
A -> B -> C
A 调用 B,B 调用 C,当 A 不依赖 B 请求 C 得结果时,B 请求 C 之后直接返回 A,那么 A,B 间 context 被 cancel,而 C 得 context 也是继承于前面,C 请求直接挂掉,只需要重新搞个 context 向下传就好,记得带上 reqId, logId 等必要信息。
并行
- 某些计算可以再 CPU 之间并行化,如果计算可以被划分为不同的可独立执行的部分,那么他就是可并行化的,任务可以通过一个 channel 发送结束信号。
假如我们可以再数组上进行一个比较耗时的操作,操作的值在每个数据上独立,如下:
type vector []float64
func (v vector) DoSome(i, n int, u Vector, c chanint) {
for ; i < n; i ++ {
v[i] += u.Op(v[i])
}
c <- 1
}
我们可以再每个 CPU 上进行循环无关的迭代计算,我们仅需要创建完所有的 goroutine 后,从 channel 中读取结束信号进行计数即可。
并发编程/工作流方案扩展
这部分如需自己开发,内容其实可以分为两部分能力去做
- 并发编程增强方案
- 工作流解决方案
需要去解决一些基础问题
- 并发编程:
- 启动 goroutine 时,增加防止程序 panic 能力
- 去封装一些更简单的错误处理方案,比如支持多个错误返回
- 限定任务的 goroutine 数量
- 工作流:
- 在每个工作流执行到下一步前先去判断上一步的结果
- 工作流内嵌入一些拦截器
singlelFlight(go 官方扩展同步包)
一般系统重要的查询增加了缓存后,如果遇到缓存击穿,那么可以通过任务计划,加索等方式去解决这个问题,singleflight 这个库也可以很不错的应对这种问题。
它可以获取第一次请求得结果去返回给相同得请求 核心方法Do执行和返回给定函数的值,确保某一个时间只有一个方法被执行。如果一个重复的请求进入,则重复的请求会等待前一个执行完毕并获取相同的数据,返回值 shared 标识返回值 v 是否是传递给重复的调用请求。
一句话形容他的功能,它可以用来归并请求,但是最好加上超时重试等机制,防止第一个执行得请求出现超时等异常情况导致同时间大量请求不可用。
场景: 数据变化量小(key 变化不频繁,重复率高),但是请求量大的场景
demo
package main
import (
"golang.org/x/sync/singleflight"
"log"
"math/rand"
"sync"
"time"
)
var (
g singleflight.Group
)
const (
funcKey = "key"
times = 5
randomNum = 100
)
func init() {
rand.Seed(time.Now().UnixNano())
}
func main() {
var wg sync.WaitGroup
wg.Add(times)
for i := 0; i < times; i++ {
go func() {
defer wg.Done()
num, err := run(funcKey)
if err != nil {
log.Fatal(err)
return
}
log.Println(num)
}()
}
wg.Wait()
}
func run(key string) (num int, err error) {
v, err, isShare := g.Do(key, func() (interface{}, error) {
time.Sleep(time.Second * 5)
num = rand.Intn(randomNum) //[0,100)
return num, nil
})
if err != nil {
log.Fatal(err)
return 0, err
}
data := v.(int)
log.Println(isShare)
return data, nil
}
连续执行 3 次,返回结果如下,全部取了共享得结果:

但是注释掉 time.Sleep(time.Second * 5) 再尝试一次看看。
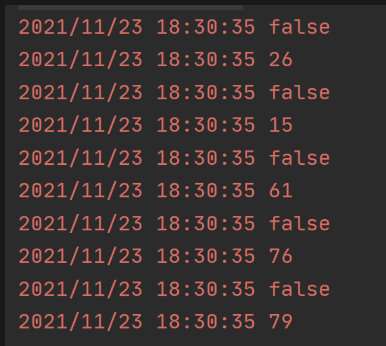
这次全部取得真实值
实践: 伙伴部门高峰期可以减少 20% 的 Redis 调用, 大大减少了 Redis 的负载
实践
开发案例
注: 下面用到的方案因为开发时间较早,并不一定是以上多种方案中最优的,选择有很多种,使用那种方案只有有所考虑可以自圆其说即可。
建议: 项目中逐渐形成统一解决方案,从混乱到统一,逐渐小团队内对此类逻辑形成统一的一个解决标准,而不是大家对需求之外的控制代码写出各式各样的控制逻辑。
批量校验
- 场景
批量校验接口限频单账户最高 100qps/s,整个系统多个校验场景公用一个账户
限频需要限制批量校验最高为 50~80 qps/s(需要预留令牌供其他场景使用,否则频繁调用批量接口时候其他场景均会失败限频)。 - 设计
- 使用 go routine 来并发进行三要素校验,因为 go routinue,所以每次开启 50 ~ 80 go routine 同时进行单次三要素校验;
- 每轮校验耗时 1s,如果所有 routinue 校验后与校验开始时间间隔不满一秒,则需要主动程序睡眠至 1s,然后开始下轮校验;
- 因为只是校验场景,如果某次校验失败,最容易的原因其实是校验方异常,或者被其他校验场景再当前 1s 内消耗过多令牌;
那么整个批量接口返回 err,运营同学重新发起就好。
- 代码
代码需要进行的优化点:
- sleep 1s 这个操作可以从调用前开始计时,调用完成后不满 1s 补充至 1s,而不是每次最长调用时间 elapsedTime + 1s;
- 通道中获取的三要素校验结果顺序和入参数据数组顺序不对应,这里通过两种方案:
- 加锁(推荐使用,最多不到 100 的竞争者数目,使用锁性能影响微乎其微);
- 给每个传入 routine 的 element 数组包装,增加一个 key 属性,每个返回的 result 包含 key 通过 key 映射可以得到需要的一个顺序。
- 分组调用 getElementResponseConcurrent 方法时,传入切片可以省略部分计算,直接使用切片表达式。

elementNum := len(elements)
m := elementNum / 80
n := elementNum % 80
if m < 1 {
if results, err := getElementResponseConcurrent(ctx, elements, conn, caller); err != nil {
return nil, err
} else {
response.Results = results
return response, nil
}
} else {
results := make([]int64, 0)
if n != 0 {
m = m + 1
}
var result []int64
for i := 1; i <= m; i++ {
if i == m {
result, err = getElementResponseConcurrent(ctx, elements[(i-1)*80:(i-1)*80+n], conn, caller)
} else {
result, err = getElementResponseConcurrent(ctx, elements[(i-1)*80:i*80], conn, caller)
}
if err != nil {
return nil, err
}
results = append(results, result...)
}
response.Results = results
}
// getElementResponseConcurrent
func getElementResponseConcurrent(ctx context.Context, elements []*api.ThreeElements, conn *grpc.ClientConn,
caller *api.Caller) ([]int64, error) {
results := make([]int64, 0)
var chResult = make(chan int64)
chanErr := make(chan error)
defer close(chanErr)
wg := sync.WaitGroup{}
faceIdClient := api.NewFaceIdClient(conn)
for _, element := range elements {
wg.Add(1)
go func(element *api.ThreeElements) {
param := element.Param
verificationRequest := &api.CheckMobileVerificationRequest{
Caller: caller,
Param: param,
}
if verification, err := faceIdClient.CheckMobileVerification(ctx, verificationRequest); err != nil {
chanErr <- err
return
} else {
result := verification.Result
chanErr <- nil
chResult <- result
}
defer wg.Done()
}(element)
}
for i := 0; i < len(elements); i++ {
if err := <-chanErr; err != nil {
return nil, err
}
var result = <-chResult
results = append(results, result)
}
wg.Wait()
time.Sleep(time.Second)
return results, nil
}
// getElementResponseConcurrent
func getElementResponseConcurrent(ctx context.Context, elements []*api.ThreeElements, conn *grpc.ClientConn,
caller *api.Caller) ([]int64, error) {
results := make([]int64, 0)
//创建一个通道
var chResult = make(chan int64)
chanErr := make(chan error)
defer close(chanErr)
wg := sync.WaitGroup{}
faceIdClient := api.NewFaceIdClient(conn)
for _, element := range elements {
wg.Add(1)
go func(element *api.ThreeElements) {
name := element.Name
mobile := element.Mobile
idCardType := element.IdCardType
idCardNumber := element.IdCardNumber
verificationRequest := &api.CheckMobileVerificationRequest{
Caller: caller,
Mobile: mobile,
Name: name,
IdCardType: idCardType,
IdCardNumber: idCardNumber,
}
if verification, err := faceIdClient.CheckMobileVerification(ctx, verificationRequest); err != nil {
log.Err("CheckMobileVerification fail").Error(err).
Any("name", name).Any("idCardType", idCardType).Any("idCardNumber", idCardNumber).
Ctx(ctx).Str("mobile", mobile).Error(err).Line()
//return nil, transform.Simple("三要素检测失败", errcode.ErrApi)
//把错误写入通道
chanErr <- err
log.Inf("getElementResponseConcurrent in go routine").Error(err).Ctx(ctx).Line()
return
} else {
result := verification.Result
chanErr <- nil // TODO err
chResult <- result
log.Inf("getElementResponseConcurrent in go routine").Any("chResult", result).Ctx(ctx).Line()
}
defer wg.Done()
}(element)
}
for i := 0; i < len(elements); i++ {
log.Inf("getElementResponseConcurrent channel begin").Any("elements", elements).Ctx(ctx).Line()
// 阻塞式获取,要获取相同次数,否则程序阻塞
if err := <-chanErr; err != nil {
return nil, err
}
var result = <-chResult
results = append(results, result)
log.Inf("getElementResponseConcurrent channel over").Any("elements", elements).Ctx(ctx).Line()
}
wg.Wait()
time.Sleep(time.Second)
return results, nil
}
历史数据批量标签
场景: 产品上线一年,逐步开始做数据分析和统计需求提供给运营使用,接入 Tdw 之前是直接采用接口读历史表进行的数据分析,涉及全量用户的分析给用户记录打标签,数据效率较低,所以采用并发分组方法,考虑协程比较轻量,从开始上线时间节点截止当前时间分共 100 组,代码较为简单。
问题: 本次接口不是上线最终版,核心分析方法仅测试环境少量数据就会有 N 多条慢查询,所以这块还需要去对整体资源业务背景问题去考虑,防止线上数据量较大还有慢查询出现 cpu 打满。
func (s ServiceOnceJob) CompensatingHistoricalLabel(ctx context.Context,
request *api.CompensatingHistoricalLabelRequest) (response *api.CompensatingHistoricalLabelResponse, err error) {
if request.Key != interfaceKey {
return nil, transform.Simple("err")
}
ctx, cancelFunc := context.WithCancel(ctx)
var (
wg = new(sync.WaitGroup)
userRegisterDb = new(datareportdb.DataReportUserRegisteredRecords)
startNum = int64(0)
)
wg.Add(1)
countHistory, err := userRegisterDb.GetUserRegisteredCountForHistory(ctx, historyStartTime, historyEndTime)
if err != nil {
return nil, err
}
div := decimal.NewFromFloat(float64(countHistory)).Div(decimal.NewFromFloat(float64(theNumberOfConcurrent)))
f, _ := div.Float64()
num := int64(math.Ceil(f))
for i := 0; i < theNumberOfConcurrent; i++ {
go func(startNum int64) {
defer wg.Done()
for {
select {
case <- ctx.Done():
return
default:
userDataArr, err := userRegisterDb.GetUserRegisteredDataHistory(ctx, startNum, num)
if err != nil {
cancelFunc()
}
for _, userData := range userDataArr {
if err := analyseUserAction(userData); err != nil {
cancelFunc()
}
}
}
}
}(startNum)
startNum = startNum + num
}
wg.Wait()
return response, nil
}func (s ServiceOnceJob) CompensatingHistoricalLabel(ctx context.Context,
request *api.CompensatingHistoricalLabelRequest) (response *api.CompensatingHistoricalLabelResponse, err error) {
if request.Key != interfaceKey {
return nil, transform.Simple("err")
}
ctx, cancelFunc := context.WithCancel(ctx)
var (
wg = new(sync.WaitGroup)
userRegisterDb = new(datareportdb.DataReportUserRegisteredRecords)
startNum = int64(0)
)
wg.Add(1)
countHistory, err := userRegisterDb.GetUserRegisteredCountForHistory(ctx, historyStartTime, historyEndTime)
if err != nil {
return nil, err
}
div := decimal.NewFromFloat(float64(countHistory)).Div(decimal.NewFromFloat(float64(theNumberOfConcurrent)))
f, _ := div.Float64()
num := int64(math.Ceil(f))
for i := 0; i < theNumberOfConcurrent; i++ {
go func(startNum int64) {
defer wg.Done()
for {
select {
case <- ctx.Done():
return
default:
userDataArr, err := userRegisterDb.GetUserRegisteredDataHistory(ctx, startNum, num)
if err != nil {
cancelFunc()
}
for _, userData := range userDataArr {
if err := analyseUserAction(userData); err != nil {
cancelFunc()
}
}
}
}
}(startNum)
startNum = startNum + num
}
wg.Wait()
return response, nil
}
批量发起/批量签署
实现思路和上面其实差不多,都是需要支持批量的特性,基本上现在业务中统一使用多协程处理。
思考
golang 协程很牛 x,协程的数目最大到底多大合适,有什么衡量指标么?
- 衡量指标,协程数目衡量
基本上可以这样理解这件事 - 不要一个请求 spawn 出太多请求,指数级增长。这一点,在第二点会受到加强;
- 当你生成 goroutines,需要明确他们何时退出以及是否退出,良好管理每个 goroutines
尽量保持并发代码足够简单,这样 grroutines 得生命周期就很明显了,如果没做到,那么要记录下异常 goroutine 退出的时间和原因; - 数目的话应该需要多少搞多少,扩增服务而不是限制,限制一般或多或少都会不合理,不仅 delay 更会造成拥堵
- 注意 协程泄露 问题,关注服务的指标。
使用锁时候正确释放锁的方式
- 任何情况使用锁一定要切记锁的释放,任何情况!任何情况!任何情况!
即便是 panic 时也要记得锁的释放,否则可以有下面的情况 - 代码库提供给他人使用,出现 panic 时候被外部 recover,这时候就会导致锁没释放。
goroutine 泄露预防与排查
一个 goroutine 启动后没有正常退出,而是直到整个服务结束才退出,这种情况下,goroutine 无法释放,内存会飙高,严重可能会导致服务不可用
- goroutine 的退出其实只有以下几种方式可以做到
- main 函数退出
- context 通知退出
- goroutine panic 退出
- goroutine 正常执行完毕退出
- 大多数引起 goroutine 泄露的原因基本上都是如下情况
- channel 阻塞,导致协程永远没有机会退出
- 异常的程序逻辑(比如循环没有退出条件)
杜绝:
- 想要杜绝这种出现泄露的情况,需要清楚的了解 channel 再 goroutine 中的使用,循环是否有正确的跳出逻辑
排查:
- go pprof 工具
- runtime.NumGoroutine() 判断实时协程数
- 第三方库
**案例: **
package main
import (
"fmt"
"net/http"
_ "net/http/pprof"
"runtime"
"time"
)
func toLeak() {
c := make(chan int)
go func() {
<-c
}()
}
func main() {
go toLeak()
go func() {
_ = http.ListenAndServe("0.0.0.0:8080", nil)
}()
c := time.Tick(time.Second)
for range c {
fmt.Printf("goroutine [nums]: %d\n", runtime.NumGoroutine())
}
}
输出:
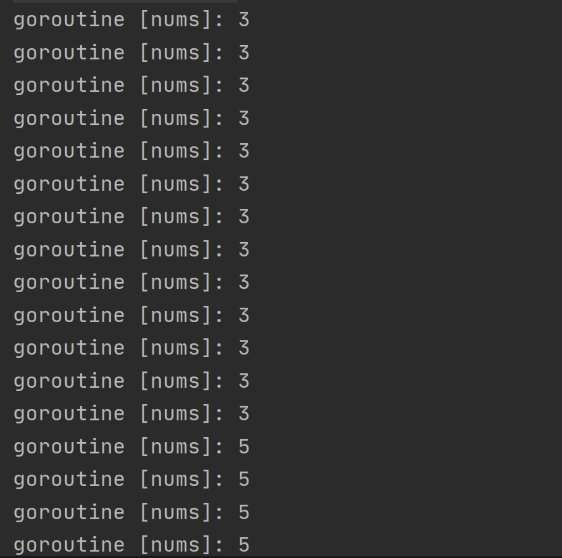
pprof:

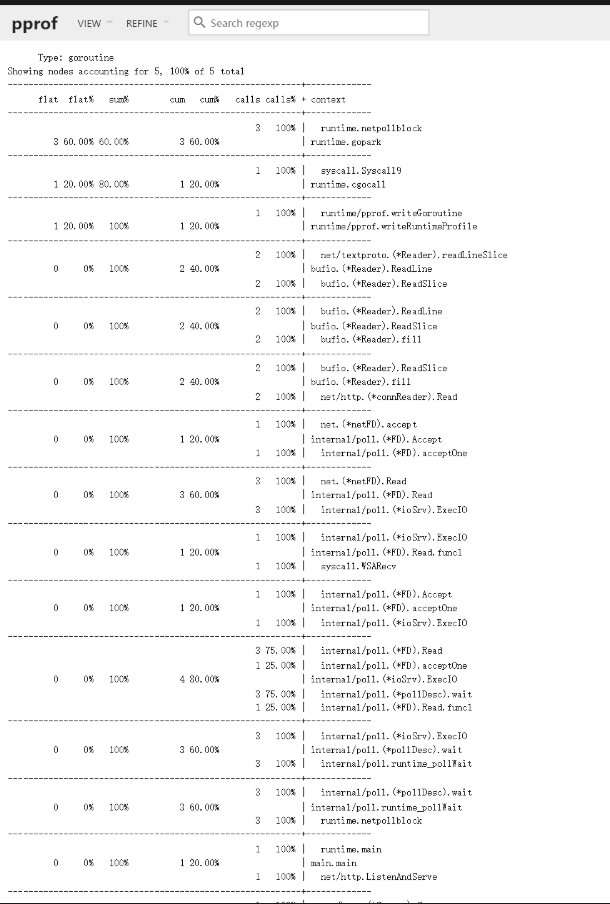
复杂情况也可以用其他的可视化工具:
- go tool pprof -http=:8001 http://127.0.0.1:8080/debug/pprof/goroutine?debug=1
父协程捕获子协程 panic
使用方便,支持链式调用
有锁的地方就去用 channel 优化
有锁的地方就去用 channel 优化,这句话可能有点绝对,肯定不是所有场景都可以做到,但是大多数场景绝 X 是可以的,干掉锁去使用 channel 优化代码进行解耦绝对是一个有趣的事情。分享一个很不错的优化 demo:
场景:
- 一个简单的即时聊天室,支持连接成功的用户收发消息,使用 socket;
- 客户端发送消息到服务端,服务端可以发送消息到每一个客户端。
分析:
- 需要一个链接池保存每一个客户端;
- 客户端发送消息到服务端,服务端遍历链接池发送给各个客户端
- 用户断开链接,需要移除链接池的对应链接,否则会发送发错;
- 遍历发送消息,需要再 goroutine 中发送,不应该被阻塞。
问题:
- 上述有个针对链接池的并发操作
解决
- 引入锁
增加锁机制,解决针对链接池的并发问题
发送消息也需要去加锁因为要防止出现 panic: concurrent write to websocket connection - 导致的问题
假设网络延时,用户新增时候还有消息再发送中,新加入的用户就无法获得锁了,后面其他的相关操作都会被阻塞导致问题。
使用 channel 优化:
- 引入 channel
新增客户端集合,包含三个通道 - 链接新增通道 registerChan,链接移除通道 unregisterChan,发送消息通道 messageChan。
- 使用通道
- 新增链接,链接丢入 registerChan;
- 移除链接,链接丢入 unregisterChan;
- 消息发送,消息丢入 messageChan;
3. 通道消息方法,代码来自于开源项目 简单聊天架构演变:
// 处理所有管道任务
func (room *Room) ProcessTask() {
log := zap.S()
log.Info("启动处理任务")
for {
select {
case c := <-room.register:
log.Info("当前有客户端进行注册")
room.clientsPool[c] = true
case c := <-room.unregister:
log.Info("当前有客户端离开")
if room.clientsPool[c] {
close(c.send)
delete(room.clientsPool, c)
}
case m := <-room.send:
for c := range room.clientsPool {
select {
case c.send <- m:
default:
break
}
}
}
}
}
结果:
成功使用 channel 替换了锁。
参考

 浙公网安备 33010602011771号
浙公网安备 33010602011771号