百度文库 文档阅读器
百度文库新一代文档阅读器!核心技术点全解析! https://mp.weixin.qq.com/s/sr1hKlkSlN0528_RfdUkrg
百度文库新一代文档阅读器!核心技术点全解析!
技术视野:
1、
图形绘制可以直接借助于开源方案,比如fabric,轻松实现各种图形的绘制
2、
vite + ts,vite 能够带给我们极致的开发体验,ts 能够让我们写的代码更有保障,业务方调用API时更便捷
小结:
1)
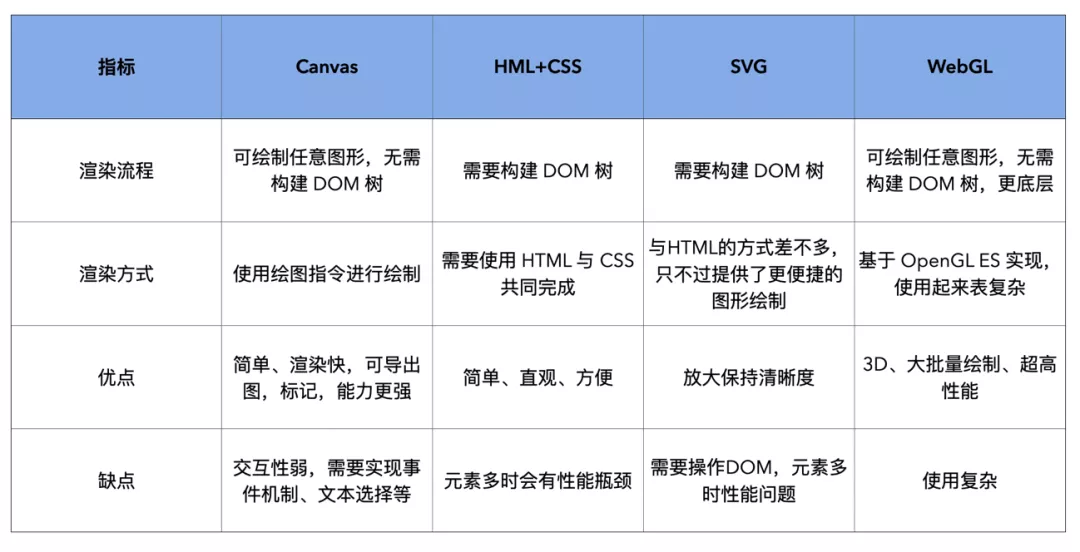
渲染机制对比:
Canvas HTML+CSS SVG WebGL
2)
一但某页不可见时,立马释放内存空间,这一措施让整个阅读器的内存占用降低90%
导读:文库有数十亿文档,包括 word、ppt、excel、txt 和 pdf 等十几种常见办公文档,核心技术是转码和展现,转码的目的是把不同文档进行解析转换成一套通用的数据格式,由后端实现,而展现是把文档数据进行渲染。在这之前,文库前端采用的HTML+CSS进行渲染,这种方式在后面的业务发展过程中遇到了阻力,比如很难实现文档导出长图、文档标记、关键字高亮、水印、文档内容分析、防复制等。
全文2803字,预计阅读时间14分钟
一、架构
在今年5月份时候,我们开始使用 Canvas 实现新一代阅读器,它能够同时支持PC、wap 和小程序,相比与老的阅读器它具备以下优势:
| 旧阅读器 | 新一代阅读器CReader | |
| 导出长图 | 无法导出,需借助服务端能力 | 可直接导出 |
| 文档标记 | 实现成本较高 | 支持 |
| 复制功能 | 文本选择体验差,不好屏蔽 | 文本选择体验好,可屏蔽复制 |
| 性能 | HTML元素多,大文档性能差 | 少量HTML元素,只渲染可见区域内容,性能更好 |
| 开发体验 | 不能本地开发、无文档、无单测、TS类型支持弱,集成复杂,可配置性低 | 采用vite+TS,高效的开发体验,丰富的文档,集成简单,不依赖业务方技术栈 |
| 扩展性 | 添加功能比较复杂 | 层级分工明确,可方便扩展功能 |
在技术选型的时候,我们选择了 vite + ts,vite 能够带给我们极致的开发体验,ts 能够让我们写的代码更有保障,业务方调用API时更便捷。整体架构分为:逻辑层:负责管理数据的加载、页面创建、页面渲染调度、事件分发、对外提供核心API;数据层:负责加载文档数据,包含文档内容、自定义字体、图片;解析层:负责把文档数据进行解析,产出要渲染的数据,比如文本内容、字体大小、文本位置、图片内容、图片位置等;渲染层:负责把解析后的内容进行渲染,目前只支持Canvas渲染,可根据业务需求进行扩展其它渲染方式,比如 HTML、SVG;应用层:使用 CReader 进行文档渲染的业务方,内部提供了一个在线阅读器,辅助开发。
二、核心技术点
2.1 文本图片渲染机制
文档主要由文本和图片构成,整个文档渲染主要围绕这两个进行。Canvas是浏览器提供的一种能力,可以通过绘制指令进行绘制,最终把要展示的内容呈现给用户。由于它不需要通过DOM元素渲染,这就享受不到DOM本身的可交互性,比如文本选择、DOM事件,不过对于文档来说,属于静态的,对可交互性要求没有那么高。下面对比一下前端中的各种渲染机制:
综合各种业务场景,我们最终选择使用Canvas,不过整个阅读器设计考虑了支持多种渲染方式。Canvas在渲染的过程中需要有一些注意点,比如在Safari浏览器中,画布的大小在移动端和PC端不能超过它的限制,通过源码(webkit源码)中可以看到:
而且,绘制过程中不能占用太多的内存空间,否则调用 getContext('2d') 时会返回 NULL,我们当时渲染 1000页文档时,内存开销很大。最终采用了一种策略,只对可见区域的页面进行绘制,一但某页不可见时,立马释放内存空间,这一措施让整个阅读器的内存占用降低90%。你可能会担心Canvas渲染会有性能问题,其实在整个测试过程中,Canvas 渲染可以通过一些手段优化,绘制性能并不会成为瓶颈。
Canvas在绘制自定义字体的时候需要确保字体被加载过,否则使用的字体将无效。而且Canvas绘制并不支持字符间距,在数据解析后需要计算每个字符最终在画布的位置,由于用户会调整文档尺寸,最终的字符位置需要考虑缩放比例。Canvas在绘制图片时需要确保图片被加载完才能进行绘制,如果想要对Canvas导出图片,那么要确保图片没有跨域问题。最终的绘制效果如下(图中的线条是我们的调试工具,可以查看每个字符具体绘制的位置):2.2 文本选择
在老的阅读器中,由于DOM节点比较复杂,文本选择的体验非常不好,会来回跳动,如果跨页选择时,由于页间会有广告,导致把广告内容也复制了。使用Canva渲染时,它并没有提供文本选择方案,需要自己实现整个文本的选择。整个思路其实就是根据鼠标经过的坐标位置,找到对应的文本,这就需要把光标的坐标与文本的坐标对应起来。在整个阅读器设计的过程中,有一个数据层会记录各个节点的坐标信息。但是,在文本选择的过程中,需要考虑多种情况,比如光标首次落在非文字区域、文本选择时发生了跨页、整行文本内容字体大小不一、行间距不一等。为了不影响文档原本内容,在文档顶部按需创建了一个 Canvas 进行文本选择高亮状态绘制。整体效果如下:
跨页文本选择
三、业务功能
3.1 防作弊
旧版阅读器中文本复制功能是浏览器自带的,所有的文本节点通过浏览器的调试工具看到具体的内容,也可以通过代码的方式获取文本内容。而采用Canvas渲染,所有的内容节点将被绘制到一张图上,从而有效避免获取文档中的内容。
3.2 文档转图
由于旧版阅读器采用HTML的方式渲染,DOM节点比较复杂,样式比较多,采用类似html2canvas这种库根本不好使。我们实现文档导出长图采用的是无头浏览器的方式,这种方式需要消耗服务端资源,而且耗时比较长,平均5-6秒。新一代阅读器采用Canvas 渲染,Canvas天然支持导出图片,从而能够把文档中的任意页导出图,把不同页面拼接成长图。
3.3 文档标记
新版阅读器采用Canvas渲染,做文档标记也就是顺理成章的事情,使得实现成本极低。图形绘制可以直接借助于开源方案,比如fabric,轻松实现各种图形的绘制,而且能够把绘制的内容导出为 json 文件,这让多人标记共享成为了可能。文档标记效果:
四、小程序排版
文库文档排版方式有两种,一种称为流式,适合移动端阅读,但是丢失了文档原有格式;另一种称为版式,主要用于 wap 和 PC,与原文档结构一致。目前小程序以流式为主,版式为辅,版式直接通过 webview 加载的H5页面,但小程序的webview中不能添加小程序的原生组件,这导致用户看版式文档时不能看文档周边的其它信息,比如文档推荐、VIP引导、工具栏等内容,下载文档时也只能从 webview 中跳回小程序原生页面。以前尝试过以iframe的方式渲染文档,但体验不是很好,由于种种原因这种方式就废弃掉了。新一代阅读器不仅可以支持PC、wap,而且能够扩充到小程序上,我们最近做过一次尝试,成功地把版式文档渲染出来了,而且体验很好。这就能够让版式文档和流式文档一样可以嵌入到小程序原生页面当中。效果如下:
五、最后
总得来说,文库新一代文档阅读器能够带给用户更好的体验,满足更多复杂的业务场景。在开发体验上,使用了最新构建工具 vite,带来极致的开发体验;接入更轻松简单,无论使用任意技术栈都能够轻松接入,如果均使用默认配置,5行代码即可接入,在以前是无法做到的;全面的单测覆盖,为质量保驾护航。同一套代码可同时满足wap、pc和小程序,覆盖文库90%的文档类型,随着不断迭代,会覆盖文库所有的文档类型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号