套接字 缓冲区 6次拷贝 内核协议栈
练习题:
-2
思考题最后给你留两道思考题吧,你可以想一想 IPv4、IPv6、本地套接字格式以及通用地址套接字,它们有什么共性呢?如果你是 BSD 套接字的设计者,你为什么要这样设计呢?
-1
为什么本地套接字格式不需要端口号,而 IPv4 和 IPv6 套接字格式却需要端口号呢?
1
既然缓冲区如此重要,我们可不可以把缓冲区搞得大大的,这样不就可以提高应用程序的吞吐量了么?你可以想一想这个方法可行吗?
2
另外你可以自己总结一下,一段数据流从应用程序发送端,一直到应用程序接收端,总共经过了多少次拷贝?
05 | 使用套接字进行读写:开始交流吧 https://time.geekbang.org/column/article/116043
连接建立的根本目的是为了数据的收发。
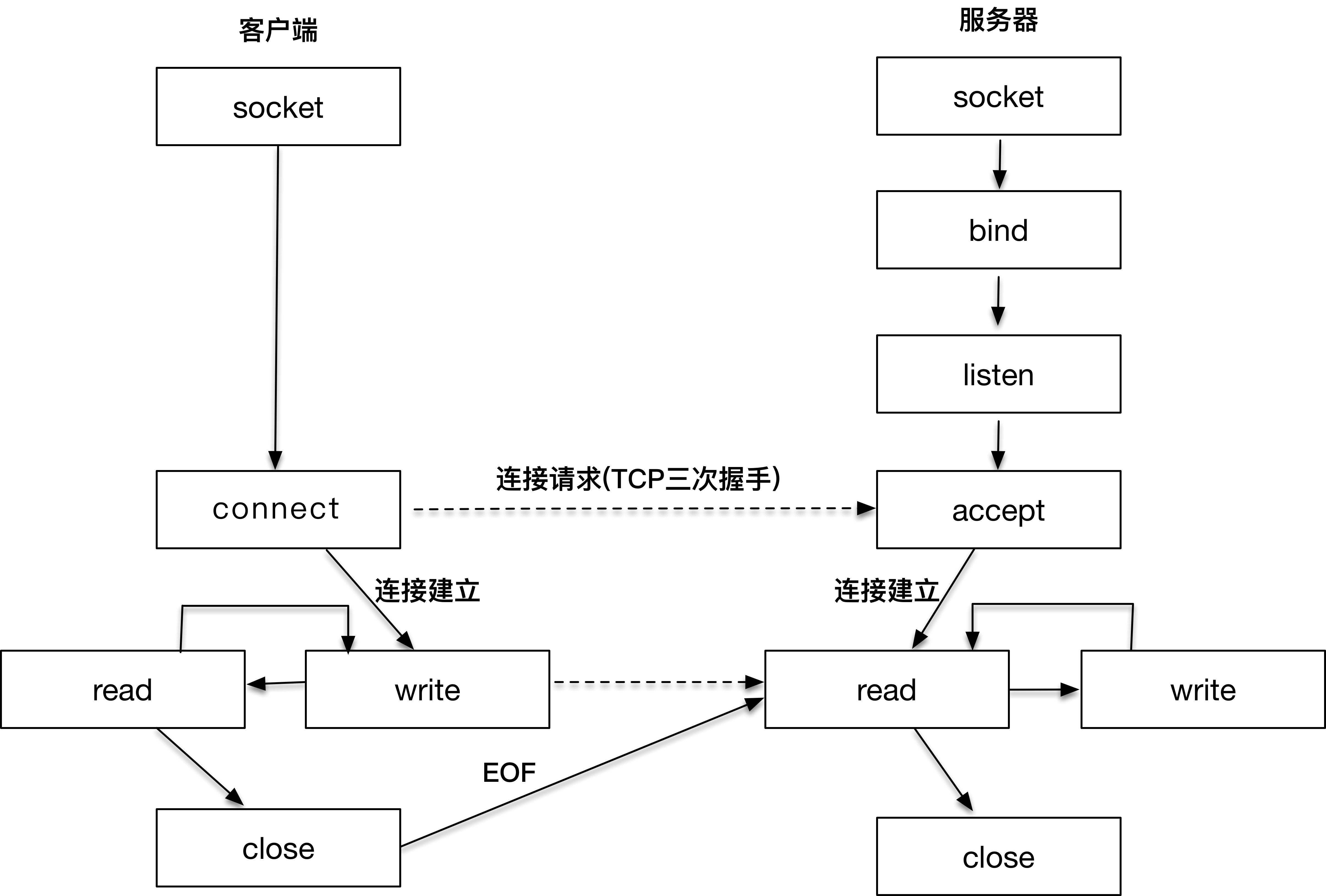
这张图表达的其实是网络编程中,客户端和服务器工作的核心逻辑。
我们先从右侧的服务器端开始看,因为在客户端发起连接请求之前,服务器端必须初始化好。右侧的图显示的是服务器端初始化的过程,首先初始化 socket,之后服务器端需要执行 bind 函数,将自己的服务能力绑定在一个众所周知的地址和端口上,紧接着,服务器端执行 listen 操作,将原先的 socket 转化为服务端的 socket,服务端最后阻塞在 accept 上等待客户端请求的到来。此时,服务器端已经准备就绪。
客户端需要先初始化 socket,再执行 connect 向服务器端的地址和端口发起连接请求,这里的地址和端口必须是客户端预先知晓的。
这个过程,就是著名的 TCP 三次握手(Three-way Handshake)。下一篇文章,我会详细讲到 TCP 三次握手的原理。一旦三次握手完成,客户端和服务器端建立连接,就进入了数据传输过程。
具体来说,客户端进程向操作系统内核发起 write 字节流写操作,内核协议栈将字节流通过网络设备传输到服务器端,服务器端从内核得到信息,将字节流从内核读入到进程中,并开始业务逻辑的处理,完成之后,服务器端再将得到的结果以同样的方式写给客户端。
可以看到,一旦连接建立,数据的传输就不再是单向的,而是双向的,这也是 TCP 的一个显著特性。
当客户端完成和服务器端的交互后,比如执行一次 Telnet 操作,或者一次 HTTP 请求,需要和服务器端断开连接时,就会执行 close 函数,操作系统内核此时会通过原先的连接链路向服务器端发送一个 FIN 包,服务器收到之后执行被动关闭,这时候整个链路处于半关闭状态,此后,服务器端也会执行 close 函数,整个链路才会真正关闭。
半关闭的状态下,发起 close 请求的一方在没有收到对方 FIN 包之前都认为连接是正常的;而在全关闭的状态下,双方都感知连接已经关闭。
请你牢牢记住文章开头的那幅图,它是贯穿整个专栏的核心图之一。讲这幅图的真正用意在于引入 socket 的概念,请注意,以上所有的操作,都是通过 socket 来完成的。
无论是客户端的 connect,还是服务端的 accept,或者 read/write 操作等,socket 是我们用来建立连接,传输数据的唯一途径。
IPv4 地址族的结构
/* IPV4套接字地址,32bit值. */
typedef uint32_t in_addr_t;
struct in_addr
{
in_addr_t s_addr;
};
/* 描述IPV4的套接字地址格式 */
struct sockaddr_in
{
sa_family_t sin_family; /* 16-bit */
in_port_t sin_port; /* 端口口 16-bit*/
struct in_addr sin_addr; /* Internet address. 32-bit */
/* 这里仅仅用作占位符,不做实际用处 */
unsigned char sin_zero[8];
};
思考
unix系统有一种一统天下的简洁之美:一切皆文件,socket也是文件。
1.像sock_addr的结构体里描述的那样,几种套接字都要有地址族和地址两个字段。这容易理解,你要与外部通信,肯定要至少告诉计算机对方的地址和使用的是哪一种地址。与远程计算机的通信还需要一个端口号。而本地socket的不同之处在于不需要端口号,那么就有了问题2;
2.本地socket本质上是在访问本地的文件系统,所以自然不需要端口。远程socket是直接将一段字节流发送到远程计算机的一个进程,而远程计算机可能同时有多个进程在监听,所以用端口号标定要发给哪一个进程。
05 | 使用套接字进行读写:开始交流吧 https://time.geekbang.org/column/article/116043
发送缓冲区
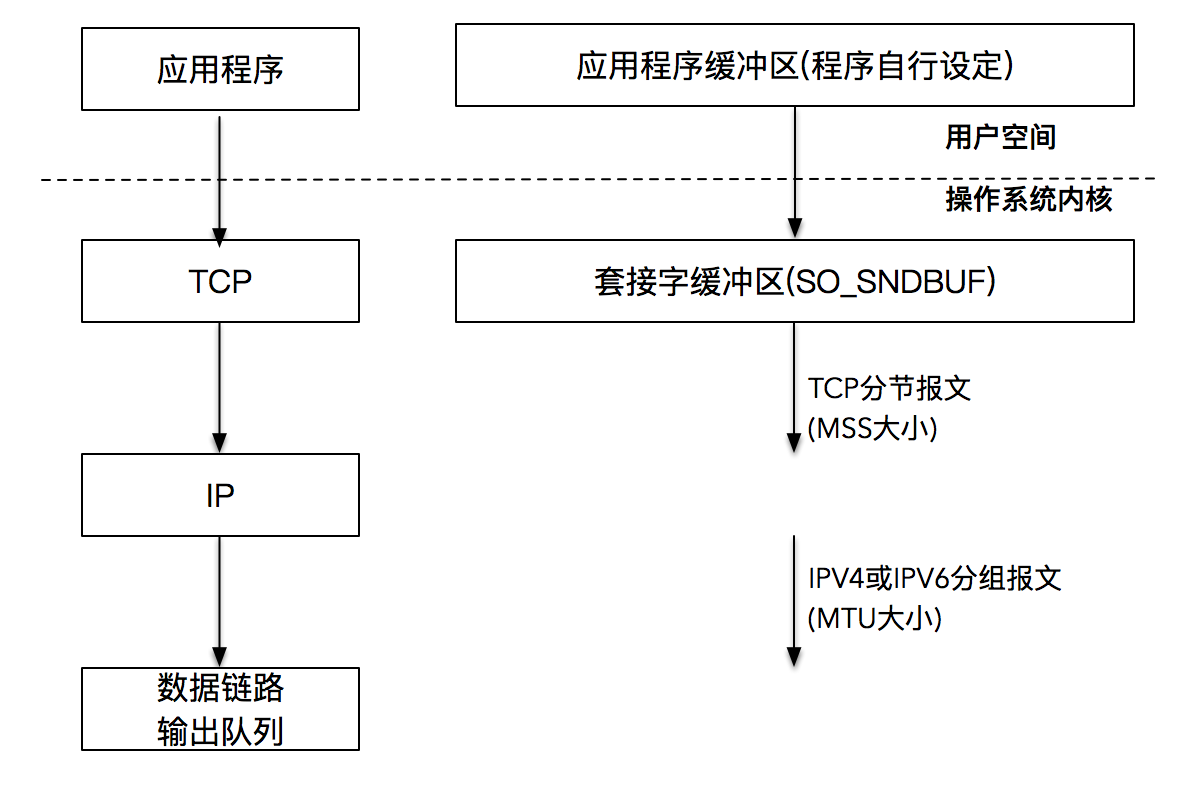
你一定要建立一个概念,当 TCP 三次握手成功,TCP 连接成功建立后,操作系统内核会为每一个连接创建配套的基础设施,比如发送缓冲区。
发送缓冲区的大小可以通过套接字选项来改变,当我们的应用程序调用 write 函数时,实际所做的事情是把数据从应用程序中拷贝到操作系统内核的发送缓冲区中,并不一定是把数据通过套接字写出去。
这里有几种情况:
第一种情况很简单,操作系统内核的发送缓冲区足够大,可以直接容纳这份数据,那么皆大欢喜,我们的程序从 write 调用中退出,返回写入的字节数就是应用程序的数据大小。
第二种情况是,操作系统内核的发送缓冲区是够大了,不过还有数据没有发送完,或者数据发送完了,但是操作系统内核的发送缓冲区不足以容纳应用程序数据,在这种情况下,你预料的结果是什么呢?报错?还是直接返回?
操作系统内核并不会返回,也不会报错,而是应用程序被阻塞,也就是说应用程序在 write 函数调用处停留,不直接返回。术语“挂起”也表达了相同的意思,不过“挂起”是从操作系统内核角度来说的。
那么什么时候才会返回呢?
实际上,每个操作系统内核的处理是不同的。大部分 UNIX 系统的做法是一直等到可以把应用程序数据完全放到操作系统内核的发送缓冲区中,再从系统调用中返回。怎么理解呢?
别忘了,我们的操作系统内核是很聪明的,当 TCP 连接建立之后,它就开始运作起来。你可以把发送缓冲区想象成一条包裹流水线,有个聪明且忙碌的工人不断地从流水线上取出包裹(数据),这个工人会按照 TCP/IP 的语义,将取出的包裹(数据)封装成 TCP 的 MSS 包,以及 IP 的 MTU 包,最后走数据链路层将数据发送出去。这样我们的发送缓冲区就又空了一部分,于是又可以继续从应用程序搬一部分数据到发送缓冲区里,这样一直进行下去,到某一个时刻,应用程序的数据可以完全放置到发送缓冲区里。在这个时候,write 阻塞调用返回。注意返回的时刻,应用程序数据并没有全部被发送出去,发送缓冲区里还有部分数据,这部分数据会在稍后由操作系统内核通过网络发送出去。
读取数据
我们可以注意到,套接字描述本身和本地文件描述符并无区别,在 UNIX 的世界里万物都是文件,这就意味着可以将套接字描述符传递给那些原先为处理本地文件而设计的函数。这些函数包括 read 和 write 交换数据的函数。
read 函数
让我们先从最简单的 read 函数开始看起,这个函数的原型如下:
ssize_t read (int socketfd, void *buffer, size_t size)
read 函数要求操作系统内核从套接字描述字 socketfd读取最多多少个字节(size),并将结果存储到 buffer 中。返回值告诉我们实际读取的字节数目,也有一些特殊情况,如果返回值为 0,表示 EOF(end-of-file),这在网络中表示对端发送了 FIN 包,要处理断连的情况;如果返回值为 -1,表示出错。当然,如果是非阻塞 I/O,情况会略有不同,在后面的提高篇中我们会重点讲述非阻塞 I/O 的特点。
注意这里是最多读取 size 个字节。如果我们想让应用程序每次都读到 size 个字节,就需要编写下面的函数,不断地循环读取。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号