结构的长度 不等于 各成员的长度和
小结:
1、内存对齐:空间换时间
2、尽管类型T1和T2拥有相同的字段集,但是它们的尺寸并不相等。
type T0 struct {
a int8
b int64
c int16
}
type T1 struct {
a int8
c int16
b int64
}
64位操作系统,基于x64的处理器
unsafe.Sizeof(T0{}),unsafe.Alignof(T0{}) 24,8
unsafe.Sizeof(T1{}),unsafe.Alignof(T1{}) 16,8
3、类型的对齐保证和类型的尺寸
从这个例子可以看出,尽管类型T1和T2拥有相同的字段集,但是它们的尺寸并不相等。
- 内置类型
int8的对齐保证和尺寸均为1个字节; 内置类型int16的对齐保证和尺寸均为2个字节; 内置类型int64的尺寸为8个字节,但它的对齐保证在32位架构上为4个字节,在64位架构上为8个字节。 - 下例中的类型
T1和T2的对齐保证均为它们的各个字段的最大对齐保证。 所以它们的对齐保证和内置类型int64相同,即在32位架构上为4个字节,在64位架构上为8个字节。 - 类型
T1和T2尺寸需为它们的对齐保证的倍数,即在32位架构上为4n个字节,在64位架构上为8n个字节。
type T1 struct {
a int8
// 在64位架构上,为了让字段b的地址为8字节对齐,
// 需在这里填充7个字节。在32位架构上,为了让
// 字段b的地址为4字节对齐,需在这里填充3个字节。
b int64
c int16
// 为了让类型T1的尺寸为T1的对齐保证的倍数,
// 在64位架构上需在这里填充6个字节,在32架构
// 上需在这里填充2个字节。
}
// 类型T1的尺寸在64位架构上为24个字节(1+7+8+2+6),
// 在32位架构上为16个字节(1+3+8+2+2)。
type T2 struct {
a int8
// 为了让字段c的地址为2字节对齐,
// 需在这里填充1个字节。
c int16
// 在64位架构上,为了让字段b的地址为8字节对齐,
// 需在这里填充4个字节。在32位架构上,不需填充
// 字节即可保证字段b的地址为4字节对齐的。
b int64
}
// 类型T2的尺寸在64位架构上位16个字节(1+1+2+4+8),
// 在32位架构上为12个字节(1+1+2+8)。
从这个例子可以看出,尽管类型T1和T2拥有相同的字段集,但是它们的尺寸并不相等。
一个有趣的事实是有时候一个结构体类型中零尺寸类型的字段可能会影响到此结构体类型的尺寸。 请阅读此问答获取详情。
内存布局 - Go语言101(通俗版Go白皮书) https://gfw.go101.org/article/memory-layout.html#size-and-padding
https://zh.wikipedia.org/wiki/数据结构对齐
数据结构对齐是程式编译后资料在内存内的布局与使用方式。包括三方面内容:数据对齐、数据结构填充(padding)与包入(packing)。
现代计算机CPU一般是以32位元或64位元大小作地址对齐,以32位元架构的计算机举例,每次以连续的4字节为一个区间,第一个字节的位址位在每次CPU抓取资料大小的边界上,除此之外,如果要访问的变量没有对齐,可能会触发总线错误。
当资料小于计算机的字(word)尺寸,可能把几个资料放在一个字中,称为包入(packing)。
许多编程语言自动处理数据结构对齐。Ada语言,[1][2] PL/I,[3] Pascal,[4] 某些C语言与C++实现, D语言,[5] Rust,[6] 与汇编语言允许特别控制对齐的方式。
定义[编辑]
内存地址a被称为n字节对齐,a是n的倍数(n应是2的幂),也可以理解为当被访问的数据长度为n 字节时,数据地址为n字节对齐。如果内存未对齐,称作misaligned。
内存指针是对齐的,如果它所指的数据是对齐的。指向聚合数据(aggregate data,如struct或数组)是对齐的,当且仅当它的每个组成数据是对齐的。
体系结构[编辑]
RISC[编辑]
x86[编辑]
x86体系架构最初是不要求内存对齐。一些SSE2指令要求数据是128比特(16字节)对齐。有些CPU指令用于未对齐访问如MOVDQU。读写内存操作仅在对齐时才是原子的。
C语言struct在x86上的对齐[编辑]
C语言数据结构内的成员先后顺序不能改变。
常见的C语言编译器在32比特x86上,double是8字节对齐,但Linux上是4字节对齐(编译选项-malign-double实现8字节对齐)。
一些编译器(Microsoft,[7] Borland, GNU,[8]等等)使用#pragma directive指定对齐的包入(packing)。例如:
#pragma pack(push) /* push current alignment to stack */
#pragma pack(1) /* set alignment to 1 byte boundary */
struct MyPackedData
{
char Data1;
long Data2;
char Data3;
};
#pragma pack(pop) /* restore original alignment from stack */
这个结构在32位系统的大小为6字节。
缺省packing与#pragma pack[编辑]
Microsoft编译器的项目缺省packing(编译选项/Zp)与#pragma pack指令。#pragma pack指令仅能减少packing尺寸。[9]
CPU拒绝读没有对齐的数据
About Data Alignment | Microsoft Docs https://docs.microsoft.com/en-us/previous-versions/ms253949(v=vs.90)?redirectedfrom=MSDN
About Data Alignment
9/7/2007
Many CPUs, such as those based on Alpha, IA-64, MIPS, and SuperH architectures, refuse to read misaligned data. When a program requests that one of these CPUs access data that is not aligned, the CPU enters an exception state and notifies the software that it cannot continue. On ARM, MIPS, and SH device platforms, for example, the operating system default is to give the application an exception notification when a misaligned access is requested.
Misaligned memory accesses can incur enormous performance losses on targets that do not support them in hardware.
Alignment
Alignment is a property of a memory address, expressed as the numeric address modulo a power of 2. For example, the address 0x0001103F modulo 4 is 3; that address is said to be aligned to 4n+3, where 4 indicates the chosen power of 2. The alignment of an address depends on the chosen power of two. The same address modulo 8 is 7.
An address is said to be aligned to X if its alignment is Xn+0.
CPUs execute instructions that operate on data stored in memory, and the data are identified by their addresses in memory. In addition to its address, a single datum also has a size. A datum is called naturally aligned if its address is aligned to its size, and misaligned otherwise. For example, an 8-byte floating-point datum is naturally aligned if the address used to identify it is aligned to 8.
Compiler handling of data alignment
Device compilers attempt to allocate data in a way that prevents data misalignment.
For simple data types, the compiler assigns addresses that are multiples of the size in bytes of the data type. Thus, the compiler assigns addresses to variables of type long that are multiples of four, setting the bottom two bits of the address to zero.
In addition, the compiler pads structures in a way that naturally aligns each element of the structure. Consider the structure struct x_ in the following code example:
struct x_
{
char a; // 1 byte
int b; // 4 bytes
short c; // 2 bytes
char d; // 1 byte
} MyStruct;
The compiler pads this structure to enforce alignment naturally.
Example
The following code example shows how the compiler places the padded structure in memory:
// Shows the actual memory layout
struct x_
{
char a; // 1 byte
char _pad0[3]; // padding to put 'b' on 4-byte boundary
int b; // 4 bytes
short c; // 2 bytes
char d; // 1 byte
char _pad1[1]; // padding to make sizeof(x_) multiple of 4
}
Both declarations return sizeof(struct x_) as 12 bytes.
The second declaration includes two padding elements:
- char _pad0[3] to align the int b member on a four-byte boundary
- char _pad1[1] to align the array elements of the structure struct _x bar[3];
The padding aligns the elements of bar[3] in a way that allows natural access.
The following code example shows the bar[3] array layout:
adr
offset element
------ -------
0x0000 char a; // bar[0]
0x0001 char pad0[3];
0x0004 int b;
0x0008 short c;
0x000a char d;
0x000b char _pad1[1];
0x000c char a; // bar[1]
0x000d char _pad0[3];
0x0010 int b;
0x0014 short c;
0x0016 char d;
0x0017 char _pad1[1];
0x0018 char a; // bar[2]
0x0019 char _pad0[3];
0x001c int b;
0x0020 short c;
0x0022 char d;
0x0023 char _pad1[1];
See Also
Reference
Concepts
Working with Packing Structures
Working with Packing Structures | Microsoft Docs https://docs.microsoft.com/en-us/previous-versions/ms253935(v=vs.90)
Working with Packing Structures
9/7/2007
Problems can occur when a structure requires more bytes than the programmer intended, especially when space requirements are paramount.
Structure Packing and Alignment
Structure packing interacts with compiler alignment behavior as follows.
- If the packsize is set equal to or greater than the default alignment, the packsize is ignored.
- If the packsize is set smaller than the default alignment, the compiler aligns according to the packsize value.
Thus, if the packsize is set to four, data types having a size of four, eight, or 16 bytes are aligned on addresses that are multiples of four. However, there is no guarantee that data types eight bytes in size (64 bits) are aligned on addresses that are a multiple of eight. The packsize has no effect on data types outside of a structure.
In addition, packing affects the alignment of the entire packed structure. For example, in a structure declared under #pragma pack(1), the alignment of all members are forced to one, regardless of whether they would have been naturally aligned even without packing.
The following techniques set a packsize, in bytes:
- The command-line option /Zp (Struct Member Alignment) sets the packsize to n, in which n can be 1, 2, 4, 8, or 16, and in which 8 is the default.
- The compiler directive #pragma pack([n]) sets the packsize to n, in which n can be 1, 2, 4, 8, or 16. If nis not specified, #pragma pack resets the packsize to its value at the beginning of compilation: either the value specified by /Zp (Struct Member Alignment), or the default, which is 8 on most platforms.
The pragma applies only from the point at which it occurs in the source. For example, the /Zp1 option sets the packsize to 1, which causes the compiler to use no padding within structures. To avoid this problem, turn off structure packing or use the __unaligned keyword when accessing unaligned members of such structures through pointers.
Guidelines for packing structures
The following list shows possible solutions to the structure issue.
-
Reordering structure members
If space requirements are critical, reorder the members of the structure so the same-sized elements are next to each other and pack tightly. Usually, you start with the largest members and work your way down to the smallest ones.
Note that reordering a structure assumes that the user has full control of the data structure, but the user might not have the freedom to rearrange the members. For example, the data structure might represent the layout of fields in a file on disk.
Consider the following code example:struct x_ { char a; // 1 byte int b; // 4 bytes short c; // 2 bytes char d; // 1 byte } MyStruct;If you reorganize the members of this structure, as shown in the following code example, the reorganized structure aligns all members on natural boundaries, and the size of the structure is eight bytes instead of 12.
struct x_ { int b; // 4 bytes short c; // 2 bytes char d; // 1 byte char a; // 1 byte } MyStruct; -
Padding the structure
A different kind of problem can arise when the structure size requires padding to make sure array elements have the same alignment, but the user needs to ensure that there is no padding between the array elements. For example, the user might need to restrict memory usage or read data from a fixed-format source.
If the structure requires padding, you can use the compiler directive #pragma pack. However, #pragma pack causes elements of the structures to be unaligned, and it requires the use of the __unaligned keyword qualifier to generate the code needed to access this data without causing alignment faults.
The following example code uses #pragma pack to tell the compiler that the pointer px points to data that is not naturally aligned, and tells the compiler to generate the appropriate sequence of load, merge, and store operations to do the assignment efficiently.# pragma pack (1) struct x_ { char a; // 1 byte int b; // 4 bytes short c; // 2 bytes } MyStruct; # pragma pack () void bar() { struct x_ __unaligned *px = &MyStruct; . . . . px->b = 5; }The __unaligned keyword should only be used as a last resort, because the generated code is less efficient than accessing naturally aligned data. However, the __unaligned keyword is clearly preferable to alignment faults.
If at all possible, arrange the members of a data structure to preserve alignment and minimize space at the same time.
See Also
Reference
对齐
alignment - Wiktionary https://en.wiktionary.org/wiki/alignment

对齐要求 空穴 hole
https://mp.weixin.qq.com/s/BnCV2ZsB-hVuDJXgQqpC4A
C语言:--位域和内存对齐
位域
位域是指信息在保存时,并不需要占用一个完整的字节,而只需要占几个或一个二进制位。为了节省空间,C语言提供了一种数据结构,叫“位域”或“位段”。
“位域“是把一个字节中的二进位划分为几个不同的区域,并说明每个区域的位数,每个域有一个域名,允许在程序中按位域名进行操作。这样就可以把几个不同的对象用一个字节的二进制位域来表示。
位域的使用和结构成员的使用相同,其一般形式为:位域 变量名.位域名 位域允许用各种格式输出。
1. 在C中,位域可以写成这样(注:位域的数据类型一律用无符号的,纪律性)。
struct bitmap
{
unsigned a : 1;
unsigned b : 3;
unsigned c : 4;
}bit;
sizeof(bitmap) == 4;(整个struct的大小为4,因为位域本质上是从一个数据类型分出来的,在我们的例子中数据类型就是unsigned,大小为4,并且位域也是满足C 的结构体内存对齐原则的,等下我们会说到)。
2. 当然了位域也可以有空域。
struct bitmap
{
unsigned a:4;
unsigned :0; /*空域*/
unsigned b:4; /*从下一单元开始存放*/
unsigned c:4;
}
sizeof(bitmap) == 8;
3. 在这个位域定义中,a占第一字节的4位,后4位填0表示不使用,b从第二字节开始,占用4位,c占用4位。这里我们可以看到空域的作用是填充数据类型的剩下的位置,有时候我们只是想调整一下内存分配,则我们可以使用无名位域:
struct bitmap {
unsigned a:1;
unsigned :2;
unsigned b:3;
unsigned c:2;
};
sizeof(bitmap) == 4;

4. 如果一个位域的位的分配超过了该类型的位的总数,则从下一个单元开始继续分配,这个很好理解:
struct bitmap
{
unsigned a : 8;
unsigned b : 30;
unsigned c : 4;
};
sizeof(bitmap) == 12;
注意这个位域的大小是12而不是8,说明如果超了大小是立马从下一个单元开始分配。
位域的使用主要出现在如下两种情况:
(1)当机器可用内存空间较少而使用位域可以大量节省内存时。如,当把结构作为大数组的元素时。
(2)当需要把一结构或联合映射成某预定的组织结构时。例如,当需要访问字节内的特定位时。
当要把某个成员说明成位域时,其类型只能是int,unsigned int与signed int三者之一(说明:int类型通常代表特定机器中整数的自然长度。short类型通常为16位,long类型通常为32位,int类型可以为16位或32位.各编译器可以根据硬件特性自主选择合适的类型长度.
关于位域还需要提醒读者注意如下几点:
其一,位域的长度不能大于int对象所占用的字位数.例如,若int对象占用16位,则如下位域说明是错误的:
unsigned int x:17;
其二,由于位域的实现会因编译程序的不同而不同,在此使用位域会影响程序的可移植性,在不是非要使用位域不可时最好不要使用位域.
其三,尽管使用位域可以节省内存空间,但却增加了处理时间,在为当访问各个位域成员时需要把位域从它所在的字中分解出来或反过来把一值压缩存到位域所在的字位中.
其四,位域的位置不能访问,因些不能对位域使用地址运算符号&(而对非位域成员则可以使用该运算符).从而,即不能使用指向位域的旨针也不能使用位域的数组(因为数组实际上就是一种特殊的指针).另外,位域也不能作为函数返回的结果.
最后还要强调一遍:位域又叫位段(位字段),是一种特殊的结构成员或联合成员(即只能用在结构或联合中).
2. 内存对齐:
1. 说到位域就不得说下内存对齐的东西,其实内存对齐也很简单,只是不同的编译器实现不一样,至于为什么要内存对齐,这个要从CPU的基本工作原理说起,但是首先要明白,无论我们是否内存对齐,CPU大多数情况都是能正常工作的(前提:对于大多数IA32指令都可以这么说,但是部分指令,如SSE多媒体指令这些就不行,这些指令有特殊内存对齐要求,比如16字节对齐,任何不满足内存对齐的地址访问储存器都是会导致异常,对于这些指令,编译器必须在编译的时候采取强制内存对齐)。
实现内存对齐可以提高CPU的性能,比如处理器能一次取出8个字节,这个时候必须要求数据地址要8字节对齐,这个是和CPU和储存器的外围电路决定的,在内存对齐的情况下,CPU从储存器取出这8个字节只需要一个时钟周期,但是如果这个地址不是8字节对齐,那么CPU可能就需要两个时钟周期才能取出这8个字节。
对于IA32,每个栈帧都惯例16字节对齐,编译器一般也会那么做,但是对于数据类型不同的编译器表现可能不一样,对于Windows(VC编译器),任何K字节的基本对象的地址都必须是K的倍数(比如对于int,必须4字节对齐,对于double,必须8字节对齐),这很大程度上提高了储存器和CPU的工作性能,但是对存储空间的浪费比较严重;对于Linux,惯例是8字节数对齐4字节边界(比如double可以4字节对齐)。对于Windows好Linux,数据类型long double都有4字节对其的要求,对于GCC,long double分配12字节(虽然它只占10字节大小)。
所以我们有一般规则:
struct X{char a;float b;int c;double d;unsigned e;};sizeof(X) == 32;
内存对齐状况应该是下面这个样子:
struct X{char a; // 1 byteschar padding1[3]; // 3 bytesfloat b; // 4 bytesint c; // 4 byteschar padding2[4]; // 4 bytesdouble d; // 8 bytesunsigned e; // 4 byteschar padding3[4]; // 4 bytes};sizeof(X) == 32;
(其中最后的4个字节的填充是因为规则4,看下面)。
2. 如果自定义数据类型含有位域,则内存对齐满足以下原则:
1. 如果相邻的位域的数据类型相同,则按照分配位的大小来,详情看我上面写的位域的第5个情况。
2. 如果相邻的位域的数据类型不相同,则不同编译器实现不一样,有些编译器选择不压缩。
3. 如果位域不连续,中间含非位域,则按标准数据类型大小划分,比如:
struct bitmap{unsigned a : 2;int b;unsigned c : 3;};sizeof(bitmap) == 12;
3. 另外可以通过添加#pragma pack(n)来强制改变内存分配情况,比如在VC编译器中:
struct bitmap
{
unsigned a;
double c;
};
sizeof(bitmap) == 16;
加了#pragma pack(4),则强制内存对齐4字节,再测试下其大小:
struct bitmap{unsigned a;double c;};sizeof(bitmap) == 12;
当然,如果#pragma pack(n)的n大于本身数据类型的宽度,则按数据类型的宽度来分配:
struct bitmap{double c;int k;int m;};sizeof(bitmap) == 16 != 32
4. 自定义类型(C结构体,C++聚合类)的最后的内存对齐,是按照自定义类型内的最大类型的宽度来的,比如上面那个例子去掉int m:
struct bitmap
{
double c;
int k;
};
sizeof(bitmap) == 16
必须以double进行8字节对齐(VC编译器)。
https://mp.weixin.qq.com/s/Wd2PKMKrRcF7brjX4N_L9w
什么是内存对齐?Go 是否有必要内存对齐?
https://mp.weixin.qq.com/s/NE6Y2TVxrl-cpY-36puQcQ
CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如 32 位的 CPU,字长为 4 字节,那么 CPU 访问内存的单位也是 4 字节。
这么设计的目的,是减少 CPU 访问内存的次数,加大 CPU 访问内存的吞吐量。比如同样读取 8 个字节的数据,一次读取 4 个字节那么只需要读取 2 次。
下面我们来看看,编写程序时,变量在内存中是否按内存对齐的差异。假设我们有如下结构体:
struct Foo {
uint8_t a;
uint32_t b;
}
示意图如下:
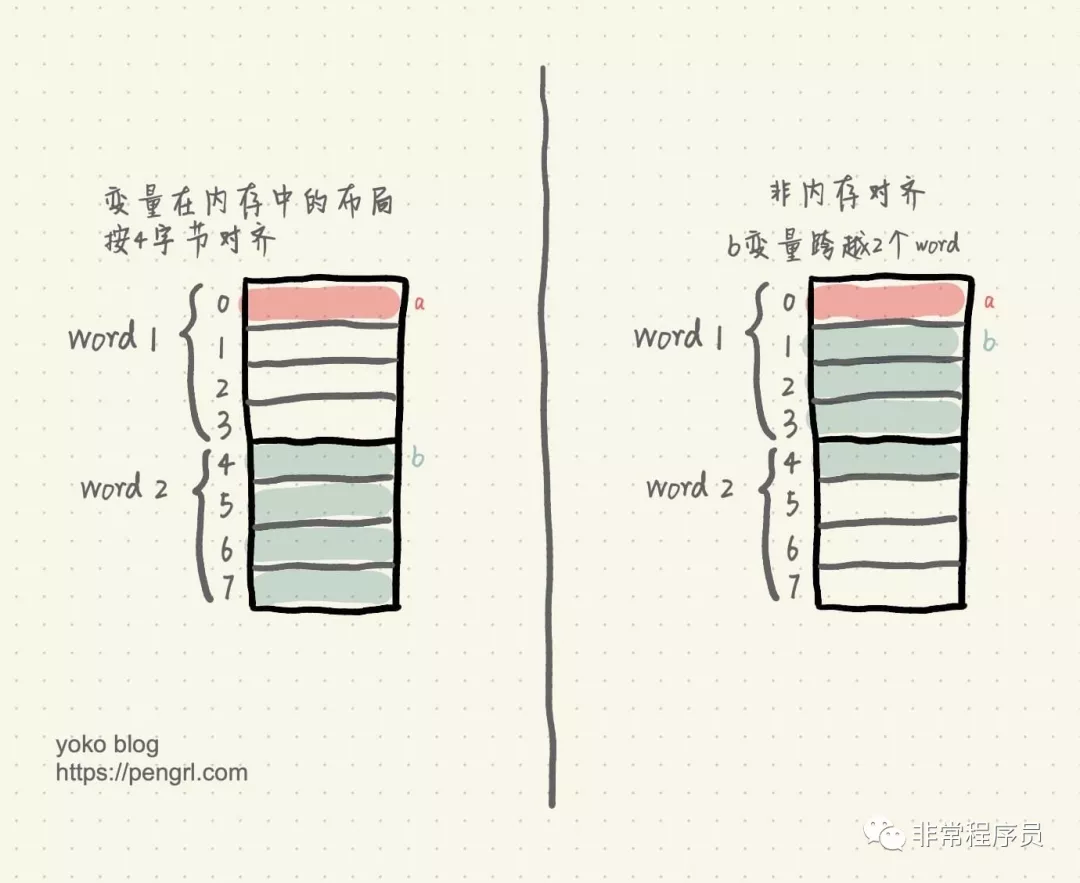
内存对齐
我们假设 CPU 以 4 字节为单位读取内存。
如果变量在内存中的布局按 4 字节对齐,那么读取 a 变量只需要读取一次内存,即 word1;读取 b 变量也只需要读取一次内存,即 word2。
而如果变量不做内存对齐,那么读取 a 变量也只需要读取一次内存,即 word1;但是读取 b 变量时,由于 b 变量跨越了 2 个 word,所以需要读取两次内存,分别读取 word1 和 word2 的值,然后将 word1 偏移取后 3 个字节,word2 偏移取前 1 个字节,最后将它们做或操作,拼接得到 b 变量的值。
显然,内存对齐在某些情况下可以减少读取内存的次数以及一些运算,性能更高。
另外,由于内存对齐保证了读取 b 变量是单次操作,在多核环境下,原子性更容易保证。
但是内存对齐提升性能的同时,也需要付出相应的代价。由于变量与变量之间增加了填充,并没有存储真实有效的数据,所以占用的内存会更大。这也是一个典型的空间换时间的应用场景。
好,本篇文章就到这里,后面会再写一篇文章介绍编写 c 程序时,如何开关内存对齐,以及控制内存按多少字节对齐。
type T0 struct {a int8b int64c int16}type T1 struct {a int8c int16b int64} 64位操作系统,基于x64的处理器 unsafe.Sizeof(T0{}),unsafe.Alignof(T0{}) 24,8 unsafe.Sizeof(T1{}),unsafe.Alignof(T1{}) 16,8
什么是内存对齐,原理你真的了解吗? - 简书 https://www.jianshu.com/p/37409be16a37

在每个bank内部,就是电容的行列矩阵结构了。(注意,二维矩阵中的一个元素一般存储着8个bit,也就是说包含了8个小电容)。
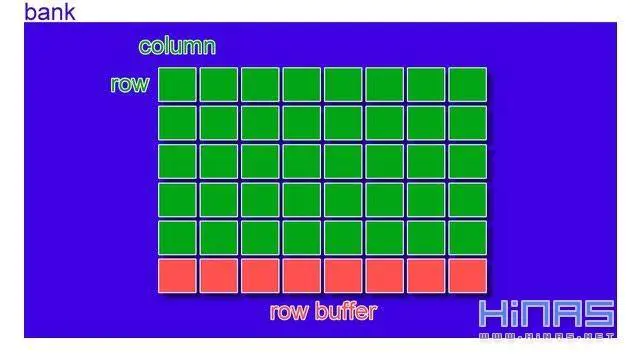
8个同位置的元素,一起组成在内存中连续的64个bit。如下图
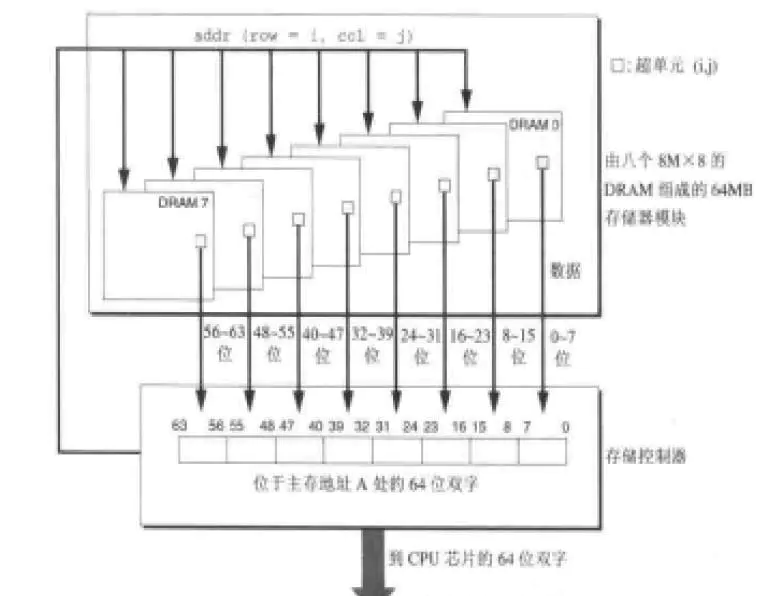
内存在进行IO的时候,一次操作取的就是64个bit。
所以,内存对齐最最底层的原因是内存的IO是以64bit为单位进行的。 对于64位数据宽度的内存,假如cpu也是64位的cpu(现在的计算机基本都是这样的),每次内存IO获取数据都是从同行同列的8个chip中各自读取一个字节拼起来的。从内存的0地址开始,0-63bit的数据可以一次IO读取出来,64-127bit的数据也可以一次读取出来。CPU和内存IO的硬件限制导致没办法一次跨在两个数据宽度中间进行IO。
假如对于一个c的程序员,如果把一个bigint(64位)地址写到的0x0001开始,而不是0x0000开始,那么数据并没有存在同一行列地址上。因此cpu必须得让内存工作两次才能取到完整的数据。效率自然就很低。这下你有没有彻底理解了内存对齐?
扩展1:如果不强制对地址进行操作,仅仅只是简单用c定义一个结构体,编译和链接器会自动替开发者对齐内存的。尽量帮你保证一个变量不跨列寻址。
扩展2:其实在内存硬件层上,还有操作系统层。操作系统还管理了CPU的一级、二级、三级缓存。实际中不一定每次IO都从内存出,如果你的数据局部性足够好,那么很有可能只需要少量的内存IO,大部分都是更为高效的高速缓存IO。但是高速缓存和内存一样,也是要考虑对齐的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号