
InnoDB事务锁系统及其实现
小结:
原创|InnoDB事务锁系统及其实现 https://mp.weixin.qq.com/s/W07ZIW0GRtsrS5nuiy2z_A
原创|InnoDB事务锁系统及其实现
原创|InnoDB事务锁系统及其实现
提示:公众号展示代码会自动折行,建议横屏阅读
「第一部分 前言」
InnoDB引擎支持行级别锁,实现了四种隔离级别,本文梳理了InnoDB事务系统及锁系统的原理和源码实现,并且对其中一些比较特别的feature做一个简单的介绍。
因为涉及的模块代码非常庞大,部分实现细节并未深入,如有错漏,欢迎指正。
在介绍InnoDB的事务系统和锁系统之前,有必要对一些基本概念做一个简单的回顾。
我们都知道事务的四大属性ACID,这些属性的保证与数据库中的几大模块紧密的耦合在一起:
-
为了保证原子性Atomicity,数据库需要保证事务要么都成功,要么都不成功,因此需要记事务的undo日志,undo日志保证做了一半的事务可以被全部撤销掉。
-
为了保证持久性Durability,数据库需要保证提交的事务修改的数据能够在各种异常情况下(数据库实例crash,机器故障)都不能丢失,因此需要记事务的redo日志,redo日志保证在事务提交前,事务的修改日志就已经成功落盘。
-
为了保证隔离性Isolation,就需要并发控制了,并发控制机制管理事务的并行执行,使得它们看起来仿佛是单独执行的一样。
以上三点的终极目标是保证数据库事务的一致性Consistency,保证数据从一个一致的状态到另一个一致的状态。
注:这里的一致性与分布式数据库的一致性是不一样的。分布式数据库的一致性是定义了读操作与写操作之间的关系,有强一致性和弱一致性之分。强一致性,或者称为线性一致性,Linearizability,也就是CAP中的C,它要求,每一个读操作都将返回『最近的写操作』(基于单一的实际时间)的值。弱一致性则放宽了这种限制。
分布式数据库的一致性与本文接下来的内容没有关系,只是为了明确它和事务的一致性是不一样的,特在此说明。
「第二部分 隔离级别」
不同隔离级别下,事务有不一样的行为和可容忍的异常,不定义隔离级别就无法去讨论事务系统如何去做事务的并发控制的,因此它是数据库如何保证事务Isolation的前提。
ANSI/ISO SQL-92定义了四种隔离级别(Read Uncommitted, Read Committed, Repeatable Read和Serializable),也是MySQL/InnoDB中实现的四种隔离级别。
InnoDB实现这四种隔离级别的方式可以概括为:
-
Read Uncommited
-
可以读取未提交记录,存在脏读的异常。此隔离级别一般不会使用。
-
Read Committed (RC)
-
针对快照读,不加锁读数据的一个已提交的版本。
-
针对当前读,RC隔离级别对读取到的记录只加记录锁,因此存在幻读异常。
-
Repeatable Read (RR)
-
针对快照读,不加锁。
-
针对当前读,RR隔离级别不仅对读取到的记录加记录锁,同时对读取的范围加锁(间隙锁),新的在该范围内的记录不能够插入和删除,因此不存在幻读异常。
-
RR是MySQL InnoDB默认的隔离级别。
-
Serializable
-
所有的读操作均为当前读,读加读锁 (S锁),写加写锁 (X锁)。
-
Serializable隔离级别下,读写冲突,相互阻塞,因此并发度急剧下降。
注:众所周知的快照隔离级别(Snapshot Isolation, SI)不在SQL-92定义的四种隔离级别之列,却在很多数据库中实现,如InterBase, PostgreSQL, Oceanbase。在SI下,事务在启动时得到一个数据库的版本号。事务结束时,成功提交仅当它修改的快照的数据项此时没有被外界改变,即没有写写冲突,否则事务回滚。SI能够规避脏读、不可重复读、幻读的异常,但却不是SQL-92定义的无并发异常的可串行化,这是因为SI下可能出现写偏序异常,解决完写偏序异常后的SI被称作可串行化的SI(Serializable SI, SSI),已经被PostgreSQL 9.1采用。
这里出现了当前读和快照读的概念,这与MySQL中基于MVCC的并发控制机制是密不可分的。
「第三部分 MVCC」
MySQL InnoDB存储引擎实现的是基于多版本的并发控制(Multi Version Concurrency Control, MVCC),MVCC的优势耳熟能详:读不加锁,读写操作不会相互阻塞,系统的并发性能高。
MVCC中,读操作可以分为两类:
-
快照读(snapshot read):读操作读取的是系统的一个一致性快照版本的数据(有可能是历史数据),不需要加锁。
-
当前读(current read):读取的数据需要是最新的,需要对数据加锁,防止有并发的操作修改。
MySQL InnoDB中哪些操作是快照读,哪些操作是当前读呢?
-
快照读:简单的select ... from ... where ?,在Repeatable Read和Read Committed隔离级别下属于快照读,不加锁。
-
当前读:select ... lock in share mode/select ... for update/insert/update/delete等操作属于当前读,需要加锁。
InnoDB实现MVCC的关键技术点
-
ROW记录格式
-
ROW和undo log关系
-
ReadView判断
ROW格式
| 主键 | columns... | DB_TRX_ID | DB_ROLL_PTR |
|---|
-
DB_TRX_ID: 表示这条记录最后一次被变更的事务ID。
-
DB_ROLL_PTR: 回滚指针,指向undo。
可通过语句 SHOW EXTENDED COLUMNs from innodb_table_stats; 查看
读取视图(ReadView)
-
ReadView为活跃事务列表:未提交的事务
-
通过高低水位判断读取的版本
-
low_limit_id 高水位
-
当前读看不到大于此id的事务修改值
-
up_limit_id低水位
-
当前读可以看到所有小于此id的事务修改值
MVCC实现原理-可见性判断
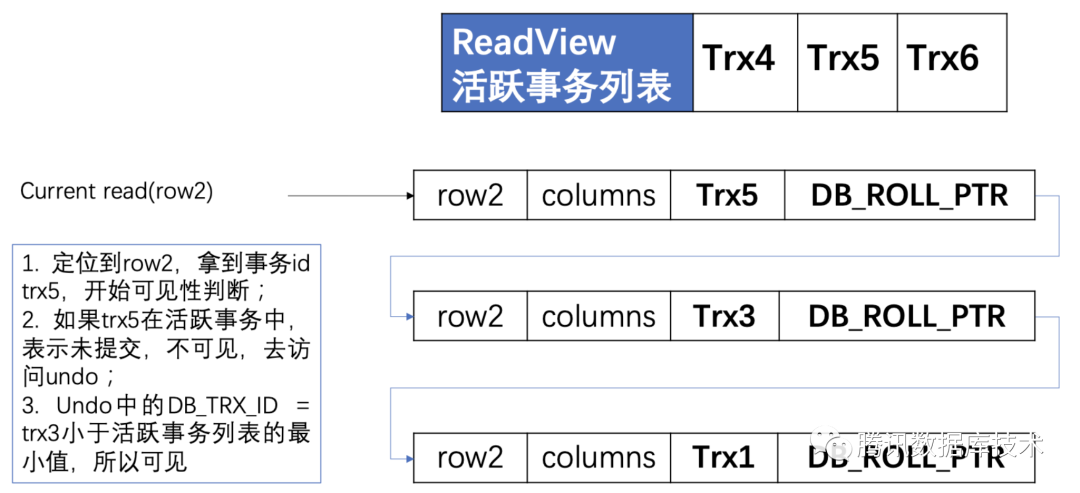
关于InnoDB MVCC更详细的原理和可见性判断可以参考本公众号文章: https://mp.weixin.qq.com/s/UxawgHGembMKK2lA33ZQDA,写的非常棒!
注:InnoDB中MVCC是基于锁和多版本实现的,还有其他的实现MVCC的并发控制机制,例如基于Timestamp Ordering(TO)的方式,有兴趣的同学可以去详细了解。
「第四部分 锁类型」
锁的概念、名词很多,如果没有对锁构建出一个完整的世界观,那么理解起来就会比较有阻碍,接下来我们把这些锁给分一下类。
按照锁的粒度进行划分可以分为:表锁和行锁。
这里就不讨论页锁了,页锁是 BDB(BerkeleyDB) 存储引擎中才有的概念,我们这里主要讨论 InnoDB 存储引擎。
按照兼容性可以把锁划分为:共享锁和排他锁。
被加上共享锁的资源,能够和其他人进行共享,而如果被加上了排他锁,其他人在拿不到这把锁的情况下是无法进行任何操作的。
按照锁的实现,这里的实现就是 InnoDB 中具体的锁的种类了,分别有:
-
意向锁(Intention Locks)
-
记录锁(Record Locks)
-
间隙锁(Gap Locks)
-
临键锁(Next-Key Locks)
-
插入意向锁(Insert Intention Locks)
-
自增锁(AUTO-INC Locks)
即使按照这种分类来对锁进行了划分,看到了这么多的锁的名词可能仍然会有点懵。比如我SELECT ... FOR UPDATE 的时候到底加的是什么锁?
我们应该透过现象看本质,本质是什么?本质是锁到底加在了什么对象上,而这个很好回答:
-
要么加在了表上
-
要么加在了行上
根据作用不同,这些锁又分为以下几种:
意向锁(Intention Locks)
意向锁是一种表级锁,它有以下两种类型:
-
意向共享锁(IS)表明该事务打算对表中的记录加共享锁
-
意向排他锁(IX)表明该事务打算对表中的记录加排他锁
例如,SELECT ... FOR SHARE在对应记录行上加锁之前会在对应表上加的意向共享锁,而SELECT .. FOR UPDATE则先会对表加意向排他锁。
意向锁只会和表级别的锁之间发生冲突,而不会和行级锁发生冲突。因为意向锁的主要目的是为了表明有事务即将、或者正在锁定某一行。
记录锁(Record Locks)
InnoDB记录锁的锁定对象是对应那行数据所对应的索引,而不是具体的行。也就是说,锁信息并不保存在真正的行数据上。
当一张表没有定义主键时,InnoDB 会创建一个隐藏的RowID,并以此 RowID 来创建聚簇索引。
间隙锁(Gap Locks)
官方文档描述:
Gap Lock的唯一目的就是阻止其他事务插入到间隙中。Gap Lock可以同时存在,不同的事务可以同时获取相同的Gap Lock,并不会互相冲突。Gap Lock也是可以显示的被禁止的,只要将事务的隔离级别降低到 READ COMMITTED。
值得注意的是,持有GAP的锁与其他非LOCK_INSERT_INTENTION的锁都是兼容的,也就是说,GAP锁就是为了防止插入的。
临键锁(Next-Key Locks)
临键锁(Next-Key Locks)实际上是记录锁和间隙锁的组合。换句话说,临键锁会给对应的索引加上记录锁,并且外加锁定一个区间。这样其他事务就无法向这个区间内新增数据。
在RR隔离级别下,InnoDB 使⽤ Next-Key Locks防⽌幻读。
幻读:在一个事务内,先后执行了两次相同的查询,第一次查询出来 5 条数据,但是第二次再查,查出了 7 条数据,这就是幻读。
插入意向锁(Insert Intention Locks)
插入意向锁是间隙锁的一种,在执行INSERT语句时需要加的锁,也是用来避免幻读异常的锁。插入意向锁相互之间不冲突,因此并发的事务在相同的index gap内插入不同的行不需要相互等待。
但实际上,在InnoDB的实现中,在不存在冲突的时候,该锁并不会真正的被创建并加入到锁管理器中去,我们在介绍 INSERT 语句的加锁流程时会做更具体的分析。
自增锁(AUTO-INC Locks)
自增锁是一种表级锁,如果一张表存在自增字段 AUTO_INCREMENT,那么事务向该表新增主数据时就会持有自增锁,当语句执行完之后就会释放。在该事务释放自增锁之前,其他的事务不能向该表执行INSERT语句。
实现时,在dict_table_t结构体中有一个autoinc_mutex和autoinc成员变量,用来维护自增字段的值。只在分配时加个mutex即可很快就释放。
因此,在statement格式下不不能保证批量量插⼊操作的binlog复制安全性,因为相同一批INSERT语句分配的自增ID每次可能不相同。
「第五部分 关键结构体」
锁模式
用一个32位的变量表示:
uint32_t lock_t::type_mode;
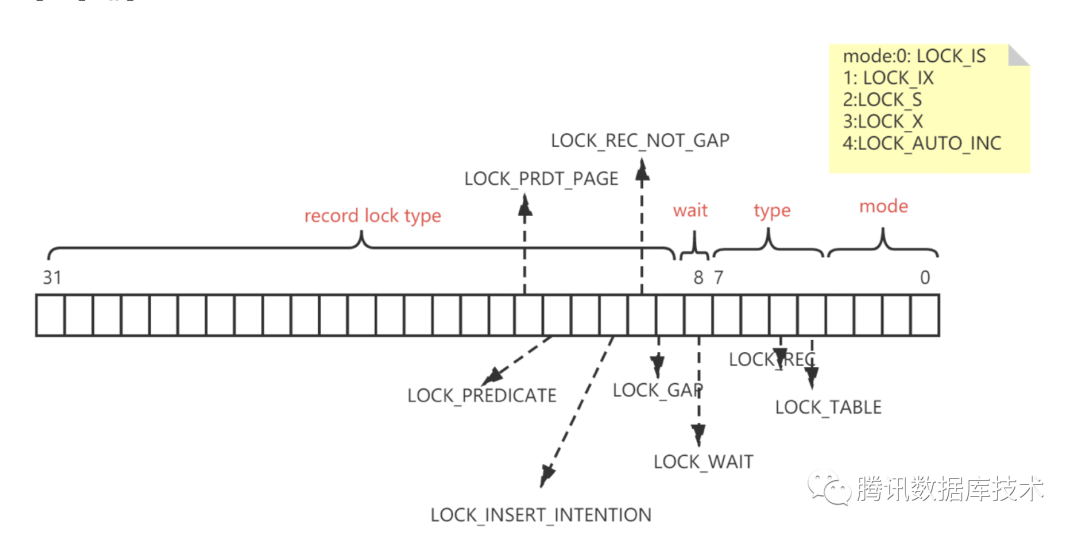
0-3四个bit定义了锁的模式,即这把锁是一把意向共享锁、意向排它锁、共享锁、排它锁还是一把自增锁。
第4位表示这把锁是否是表锁,1代表是表锁,0代表不是。
第5位表示这把锁是否是记录锁,1代表是,0代表不是。
以此类推。
· LOCK_GAP:只锁间隙
· LOCK_REC_NO_GAP:只锁记录
· LOCK_ORDINARY: 锁记录和记录之前的间隙
· LOCK_INSERT_INTENTION: 插入意向锁,用于insert时检查锁冲突
在代码实现上,不同模式的锁的表示方法如下表所示
|
锁模式 |
表示方法 |
|---|---|
| 记录锁 | LOCK_X | LOCK_REC_NO_GAP |
| 间隙锁 | LOCK_X | LOCK_GAP |
| next-key锁 | LOCK_X | LOCK_ORDINARY |
| 插入意向锁 |
LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION |
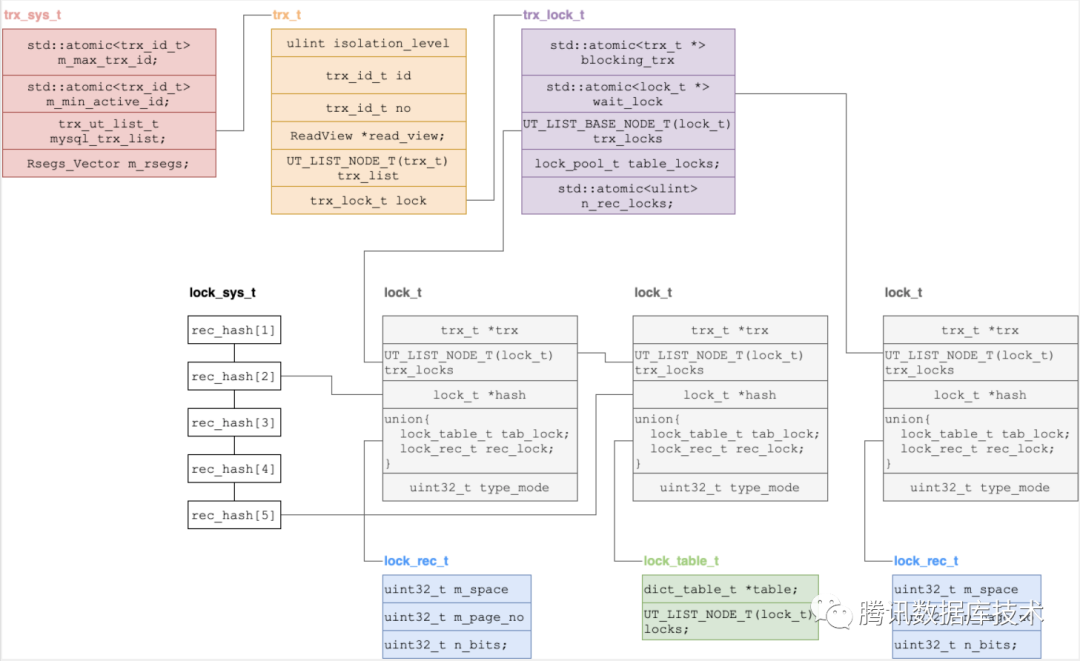
全局锁管理器(lock_sys_t)
-
主要成员变量是一个hash table,用来管理全局活跃事务创建的锁对象。
struct lock_sys_t {locksys::Latches latches;/** 哈希的key是由记录的space id和page no来生成的,value为lock_t */hash_table_t *rec_hash;Lock_mutex wait_mutex;srv_slot_t *waiting_threads;}
锁对象(lock_t)
-
行锁表锁共用lock_t;
-
一个lock_t要么是行锁要么是表锁。
struct lock_t {/** 拥有这个锁对象的事务 */trx_t *trx;/** 该事务持有的锁链表 */UT_LIST_NODE_T(lock_t) trx_locks;/** 记录锁的索引 */dict_index_t *index;/** 记录锁的哈希节点,即接入哈希链的节点,一个锁对象可能被多个事务创建 */lock_t *hash;/** 表锁和记录锁采用union方式管理,节省空间,因为一个锁对象要么是行锁要么是表锁 */union {/** 表锁 */lock_table_t tab_lock;/** 行锁 */lock_rec_t rec_lock;};/** 表示锁的类型和模式 */uint32_t type_mode;};
行锁(lock_rec_t)
-
如果一个lock_t是行锁,记录这些信息
struct lock_rec_t {uint32_t m_space; /** 数据所在表空间id */uint32_t m_page_no; /** 数据所在页号 */uint32_t n_bits; /** lock bitmap的位数 */};
表锁(lock_table_t)
-
如果一个lock_t是表锁,记录这些信息
struct lock_table_t {dict_table_t *table; /** 锁住的表 */UT_LIST_NODE_T(lock_t) locks; /** 同一个表上的表锁链表 */};
NOTES:
-
表锁和记录锁共用数据结构lock_t;
-
行锁以page为单位进行管理,同一个事务在同一个page上的所有行锁只创建一个lock_t,具体要看某一个记录上是否有锁,要用该记录在page中唯一标识的heap no到bitmap查询该位是否为1;
-
lock_t结构体中不包含bitmap成员变量,但是在申请内存的时候,会在申请sizeof(lock_t)这块内存的基础上,额外多要一块bitmap大小的内存。紧邻lock_t存放,每个bit代表页内一行数据,使用heap_no对应。
行锁ID(RecID)
-
用来唯一标识一个lock_t中某一行具体的锁。
struct RecID {uint32_t m_space; /** 表空间ID */uint32_t m_page_no; /** 页面号 */uint32_t m_heap_no; /** 页上的heap no */ulint m_fold; /** hashed key value,通过m_fold找到在lock_sys_t::rec_hash对应lock_t链表,该链表上的所有lock_t拥有相同的space id和page no,某一行上的冲突通过bitmap判断 */}
事务锁管理器(trx_lock_t)
-
事务对象的一个成员变量,用来管理该事务持有的锁、等待的锁等跟锁相关的信息。
struct trx_lock_t {std::atomic<trx_t *> blocking_trx; /** 阻塞住该事务的事务 */std::atomic<lock_t *> wait_lock; /** 等待的锁对象 */UT_LIST_BASE_NODE_T(lock_t) trx_locks; /** 该事务请求的所有锁链表 */lock_pool_t table_locks; /** 该事务请求的所有表锁,包括自增锁 */std::atomic<ulint> n_rec_locks; /** 请求的行锁的个数 */}
事务(trx_t)
-
保存一个事务执行期间的上下文。
struct trx_t {ulint isolation_level;mutable TrxMutex mutex;bool abort;trx_id_t id; /** 事务ID */trx_id_t no; /** 事务串行化号:事务进入COMMIT_IN_MEMORY状态前最大的事务ID */ReadView *read_view; /*!< 事务中使用的一致读取视图 */UT_LIST_NODE_T(trx_t) trx_list; /** 事务链表 */trx_lock_t lock; /** 事务锁管理器 */time_t start_time;lsn_t commit_lsn;THD *mysql_thd; /*!< MySQL处理该事务的线程 */}
全局事务管理器(trx_sys_t)
-
管理全局正在执行的事务。
struct trx_sys_t {TrxSysMutex mutex;MVCC *mvcc; /** 管理读取视图 */std::atomic<trx_id_t> m_max_trx_id;std::atomic<trx_id_t> m_min_active_id;trx_ut_list_t mysql_trx_list; /** 事务链表 *//** std::vector of rollback segments */Rsegs_Vector m_rsegs;}
这些数据结构之间的关系如下图所示:
「第六部分 加锁模式及加锁流程」
6.1 当前读加锁模式
回顾前文所说,MVCC中当前读操作需要读取到最新的一致的数据,因此需要对数据行加锁,对于加在行上的锁,其本质是将锁加在了这行数据对应的索引上。在一个支持MVCC并发控制的系统中,一条SQL究竟加什么锁还与以下因素密切相关:
-
当前系统的隔离级别(RC,RR,Serializable)
-
索引(是否有索引,是否是主键索引,是否是二级唯一索引)
-
是等值查询还是范围查询
-
是否修改了其他索引数据
-
查询计划(是走索引还是走全表扫描,是否有索引下推)
RR+主键列索引
-
如果有对应的主键记录就在记录上加记录锁(lock_x | lock_rec_not_gap)
-
如果没有对应的主键记录就在后面的记录上加间隙锁(lock_x | lock_gap),防止其他事务插入这条记录。
-
UPDATA和DELETE与SELECT FOR UPDATE的区别在与,在更新包含索引列的情况下,前者需要更新二级索引,需要对涉及索引上加记录锁(lock_x | lock_rec_not_gap)。
-
与等值当前读不同的是,范围读需要在主键索引上加next-key locks,防止其他事务在查询范围内插入新的数据。其他一样。
-
以下是不同范围更新的加锁情况,其中supremum表示索引的上界。
RR+唯一索引
通过二级唯一索引更新记录,首先会在WHERE条件使用到的二级索引上,如果是等值查询加Record类型的X锁,如果是范围查询,需要加Next-key类型的X锁。然后通过二级索引找到primary key,并在primary key上加Record类型的X锁(之所以不是Next-key,是因为查询条件是二级索引)。最后对满足范围条件的最后一条记录的下一条记录加间隙锁(lock_x | lock_gap),如果是supremum加next-key lock(lock_x|lock_ordinary)。
RR+非唯一索引
等值和范围查询都需要在对应索引上加next-key locks, 因为不唯一,即使使用等值查询,其它事务仍然有可能插入满足查询条件的新纪录。
在InnoDB中,通过二级索引更新记录,首先会在WHERE条件使用到的二级索引上加Next-key类型的X锁,以防止查找记录期间的其它插入/删除记录,然后通过二级索引找到primary key并在primary key上加Record类型的X锁(之所以不是Next-key,是因为查询条件是二级索引,若WHERE条件使用到的是primary key上的范围查询,就会上Next-key类型的X锁),之后更新记录并检查更新字段是否是其它索引中的某列,如果存在这样的索引,通过update的旧值到二级索引中删除相应的entry,此时X锁类型为Record。最后对最后一条满足条的记录的下一条记录上加间隙锁,防止有数据插入。
我们以一个二级非唯一索引上的更新操作为例:
mysql> CREATE TABLE `t` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,`c` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `idx_a_b` (`a`,`b`),KEY `idx_b` (`b`)) ENGINE=InnoDB;mysql> update set c = c + 1 where b = 62;
代码执行流程:
该SQL以二级非唯一索引作为查询条件,因此,首先需要找到的二级索引上的相应列加next_key lock(lock_x | lock_ordinary),
接着对找到的主键索引记录加记录锁(lock_x | lock_rec_not_gap),
更新结束后,对最后一条记录的下一条记录(在这里是b = 63的那条数据)加间隙锁(lock_x | lock_gap),防止有数据插入。
RR+无索引
在Repeatable Read隔离级别下,如果进行全表扫描的当前读(可能是没有索引,也可能是有索引,但是查询计划并没有走索引),那么会对主键索引上的所有记录加上next key locks,对supremum加上next key locks,对满足条件的记录的索引加上记录锁(lock_x | lock_rec_not_gap),杜绝所有的并发 更新/删除/插入 操作。
当然,也可以通过触发semi-consistent read,来缓解加锁开销与并发影响,但是semi-consistent read本身也会带来其他问题,不建议使用。semi-consistent read在下面的章节中介绍。
RC
-
RC下所有语句都不会加next_key locks和gap locks,只会加record locks。
-
如果查询范围是主键索引,对相应主键记录加LOCK_X|LOCK_REC_NOT_GAP,
-
如果是更新操作,并且更新包括其他索引列,还需要在涉及索引上加LOCK_X|LOCK_REC_NOT_GAP锁。
-
如果查询条件是二级非唯一索引,且是更新操作,并且更新包括其他索引列,那么会依次对二级索引和对应主键行,索引数据加LOCK_X|LOCK_REC_NOT_GAP锁。这里需要注意的是,查询条件对应的数据会直接加显式锁,其他的二级索引上得记录锁是隐式锁,这在下面介绍隐式锁的章节中有所介绍。
RC+无索引查询
若id列上没有索引,SQL会走聚簇索引的全扫描进行过滤,由于过滤是由MySQL Server层面进行的。因此每条记录,无论是否满足条件,都会被加上X锁。但是,为了效率考量,MySQL做了优化,对于不满足条件的记录,会在判断后放锁,最终持有的,是满足条件的记录上的锁,但是不满足条件的记录上的加锁/放锁动作不会省略。同时,优化也违背了2PL的约束。
提前释放锁执行路径:
Sql_cmd_update::update_single_table->ha_innobase::unlock_row->row_unlock_for_mysql->lock_rec_unlock
6.2 当前读加锁流程
函数lock_rec_lock中是确定上锁模式之后具体的上锁的流程,首先通过lock_rec_lock_fast函数判断是否可以快速上锁,
-
如果该page上没有锁记录,直接创建锁记录,返回加锁成功;
-
如果page上有多个行锁:
-
如果已经拥有该锁的事务不是当前事务,或者该锁不是一个行锁,或者申请锁的heap no大于该锁的bitmap的位数,不能直接加锁。
-
否则的话可以加速成功,对应的bitmap位置为1。
如果不能快速加锁成功的话,调用lock_rec_lock_slow上锁:
-
如果该事务上已经拥有一个在该记录上更强的锁了,直接返回成功;
-
如果没有的话:
-
通过heap no去bitmap查是否这一行存在冲突,存在锁冲突,加入等待队列,返回锁等待;
-
不存在冲突,将锁加入到lock sys中去,返回加锁成功。
6.3 semi-consistent read
简单来说,semi-consistent read的作用是减少更新同一行记录时的锁冲突,减少锁等待。
一个update语句,如果读到一行上没有锁,读取最新版本的数据并加锁;如果读到一行已经加锁的记录,此时InnoDB返回记录最近提交的版本,由MySQL上层判断此版本是否满足update的where条件。
-
若满足,则MySQL会重新发起一次读操作,此时会读取行的最新版本(并加锁)。
-
对于不满足更新条件的记录,可以提前放锁,减少并发冲突的概率。
semi-consistent read只会发生在read committed隔离级别下,或者是参数innodb_locks_unsafe_for_binlog=ON。且仅仅针对于update操作。
6.4 insert加锁流程
我们在前文介绍锁类型的时候提到了插入意向锁,它的作用是在事务执行insert语句时防止幻读,插入意向锁模式:LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION。
|
请求锁\持有锁 |
GAP |
Insert Intention |
Record |
Next-key |
|---|---|---|---|---|
| GAP | ||||
| Insert Intention | x | x | ||
| Record | x | x | ||
| Next-key | x | x |
当向某个数据页中插入一条记录时,总是会调用 lock_rec_insert_check_and_lock 函数进行锁检查,会去检查当前插入位置的下一条记录上是否存在锁对象。
如果下一条记录上存在锁对象,就需要判断该对象是否锁住了gap。如果gap被锁住了,判定和插入意向锁冲突,当前插入操作需要等待。但是插入意向锁之间并不互斥,这意味着同一个gap里可能有多个申请插入意向锁的会话。如果不存在冲突,InnoDB使用了隐式锁来优化这一场景的性能。
隐式锁
当事务需要加锁的时,如果这个锁不可能发生冲突,InnoDB会跳过加锁环节,这种机制称为隐式锁。隐式锁是InnoDB实现的一种延迟加锁机制,其特点是只有在可能发生冲突时才加锁,从而减少了锁的数量,提高了系统整体性能。另外,隐式锁是针对被修改的B+ tree记录,因此都是记录类型的锁,不可能是间隙锁或Next-Key类型锁。
InnoDB的每条记录中都一个隐含的trx_id字段,这个字段存在于聚集索引的B+tree中。假设只有主键索引,则在进行插入时,行数据的trx_id被设置为当前事务id;假设存在二级索引,则在对二级索引进行插入时,需要更新所在page的max_trx_id。
-
UPDATE、DELETE 在查询时,直接对查询用的 Index 和主键使用显示锁,其他索引上使用隐式锁。
在函数lock_rec_insert_check_and_lock中,加锁流程如下。
dberr_t lock_rec_insert_check_and_lock(){.../* 插入意向锁模式 */const ulint type_mode = LOCK_X | LOCK_GAP | LOCK_INSERT_INTENTION;const lock_t *wait_for =lock_rec_other_has_conflicting(type_mode, block, heap_no, trx);/* 如果与插入意向锁有冲突,创建一个插入意向锁,加到事务锁列表中去,插入等待队列中 */if (wait_for != nullptr) {RecLock rec_lock(thr, index, block, heap_no, type_mode);trx_mutex_enter(trx);err = rec_lock.add_to_waitq(wait_for);trx_mutex_exit(trx);}switch (err) {...case DB_SUCCESS:/* 如果没有冲突,直接更新最大事务号,返回成功 */page_update_max_trx_id(block, buf_block_get_page_zip(block), trx->id,mtr);...}...}
隐式锁转换为显式锁
将记录上的隐式锁转换为显示锁是由函数lock_rec_convert_impl_to_expl完成的:
主键索引上判断隐式锁是否存在
对于主键,只需要通过查看记录隐藏列trx_id是否是活跃事务就可以判断隐式锁是否存在。对于对于二级索引会相对比较麻烦,先通过二级索引页上的max_trx_id进行过滤,如果无法判断是否活跃则需要通过应用undo日志回溯老版本数据,才能进行准确的判断。
二级索引上判断隐式锁是否存在
lock_sec_rec_some_has_impl函数中:先可以通过PAGE_MAX_TRX_ID进行判断,如果当前PAGE_MAX_TRX_ID的值小于当前活跃事务的最新ID,说明修改这条记录的事务已经提交,则不存在隐式锁,反之则可能存在隐式锁,需要通过聚集索引进行判断,其判断过程由函数row_vers_impl_x_locked_low完成:
-
获取保存在聚集索引记录上的事务ID
-
如果该ID等于本事务ID,返回本事务,存在隐式锁。
-
如果该ID对应的事务已提交,返回0。
-
事务未提交,需要通过undo日志找到是哪个事务修改了二级索引记录
-
通过undo日志获取老版本记录,获取老版本事务ID,构造老版本tuple,构造老版本二级索引tuple ,如果两个版本的二级索引记录相同,但是deleted_flag位不同,表示某活跃事务删除了记录,因此二级索引记录含有隐式锁 */ /* 两个版本的二级索引不同,且deleted_flag为0,表示某活跃事务更新了二级索引记录,因此二级索引含有隐式锁。
二级索引在判断出隐式锁存在后,也是调用lock_rec_convert_impl_to_expl_for_trx函数将隐式锁转化为显示锁,并将其加入到lock hash table中。
一个并发场景
从上面的分析可知,INSERT操作首先判断是否有跟插入意向锁冲突的事务,如果没有冲突会在对应的位置更新事务号信息,这两个操作之间是有时间差的,如果在这之间执行 select ... lock in share mode 语句,由于此时记录还不存在,所以也不存在活跃事务,不会触发隐式锁转换,这条语句会返回 0 条记录,并加上 GAP 锁;而 insert 语句继续写数据,不加任何锁,在 insert 事务提交之后,select ... lock in share mode 就能查到 1 条记录,这岂不是幻读问题吗?
insert调用栈:row_ins_step -> row_ins -> row_ins_index_entry_step -> row_ins_index_entry -> row_ins_clust_index_entry -> row_ins_clust_index_entry_low -> btr_cur_optimistic_insert -> btr_cur_ins_lock_and_undo -> lock_rec_insert_check_and_lock。
在函数row_ins_clust_index_entry_low中会开启一个mini transaction。
每个 mini-transaction 会遵守下面的几个规则:
-
修改一个页需要获得该页的 X-LATCH;
-
访问一个页需要获得该页的 S-LATCH 或 X-LATCH;
-
持有该页的 LATCH 直到修改或者访问该页的操作完成。
因此,该并发导致的幻读不会发生:
-
执行 insert 语句,对要操作的页加 RW-X-LATCH,然后判断是否有和插入意向锁冲突的锁,如果有,加插入意向锁,进入锁等待;如果没有,直接写数据,不加任何锁,结束后释放 RW-X-LATCH。
-
执行 select ... lock in share mode 语句,对要操作的页加 RW-S-LATCH,如果页面上存在 RW-X-LATCH 会被阻塞,没有的话则判断记录上是否存在活跃的事务,如果存在,则为 insert 事务创建一个排他记录锁,并将自己加入到锁等待队列,最后也会释放 RW-S-LATCH。
INSERT当前读判断记录是否存在
-
mtr.start()
-
首先判断插入记录是否有唯一键,如果有,则进行唯一性约束检查:
-
如果不存在相同键值,则继续第三步;
-
如果存在相同键值,则判断该键值是否加锁:
-
如果没有锁, 判断该记录是否被标记为删除:
-
如果标记为删除,说明事务已经提交,还没来得及 purge,这时加 S 锁等待;
-
如果没有标记删除,则报 1062 duplicate key 错误;
-
如果有锁,说明该记录正在处理(新增、删除或更新),且事务还未提交,加 S 锁等待;
-
如果唯一性检查成功,对插入的间隙判断是否和插入意向锁(Insert Intension Locks)的有冲突:
-
如果该间隙已被加上了 GAP 锁或 Next-Key 锁,则加锁失败,创建插入意向锁进入等待;
-
如果没有,则加锁成功,表示可以插入,对应page写trx_id;
-
插入记录,更新记录trx_id。
-
mtr.commit()
INSERT当前读判断记录是否存在的加锁流程在RR和RC下相同。
6.5 锁唤醒与回滚
锁冲突进入等待后,事务挂起,等待被唤醒,触发锁唤醒的主要场景有:锁授予唤醒、死锁唤醒(事务回滚)、超时唤醒(语句回滚)。
如果某一个操作因为锁等待超时而回滚,此时事务持有在表级上的锁并不会被释放(具体流程见lock_cancel_waiting_and_release),这是合理的,因为我们并不知道在该操作之前,事务是不是就已经获得了该表上的锁,如果是,那么释放这个表锁会使得,该事务还未结束,其他DDL操作就能够正常进行,从而引起一致性错误。
此外,一个事务中途的操作出现任何异常,已经持有的行锁不会释放(semi consistent read除外),严格按照两段锁协议。
CATS事务调度算法
CATS(Contention Aware Transaction Schedule)是MySQL 8.0的一个新特性,相关论文发表在VLDB 2018。它的作用是在高冲突场景下,一个事务在释放一个锁后决定这把锁给哪个等待的事务。CATS将等待的事务按照权重排序,权重最高的事务拥有最高的优先级获得等待的锁。事务的权重取决于等待这个事务的事务数量。换句话说,一个事务有越多的等待事务,那么它获取锁的优先级越高。
回滚流程
回滚有两种:一种是事务级的回滚,回滚整个事务;第二种是使用savepoint部分回滚,可以回滚到事务中间的某一个状态。ROLLBACK SAVEPOINT *savepoint_name*
第一种没什么好说的,回滚整个事务,释放所有获得的锁,第二种回滚不会结束事务,InnoDB不会释放内存中的行锁,这是满足两段锁协议的,能够有效减少死锁的发生。
如果回滚的操作中有INSERT操作,结果会有点不同,INSERT操作会在下一条满足条件的记录上加上gap锁,如果下一条记录是supremum,加next-key锁,防止有新的事务插入这条数据,引起幻读异常。因此,使用savepoint回滚INSERT操作时,事务并不会释放supremum上的锁。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号