
京东评价系统海量数据存储设计
https://mp.weixin.qq.com/s/X5dsgH5JpmETDjw_UEn7ww
京东评价系统海量数据存储设计
作者:韦仕,京东商城交易平台评价社区负责人,2010年加入京东,先后参与了用户、商品、评论等系统的架构升级工作。
京东的商品评论目前已达到数十亿条,每天提供的服务调用也有数十亿次,而这些数据每年还在成倍增长,而数据存储是其中最重要的部分之一,接下来就介绍下京东评论系统的数据存储是如何设计的。
整体数据存储包括基础数据存储、文本存储、数据索引、数据缓存几个部分。
基础数据存储
基础数据存储使用mysql,因用户评论为文本信息,通常包含文字、字符等,占用的存储空间比较大,为此mysql作为基础数据库只存储非文本的评论基础信息,包括评论状态、用户、时间等基础数据,以及图片、标签、点赞等附加数据。而不同的数据又可选择不同的库表拆分方案,参考如下:
-
评论基础数据按用户ID进行拆库并拆表;
-
图片及标签处于同一数据库下,根据商品编号分别进行拆表;
-
其它的扩展信息数据,因数据量不大、访问量不高,处理于同一库下且不做分表即可。
因人而异、因系统而异,根据不同的数据场景选择不同存储方案,有效利用资源的同时还能解决数据存储问题,为高性能、高可用服务打下坚实基础。
文本存储
文本存储使用了mongodb、hbase,选择nosql而非mysql,一是减轻了mysql存储压力,释放msyql,庞大的存储也有了可靠的保障;二是nosql的高性能读写大大提升了系统的吞吐量并降低了延迟。存储的升级过程尝试了cassandra、mongodb等分布式的nosql存储,cassandra适用于写多读少的情况,而 mongodb也是基于分布式文件存储的数据库,介于关系型数据库与非关系型数据库之间,同时也是内存级数据库,mongo写性能不及 cassandra,但读写分离情况下读性能相当不错,因此从应用场景上我们选择了mongodb。mongodb确实不错,也支持了系统稳定运行了好几年。
但从今后的数据增长、业务扩增、应用扩展等多方面考虑,hbase才是最好的选择,它的存储能力、可靠性、可扩展性都是毋庸置疑的。选择了 hbase,只需要根据评论ID构建Rowkey,然后将评论文本信息进行存储,查询时只需要根据ID便能快速读取评论的文本内容,当然也可将评论的其它字段信息进行冗余存储,这样根据评论ID读取评论信息后不用再从mysql进行读取,减少数据操作,提升查询性能。
数据索引
京东的评论是以用户和商品两个维度进行划分的。对于用户而言,用户需要发表评论、上传晒图、查看自己的评论等,因此mysql数据库中只要根据用户ID对评论数据进行拆库拆表进行存储,便能解决用户数据读写问题。而对于商品而言,前台需要将统计商品的评论数并将所有评论展示出来,后台需根据评论的全字段进行检索同时还带模糊查询,而评论数据是按userId进行库表拆分的,现在要按商品去获取评论,显然当前的拆分库是无法实现的。起初考虑过根据商品编号再进行拆库拆表,但经过多层分析后发现行不通,因为再按商品编号进行拆分,得再多加一倍机器,硬件成本非常高,同时要保持用户及商品两维度的分库数据高度一致,不仅增加了系统维护成本及业务复杂度,同时也无法解决评论的数据统计、列表筛选、模糊查询等问题,为此引入了全文检索框架solr(前台)/elasticsearch(后台)进行数据索引。
数据索引其实就是将评论数据构建成索引存储于索引服务中,便于进行评论数据的模糊查询、条件筛选及切面统计等,以弥补以上数据存储无法完成的功能。京东评论系统为此使用了solr/elasticsearch搜索服务,它们都是基于Lucene的全文检索框架,也是分布式的搜索框架(solr4.0后增加了solr cloud以支持分布式),支持数据分片、切面统计、高亮显示、分词检索等功能,利用搜索框架能有效解决前台评论数据统计、列表筛选问题,也能支持后台系统中的关键词显示、多字段检索及模糊查询,可谓是一举多得。
搜索在构建索引时,属性字段可分为存储字段与索引字段,存储字段在创建索引后会将内容存储于索引文档中,同时也会占用相应的索引空间,查询后可返回原始内容,而索引字段创建索引后不占用索引空间也无法返回原始内容,只能用于查询,因此对于较长的内容建议不进行存储索引。
评论搜索在构建索引时,主键评论ID的索引方式设置为存储,其它字段设置为索引,这样不仅减少索引文件的存储空间,也大大提升了索引的构建效率与查询性能。当然,在使用搜索框架时,业务数据量比较小的也可选择将所有字段进行存储,这样在搜索中查询出结果后将不需要从数据库上查询其它信息,也减轻了数据库的压力。
为了更好地应对前后台不同的业务场景,搜索集群被划分为前台搜索集群和后台搜索集群。
前台搜索集群根据商品编号进行索引数据分片,用于解决评论前台的评论数统计、评论列表筛选功能。评论数统计,如果使用常规数据库进行统计时,需要进行sql上的group分组统计,如果只有单个分组统计性能上还能接受,但京东的评论数统计则需要对1到5分的评论分别进行统计,分组增加的同时随着统计量的增加数据库的压力也会增加,因此在mysql上通过group方式进行统计是行不通的。而使用solr的切面统计,只需要一次查询便能轻松地统计出商品每个分级的评论数,而且查询性能也是毫秒级的。切面统计用法如下:
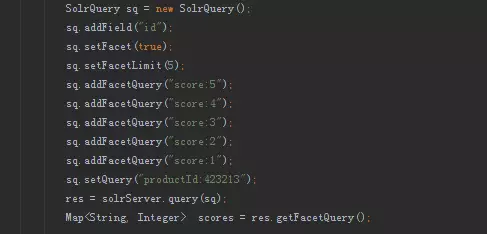
评论列表,只需根据条件从搜索中查询出评论ID集合,再根据评论ID到mysql、Hbase中查询出评论的其它字段信息,经过数据组装后便可返回前台进行展示。
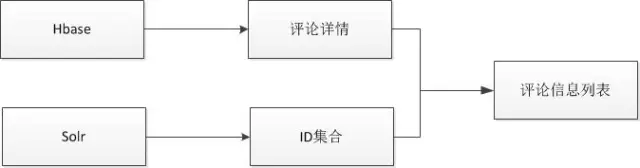
后台搜索集群,评论后台系统需要对评论进行查询,其中包括关键词高亮显示、全字段检索、模糊查询等,为此solr/elasticsearch都是个很好的选择,目前使用elasticsearch。
未来也计划将前台搜索集群切换为elasticsearch。
数据缓存
面对数十亿的数据请求,直接击穿到mysql、搜索服务上都是无法承受的,所以需要对评论数据进行缓存,在此选择了高性能缓存redis,根据不同的业务数据进行集群划分,同时采用多机房主从方式部署解决单点问题,这样只需要对不同的缓存集群进行相应的水平扩展便能快速提升数据吞吐能力,也有效地保证了服务的高性能、高可用。
当然,缓存设计时还有很多细节可以进行巧妙处理的,如:
-
当用户新发表一条评论,要实现前台实时展示,可以将新增的评论数向首屏列表缓存中追加最新的评论信息;
-
评论数是读多写少,这样就可以将评论数持久化到redis当中,只有当数据进行更新时通过异步的方式去将缓存刷新即可;评论数展示可通过nginx+lua的方式提供服务,服务请求无需回源到应用上,不仅提升服务性能,也能减轻应用系统的压力;
-
对于评论列表,通常访问的都是第一屏的数据,也就是第一页的数据,可以将第一页的数据缓存到redis当中,有数据更新时再通过异步程序去更新;
-
对于秒杀类的商品,评论数据可以结合本地缓存提前进行预热,这样当秒杀流量瞬间涌入的时候也不会对缓存集群造成压力;通过减短key长度、去掉多余属性、压缩文本等方式节省内存空间,提高内存使用率。
数据容灾与高可用
引入了这么多的存储方案就是为了解决大数据量存储问题及实现数据服务的高可用,同时合理的部署设计与相应的容灾处理也必须要有的。以上数据存储基本都使用多机房主从方式部署,各机房内部实现主从结构进行数据同步。如图:
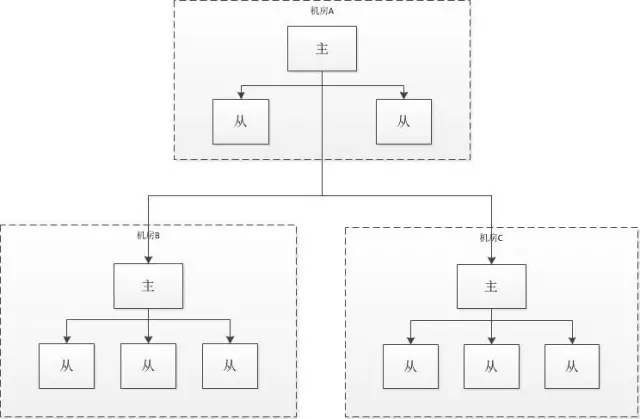
mysql集群数据库拆库后需要对各分库进行多机房主从部署,系统应用进行读写分离并根据机房进行就近调用,当主机房数据库出现故障后将故障机房的数据操作都切换到其它机房,待故障排除后再进行数据同步与流量切换。
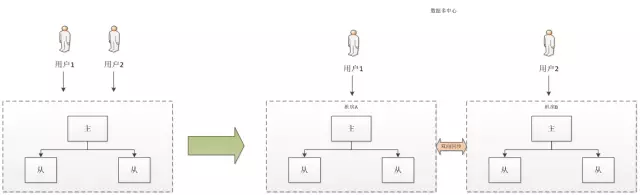
使用主从机房部署的方式所有数据更新操作都要在主库上进行,而当主机房故障是需要通过数据库主从关系的重建、应用重新配置与发布等一系列操作后才能解决流量切换,过程较为复杂且影响面较大,所以这是个单点问题,为此实现数据服务多中心将是我们下一个目标。
多中心根据特定规则将用户分别路由到不同机房进行数据读写,各机房间通过数据总线进行数据同步,当某一机房出现故障,只需要一键操作便能快速地将故障机房的用户流量全部路由到其它机房,实现了数据的多写多活,也进一步实现了服务的高可用。数据多中心如下:
hbase集群目前使用的是京东的公有集群,实现了双机房主备部署,主集群出现故障后自动将流量切换到备用集群,而当hbase整个集群故障时还可对其进行降级,同步只写入缓存及备用存储mongo,待集群恢复后再由后台异步任务将数据回写到hbase当中。
搜索集群根据商品编号进行索引数据分片多机房主从部署,并保证至少3个从节点并部署于多个机房当中,当主节点出现故障后从这些从节点选取其中一个作为新的主提供服务。集群主节点只提供异步任务进行索引更新操作,从节点根据应用机房部署情况提供索引查询服务。
Redis缓存集群主从部署仍是标配,主节点只提供数据的更新操作,从节点提供前台缓存读服务,实现缓存数据的读写分离,提升了缓存服务的处理能力。当主节点出现故障,选取就近机房的一个从节点作为新主节点提供写服务,并将主从关系进行重新构建。任何一从节点出现故障都可通过内部的配置中心进行一键切换,将故障节点的流量切换到其它的从节点上。
总结
整体数据架构并没有什么高大上的设计,而且整体数据架构方案也是为了解决实际痛点和业务问题而演进过来的。数据存储方案上没有最好的,只有最适合的,因此得根据不同的时期、不同的业务场景去选择合适的设计才是最关键的,大家有什么好的方案和建议可以相互讨论与借鉴,系统的稳定、高性能、高可用才是王道。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号