高并发系统 队列 减库存 不知道谁依赖“我”的处理结果、不关心其他系统如何处理后续业务
聊聊高并发系统之队列术
https://mp.weixin.qq.com/s/qoXwqKsSLE1i7YB7_c19Cg
队列在数据结构中是一种线性表,从一端插入数据,然后从另一端删除数据。本文目的不是讲解各种队列算法,而是在应用层面讲述使用队列能解决哪些场景问题。
在我开发过的系统中,不是所有的业务都必须实时处理、不是所有的请求都必须实时反馈结果给用户、不是所有的请求/处理都必须100%处理成功、不知道谁依赖“我”的处理结果、不关心其他系统如何处理后续业务、不需要强一致性,只需保证最终一致性即可、想要保证数据处理的有序性;此时你应该考虑使用队列来解决这些问题。在实际开发时我们经常使用队列进行异步处理、系统解耦、数据同步、流量削峰、缓冲、限流等。
应用场景
异步处理:使用队列的一个主要原因是进行异步处理,比如用户注册成功后需要发送注册成功邮件/新用户积分/优惠券等等、缓存过期时先返回老的数据,然后异步更新缓存、异步写日志等;通过异步处理,可以提升主流程响应速度,而非主流程/非重要业务可以异步集中处理,这样还可以将任务聚合然后批量处理;因此可以使用消息队列/任务队列来进行异步处理。
系统解耦:比如用户成功支付完成订单后,需要通知生产配货系统、发票系统、库存系统、推荐系统、搜索系统、风控系统等进行业务处理;而未来需要添加/支持哪些业务是不清楚的,而且这些业务处理不需要实时处理、不需要强一致,只需要最终一致性即可,因此可以通过消息队列/任务队列进行系统解耦。
数据同步:比如想把Mysql变更的数据同步到Redis、或者将Mysql数据同步到Mongodb、或者机房间数据同步、或者主从数据同步等,此时可以考虑使用如databus、canal、otter。使用数据总线队列进行数据同步的好处是可以保证数据修改的有序性。
流量削峰:系统瓶颈一般在数据库上,比如扣减库存、下单等;此时可以考虑使用队列将变更请求暂时放入队列,通过缓存+队列暂存的方式将数据库流量削峰;还有如秒杀系统,下单服务会是该系统的瓶颈,此时会使用队列进行排队和限流,从而保护下单服务。通过队列暂存或者队列限流来削峰。
比如减库存,可以考虑这样设计:

直接在Redis中扣减,然后记录下扣减日志(FIFO队列),通过Worker去同步到DB。
实际队列的应用场景还是非常多的,本文列举了笔者遇到过比较多的场景。
缓冲区队列
典型的如Log4j的日志缓冲区,当我们使用log4j记录日志时,可以配置字节缓冲区,字节缓存区满时会立即同步到磁盘(flush操作)。Log4j使用BufferedWriter实现的;此模式不是异步写,在缓冲区满的时候还是会阻塞主线程。如果需要异步模式可以使用AsyncAppender,然后通过bufferSize控制日志事件缓冲区大小。
通过缓冲区队列可以实现:批量处理、异步处理。
任务队列
使用任务队列将一些不需要与主线程同步执行的任务扔到任务队列异步处理即可;笔者用的最多的是线程池任务队列(默认LinkedBlockingQueue)和Disruptor任务队列(RingBuffer)。如刷数据时,将任务扔到队列异步处理即可,处理成功后再异步通知用户;还有如删除SKU操作,用户请求时直接将任务分解并扔到队列,异步处理,处理成功后异步通知用户即可;还有如查询聚合,将多个可并行处理的任务扔到队列然后等待最慢的一个返回。如果使用的是内存任务队列请记住可能存在系统重启等问题造成的数据丢失。
通过任务队列可以实现:异步处理、任务分解/聚合处理。
注:JDK7提供了ExecutorService的新的实现ForkJoinPool,其提供了Work-stealing机制,可以更好地提升并发效率。
在使用Executors.newFixedThreadPool时,其没有设置队列大小(默认Integer.MAX_VALUE),如果有大量任务被缓存到LinkedBlockingQueue中等待线程执行,会出现GC慢等问题,造成系统响应慢甚至OOM。因此在使用线程池时候,要指定队列大小并设置合理的RejectedExecutionHandler;要记录请求来源的参数方便定位引发问题的源头。
消息队列
笔者所在公司使用的是自研的JMQ;开源的有ActiveMQ、Kafka、Redis。使用消息队列存储各业务数据,其他系统根据需要订阅即可。常见的模式是:点对点(一个消息只有一个消费者)、发布订阅(一个消息可以有多个消费者);而常用的是发布订阅模式。
比如用户注册成功、修改商品数据、订单状态变更等都应该将变更发送到消息队列,从而其他系统根据需要订阅该消息,然后按照自己的需求进行业务逻辑开发。
在添加新功能时,消息消费者只需要订阅该消息,然后开发相应的业务逻辑,消息生产者根本不关心你怎么使用消息和你做什么业务处理。
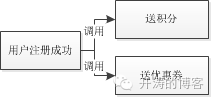
同步调用,添加什么新功能都需要到用户系统提需求。其中一个服务出现问题了,整个服务就不可用了。

消息队列,用户系统只需要发布用户注册成功的消息即可,相关系统订阅该消息,然后执行相关的业务逻辑。相关服务出问题不影响到注册主流程。
通过消息队列可以实现:异步处理、系统解耦。
请求队列
请求队列是指如在Web环境下对用户请求排队,从而进行一些特殊控制:流量控制、请求分级、请求隔离;如将请求按照功能划分到不同的队列,从而使得不同的队列出现问题后相互不影响;还可以对请求分级,一些重要请求可以优先处理(发展到一定程度应将功能物理分离);还有服务器处理能力有限,在接近服务器瓶颈时需要考虑限流,最简单的限流时丢弃处理不了的请求,此时可以使用队列进行流量控制。
数据总线队列
一般消息队列中的消息都是业务维度的,比如业务键或者业务状态等,比如哪个SKU变更了,而有些订阅者需要再查一遍来获取最新的修改数据(比如缓存同步);通过现有的消息队列方式的缺点是很难只进行修改部分的推送和保证数据有序性。而此种场景比较适合使用数据总线队列实现。如数据库数据修改后需要同步数据到缓存,或者需要将一个机房数据同步到另一个机房,只是数据维度的同步,此时应该使用数据总线队列如canal、otter、databus;使用数据总线队列的好处是可以保证数据的有序性。
混合队列
在《构建需求响应式亿级商品详情页》曾介绍过该方式的队列,使用混合队列来解决实际问题。

此处MQ是使用京东自研的JMQ,消息是可靠持久化存储的;应用会按照不同的维度发布消息到JMQ;下游应用接收到该消息后会放入到Redis,使用Redis List来存储这些任务;应用将Redis消息消费处理后,会按照不同的维度聚合商品消息然后再次发送出去。
使用Redis队列的主要原因是想提升消息堆积能力和并发处理能力。另外在使用Redis构建消息队列时需要考虑网络抖动造成的消息丢失问题,因为Redis是没有回滚事务的,或者说是确认机制。我们使用如下方式防止消息丢失:
try {
id = queueRedis.opsForList().rightPopAndLeftPush(queueName, processingQueueName);
} catch (Exception e) {
//发生了网络异常,需要把processing中的id再放回到waiting queue中
String msg = queueName + " to " + processingQueueName + " rpoplpush error";
LOG.error(msg, e);
//报警代码
}
而对于失败我们会进行重试三次,重试失败后放入失败队列,而失败队列是具有防重功能的(从本地队列和失败队列排重),使用的是Redis Lua脚本实现:
static EventQueueScript ADD_TO_FAIL_QUEUE_REDIS_SCRIPT = new EventQueueScript(
"redis.call('lrem', KEYS[1], 1, ARGV[1]) redis.call('lrem', KEYS[2], 1, ARGV[1]) return redis.call('lpush', KEYS[2], ARGV[1])"
);
Redis作者Antirez开发的内存分布式消息队列Disque是未来更好的内存消息队列选择。
其他
优先级队列:在实际开发时肯定有些任务是紧急的,此时应该优先处理紧急的任务;所以请考虑对队列进行分级。
副本队列:在进行一些系统重构或者上新的功能时,如果没有足够的信心保证业务逻辑正确,可以考虑存储一份队列的副本(比如1小时、1天的),从而当业务出现问题时可以对这些消息进行回放。
镜像队列:每个队列不会无限制订阅数量,一定会有一个极限的;当到达极限时请考虑使用镜像队列方式解决该问题。
队列并发数:不同队列实现,队列服务端并发连接数是不一样的;一定不是增大队列并发连接数消费能力也随着增加;也不会因为增加了消费服务器消费并发能力也随着增加,需要根据实际情况来设置合理的并发连接数。
推还是拉:消息体内容不是越全越好,需要根据具体业务设计消息体;如有些系统依赖商品变更消息(只有一个SKU)、有些系统依赖商品状态消息(SKU、状态)、有些系统依赖商品属性变更消息(SKU、变更的属性)等,如果让所有系统都消费商品变更消息,那么这些系统都会调用商品查询服务拉一下最新的商品信息然后进行处理。因此要根据实际情况来决定是使用推送方式(将系统需要的所有信息推过去)还是拉取方式(只推送ID,然后再查一遍)。
消息合并:如果消息写入量非常大,应该考虑将消息合并写,可以"写应用本地磁盘队列"-->“同步本地磁盘队列到消息中间件”;同步时可以根据需求制定同步策略,如1秒同步1次。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号