Streaming Telemetry 流遥测技术 SNMP 采集频率 推拉
乐维Zabbix技术资料Zabbix交流区解决方案 ——惠普服务器SNMP采集频繁导致服务停止 http://www.lwops.cn/forum.php?mod=viewthread&tid=68&fromuid=1
| 运维软件:zabbix 采集方式:snmp 采集设备:惠普-DL380_Gen9-服务器 采集周期:根据指标要求频率有5分钟到1天 主要命令:reset /map1 snmp采集惠普服务器一段时间后,zabbix提示连接失败,重启ilo后又可以重新采集,我们可以利用这一点做一个自动重启脚本,保证采集正常。 实现思路:zabbix检查自定时间内没有数据->触发告警脚本->告警脚本登录设备执行 reset /map1 1.我们要模板里加一个多久没有采集到数据的触发器如: <ignore_js_op>  2.增加报警媒介。 管理->报警媒介类型->创建报警媒介类型。 <ignore_js_op>  脚本的操作是根据传过来的参数到数据库是找出此设备管理口IP、帐号、密码。主要sql:SELECT i.ip,h.ipmi_username,h.ipmi_password from `hosts` as h LEFT JOIN interface as i on i.hostid = h.hostid where h.host="'.$hostName.'" and i.port= 161。 然后用ssh连接到该设备,执行reset /map1 就可以重启该ilo了。 3.添加动作 配置->动作->创建动作 <ignore_js_op>  到此重启设备ilo口完成。 面对snmp频繁采集导致snmp连接失败,这也是一个解决方案。 |

SNMP 协议_使用文档_智能日志管理平台 - 七牛开发者中心 https://developer.qiniu.com/insight/4774/snmp-reader
-
名称(
snmp_reader_name):默认system, 对于简单变量(snmp_fields中的字段), 将把该字段放入收集的数据中, 所谓标识, 类似于 table_name。 -
连接超时时间(
snmp_time_out): 默认5s, 超时时间。【如果snmp_tables数据项比较多,5s返回时间太短,建议调整为100s】 -
收集频率(
snmp_interval): 默认30s, 采集频率。 -
重试次数(
snmp_retries):默认3, 重试次数。
SNMP 已死 - Streaming Telemetry 流遥测技术_姜汁啤酒的网工日常的技术博客_51CTO博客 https://blog.51cto.com/gingerbeer/2287783
姜汁啤酒2018-09-30 09:40:19©著作权
第一:数据不精确
SNMP是基于查询的模式,网管系统通过定期发送snmp 查询消息,挨个儿问网络设备,或者服务器设备?
喂,你好么?
你哪里啥情况啊,接口流量是多少,CPU是多少,内占用率等?
就像大学时候的查房老太太,过一会儿就过来骚扰你一下。
但是这个查询,毕竟有个时间间隔,一般情况下我们都是配置5分钟,即300秒。
你要是以一天,或者数小时来看,5分钟的确很短。
所以一切都很好,很完美。
但是,偶尔就会出问题,我们以基于类似Cacti这种流量监控平台为例。
例如,客户抱怨在某个时间段网速很卡,有丢包现象。
然后工程师查看监控平台,没问题啊,我们监控平台上接口流量非常稳定。
没见着拥塞。
你说,这个时候,你是说客户刁蛮,还是说工程师说假话?
其实他们两个说的都没错。
让我们看下图:
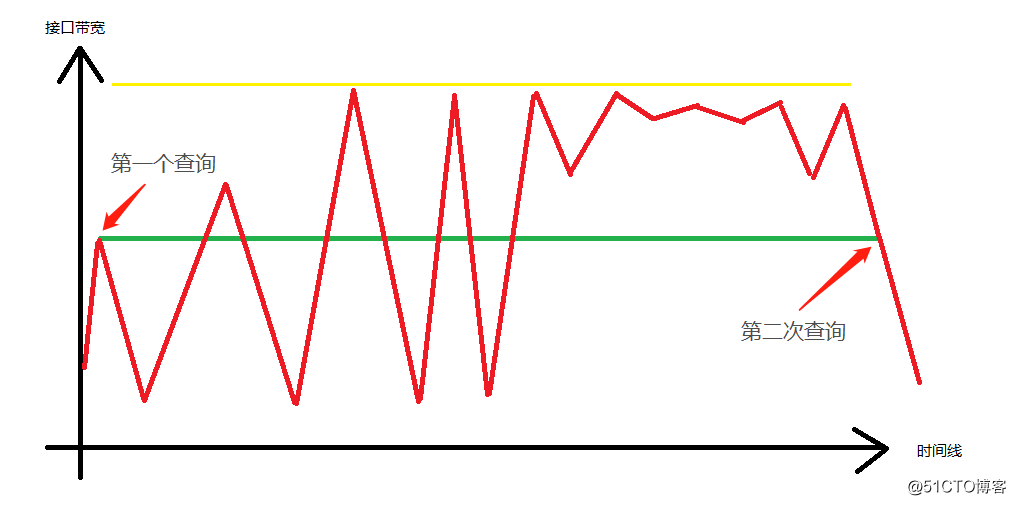
(姜汁啊,嗯?你这个windows画图功底有待加强啊,不是一般的丑啊。)
上图中,绿色线条为监控系统认为的带宽,而顶上的黄 色 线 条代表接口带宽,上下波动的代表实时流量。
我猜,不用仔细说,你估计都知道大概了。
没错,当5分钟前SNMP第一次查询时,得到了第一个值,而第二次查询后,很碰巧,得到的值和第一次一样。
所以从SNMP的角度来看,貌似这5分钟之内,所占用的接口带宽没变化。
但是,真正的用户数据正如滔滔大浪,风云变幻。
你不知道在某一个时刻就会有突发数据,而突发两个字,正说明了他不是持续性的,是临时突然出现。
可是这突发流量仍然会造成网络接口丢包。
例如图中几个凸出。
可是在监控系统里面,却是风平浪静,岁月静好啊。
上面的例子可能稍微极端点,因为完全平直的监控平台流量线,不太可能。
但是很平滑,而不是突突突的突发流量,倒是实实在在发生的。
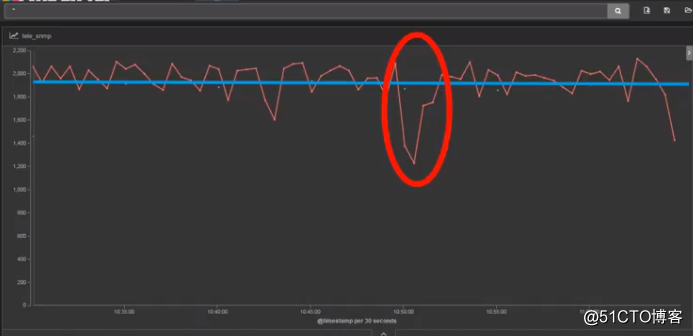
例如,下面又是另外一个反例:
下图中, 蓝色线条,很不幸,仍然是SNMP查询。
而红色线条,是某个监控协议吐出来的数据。
这里看出,红色线条非常贴近于真实流量了。
而粗红色线条圈起来的部分,则是某个故障导致流量暴跌。
可是,SNMP的定期查询,是看不到这些细节的。
在他的眼里,永远是丝般顺滑的直线。
第二:出力不讨好
上面说了,SNMP因为定期查询的原因,导致n多细节漏掉了。
有些小伙伴嘴角上扬,露出坏坏的笑容。
你这还不好解决,把SNMP查询时间调短一点不就行了么。
例如,1分钟,想爽一点30秒也成。
这叫当领导的动嘴,干活的动腿啊。
相信很多运维朋友肯定体会过,网络设备CPU定期飙高。
特别有规律,几分钟来一把。
而且赶巧的时,网管系统的服务器也特别心有灵犀,两者一起共振。
你高,我也高。
查来查去,就一个进程搞的事:SNMP。
这不用说,要么就是监控系统太多,这个系统负责查询一部分,那个系统负责查询另外一部分。
这网络设备吃不消啊。
要么是一个监控系统,但是查询内容太多。例如每查询一次,基本上把网络设备翻了个底朝天。
因为这些查询相应都是基于网络设备的路由引擎来处理,CPU能不高么?
所以,修改查询频率过高也不行。
第三:不靠谱
上面说完了snmp 查询,snmp的trap消息也是存在问题。
一般情况下我们都是用UDP来承载SNMP消息,那UDP的德行你们也懂的。
没问题还好,有啥问题了,直接当场把数据包丢了,关键是还不告诉你数据包被它丢了,这个品行值得怀疑。
一般协议还行,但是SNMP trap就这么一个啊。
你要是一个接口down掉了,网络设备就发一次,仅此一次trap消息这个独苗苗。
UDP照丢不误。
丢了以后,网络设备拍拍屁股说,反正我发出去了。
网管系统说,我没看见,不知道。
另外一个问题,我自己就遇到过,例如当一台监控平台设备同时管控上千台设备的时候。
这些不同时间段的snmp trap消息就像洪水一样涌入监控平台设备,可是当这些trap在进入监控平台内部snmp进程的时候,因为开源软件的某些bug,并发数不够了,导致trap在设备内部软件队列排着队,进场。
然后滑稽的一幕出现了,2个小时前一台网络设备挂了,网管中心监控人员开心的吃着火锅唱着歌。直到有人冲到办公室说,我们网断了,什么情况?
没有啊,你看监控平台,全是绿油油的灯,多美。
两小时以后,有人大呼,设备down了。
那回到问题本身,假设现在有一个重要接口down掉了,靠SNMP你怎么解决?
A. 咱把查询时间调节到每秒查询吧?
B. 等着SNMP trap消息吧?
你说上面两个,你选择哪个?
第四:不完全兼容
你是否遇到如下场景:
一早上,什么事情没干,光百度了。
百度什么?
关键字:某某设备的MIB库?
或者,关键字:某某设备SNMP 查询某个数值。
这些事情,真心烦心。
到最后怎么解决的?
唉,还能怎么解决,敲命令行收集呗。
要是会编程,就写个程序来敲命令收集呗。
要是当领导了,就找个会写代码的工程师,写个程序来敲命令收集呗。
第五:毫无人性的OID值
问你个问题,你知道这是什么?
.1.3.6.1.2.1.2.1.8
答:SNMP OID值。
再问?
什么OID值?
如果你说:这指代IF-MIB的接口状态,ifOperStatus
恭喜你,你可以进入非正常人类研究中心参观了。
我相信你也玩过snmpwalk,你walk一把出来的全是一堆非人类语言,密密麻麻的数字。
你说上班的心情怎么能好?
SNMP 小结
不敢再说多了,说多了都是在拉仇恨,毕竟包括我在内很多人都还在依靠着SNMP,不伺候好了,小心给你罢工。
综上所述,SNMP在现如今的网络环境下,的确遇到了瓶颈。
尤其是网络规模日益扩大的今天。
所以,应了那句话:
有些SNMP还活着,但是其实它已经死了。。
怎么办?
从拉(Pull) 到推(Push)的变化。
我们能不能换个角度,把传统的从监控系统到网络设备”拉“数据的方法,变为网络设备主动向监控系统”推“数据的方法?
例如,以SNMP 为例的设备状态获取方法是拉的方法,即所谓的查询。
这就导致了网络设备被动响应,因为你不知道什么时候SNMP查询会飞过来,等它来了,网络设备不得不分配资源处理。
但是,换个角度,如果采用主动上报的方式,这个问题就解决了。
因为主动上报,网络设备握有主动权,开发人员可以根据实际运行情况调整设备资源利用率和负载。
为了方便阅读,下面是两者的一个简单对比:

不用说,一番PK下来,除了灵活性败给被动查询,其他方面主动上报”推“的方式优势巨大。
未来趋势:Streaming Telemetry 流遥测技术
这个名字很吊,流遥测技术。
其实,简单来讲。它就是实现了上述“推”数据的方法。
那如何高效的完成“推”的这个动作呢?
Streaming Telemetry有如下特点:
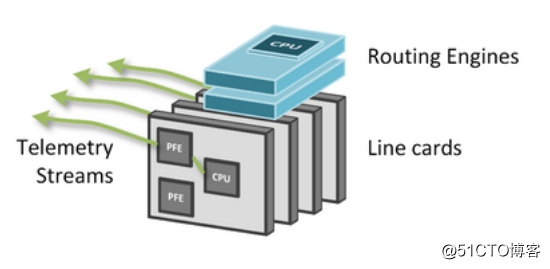
1. 基于数据层面的数据上报
传统的SNMP,不管是查询还是Trap,都是路由引擎,控制层面来处理。
但是Streaming Telemetry则可以借助于厂商支持,在硬件板卡ASIC层面植入代码,直接从板卡导出实时数据。
而板卡导出的数据是按照线速发送,从而使得上层的路由引擎专注于处理协议和路由计算等。
如下图所示:
2.高扩展性
基于第一条数据层面的原因,Stream Telemetry的扩展性大大增强。
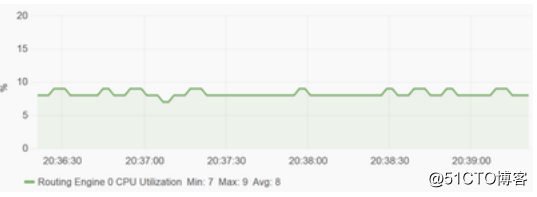
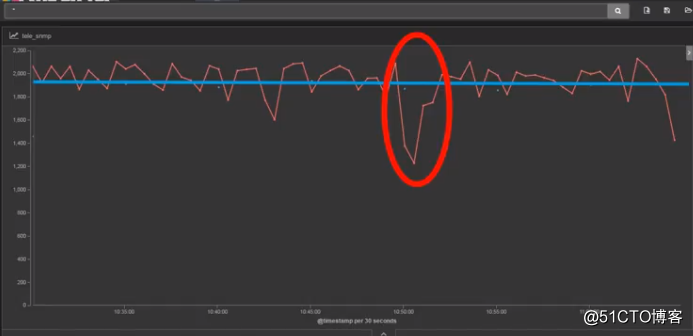
例如下面这张图是一张CPU的利用率图。(设备型号未知)
大致看来,CPU利用率徘徊在8%左右。
但是,这台设备配置了Stream Telemetry主动上报。
你猜,它都上报了多少内容?
下面是数据:
- 每15秒上报一次
- 超过60种指标上报
- 包含500多个上报类型
- 176个万兆接口的输入,输出统计,error数,Qos队列数统计。
- 每一个接口都包含IPv4和IPv6两种数据类型。
- 最后以及200个MPLS LSP的字节数和数据包数。
太恐怖了,SNMP与之相比,瞬间弱爆了。
这一张图片红色线条,在上面提到过是某协议吐出的数据。
不用说,你都知道了。
这就是Streaming Telemetry吐出的数据。
3. 自动支持 Devops运维自动化
Streaming Telemetry因为两大优势,自动对接了当前流行的技术,例如运维自动化技术。
一方面,Streaming Telemetry监控平台收集到的数据接近于即时信息,所以Devops运维自动化工程师可以有很多不同的玩法,例如根据当前流量数据,结合SDN来自动调整数据转发路径。
另外一方面,Streaming Telemetry采用的数据格式都是当今很流行的标准格式和模型。例如JSON,NETCONF,以及YANG模型。
所以,简单来说,这是一个顺应时代的工具和技术。
4. 多选择
目前Streaming Telemetry技术,有两个选择。
一个是Sflow
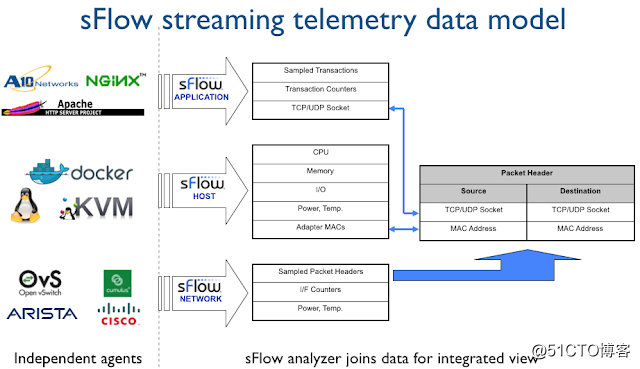
而另外一个是OpenConfig Telemetry
(已经在Google部署,30%的厂商设备已经开启Streaming Telemetry,每秒百万级别的更新量。)

少走冤枉路!带你走过SNMP的那些坑_uyunopss的博客-CSDN博客_snmp开源库 https://blog.csdn.net/uyunopss/article/details/53183660
2016-11-16
文章标签: SNMP
SNMP(Simple Network Management Protocol)即简单网络管理协议,是在网络与系统监控领域中,最常使用的一种数据采集技术。尽管这个协议非常简单,但在大规模IT环境监测中,还是经常会碰到各种坑,因此优云开源了一套友好的SNMPAPI,并通过本文简单介绍这套API中的一些特点,希望帮助各位运维同仁提前规避一些问题。
特点[0].提供解析各种数据类型的SnmpValue类
在SNMP中,有各种各样的数据类型,光表达数值类型的,就有Gauge32、Integer32、Counter32、Counter64等数十种,甚至有一种称为OctetString的万能数据类型,可以代表常见的ASCII字符串、IP地址、MAC地址、端口列表等等含义。很多老手都经常由于错误的转换OctetString,导致采用到的数据没有意义,更别提新手面对这些数据类型,会有多糊涂了。
本API所返回的采集结果,均使用SnmpValue类,对各种原数据类型进行了统一封装,提供了更友好的使用接口,如下所示:
特点[1].提供避免死循环的Walk操作
Walk操作是指不断使用Get-Next请求去逐个采集设备的一些相邻OID,以获取一批相关信息的操作。
从SNMP规范上来说,设备上的OID排列应该是升序并且不会重复,但林子大了,什么鸟都有!一些OID出现逆增长甚至干脆重复的设备也会出现。因此程序员写出会死循环的Walk操作也很常见。
而本API提供的三个特性可以避免这种情况出现:
·兼容OID逆增长
·自动合并重复OID,保留同一个OID采集到的最后一次值
·允许设置单次Walk最大结果数,避免死循环、
特点[2].提供Table数据类型与WalkTable操作
Walk操作很多时候都是在采集设备的表格类信息,如端口列表、路由表、转发表等。
但在使用普通的Walk操作时,返回的只是一个一维数组,每个元素只对应到表格中的一个单元格。因此为了从中完整的提取出一个路由记录、端口信息,往往要需要不停的遍历数组,根据OID与Index提取元素。同时由于设备的表格也可能在Walk过程中发生了改变,有时也会碰到缺失某些单元格的情况,无法组织起有效数据的情况。
因此,如果使用传统的方法来提取信息,一般会写出如下复杂的代码:
而使用本API中的walkTable与Table数据类型,可以大大的简化相关操作,如下所示:
特点[3].合并pdu发出多个requestoid,大幅度提高性能
在进行SNMP采集时,往往会出现大量的SNMP请求,这是因为进行Walk时,需要产生大量的Get-Next操作。
举例来说,采集一个拥有48个端口的设备端口表,则需要的请求数为:
> 48(端口数)* 22(每端口字段数)=1056次请求
而本API,在设计时考虑到了减少请求的需求,会尝试将一行多个字段的OID请求合并到一次请求中,以大幅度减少需要发出的数据包数量。
同样采集一个48个端口,其需要的请求数为:
> 48(端口数)* 1(合并后的请求数)=48次请求
可见减少了96%的请求。
特点[4].控制SNMP采集频率,避免被管设备CPU飙升
最后,由于一些网络设备较为陈旧,其采用的CPU性能较弱,以及厂商的SNMP Agent存在性能缺陷,因此在实际的SNMP采集操作时,常经常会出现CPU利用率持续在100%,更有甚者开始出现网络数据丢包,影响正常数据转发功能的情况。
本API默认对访问频繁进行了50ms的最低频率控制,并且此参数也可按被采集的设备进行单独调整,因此可有效避免SNMP采集对设备的不利影响。
除上述特点外,此套开源类库,还提供了诸如“OID联合与父子判断”、“异常简化”、“V3参数简化”、“Table缺失容错”等优秀特性,欢迎大家使用与进一步补充功能。
作者介绍 蒋君伟 任职优云软件
·IT运维资深实践者;
·研发成果:网络管理、系统管理、CMDB、ITSM等产品,并成功建设了多个全国性的网络运维管理项目;
·实践项目:开源社区技术推广、实现SNMP协议栈、研究去中心化大规模集群技术。
————————————————
版权声明:本文为CSDN博主「uyunopss」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/uyunopss/article/details/53183660

 浙公网安备 33010602011771号
浙公网安备 33010602011771号