回归分析 分布最佳的连结函数 岭回归分析 方程的确定性系数
https://baike.baidu.com/item/向前选择法/22667531?fromModule=lemma_inlink
中文名向前选择法
外文名forward selection
所属学科数学
简 介一种回归模型的自变量选择方法
所属问题数理统计
特 点把候选的自变量逐个引入回归方程
相关概念向后选择法,逐步回归法等
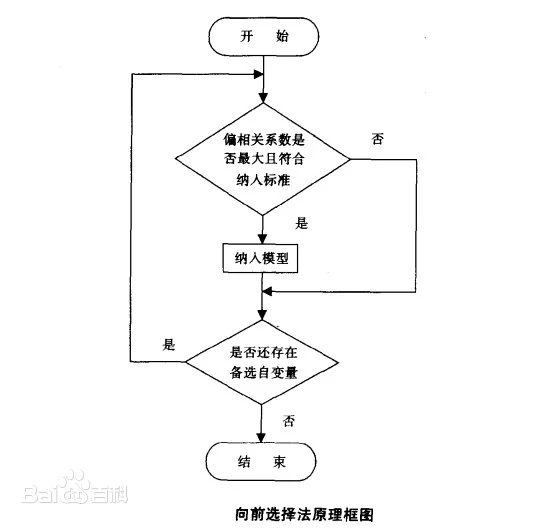
在实际问题中,选择合适的变量来建立回归方程,不是一件很容易的事情。因为影响因变量y的因素很多,而这些因素之间存在着多重共线性,特别是在教育和经济类数据中,各自变量之间有高度的相互依赖性,这样会给回归系数估计值带来不合理的解释。为了得到一个稳健的、可靠的回归模型,这就需要给出一种方法,使得能从众多的影响y的因素中挑选出对y影响大的变量,在它们和y的观测数据基础上建立最优的回归方程。向前选择法与向后剔除法、逐步回归法一样是目前使用较为广泛的在众多因素中筛选对因变量有显著影响的自变量的统计方法。在向前选择法中,与因变量有最大正相关或最大负相关的变量首先进入回归方程,然后按假设H0:“进入回归方程的变量的系数为0”对进入回归方程的变量的系数进行F-检验。为了决定变量(及每一个后继变量)是否能进入回归方程,须指定进入回归方程的判别标准。常用的标准有:①F值进入标准FIN:当F统计量值
![]() (临界值,常指定为3.84)时,变量才可能进入回归方程;②F概率进入标准PIN:当F统计量的相伴概率≤PIN(临界概率,常指定为0.05)时,变量才可能进入回归方程。如果第一个被选变量满足F检验条件(即H0被拒绝),则向前选择变量过程继续;否则,选择变量过程结束,回归方程中无任何自变量。一旦有一个自变量进入回归方程,接着考察因变量与不在方程中的每个变量的偏相关系数,具有最大偏相关系数的变量是下一个候选者。如果满足F检验条件,则该变量进入回归方程,且重复上述选择过程。当没有变量满足F检验条件时,选择变量过程终止。此时所得到的回归方程为最优回归方程 [2]。
(临界值,常指定为3.84)时,变量才可能进入回归方程;②F概率进入标准PIN:当F统计量的相伴概率≤PIN(临界概率,常指定为0.05)时,变量才可能进入回归方程。如果第一个被选变量满足F检验条件(即H0被拒绝),则向前选择变量过程继续;否则,选择变量过程结束,回归方程中无任何自变量。一旦有一个自变量进入回归方程,接着考察因变量与不在方程中的每个变量的偏相关系数,具有最大偏相关系数的变量是下一个候选者。如果满足F检验条件,则该变量进入回归方程,且重复上述选择过程。当没有变量满足F检验条件时,选择变量过程终止。此时所得到的回归方程为最优回归方程 [2]。

https://baike.baidu.com/item/回归分析/2625498?fr=ge_ala
在统计学中,回归分析(regression analysis)指的是确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法。回归分析按照涉及的变量的多少,分为一元回归和多元回归分析;按照因变量的多少,可分为简单回归分析和多重回归分析;按照自变量和因变量之间的关系类型,可分为线性回归分析和非线性回归分析。 [1]
适用条件
在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。
适用条件
在大数据分析中,回归分析是一种预测性的建模技术,它研究的是因变量(目标)和自变量(预测器)之间的关系。这种技术通常用于预测分析,时间序列模型以及发现变量之间的因果关系。例如,司机的鲁莽驾驶与道路交通事故数量之间的关系,最好的研究方法就是回归。
应用
1. Linear Regression线性回归
它是最为人熟知的建模技术之一。线性回归通常是人们在学习预测模型时首选的技术之一。在这种技术中,因变量是连续的,自变量可以是连续的也可以是离散的,回归线的性质是线性的。
线性回归使用最佳的拟合直线(也就是回归线)在因变量(Y)和一个或多个自变量(X)之间建立一种关系。
多元线性回归可表示为Y=a+b1*X +b2*X2+ e,其中a表示截距,b表示直线的斜率,e是误差项。多元线性回归可以根据给定的预测变量(s)来预测目标变量的值。
2.Logistic Regression逻辑回归
逻辑回归是用来计算“事件=Success”和“事件=Failure”的概率。当因变量的类型属于二元(1 / 0,真/假,是/否)变量时,应该使用逻辑回归。这里,Y的值为0或1,它可以用下方程表示。
odds= p/ (1-p) = probability of event occurrence / probability of not event occurrence
ln(odds) = ln(p/(1-p))
logit(p) = ln(p/(1-p)) =b0+b1X1+b2X2+b3X3....+bkXk
上述式子中,p表述具有某个特征的概率。你应该会问这样一个问题:“为什么要在公式中使用对数log呢?”。
因为在这里使用的是的二项分布(因变量),需要选择一个对于这个分布最佳的连结函数。它就是Logit函数。在上述方程中,通过观测样本的极大似然估计值来选择参数,而不是最小化平方和误差(如在普通回归使用的)。
3. Polynomial Regression多项式回归
对于一个回归方程,如果自变量的指数大于1,那么它就是多项式回归方程。如下方程所示:
y=a+b*x^2
在这种回归技术中,最佳拟合线不是直线。而是一个用于拟合数据点的曲线。
4. Stepwise Regression逐步回归
在处理多个自变量时,可以使用这种形式的回归。在这种技术中,自变量的选择是在一个自动的过程中完成的,其中包括非人为操作。
这一壮举是通过观察统计的值,如R-square,t-stats和AIC指标,来识别重要的变量。逐步回归通过同时添加/删除基于指定标准的协变量来拟合模型。下面列出了一些最常用的逐步回归方法:
标准逐步回归法做两件事情。即增加和删除每个步骤所需的预测。
向前选择法从模型中最显著的预测开始,然后为每一步添加变量。
向后剔除法与模型的所有预测同时开始,然后在每一步消除最小显著性的变量。
这种建模技术的目的是使用最少的预测变量数来最大化预测能力。这也是处理高维数据集的方法之一。2
5. Ridge Regression岭回归
当数据之间存在多重共线性(自变量高度相关)时,就需要使用岭回归分析。在存在多重共线性时,尽管最小二乘法(OLS)测得的估计值不存在偏差,它们的方差也会很大,从而使得观测值与真实值相差甚远。岭回归通过给回归估计值添加一个偏差值,来降低标准误差。
在线性等式中,预测误差可以划分为 2 个分量,一个是偏差造成的,一个是方差造成的。预测误差可能会由这两者或两者中的任何一个造成。在这里,将讨论由方差所造成的误差。
岭回归通过收缩参数λ(lambda)解决多重共线性问题。请看下面的等式:
L2=argmin||y=xβ||+λ||β||
在这个公式中,有两个组成部分。第一个是最小二乘项,另一个是β-平方的λ倍,其中β是相关系数向量,与收缩参数一起添加到最小二乘项中以得到一个非常低的方差。
6. Lasso Regression套索回归
它类似于岭回归,Lasso (Least Absolute Shrinkage and Selection Operator)也会就回归系数向量给出惩罚值项。此外,它能够减少变化程度并提高线性回归模型的精度。看看下面的公式:
L1=agrmin||y-xβ||
+λ||β||
Lasso 回归与Ridge回归有一点不同,它使用的惩罚函数是L1范数,而不是L2范数。这导致惩罚(或等于约束估计的绝对值之和)值使一些参数估计结果等于零。使用惩罚值越大,进一步估计会使得缩小值越趋近于零。这将导致要从给定的n个变量中选择变量。
如果预测的一组变量是高度相关的,Lasso 会选出其中一个变量并且将其它的收缩为零。
7.ElasticNet回归
ElasticNet是Lasso和Ridge回归技术的混合体。它使用L1来训练并且L2优先作为正则化矩阵。当有多个相关的特征时,ElasticNet是很有用的。Lasso 会随机挑选他们其中的一个,而ElasticNet则会选择两个。
Lasso和Ridge之间的实际的优点是,它允许ElasticNet继承循环状态下Ridge的一些稳定性。
数据探索是构建预测模型的必然组成部分。在选择合适的模型时,比如识别变量的关系和影响时,它应该是首选的一步。比较适合于不同模型的优点,可以分析不同的指标参数,如统计意义的参数,R-square,Adjusted R-square,AIC,BIC以及误差项,另一个是Mallows’ Cp准则。这个主要是通过将模型与所有可能的子模型进行对比(或谨慎选择他们),检查在你的模型中可能出现的偏差。
交叉验证是评估预测模型最好的方法。在这里,将你的数据集分成两份(一份做训练和一份做验证)。使用观测值和预测值之间的一个简单均方差来衡量你的预测精度。
如果你的数据集是多个混合变量,那么你就不应该选择自动模型选择方法,因为你应该不想在同一时间把所有变量放在同一个模型中。
它也将取决于你的目的。可能会出现这样的情况,一个不太强大的模型与具有高度统计学意义的模型相比,更易于实现。回归正则化方法(Lasso,Ridge和ElasticNet)在高维和数据集变量之间多重共线性情况下运行良好。3
假定条件与内容
在数据分析中一般要对数据进行一些条件假定:
方差齐性
线性关系
效应累加
变量无测量误差
变量服从多元正态分布
观察独立
模型完整(没有包含不该进入的变量、也没有漏掉应该进入的变量)
误差项独立且服从(0,1)正态分布。
现实数据常常不能完全符合上述假定。因此,统计学家研究出许多的回归模型来解决线性回归模型假定过程的约束。
回归分析的主要内容为:
①从一组数据出发,确定某些变量之间的定量关系式,即建立数学模型并估计其中的未知参数。估计参数的常用方法是最小二乘法。
②对这些关系式的可信程度进行检验。
③在许多自变量共同影响着一个因变量的关系中,判断哪个(或哪些)自变量的影响是显著的,哪些自变量的影响是不显著的,将影响显著的自变量加入模型中,而剔除影响不显著的变量,通常用逐步回归、向前回归和向后回归等方法。
④利用所求的关系式对某一生产过程进行预测或控制。回归分析的应用是非常广泛的,统计软件包使各种回归方法计算十分方便。
在回归分析中,把变量分为两类。一类是因变量,它们通常是实际问题中所关心的一类指标,通常用Y表示;而影响因变量取值的的另一类变量称为自变量,用X来表示。
回归分析研究的主要问题是:
(1)确定Y与X间的定量关系表达式,这种表达式称为回归方程;
(2)对求得的回归方程的可信度进行检验;
(3)判断自变量X对因变量Y有无影响;
(4)利用所求得的回归方程进行预测和控制。4
应用
相关分析研究的是现象之间是否相关、相关的方向和密切程度,一般不区别自变量或因变量。而回归分析则要分析现象之间相关的具体形式,确定其因果关系,并用数学模型来表现其具体关系。比如说,从相关分析中可以得知“质量”和“用户满意度”变量密切相关,但是这两个变量之间到底是哪个变量受哪个变量的影响,影响程度如何,则需要通过回归分析方法来确定。1
一般来说,回归分析是通过规定因变量和自变量来确定变量之间的因果关系,建立回归模型,并根据实测数据来求解模型的各个参数,然后评价回归模型是否能够很好的拟合实测数据;如果能够很好的拟合,则可以根据自变量作进一步预测。
例如,如果要研究质量和用户满意度之间的因果关系,从实践意义上讲,产品质量会影响用户的满意情况,因此设用户满意度为因变量,记为Y;质量为自变量,记为X。通常可以建立下面的线性关系: Y=A+BX+§
式中:A和B为待定参数,A为回归直线的截距;B为回归直线的斜率,表示X变化一个单位时,Y的平均变化情况;§为依赖于用户满意度的随机误差项。
对于经验回归方程: y=0.857+0.836x
回归直线在y轴上的截距为0.857、斜率0.836,即质量每提高一分,用户满意度平均上升0.836分;或者说质量每提高1分对用户满意度的贡献是0.836分。
上面所示的例子是简单的一个自变量的线性回归问题,在数据分析的时候,也可以将此推广到多个自变量的多元回归,具体的回归过程和意义请参考相关的统计学书籍。此外,在SPSS的结果输出里,还可以汇报R2,F检验值和T检验值。R2又称为方程的确定性系数(coefficient of determination),表示方程中变量X对Y的解释程度。R2取值在0到1之间,越接近1,表明方程中X对Y的解释能力越强。通常将R2乘以100%来表示回归方程解释Y变化的百分比。F检验是通过方差分析表输出的,通过显著性水平(significance level)检验回归方程的线性关系是否显著。一般来说,显著性水平在0.05以上,均有意义。当F检验通过时,意味着方程中至少有一个回归系数是显著的,但是并不一定所有的回归系数都是显著的,这样就需要通过T检验来验证回归系数的显著性。同样地,T检验可以通过显著性水平或查表来确定。在上面所示的例子中,各参数的意义如下表所示。
线性回归方程检验
|
指标
|
值
|
显著性水平
|
意义
|
|
R2
|
0.89
|
“质量”解释了89%的“用户满意度”的变化程度
|
|
|
F
|
276.82
|
0.001
|
回归方程的线性关系显著
|
|
T
|
16.64
|
0.001
|
回归方程的系数显著
|
示例 SIM手机用户满意度与相关变量线性回归分析
以SIM手机的用户满意度与相关变量的线性回归分析为例,来进一步说明线性回归的应用。从实践意义讲上,手机的用户满意度应该与产品的质量、价格和形象有关,因此以“用户满意度”为因变量,“质量”、“形象”和“价格”为自变量,作线性回归分析。利用SPSS软件的回归分析,得到回归方程如下:
用户满意度=0.008×形象+0.645×质量+0.221×价格
对于SIM手机来说,质量对其用户满意度的贡献比较大,质量每提高1分,用户满意度将提高0.645分;其次是价格,用户对价格的评价每提高1分,其满意度将提高0.221分;而形象对产品用户满意度的贡献相对较小,形象每提高1分,用户满意度仅提高0.008分。
方程各检验指标及含义如下:
|
指标
|
显著性水平
|
意义
|
|
|
R2
|
0.89
|
89%的用户满意度”的变化程度
|
|
|
F
|
248.53
|
0.001
|
回归方程的线性关系显著
|
|
T(形象)
|
0.00
|
1.000
|
“形象”变量对回归方程几乎没有贡献
|
|
T(质量)
|
13.93
|
0.001
|
“质量”对回归方程有很大贡献
|
|
T(价格)
|
5.00
|
0.001
|
“价格”对回归方程有很大贡献
|
从方程的检验指标来看,“形象”对整个回归方程的贡献不大,应予以删除。所以重新做“用户满意度”与“质量”、“价格”的回归方程如下:满意度=0.645×质量+0.221×价格
用户对价格的评价每提高1分,其满意度将提高0.221分(在本示例中,因为“形象”对方程几乎没有贡献,所以得到的方程与前面的回归方程系数差不多)。
方程各检验指标及含义如下:
|
指标
|
显著性水平
|
意义
|
|
|
R2
|
0.89
|
89%的用户满意度”的变化程度
|
|
|
F
|
374.69
|
0.001
|
回归方程的线性关系显著
|
|
T(质量)
|
15.15
|
0.001
|
“质量”对回归方程有很大贡献
|
|
T(价格)
|
5.06
|
0.001
|
“价格”对回归方程有很大贡献
|
步骤确定变量
明确预测的具体目标,也就确定了因变量。如预测具体目标是下一年度的销售量,那么销售量Y就是因变量。通过市场调查和查阅资料,寻找与预测目标的相关影响因素,即自变量,并从中选出主要的影响因素。
建立预测模型
依据自变量和因变量的历史统计资料进行计算,在此基础上建立回归分析方程,即回归分析预测模型。
进行相关分析
回归分析是对具有因果关系的影响因素(自变量)和预测对象(因变量)所进行的数理统计分析处理。只有当自变量与因变量确实存在某种关系时,建立的回归方程才有意义。因此,作为自变量的因素与作为因变量的预测对象是否有关,相关程度如何,以及判断这种相关程度的把握性多大,就成为进行回归分析必须要解决的问题。进行相关分析,一般要求出相关关系,以相关系数的大小来判断自变量和因变量的相关的程度。
计算预测误差
回归预测模型是否可用于实际预测,取决于对回归预测模型的检验和对预测误差的计算。回归方程只有通过各种检验,且预测误差较小,才能将回归方程作为预测模型进行预测。
确定预测值
利用回归预测模型计算预测值,并对预测值进行综合分析,确定最后的预测值。
注意问题
应用回归预测法时应首先确定变量之间是否存在相关关系。如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果。
正确应用回归分析预测时应注意:
①用定性分析判断现象之间的依存关系;
②避免回归预测的任意外推;
③应用合适的数据资料;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号