高并发库存秒杀场景,阿里巴巴数据库是这样应对的
https://mp.weixin.qq.com/s/1I0EbuZ4dOi_lzmDW-kdlg
高并发库存秒杀场景,阿里巴巴数据库是这样应对的
简单库存场景的数据库实现
一般来说,从数据库层面讲,库存业务会分为两步,第一步是插入一条记录到扣减明细表inventory_detail,第二步是对库存扣减表inventory的一条记录进行扣减,这两步往往是在一个事务中实现的。
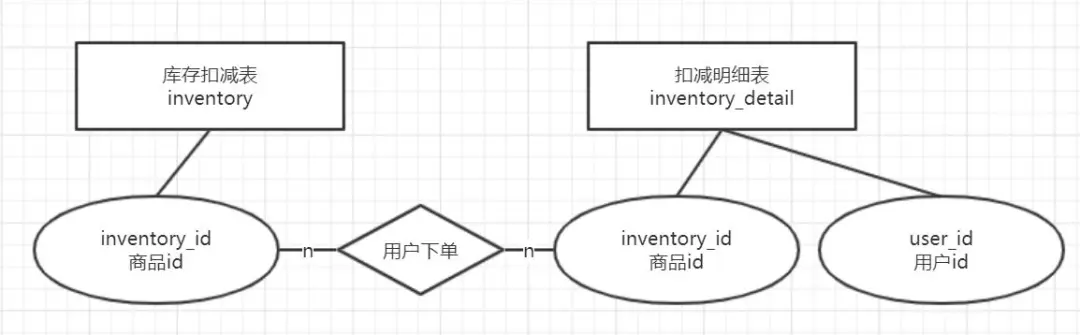
数据库业务架构图如下,所有的请求均发往同一个Database。
从上文的架构图不难看出,所有的商品的库存信息都存在单一的表和库里,当商品种类繁多或者业务并发请求暴涨时,单实例的数据库显然会成为容量或者性能瓶颈。该数据库架构一般只是功能性的实现,主要用于微型库存系统或者测试使用。
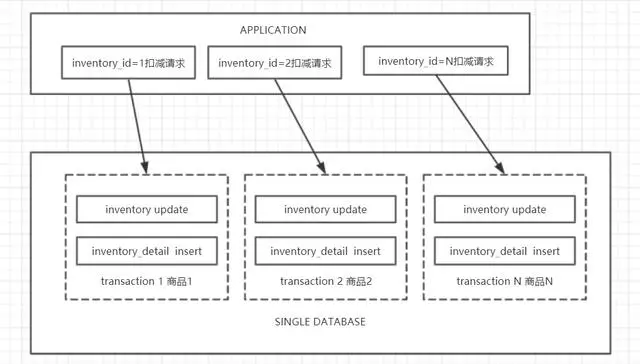
高并发库存系统的数据库实现
为了解决单实例存在的容量和性能上限问题,阿里巴巴所有的库存系统在十年前就实现了分库分表设计,主要通过数据的水平拆分实现不同商品的库存扣减请求路由到不同的数据库。基本数据库架构图如下
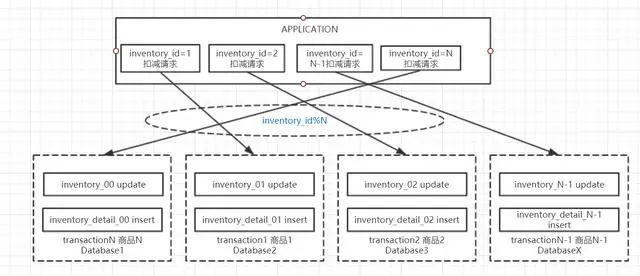
从上图不难看出,库存扣减表和扣减明细表一般都使用商品id作为片键,这样可以保证满足整个系统在高并发扣减请求的同时,同一商品的库存扣减操作和添加明细操作在同一个事务中实现。如果数据分布和业务请求足够均匀,理论上经过分库分表设计后,整个系统的吞吐量将会是线性的增长,主要取决于分实例的数量。
热点行更新
在电商业务中,商家活动比如秒杀不可避免。秒杀活动会给电商库存系统带来巨大的挑战,尤其体现在数据库层面。因为往往一个商品id对应于数据库的一行记录,所以在DB架构上按照商品维度做了分库分表也是无效的。而更新这行记录时必然需要给这行记录加X锁。热点商品的库存扣减本质上就是热点行更新的能力,高并发的同行更新会造成严重的行锁等待现象,从而导致数据库的threads_running和rt飙升,造成雪崩。在当前的官方mysql中,一般单行更新的QPS在500以内,对于热点商品的秒杀需求,这个量往往是不达标的。
阿里巴巴PolarDB-X数据库团队基于以上场景的需求,针对内核优化,引入了先进的水车模型,在识别出热点SQL后,实现了在内核层面优化处理,相比官方MySQL提高了10倍以上的热点行扣减能力,广泛应用于集团电商库存集群,资金平台,权益发放平台等核心数据库集群。
其主要的核心思想是:针对应用层SQL做轻量化改造,带上"热点行SQL"的标签,当这种SQL进入内核后,在内存中维护一个hash表,将主键或唯一键相同的请求(一般也就是同一商品id)hash到同一个地方做请求的合并,经过一段时间后(默认100us)统一提交,从而实现了将串行处理变成了批处理,让每个热点行更新请求并不需要都去扫描和更新btree。
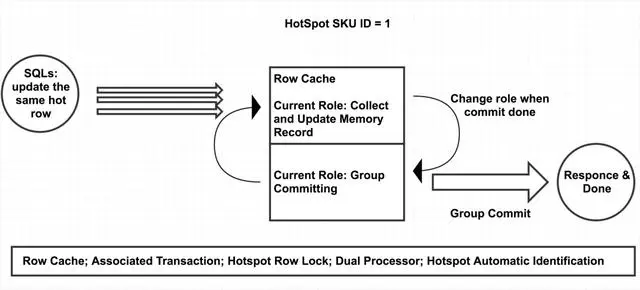
类似原理,阿里云RDS数据库团队同样在内核层面针对热点行更新做了大量的优化,核心思路为引入SQL语句的排队机制,将可能存在行锁冲突的语句放在一个组内排序,从而减少行锁冲突带来的额外系统开销。Statement Queque和Inventory Hint可以结合使用,不过在事务中,热点行更新必须是该事务的最后一条记录,因为commit on success的机制存在,一旦该SQL执行成功就会自动提交或自动回滚。简单的使用范例如下
begin;
insert into inventory_detail(inventory_id,user_id) values(1,1);
update /*+ ccl_queue_value(1) commit_on_success rollback_on_fail target_affect_row(1) */ inventory set inventory_count=inventory_count+1 where inventory_id=1
更多文档参考inventory hint statement queue
业务架构优化
幂等性实现
在库存数据库系统中,一般都会在更新库存记录后,写入一条库存扣减明细的流水记录,用于后续可能存在的查询需求。举个例子,在集团的权益发放平台中,库存流水记录主要用于实现库存扣减的幂等性,即同一个用户只能领取一次权益。在系统的实际运行过程中,可能因为一些网络故障等其他原因,当底层数据库的扣减成功以后并没有成功返回给用户时,用户可能会有重试操作,这时就必须避免库存记录的重复扣减情况。所以针对这些情况,应用在设计时会考虑先查询一遍库存流水记录,如果该用户已经领取过该权益,则不再重复扣减,直接返回。为了实现这种强幂等性的需求,库存扣减和插入流水就必须在同一个事务中,满足同时成功或同时失败。
基于缓存的分桶扣减方案
在更大规模,针对单一商品的超高并发扣减的库存集群中,可能基于数据库内核的改造优化还无法满足业务需求。单一商品的超高并发扣减可能会影响到同一数据库实例上的其他商品扣减,同一个数据库实例上也可能存在多个热点商品造成互相影响,这时就需要考虑在业务和数据库架构上再做一次升级,我们引入基于缓存的分桶扣减方案。
下图为该方案数据库架构图,基于缓存的分桶扣减方案的主要思路为
-
1、普通的非热点商品,或者并发度不够大的热点商品走强幂等性的分库分表+数据库内核改造优化
-
2、超大热点商品,针对该商品再做多key拆分,先走弱幂等性的缓存扣减,缓存扣减后,异步往DB写入一条库存流水记录,后续再做缓存与数据库的库存总量同步

在分桶方案详细落地实现上,需要考虑的细节问题会多很多,比较重要的有以下几点
1、分桶管理
为了更通俗和直观的描述,缓存集群的一个key就对应于于一个"分桶"。要实现一个基于缓存分桶方案的高扩展性的库存系统,分桶的设计至关重要,比如一个热点商品应该对应多少个分桶,分桶的数量能否根据当前的业务变化做到弹性的伸缩
-
1、分桶预分配库存:当分桶初始化后,每个分桶应该保存多少库存量。不一定在预分配库存阶段将该商品的库存数量从DB全部分配到缓存中,可能是一种渐进式的分配策略,DB作为库存总池子
-
2、分桶扩容/缩容:分桶数量的变化,扩缩容操作本质上是调整桶映射管理内的信息,加入或者减少桶,桶信息一旦增加或者减少了,扣减链路会秒级感知到,然后将用户流量引导或者移除出去。从上面的DB架构图可以看出,比较简单的实现方式就是根据当前热点商品的桶数量取模
-
3、桶内库存数量扩容/缩容:即每个分桶内该商品的库存数量变化,扩容场景主要用于当该分桶内库存接近扣减完成时,系统自动去MySQL库存集群总池子里捞一部分过来放进桶内。缩容场景主要场景在于桶下线后将桶内剩余的库存回收到库存总池子中
-
4、合并展示:在基于缓存的分桶设计中,由于同一种热点商品拆分成了多个key,所以在前端界面展示上同样会带来挑战,需要做库存的合并
2、超卖问题
一个较为简单的处理超卖问题的思路是预留一部分库存,当库存数量低于之前定义的预留值时,直接返回前端库存扣减完毕,从而避免造成超卖。
3、碎片问题
在一些类库存系统的设计中,考虑到系统的兼容性和支持的扣减种类,或许扣减的是商品的库存数量,或许是红包的金额(将带小数的红包金额转换成整型数扣减)。所谓碎片问题,举个例子,假如扣减的是红包金额,假设红包金额至少要发1块钱,换算成整型数也就是100,在多个分桶扣减的情况下,最后部分分桶的剩余库存值可能低于100,而所有分桶加起来的总额又大于100。如果不做处理,就会造成资损。
应对这种极端场景,系统需要在检测到存在碎片时,自动将存在碎片的分桶下线纳入库存总池子,由DB总池子再分出少量的缓存key来进行扣减,多次循环直到不存在碎片为止。或者针对出现这种情况后,由于库存总量已经基本扣减完毕,在纳入DB总池子后直接在DB侧扣减。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号