每天改进一点点之改进日志收集系统 原创: 赵建鹏 雪球工程师团队 2018-03-23
小结:
1、
每天改进一点点之改进日志收集系统
原创: 赵建鹏 雪球工程师团队 2018-03-23
https://mp.weixin.qq.com/s/fVydtgs0da7HNrPw-nPMMg
| 问题出现
最近雪球的大数据集群集群在存储、计算资源已经接近饱和,我们开始了节点扩容的工作,这套系统采用 CDH (Hadoop 的一个分发版)来搭建,因为运行了一段时间版本也比较老旧了,我们决定新建一个 CDH 集群然后把数据逐步从旧集群迁移到新集群这样可以同时完成扩容和升级的工作。
但是在迁移过程中 由于新旧集群的资源紧缺,又导致了原有的日志收集服务频繁发生问题:
-
日志延迟
-
数据丢失
-
负载过高
雪球每天需要收集的日志量很大,这些数据是我们日常监控、报警、问题排查、业务统计的来源,我们并不想丢失任何数据。所以必须要对日志收集服务进行问题诊断和改造。
| 原有的收集流程
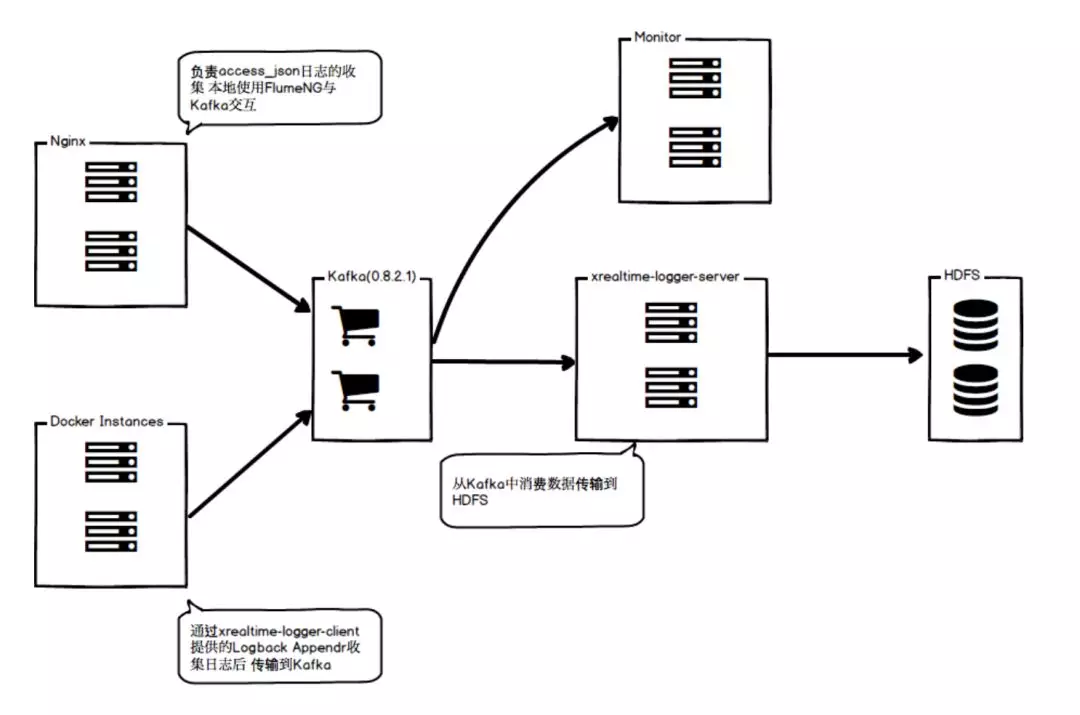
这套方案在 2015 年下半年投入使用,最初的流程只是通过Kafka传输数据队列消费者将数据传输到 HDFS 集群
优点:
-
架构简单
-
基于Kafka的ISR机制保证日志传输过程的可用性
缺点:
-
现有版本客户端有潜在风险,比如消息乱序、基于BDB实现的本地Buffer
-
只保证传输过程中的可用性,缺乏基于Kafka恢复、检查数据的工具
-
基于Kafka实现的可用性成本较高
-
输出实现方案较少,只支持HDFS
-
目前版本缺乏监控信息,无法得知服务的健康状态
另外,我们存储的数据 2017 下半年的就已经是是 2015 年的 3 倍左右了(当时还是牛市)。因为现在雪球业务在快速增长,在可见的未来当前的架构已经不能满足需求,于是我们开始了重构之路。
| 重构后的收集流程
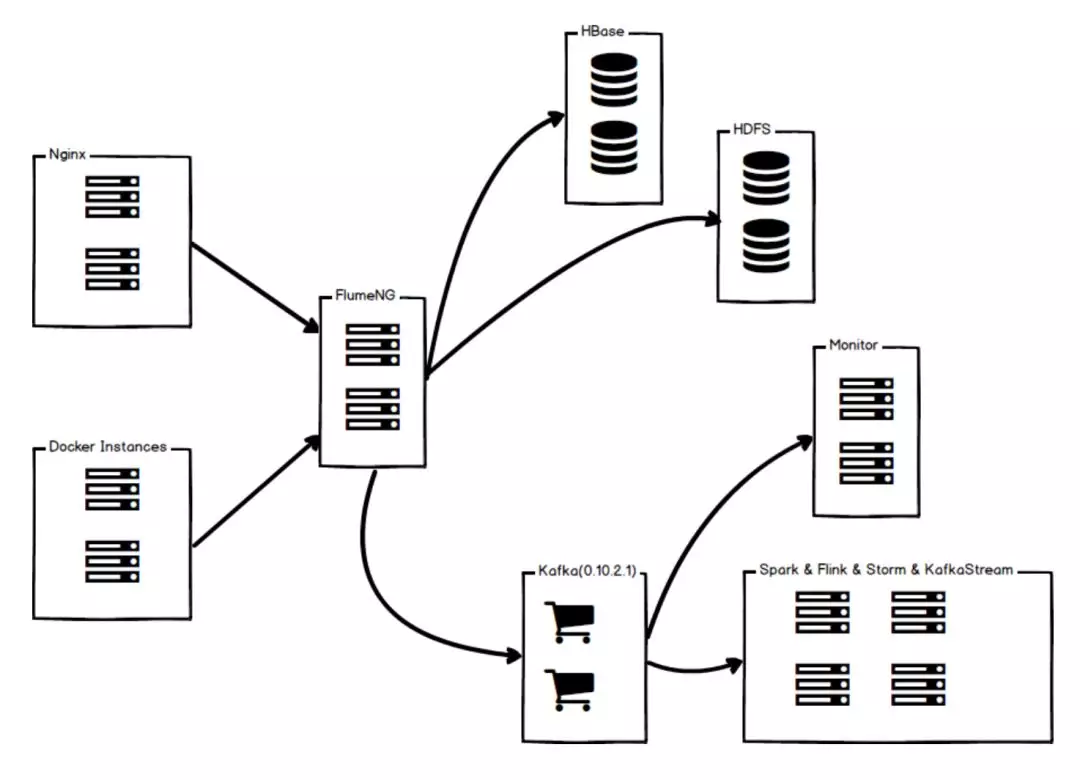
首先将传输实现从Kafka替换成FlumeNG 降低日志传输的成本 再将离线数据直接传输到HDFS、Hive、HBase 有实时计算需求的数据先通过FlumeNG过滤掉无用数据 再传输到Kafka給Flink、Spark使用
| 重构的技术选型
在不影响集群的迁移进度情况下,选择一个比较有群众基础的开源组件,也就是 FlumeNG 选择它主要有以下的原因:
-
插件支持、监控信息比较全
-
基于Java 开发,方便进行二次开发、定位问题
-
支持热部署 也支持基于 Zookeeper 实现的配置文件管理
| 解决旧版本的主要问题
-
使用 Spillable Memory Channel 实现高可用 在数据输入输出健康的情况下通过内存作为 Buffer 通信,一旦发生问题有本地大容量硬盘支撑
-
将大部分只有离线计算需求的数据从传输成本较高的 Kafka 集群中迁移出来再通过插件将有实时需求的数据输出到 Kafka 纯离线数据直接输出到 HDFS、Hive、HBase
-
通过拦截器将单一业务的日志分流到不同的输出目标,在这之前是接受端接收全部消息后自己过滤,既浪费网络 IO 又浪费 CPU
-
支持多种数据源,可以在不影响大部分业务的情况下将旧版本日志传输逐渐从 Kafka 慢慢替换成 Avro、Syslog 等实现
-
FlumeNG 节点本身无状态(除了本地没有来得及发出去的日志)复杂程度较 Kafka 要低许多 因此扩容、重启流程较 Kafka 要容易得多
开源的解决方案 不一定完全符合业务需求 所以基于FlumeNG 我们又进行了一些二次开发
| HDFS Sink 重写
社区原本的 HDFS Sink 为了“动态文件路径”这个需求做了很多妥协,比方说IdleTime 这个需求是为了节约因同时打开的 HDFS FD 过多而存在的,会自动释放近期没有写入事件的 FD, 而所有业务的日志输出高峰、低谷我们无法控制(比如行情)在收盘期间日志量较少,就会导致Idle事件频繁触发,使得文件碎片化。再者内部锁粒度较粗,也没有按照不同的 FD 做 Batch 并行推送数据,对 CPU 和网络 IO 有一定程度的浪费。
基于这些原因 对 HDFS Sink 进行了改造,根据 Timestamp 导致的路径变化来释放 FD 取消掉 IdleTime 检查,将锁粒度降低,将事件按照FD分组后实现批量更新 多个 FD 并行对 HDFS 发起请求。
| Logback Appender 的实现
FlumeNG 给 Log4j 开发了一套 Appender 遗憾的是没有 Logback 版本的实现只能自研,基础需求传输日志到 FlumeNG 要在保证业务方不会因为的 FlumeNG 的故障影响到正常服务的情况下实现 HA。
上一个版本在传输数据到 Kafka 之前,会将数据存储到 BDB 里,新版本则是在本地硬盘通过 WatchService 监听 IO 事件做的缓冲队列,性能要比BDB实现好一些。
| 写在最后
改造日志收集这个问题虽然说不是一个很难解决的问题,但是解决这个问题的思路是雪球的工程师团队一直以来的习惯:尽可能的多了解问题产生的原因,然后找到已经存在的解决方案了解他们的原理,最后根据我们的应用的特点有针对性的去选择和改进。换成其他的技术问题按照这样的思路也会得到最佳的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号