Select for update使用详解 InnoDB Locking
实践:
1、
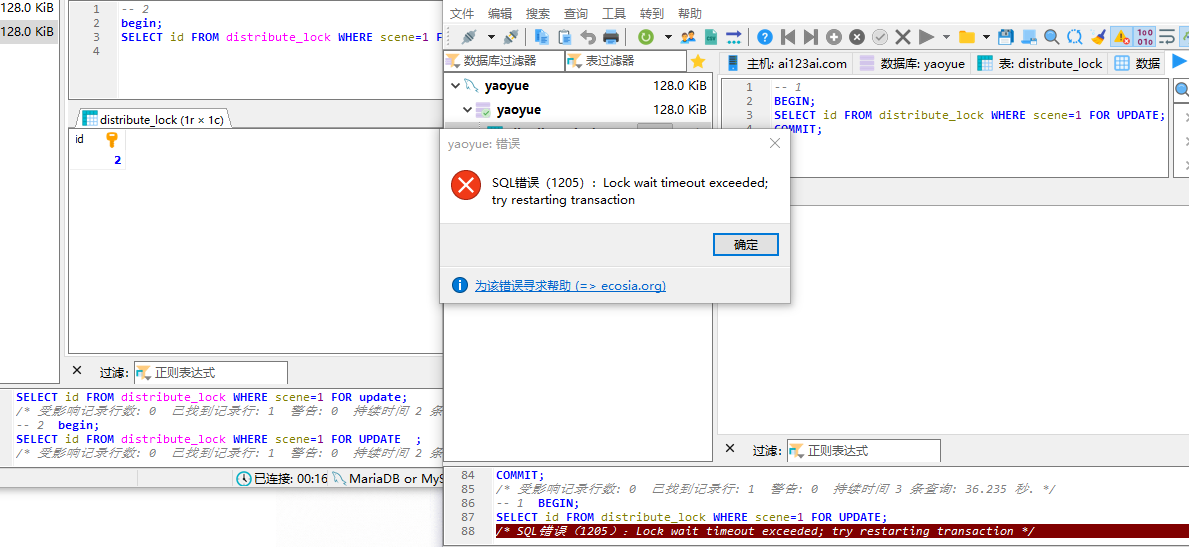
开启事务1,不提交,事务2,无法查询;
应用:分布式锁。
SHOW VARIABLES LIKE "%transaction%";
transaction_isolation REPEATABLE-READ
Locking reads are only possible when autocommit is disabled (either by beginning transaction with START TRANSACTION or by setting autocommit to 0.
MySQL :: MySQL 8.0 Reference Manual :: 15.7.2.4 Locking Reads https://dev.mysql.com/doc/refman/8.0/en/innodb-locking-reads.html
在开启事务、或autocommit为0时成立:养成显示开启事务的习惯。
更多例子:
MySQL :: MySQL 8.0 Reference Manual :: 15.7.2.4 Locking Reads https://dev.mysql.com/doc/refman/8.0/en/innodb-locking-reads.html
Select for update使用详解 - 知乎 https://zhuanlan.zhihu.com/p/143866444
前言
近期开发与钱相关的项目,在高并发场景下对数据的准确行有很高的要求,用到了for update,故总结一波以便日后留恋。
for update的使用场景
如果遇到存在高并发并且对于数据的准确性很有要求的场景,是需要了解和使用for update的。
比如涉及到金钱、库存等。一般这些操作都是很长一串并且是开启事务的。如果库存刚开始读的时候是1,而立马另一个进程进行了update将库存更新为0了,而事务还没有结束,会将错的数据一直执行下去,就会有问题。所以需要for upate 进行数据加锁防止高并发时候数据出错。
记住一个原则:一锁二判三更新
排他锁的申请前提
没有线程对该结果集中的任何行数据使用排他锁或共享锁,否则申请会阻塞。
for update仅适用于InnoDB,且必须在事务块(BEGIN/COMMIT)中才能生效。在进行事务操作时,通过“for update”语句,MySQL会对查询结果集中每行数据都添加排他锁,其他线程对该记录的更新与删除操作都会阻塞。排他锁包含行锁、表锁。
场景分析
假设有一张商品表 goods,它包含 id,商品名称,库存量三个字段,表结构如下:
CREATE TABLE `goods` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(100) DEFAULT NULL,
`stock` int(11) DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `idx_name` (`name`) USING HASH
) ENGINE=InnoDB
插入如下数据:
INSERT INTO `goods` VALUES ('1', 'prod11', '1000');
INSERT INTO `goods` VALUES ('2', 'prod12', '1000');
INSERT INTO `goods` VALUES ('3', 'prod13', '1000');
INSERT INTO `goods` VALUES ('4', 'prod14', '1000');
INSERT INTO `goods` VALUES ('5', 'prod15', '1000');
INSERT INTO `goods` VALUES ('6', 'prod16', '1000');
INSERT INTO `goods` VALUES ('7', 'prod17', '1000');
INSERT INTO `goods` VALUES ('8', 'prod18', '1000');
INSERT INTO `goods` VALUES ('9', 'prod19', '1000');
一、数据一致性
假设有A、B两个用户同时各购买一件 id=1 的商品,用户A获取到的库存量为 1000,用户B获取到的库存量也为 1000,用户A完成购买后修改该商品的库存量为 999,用户B完成购买后修改该商品的库存量为 999,此时库存量数据产生了不一致。
有两种解决方案:
悲观锁方案:每次获取商品时,对该商品加排他锁。也就是在用户A获取获取 id=1 的商品信息时对该行记录加锁,期间其他用户阻塞等待访问该记录。悲观锁适合写入频繁的场景。
begin;
select * from goods where id = 1 for update;
update goods set stock = stock - 1 where id = 1;
commit;
乐观锁方案:每次获取商品时,不对该商品加锁。在更新数据的时候需要比较程序中的库存量与数据库中的库存量是否相等,如果相等则进行更新,反之程序重新获取库存量,再次进行比较,直到两个库存量的数值相等才进行数据更新。乐观锁适合读取频繁的场景。
#不加锁获取 id=1 的商品对象
select * from goods where id = 1
begin;
#更新 stock 值,这里需要注意 where 条件 “stock = cur_stock”,只有程序中获取到的库存量与数据库中的库存量相等才执行更新
update goods set stock = stock - 1 where id = 1 and stock = cur_stock;
commit;
如果我们需要设计一个商城系统,该选择以上的哪种方案呢?
查询商品的频率比下单支付的频次高,基于以上我可能会优先考虑第二种方案(当然还有其他的方案,这里只考虑以上两种方案)。
二、行锁与表锁
InnoDB默认是行级别的锁,当有明确指定的主键时候,是行级锁。否则是表级别。
#for update的注意点
for update 仅适用于InnoDB,并且必须开启事务,在begin与commit之间才生效。
要测试for update的锁表情况,可以利用MySQL的Command Mode,开启二个视窗来做测试。
1、只根据主键进行查询,并且查询到数据,主键字段产生行锁。
begin;
select * from goods where id = 1 for update;
commit;
2、只根据主键进行查询,没有查询到数据,不产生锁。
begin;
select * from goods where id = 1 for update;
commit;
3、根据主键、非主键含索引(name)进行查询,并且查询到数据,主键字段产生行锁,name字段产生行锁。
begin;
select * from goods where id = 1 and name='prod11' for update;
commit;
4、根据主键、非主键含索引(name)进行查询,没有查询到数据,不产生锁。
begin;
select * from goods where id = 1 and name='prod12' for update;
commit;
5、根据主键、非主键不含索引(name)进行查询,并且查询到数据,如果其他线程按主键字段进行再次查询,则主键字段产生行锁,如果其他线程按非主键不含索引字段进行查询,则非主键不含索引字段产生表锁,如果其他线程按非主键含索引字段进行查询,则非主键含索引字段产生行锁,如果索引值是枚举类型,mysql也会进行表锁,这段话有点拗口,大家仔细理解一下。
begin;
select * from goods where id = 1 and name='prod11' for update;
commit;
6、根据主键、非主键不含索引(name)进行查询,没有查询到数据,不产生锁。
begin;
select * from goods where id = 1 and name='prod12' for update;
commit;
7、根据非主键含索引(name)进行查询,并且查询到数据,name字段产生行锁。
begin;
select * from goods where name='prod11' for update;
commit;
8、根据非主键含索引(name)进行查询,没有查询到数据,不产生锁。
begin;
select * from goods where name='prod11' for update;
commit;
9、根据非主键不含索引(stock)进行查询,并且查询到数据,stock字段产生表锁。
begin;
select * from goods where stock='1000' for update;
commit;
10、根据非主键不含索引(stock)进行查询,没有查询到数据,stock字段产生表锁。
begin;
select * from goods where stock='2000' for update;
commit;
11、只根据主键进行查询,查询条件为不等于,并且查询到数据,主键字段产生表锁。
begin;
select * from goods where id <> 1 for update;
commit;
12、只根据主键进行查询,查询条件为不等于,没有查询到数据,主键字段产生表锁。
begin;
select * from goods where id <> 1 for update;
commit;
13、只根据主键进行查询,查询条件为 like,并且查询到数据,主键字段产生表锁。
begin;
select * from goods where id like '1' for update;
commit;
14、只根据主键进行查询,查询条件为 like,没有查询到数据,主键字段产生表锁。
begin;
select * from goods where id like '1' for update;
commit;
测试环境
数据库版本:5.1.48-community
数据库引擎:InnoDB Supports transactions, row-level locking, and foreign keys
数据库隔离策略:REPEATABLE-READ(系统、会话)
总结
1、InnoDB行锁是通过给索引上的索引项加锁来实现的,只有通过索引条件检索数据,InnoDB才使用行级锁,否则,InnoDB将使用表锁。
2、由于MySQL的行锁是针对索引加的锁,不是针对记录加的锁,所以虽然是访问不同行的记录,但是如果是使用相同的索引键,是会出现锁冲突的。应用设计的时候要注意这一点。
3、当表有多个索引的时候,不同的事务可以使用不同的索引锁定不同的行,另外,不论是使用主键索引、唯一索引或普通索引,InnoDB都会使用行锁来对数据加锁。
4、即便在条件中使用了索引字段,但是否使用索引来检索数据是由MySQL通过判断不同执行计划的代价来决定的,如果MySQL认为全表扫描效率更高,比如对一些很小的表,它就不会使用索引,这种情况下InnoDB将使用表锁,而不是行锁。因此,在分析锁冲突时,别忘了检查SQL的执行计划,以确认是否真正使用了索引。
5、检索值的数据类型与索引字段不同,虽然MySQL能够进行数据类型转换,但却不会使用索引,从而导致InnoDB使用表锁。通过用explain检查两条SQL的执行计划,我们可以清楚地看到了这一点。
MySQL :: MySQL 8.0 Reference Manual :: 15.7.1 InnoDB Locking https://dev.mysql.com/doc/refman/8.0/en/innodb-locking.html
This section describes lock types used by InnoDB.
InnoDB implements standard row-level locking where there are two types of locks, shared (S) locks and exclusive (X) locks.
-
A shared (
S) lock permits the transaction that holds the lock to read a row. -
An exclusive (
X) lock permits the transaction that holds the lock to update or delete a row.
If transaction T1 holds a shared (S) lock on row r, then requests from some distinct transaction T2 for a lock on row r are handled as follows:
-
A request by
T2for anSlock can be granted immediately. As a result, bothT1andT2hold anSlock onr. -
A request by
T2for anXlock cannot be granted immediately.
If a transaction T1 holds an exclusive (X) lock on row r, a request from some distinct transaction T2 for a lock of either type on r cannot be granted immediately. Instead, transaction T2 has to wait for transaction T1 to release its lock on row r.
InnoDB supports multiple granularity locking which permits coexistence of row locks and table locks. For example, a statement such as LOCK TABLES ... WRITE takes an exclusive lock (an X lock) on the specified table. To make locking at multiple granularity levels practical, InnoDB uses intention locks. Intention locks are table-level locks that indicate which type of lock (shared or exclusive) a transaction requires later for a row in a table. There are two types of intention locks:
-
An intention shared lock (
IS) indicates that a transaction intends to set a shared lock on individual rows in a table. -
An intention exclusive lock (
IX) indicates that a transaction intends to set an exclusive lock on individual rows in a table.
For example, SELECT ... FOR SHARE sets an IS lock, and SELECT ... FOR UPDATE sets an IX lock.
The intention locking protocol is as follows:
-
Before a transaction can acquire a shared lock on a row in a table, it must first acquire an
ISlock or stronger on the table. -
Before a transaction can acquire an exclusive lock on a row in a table, it must first acquire an
IXlock on the table.
Table-level lock type compatibility is summarized in the following matrix.
X | IX | S | IS | |
|---|---|---|---|---|
X |
Conflict | Conflict | Conflict | Conflict |
IX |
Conflict | Compatible | Conflict | Compatible |
S |
Conflict | Conflict | Compatible | Compatible |
IS |
Conflict | Compatible | Compatible | Compatible |
A lock is granted to a requesting transaction if it is compatible with existing locks, but not if it conflicts with existing locks. A transaction waits until the conflicting existing lock is released. If a lock request conflicts with an existing lock and cannot be granted because it would cause deadlock, an error occurs.
Intention locks do not block anything except full table requests (for example, LOCK TABLES ... WRITE). The main purpose of intention locks is to show that someone is locking a row, or going to lock a row in the table.
Transaction data for an intention lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
TABLE LOCK table `test`.`t` trx id 10080 lock mode IXA record lock is a lock on an index record. For example, SELECT c1 FROM t WHERE c1 = 10 FOR UPDATE; prevents any other transaction from inserting, updating, or deleting rows where the value of t.c1 is 10.
Record locks always lock index records, even if a table is defined with no indexes. For such cases, InnoDB creates a hidden clustered index and uses this index for record locking. See Section 15.6.2.1, “Clustered and Secondary Indexes”.
Transaction data for a record lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10078 lock_mode X locks rec but not gap
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;;A gap lock is a lock on a gap between index records, or a lock on the gap before the first or after the last index record. For example, SELECT c1 FROM t WHERE c1 BETWEEN 10 and 20 FOR UPDATE; prevents other transactions from inserting a value of 15 into column t.c1, whether or not there was already any such value in the column, because the gaps between all existing values in the range are locked.
A gap might span a single index value, multiple index values, or even be empty.
Gap locks are part of the tradeoff between performance and concurrency, and are used in some transaction isolation levels and not others.
Gap locking is not needed for statements that lock rows using a unique index to search for a unique row. (This does not include the case that the search condition includes only some columns of a multiple-column unique index; in that case, gap locking does occur.) For example, if the id column has a unique index, the following statement uses only an index-record lock for the row having id value 100 and it does not matter whether other sessions insert rows in the preceding gap:
SELECT * FROM child WHERE id = 100;If id is not indexed or has a nonunique index, the statement does lock the preceding gap.
It is also worth noting here that conflicting locks can be held on a gap by different transactions. For example, transaction A can hold a shared gap lock (gap S-lock) on a gap while transaction B holds an exclusive gap lock (gap X-lock) on the same gap. The reason conflicting gap locks are allowed is that if a record is purged from an index, the gap locks held on the record by different transactions must be merged.
Gap locks in InnoDB are “purely inhibitive”, which means that their only purpose is to prevent other transactions from inserting to the gap. Gap locks can co-exist. A gap lock taken by one transaction does not prevent another transaction from taking a gap lock on the same gap. There is no difference between shared and exclusive gap locks. They do not conflict with each other, and they perform the same function.
Gap locking can be disabled explicitly. This occurs if you change the transaction isolation level to READ COMMITTED. In this case, gap locking is disabled for searches and index scans and is used only for foreign-key constraint checking and duplicate-key checking.
There are also other effects of using the READ COMMITTED isolation level. Record locks for nonmatching rows are released after MySQL has evaluated the WHERE condition. For UPDATE statements, InnoDB does a “semi-consistent” read, such that it returns the latest committed version to MySQL so that MySQL can determine whether the row matches the WHERE condition of the UPDATE.
A next-key lock is a combination of a record lock on the index record and a gap lock on the gap before the index record.
InnoDB performs row-level locking in such a way that when it searches or scans a table index, it sets shared or exclusive locks on the index records it encounters. Thus, the row-level locks are actually index-record locks. A next-key lock on an index record also affects the “gap” before that index record. That is, a next-key lock is an index-record lock plus a gap lock on the gap preceding the index record. If one session has a shared or exclusive lock on record R in an index, another session cannot insert a new index record in the gap immediately before R in the index order.
Suppose that an index contains the values 10, 11, 13, and 20. The possible next-key locks for this index cover the following intervals, where a round bracket denotes exclusion of the interval endpoint and a square bracket denotes inclusion of the endpoint:
(negative infinity, 10]
(10, 11]
(11, 13]
(13, 20]
(20, positive infinity)For the last interval, the next-key lock locks the gap above the largest value in the index and the “supremum” pseudo-record having a value higher than any value actually in the index. The supremum is not a real index record, so, in effect, this next-key lock locks only the gap following the largest index value.
By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 15.7.4, “Phantom Rows”).
Transaction data for a next-key lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
RECORD LOCKS space id 58 page no 3 n bits 72 index `PRIMARY` of table `test`.`t`
trx id 10080 lock_mode X
Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
0: len 8; hex 73757072656d756d; asc supremum;;
Record lock, heap no 2 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 8000000a; asc ;;
1: len 6; hex 00000000274f; asc 'O;;
2: len 7; hex b60000019d0110; asc ;;An insert intention lock is a type of gap lock set by INSERT operations prior to row insertion. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
The following example demonstrates a transaction taking an insert intention lock prior to obtaining an exclusive lock on the inserted record. The example involves two clients, A and B.
Client A creates a table containing two index records (90 and 102) and then starts a transaction that places an exclusive lock on index records with an ID greater than 100. The exclusive lock includes a gap lock before record 102:
mysql> CREATE TABLE child (id int(11) NOT NULL, PRIMARY KEY(id)) ENGINE=InnoDB;
mysql> INSERT INTO child (id) values (90),(102);
mysql> START TRANSACTION;
mysql> SELECT * FROM child WHERE id > 100 FOR UPDATE;
+-----+
| id |
+-----+
| 102 |
+-----+Client B begins a transaction to insert a record into the gap. The transaction takes an insert intention lock while it waits to obtain an exclusive lock.
mysql> START TRANSACTION;
mysql> INSERT INTO child (id) VALUES (101);Transaction data for an insert intention lock appears similar to the following in SHOW ENGINE INNODB STATUS and InnoDB monitor output:
RECORD LOCKS space id 31 page no 3 n bits 72 index `PRIMARY` of table `test`.`child`
trx id 8731 lock_mode X locks gap before rec insert intention waiting
Record lock, heap no 3 PHYSICAL RECORD: n_fields 3; compact format; info bits 0
0: len 4; hex 80000066; asc f;;
1: len 6; hex 000000002215; asc " ;;
2: len 7; hex 9000000172011c; asc r ;;...An AUTO-INC lock is a special table-level lock taken by transactions inserting into tables with AUTO_INCREMENT columns. In the simplest case, if one transaction is inserting values into the table, any other transactions must wait to do their own inserts into that table, so that rows inserted by the first transaction receive consecutive primary key values.
The innodb_autoinc_lock_mode variable controls the algorithm used for auto-increment locking. It allows you to choose how to trade off between predictable sequences of auto-increment values and maximum concurrency for insert operations.
For more information, see Section 15.6.1.6, “AUTO_INCREMENT Handling in InnoDB”.
InnoDB supports SPATIAL indexing of columns containing spatial data (see Section 11.4.9, “Optimizing Spatial Analysis”).
To handle locking for operations involving SPATIAL indexes, next-key locking does not work well to support REPEATABLE READ or SERIALIZABLE transaction isolation levels. There is no absolute ordering concept in multidimensional data, so it is not clear which is the “next” key.
To enable support of isolation levels for tables with SPATIAL indexes, InnoDB uses predicate locks. A SPATIAL index contains minimum bounding rectangle (MBR) values, so InnoDB enforces consistent read on the index by setting a predicate lock on the MBR value used for a query. Other transactions cannot insert or modify a row that would match the query condition.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号