map数据结构
Go map实现原理 - 恋恋美食的个人空间 - OSCHINA - 中文开源技术交流社区 https://my.oschina.net/renhc/blog/2208417
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
count int // # live cells == size of map. Must be first (used by len() builtin)
flags uint8
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
hash0 uint32 // hash seed
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
extra *mapextra // optional fields
}
Golang的map使用哈希表作为底层实现,一个哈希表里可以有多个哈希表节点,也即bucket,而每个bucket就保存了map中的一个或一组键值对。
map数据结构由runtime/map.go:hmap定义:
type hmapstruct{
countint// 当前保存的元素个数
... B uint8 ...bucketsunsafe.Pointer// bucket数组指针,数组的大小为2^B
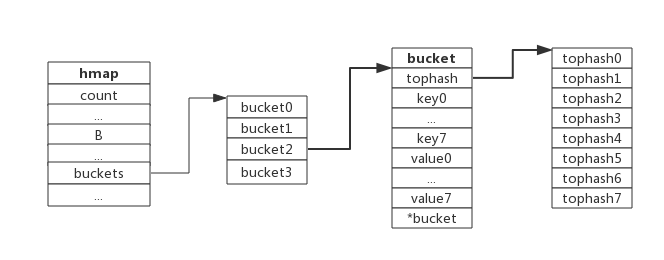
...}下图展示一个拥有4个bucket的map:

本例中, hmap.B=2, 而hmap.buckets长度是2^B为4. 元素经过哈希运算后会落到某个bucket中进行存储。查找过程类似。
bucket很多时候被翻译为桶,所谓的哈希桶实际上就是bucket。
2. bucket数据结构
bucket数据结构由runtime/map.go:bmap定义:
type bmapstruct{
tophash [8]uint8//存储哈希值的高8位
databyte[1]//key value数据:key/key/key/.../value/value/value...
overflow *bmap//溢出bucket的地址
}每个bucket可以存储8个键值对。
- tophash是个长度为8的数组,哈希值相同的键(准确的说是哈希值低位相同的键)存入当前bucket时会将哈希值的高位存储在该数组中,以方便后续匹配。
- data区存放的是key-value数据,存放顺序是key/key/key/…value/value/value,如此存放是为了节省字节对齐带来的空间浪费。
- overflow 指针指向的是下一个bucket,据此将所有冲突的键连接起来。
注意:上述中data和overflow并不是在结构体中显示定义的,而是直接通过指针运算进行访问的。
下图展示bucket存放8个key-value对:
package runtime
// This file contains the implementation of Go's map type.
//
// A map is just a hash table. The data is arranged
// into an array of buckets. Each bucket contains up to
// 8 key/elem pairs. The low-order bits of the hash are
// used to select a bucket. Each bucket contains a few
// high-order bits of each hash to distinguish the entries
// within a single bucket.
//
// If more than 8 keys hash to a bucket, we chain on
// extra buckets.
//
// When the hashtable grows, we allocate a new array
// of buckets twice as big. Buckets are incrementally
// copied from the old bucket array to the new bucket array.
//
// Map iterators walk through the array of buckets and
// return the keys in walk order (bucket #, then overflow
// chain order, then bucket index). To maintain iteration
// semantics, we never move keys within their bucket (if
// we did, keys might be returned 0 or 2 times). When
// growing the table, iterators remain iterating through the
// old table and must check the new table if the bucket
// they are iterating through has been moved ("evacuated")
// to the new table.
// Picking loadFactor: too large and we have lots of overflow
// buckets, too small and we waste a lot of space. I wrote
// a simple program to check some stats for different loads:
// (64-bit, 8 byte keys and elems)
// loadFactor %overflow bytes/entry hitprobe missprobe
// 4.00 2.13 20.77 3.00 4.00
// 4.50 4.05 17.30 3.25 4.50
// 5.00 6.85 14.77 3.50 5.00
// 5.50 10.55 12.94 3.75 5.50
// 6.00 15.27 11.67 4.00 6.00
// 6.50 20.90 10.79 4.25 6.50
// 7.00 27.14 10.15 4.50 7.00
// 7.50 34.03 9.73 4.75 7.50
// 8.00 41.10 9.40 5.00 8.00
//
// %overflow = percentage of buckets which have an overflow bucket
// bytes/entry = overhead bytes used per key/elem pair
// hitprobe = # of entries to check when looking up a present key
// missprobe = # of entries to check when looking up an absent key
//
// Keep in mind this data is for maximally loaded tables, i.e. just
// before the table grows. Typical tables will be somewhat less loaded.
import (
"runtime/internal/atomic"
"runtime/internal/math"
"runtime/internal/sys"
"unsafe"
)
const (
// Maximum number of key/elem pairs a bucket can hold.
bucketCntBits = 3
bucketCnt = 1 << bucketCntBits
// Maximum average load of a bucket that triggers growth is 6.5.
// Represent as loadFactorNum/loadFactorDen, to allow integer math.
loadFactorNum = 13
loadFactorDen = 2
// Maximum key or elem size to keep inline (instead of mallocing per element).
// Must fit in a uint8.
// Fast versions cannot handle big elems - the cutoff size for
// fast versions in cmd/compile/internal/gc/walk.go must be at most this elem.
maxKeySize = 128
maxElemSize = 128
// data offset should be the size of the bmap struct, but needs to be
// aligned correctly. For amd64p32 this means 64-bit alignment
// even though pointers are 32 bit.
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
// Possible tophash values. We reserve a few possibilities for special marks.
// Each bucket (including its overflow buckets, if any) will have either all or none of its
// entries in the evacuated* states (except during the evacuate() method, which only happens
// during map writes and thus no one else can observe the map during that time).
emptyRest = 0 // this cell is empty, and there are no more non-empty cells at higher indexes or overflows.
emptyOne = 1 // this cell is empty
evacuatedX = 2 // key/elem is valid. Entry has been evacuated to first half of larger table.
evacuatedY = 3 // same as above, but evacuated to second half of larger table.
evacuatedEmpty = 4 // cell is empty, bucket is evacuated.
minTopHash = 5 // minimum tophash for a normal filled cell.
// flags
iterator = 1 // there may be an iterator using buckets
oldIterator = 2 // there may be an iterator using oldbuckets
hashWriting = 4 // a goroutine is writing to the map
sameSizeGrow = 8 // the current map growth is to a new map of the same size
// sentinel bucket ID for iterator checks
noCheck = 1<<(8*sys.PtrSize) - 1
)
3. 哈希冲突
当有两个或以上数量的键被哈希到了同一个bucket时,我们称这些键发生了冲突。Go使用链地址法来解决键冲突。
由于每个bucket可以存放8个键值对,所以同一个bucket存放超过8个键值对时就会再创建一个键值对,用类似链表的方式将bucket连接起来。
下图展示产生冲突后的map:
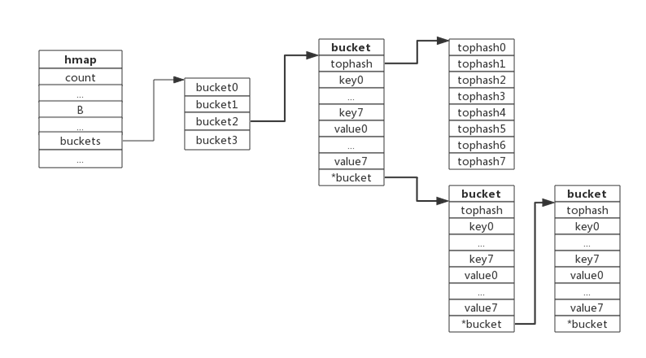
bucket数据结构指示下一个bucket的指针称为overflow bucket,意为当前bucket盛不下而溢出的部分。事实上哈希冲突并不是好事情,它降低了存取效率,好的哈希算法可以保证哈希值的随机性,但冲突过多也是要控制的,后面会再详细介绍。
4. 负载因子
负载因子用于衡量一个哈希表冲突情况,公式为:
负载因子 = 键数量/bucket数量例如,对于一个bucket数量为4,包含4个键值对的哈希表来说,这个哈希表的负载因子为1.
哈希表需要将负载因子控制在合适的大小,超过其阀值需要进行rehash,也即键值对重新组织:
- 哈希因子过小,说明空间利用率低
- 哈希因子过大,说明冲突严重,存取效率低
每个哈希表的实现对负载因子容忍程度不同,比如Redis实现中负载因子大于1时就会触发rehash,而Go则在在负载因子达到6.5时才会触发rehash,因为Redis的每个bucket只能存1个键值对,而Go的bucket可能存8个键值对,所以Go可以容忍更高的负载因子。
5. 渐进式扩容
5.1 扩容的前提条件
为了保证访问效率,当新元素将要添加进map时,都会检查是否需要扩容,扩容实际上是以空间换时间的手段。
触发扩容的条件有二个:
1. 负载因子 > 6.5时,也即平均每个bucket存储的键值对达到6.5个。
2. overflow数量 > 2^15时,也即overflow数量超过32768时。
5.2 增量扩容
当负载因子过大时,就新建一个bucket,新的bucket长度是原来的2倍,然后旧bucket数据搬迁到新的bucket。
考虑到如果map存储了数以亿计的key-value,一次性搬迁将会造成比较大的延时,Go采用逐步搬迁策略,即每次访问map时都会触发一次搬迁,每次搬迁2个键值对。
下图展示了包含一个bucket满载的map(为了描述方便,图中bucket省略了value区域):

当前map存储了7个键值对,只有1个bucket。此地负载因子为7。再次插入数据时将会触发扩容操作,扩容之后再将新插入键写入新的bucket。
当第8个键值对插入时,将会触发扩容,扩容后示意图如下:
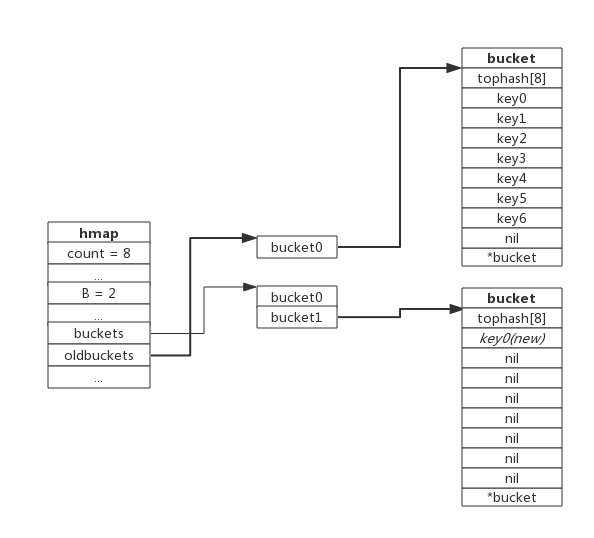
hmap数据结构中oldbuckets成员指身原bucket,而buckets指向了新申请的bucket。新的键值对被插入新的bucket中。
后续对map的访问操作会触发迁移,将oldbuckets中的键值对逐步的搬迁过来。当oldbuckets中的键值对全部搬迁完毕后,删除oldbuckets。
搬迁完成后的示意图如下:

数据搬迁过程中原bucket中的键值对将存在于新bucket的前面,新插入的键值对将存在于新bucket的后面。
实际搬迁过程中比较复杂,将在后续源码分析中详细介绍。
5.3 等量扩容
所谓等量扩容,实际上并不是扩大容量,buckets数量不变,重新做一遍类似增量扩容的搬迁动作,把松散的键值对重新排列一次,以使bucket的使用率更高,进而保证更快的存取。
在极端场景下,比如不断地增删,而键值对正好集中在一小部分的bucket,这样会造成overflow的bucket数量增多,但负载因子又不高,从而无法执行增量搬迁的情况,如下图所示:

上图可见,overflow的bucket中大部分是空的,访问效率会很差。此时进行一次等量扩容,即buckets数量不变,经过重新组织后overflow的bucket数量会减少,即节省了空间又会提高访问效率。
6. 查找过程
查找过程如下:
1. 根据key值算出哈希值
2. 取哈希值低位与hmap.B取模确定bucket位置
3. 取哈希值高位在tophash数组中查询
4. 如果tophash[i]中存储值也哈希值相等,则去找到该bucket中的key值进行比较
5. 当前bucket没有找到,则继续从下个overflow的bucket中查找。
6. 如果当前处于搬迁过程,则优先从oldbuckets查找
注:如果查找不到,也不会返回空值,而是返回相应类型的0值。
7. 插入过程
新元素插入过程如下:
1. 根据key值算出哈希值
2. 取哈希值低位与hmap.B取模确定bucket位置
3. 查找该key是否已经存在,如果存在则直接更新值
4. 如果没找到将key,将key插入

 浙公网安备 33010602011771号
浙公网安备 33010602011771号