逃逸分析与栈、堆分配分析 escape_analysis escapes to heap moved to heap
实践:
1、
package main
func main() {
var a string = func() string {
return "a"
}()
var b string = "b"
f := func() string {
return "c"
}
f1 := func() string {
var d string
for i := 0; i < 65535; i++ {
for ii := 0; ii < 65535; ii++ {
d += "a"
}
}
return d
}
var c = f()
// var d = f1()
var d string
for i := 0; i < 65535; i++ {
for ii := 0; ii < 65535; ii++ {
d += "a"
}
}
var fe = func() *string {
s := "e"
return &s
}
var e *string = &d
var e1 *string = fe()
var e2 string = d
var e3 string = f1()
_, _, _, _, _, _, _, _ = a, b, c, d, e, e1, e2, e3
var s []int = make([]int, 0, 1)
var s1 []int = make([]int, 0, 65535)
var a1 [1]int = [1]int{}
var a2 [1048576]int = [1048576]int{} // 2**20
_, _, _, _ = s, s1, a1, a2
print()
}
go build -gcflags '-m -m -l' main.go
# command-line-arguments
.\main.go:38:21: make([]int, 0, 65535) escapes to heap:
.\main.go:38:21: flow: {heap} = &{storage for make([]int, 0, 65535)}:
.\main.go:38:21: from make([]int, 0, 65535) (too large for stack) at .\main.go:38:21
.\main.go:29:3: s escapes to heap:
.\main.go:29:3: flow: ~r0 = &s:
.\main.go:29:3: from &s (address-of) at .\main.go:30:10
.\main.go:29:3: from return &s (return) at .\main.go:30:3
.\main.go:29:3: moved to heap: s
.\main.go:4:17: func literal does not escape
.\main.go:38:21: make([]int, 0, 65535) escapes to heap:
.\main.go:38:21: flow: {heap} = &{storage for make([]int, 0, 65535)}:
.\main.go:38:21: from make([]int, 0, 65535) (too large for stack) at .\main.go:38:21
.\main.go:29:3: s escapes to heap:
.\main.go:29:3: flow: ~r0 = &s:
.\main.go:29:3: from &s (address-of) at .\main.go:30:10
.\main.go:29:3: from return &s (return) at .\main.go:30:3
.\main.go:29:3: moved to heap: s
.\main.go:4:17: func literal does not escape
.\main.go:8:7: func literal does not escape
.\main.go:11:8: func literal does not escape.\main.go:28:11: func literal does not escape
.\main.go:37:20: make([]int, 0, 1) does not escape
.\main.go:38:21: make([]int, 0, 65535) escapes to heap
疑问:
为什么 d,e2,a2没有逃逸?
小结:
1、当形参为 interface 类型时,在编译阶段编译器无法确定其具体的类型。因此会产生逃逸,最终分配到堆上。
2、The construction of a value doesn’t determine where it lives. Anytime you share a value up the call stack, it is going to escape.
3、
However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors.
Frequently Asked Questions (FAQ) - The Go Programming Language https://golang.org/doc/faq#stack_or_heap
How do I know whether a variable is allocated on the heap or the stack? ¶
From a correctness standpoint, you don't need to know. Each variable in Go exists as long as there are references to it. The storage location chosen by the implementation is irrelevant to the semantics of the language.
The storage location does have an effect on writing efficient programs. When possible, the Go compilers will allocate variables that are local to a function in that function's stack frame. However, if the compiler cannot prove that the variable is not referenced after the function returns, then the compiler must allocate the variable on the garbage-collected heap to avoid dangling pointer errors. Also, if a local variable is very large, it might make more sense to store it on the heap rather than the stack.
In the current compilers, if a variable has its address taken, that variable is a candidate for allocation on the heap. However, a basic escape analysis recognizes some cases when such variables will not live past the return from the function and can reside on the stack.
The construction of a value doesn’t determine where it lives. Only how a value is shared will determine what the compiler will do with that value. Anytime you share a value up the call stack, it is going to escape. There are other reasons for a value to escape which you will explore in the next post.
What these posts are trying to lead you to is guidelines for choosing value or pointer semantics for any given type. Each semantic comes with a benefit and cost. Value semantics keep values on the stack which reduces pressure on the GC. However, there are different copies of any given value that must be stored, tracked and maintained. Pointer semantics place values on the heap which can put pressure on the GC. However, they are efficient because there is only one value that needs to be stored, tracked and maintained. The key is using each semantic correctly, consistently and in balance.
golang 逃逸分析与栈、堆分配分析_惜暮-CSDN博客 https://louyuting.blog.csdn.net/article/details/102846449
我们在写 golang 代码时候定义变量,那么一个很常见的问题,申请的变量保存在哪里呢?栈?还是堆?会不会有一些特殊例子?这篇文章我们就来探索下具体的case以及如何做分析。
还是从实际使用场景出发:
Question
package main
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo() *User {
return &User{
ID: 666666,
Name: "sim lou",
Avatar: "https://www.baidu.com/avatar/666666",
}
}
func main() {
u := GetUserInfo()
println(u.Name)
}
这里GetUserInfo 函数里面的 User 对象是存储在函数栈上还是堆上?
什么是堆?什么是栈?
简单说:
- 堆:一般来讲是人为手动进行管理,手动申请、分配、释放。一般所涉及的内存大小并不定,一般会存放较大的对象。另外其分配相对慢,涉及到的指令动作也相对多
- 栈:由编译器进行管理,自动申请、分配、释放。一般不会太大,我们常见的函数参数(不同平台允许存放的数量不同),局部变量等等都会存放在栈上
今天我们介绍的 Go 语言,它的堆栈分配是通过 Compiler 进行分析,GC 去管理的,而对其的分析选择动作就是今天探讨的重点
逃逸分析
逃逸分析是一种确定指针动态范围的方法,简单来说就是分析在程序的哪些地方可以访问到该指针。
通俗地讲,逃逸分析就是确定一个变量要放堆上还是栈上,规则如下:
- 是否有在其他地方(非局部)被引用。只要有可能被引用了,那么它一定分配到堆上。否则分配到栈上
- 即使没有被外部引用,但对象过大,无法存放在栈区上。依然有可能分配到堆上
对此你可以理解为,逃逸分析是编译器用于决定变量分配到堆上还是栈上的一种行为。
在什么阶段确立逃逸
go 在编译阶段确立逃逸,注意并不是在运行时
为什么需要逃逸
其实就是为了尽可能在栈上分配内存,我们可以反过来想,如果变量都分配到堆上了会出现什么事情?例如:
- 垃圾回收(GC)的压力不断增大
- 申请、分配、回收内存的系统开销增大(相对于栈)
- 动态分配产生一定量的内存碎片
其实总的来说,就是频繁申请、分配堆内存是有一定 “代价” 的。会影响应用程序运行的效率,间接影响到整体系统。因此 “按需分配” 最大限度的灵活利用资源,才是正确的治理之道。这就是为什么需要逃逸分析的原因,你觉得呢?
go怎么确定是否逃逸
第一:编译器命令
可以看到详细的逃逸分析过程。而指令集 -gcflags 用于将标识参数传递给 Go 编译器,涉及如下:
- -m 会打印出逃逸分析的优化策略,实际上最多总共可以用 4 个 -m,但是信息量较大,一般用 1 个就可以了
- -l 会禁用函数内联,在这里禁用掉 inline 能更好的观察逃逸情况,减少干扰
$ go build -gcflags '-m -l' main.go
第二:反编译命令查看
$ go tool compile -S main.go
注:可以通过 go tool compile -help 查看所有允许传递给编译器的标识参数
实际案例
1.指针
package main
type User struct {
ID int64
Name string
Avatar string
}
func GetUserInfo() *User {
return &User{
ID: 666666,
Name: "sim lou",
Avatar: "https://www.baidu.com/avatar/666666",
}
}
func main() {
u := GetUserInfo()
println(u.Name)
}
看编译器命令执行结果:
$go build -gcflags '-m -l' escape_analysis.go
# command-line-arguments
./escape_analysis.go:13:11: &User literal escapes to heap
通过查看分析结果,可得知 &User 逃到了堆里,也就是分配到堆上了。这是不是有问题啊…再看看汇编代码确定一下,如下:
$go tool compile -S escape_analysis.go
"".GetUserInfo STEXT size=190 args=0x8 locals=0x18
0x0000 00000 (escape_analysis.go:9) TEXT "".GetUserInfo(SB), ABIInternal, $24-8
......
0x002c 00044 (escape_analysis.go:13) CALL runtime.newobject(SB)
......
0x0045 00069 (escape_analysis.go:12) CMPL runtime.writeBarrier(SB), $0
0x004c 00076 (escape_analysis.go:12) JNE 156
0x004e 00078 (escape_analysis.go:12) LEAQ go.string."sim lou"(SB), CX
......
0x0061 00097 (escape_analysis.go:13) CMPL runtime.writeBarrier(SB), $0
0x0068 00104 (escape_analysis.go:13) JNE 132
0x006a 00106 (escape_analysis.go:13) LEAQ go.string."https://www.baidu.com/avatar/666666"(SB), CX
......
执行了 runtime.newobject 方法,也就是确实是分配到了堆上。这是为什么呢?这是因为 GetUserInfo() 返回的是指针对象,引用被返回到了方法之外了。因此编译器会把该对象分配到堆上,而不是栈上。否则方法结束之后,局部变量就被回收了,岂不是翻车。所以最终分配到堆上是理所当然的。
那么所有的指针都在堆上?也不是:
func PrintStr() {
str := new(string)
*str = "hello world"
}
func main() {
PrintStr()
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
看编译器逃逸分析的结果:
$go build -gcflags '-m -l' escape_analysis3.go
# command-line-arguments
./escape_analysis3.go:4:12: PrintStr new(string) does not escape
- 1
- 2
- 3
看,该对象分配到栈上了。很核心的一点就是它有没有被作用域之外所引用,而这里作用域仍然保留在 main 中,因此它没有发生逃逸。
2. 不确定类型
func main() {
str := new(string)
*str = "hello world"
fmt.Println(*str)
}
- 1
- 2
- 3
- 4
- 5
执行命令观察一下,如下:
$go build -gcflags '-m -l' escape_analysis4.go
# command-line-arguments
./escape_analysis4.go:6:12: main new(string) does not escape
./escape_analysis4.go:8:13: main ... argument does not escape
./escape_analysis4.go:8:14: *str escapes to heap
- 1
- 2
- 3
- 4
- 5
通过查看分析结果,可得知 str 变量逃到了堆上,也就是该对象在堆上分配。但上个案例时它还在栈上,我们也就 fmt 输出了它而已。这…到底发生了什么事?
相对案例一,案例二只加了一行代码 fmt.Println(str),问题肯定出在它身上。其原型:func Println(a ...interface{}) (n int, err error)
通过对其分析,可得知当形参为 interface 类型时,在编译阶段编译器无法确定其具体的类型。因此会产生逃逸,最终分配到堆上。
如果你有兴趣追源码的话,可以看下内部的 reflect.TypeOf(arg).Kind() 语句,其会造成堆逃逸,而表象就是 interface 类型会导致该对象分配到堆上。
总结
- 静态分配到栈上,性能一定比动态分配到堆上好
- 底层分配到堆,还是栈。实际上对你来说是透明的,不需要过度关心
- 每个 Go 版本的逃逸分析都会有所不同(会改变,会优化)
- 直接通过 go build -gcflags ‘-m -l’ 就可以看到逃逸分析的过程和结果
- 到处都用指针传递并不一定是最好的,要用对。
Language Mechanics On Escape Analysis https://www.ardanlabs.com/blog/2017/05/language-mechanics-on-escape-analysis.html
https://mp.weixin.qq.com/s/58aqlX92ho0Z8KLrbURRfg
详解逃逸分析
Go是一门带有垃圾回收的现代语言,它抛弃了传统C/C++的开发者需要手动管理内存的方式,实现了内存的主动申请和释放的管理。Go的垃圾回收,让堆和栈的概念对程序员保持透明,它增加的逃逸分析与GC,使得程序员的双手真正地得到了解放,给了开发者更多的精力去关注软件设计本身。
就像《CPU缓存体系对Go程序的影响》文章中说过的一样,“你不一定需要成为一名硬件工程师,但是你确实需要了解硬件的工作原理”。Go虽然帮我们实现了内存的自动管理,我们仍然需要知道其内在原理。内存管理主要包括两个动作:分配与释放。逃逸分析就是服务于内存分配,为了更好理解逃逸分析,我们先谈一下堆栈。
堆和栈
应用程序的内存载体,我们可以简单地将其分为堆和栈。
在Go中,栈的内存是由编译器自动进行分配和释放,栈区往往存储着函数参数、局部变量和调用函数帧,它们随着函数的创建而分配,函数的退出而销毁。一个goroutine对应一个栈,栈是调用栈(call stack)的简称。一个栈通常又包含了许多栈帧(stack frame),它描述的是函数之间的调用关系,每一帧对应一次尚未返回的函数调用,它本身也是以栈形式存放数据。
举例:在一个goroutine里,函数A()正在调用函数B(),那么这个调用栈的内存布局示意图如下。
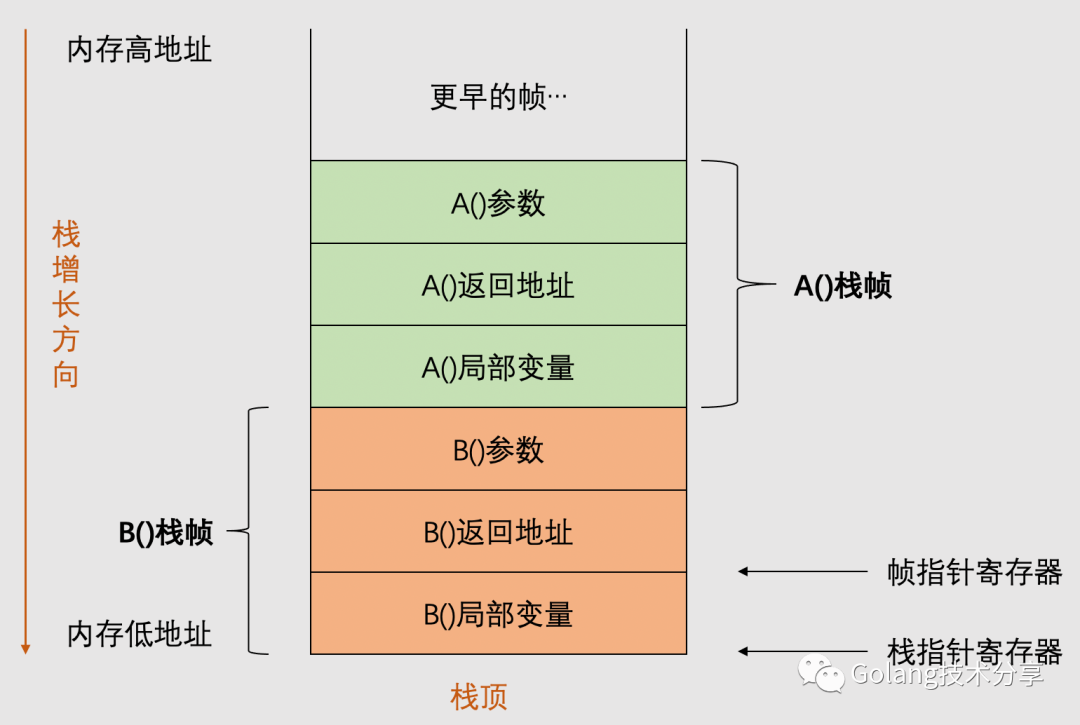
与栈不同的是,应用程序在运行时只会存在一个堆。狭隘地说,内存管理只是针对堆内存而言的。程序在运行期间可以主动从堆上申请内存,这些内存通过Go的内存分配器分配,并由垃圾收集器回收。
栈是每个goroutine独有的,这就意味着栈上的内存操作是不需要加锁的。而堆上的内存,有时需要加锁防止多线程冲突(为什么要说有时呢,因为Go的内存分配策略学习了TCMalloc的线程缓存思想,他为每个处理器P分配了一个mcache,从mcache分配内存也是无锁的)。
而且,对于程序堆上的内存回收,还需要通过标记清除阶段,例如Go采用的三色标记法。但是,在栈上的内存而言,它的分配与释放非常廉价。简单地说,它只需要两个CPU指令:一个是分配入栈,另外一个是栈内释放。而这,只需要借助于栈相关寄存器即可完成。
另外还有一点,栈内存能更好地利用CPU的缓存策略。因为它们相较于堆而言是更连续的。
逃逸分析
我们如何知道一个对象是应该放在堆内存,还是栈内存之上呢?可以官网的FAQ(地址:https://golang.org/doc/faq)中找到答案。

如果可以,Go编译器会尽可能将变量分配到到栈上。但是,当编译器无法证明函数返回后,该变量没有被引用,那么编译器就必须在堆上分配该变量,以此避免悬挂指针(dangling pointer)。另外,如果局部变量非常大,也会将其分配在堆上。
那么,Go是如何确定的呢?答案就是:逃逸分析。编译器通过逃逸分析技术去选择堆或者栈,逃逸分析的基本思想如下:检查变量的生命周期是否是完全可知的,如果通过检查,则可以在栈上分配。否则,就是所谓的逃逸,必须在堆上进行分配。
Go语言虽然没有明确说明逃逸分析规则,但是有以下几点准则,是可以参考的。
-
逃逸分析是在编译器完成的,这是不同于jvm的运行时逃逸分析;
-
如果变量在函数外部没有引用,则优先放到栈中;
-
如果变量在函数外部存在引用,则必定放在堆中;
我们可通过go build -gcflags '-m -l'命令来查看逃逸分析结果,其中-m 打印逃逸分析信息,-l禁止内联优化。下面,我们通过一些案例,来熟悉一些常见的逃逸情况。
情况一:变量类型不确定
1package main
2
3import "fmt"
4
5func main() {
6 a := 666
7 fmt.Println(a)
8}
逃逸分析结果如下
1 $ go build -gcflags '-m -l' main.go
2# command-line-arguments
3./main.go:7:13: ... argument does not escape
4./main.go:7:13: a escapes to heap
分析结果告诉我们变量a逃逸到了堆上。但是我们并没有外部引用,为什么也会有逃逸呢?为了看到更多细节,可以在语句中再添加一个-m参数。得到信息如下
1 $ go build -gcflags '-m -m -l' main.go
2# command-line-arguments
3./main.go:7:13: a escapes to heap:
4./main.go:7:13: flow: {storage for ... argument} = &{storage for a}:
5./main.go:7:13: from a (spill) at ./main.go:7:13
6./main.go:7:13: from ... argument (slice-literal-element) at ./main.go:7:13
7./main.go:7:13: flow: {heap} = {storage for ... argument}:
8./main.go:7:13: from ... argument (spill) at ./main.go:7:13
9./main.go:7:13: from fmt.Println(... argument...) (call parameter) at ./main.go:7:13
10./main.go:7:13: ... argument does not escape
11./main.go:7:13: a escapes to heap
a逃逸是因为它被传入了fmt.Println的参数中,这个方法参数自己发生了逃逸。
1func Println(a ...interface{}) (n int, err error)
2
因为fmt.Println的函数参数为interface类型,编译期不能确定其参数的具体类型,所以将其分配于堆上。
情况二:暴露给外部指针
1package main
2
3func foo() *int {
4 a := 666
5 return &a
6}
7
8func main() {
9 _ = foo()
10}
逃逸分析如下,变量a发生了逃逸。
1 $ go build -gcflags '-m -m -l' main.go
2# command-line-arguments
3./main.go:4:2: a escapes to heap:
4./main.go:4:2: flow: ~r0 = &a:
5./main.go:4:2: from &a (address-of) at ./main.go:5:9
6./main.go:4:2: from return &a (return) at ./main.go:5:2
7./main.go:4:2: moved to heap: a
这种情况直接满足我们上述中的原则:变量在函数外部存在引用。这个很好理解,因为当函数执行完毕,对应的栈帧就被销毁,但是引用已经被返回到函数之外。如果这时外部从引用地址取值,虽然地址还在,但是这块内存已经被释放回收了,这就是非法内存,问题可就大了。所以,很明显,这种情况必须分配到堆上。
情况三:变量所占内存较大
1func foo() {
2 s := make([]int, 10000, 10000)
3 for i := 0; i < len(s); i++ {
4 s[i] = i
5 }
6}
7
8func main() {
9 foo()
10}
逃逸分析结果
1$ go build -gcflags '-m -m -l' main.go
2# command-line-arguments
3./main.go:4:11: make([]int, 10000, 10000) escapes to heap:
4./main.go:4:11: flow: {heap} = &{storage for make([]int, 10000, 10000)}:
5./main.go:4:11: from make([]int, 10000, 10000) (too large for stack) at ./main.go:4:11
6./main.go:4:11: make([]int, 10000, 10000) escapes to heap
当我们创建了一个容量为10000的int类型的底层数组对象时,由于对象过大,它也会被分配到堆上。这里我们不禁要想一个问题,为啥大对象需要分配到堆上。
这里需要注意,在上文中没有说明的是:在Go中,执行用户代码的goroutine是一种用户态线程,其调用栈内存被称为用户栈,它其实也是从堆区分配的,但是我们仍然可以将其看作和系统栈一样的内存空间,它的分配和释放是通过编译器完成的。与其相对应的是系统栈,它的分配和释放是操作系统完成的。在GMP模型中,一个M对应一个系统栈(也称为M的g0栈),M上的多个goroutine会共享该系统栈。
不同平台上的系统栈最大限制不同。
1$ ulimit -s
28192
以x86_64架构为例,它的系统栈大小最大可为8Mb。我们常说的goroutine初始大小为2kb,其实说的是用户栈,它的最小和最大可以在runtime/stack.go中找到,分别是2KB和1GB。
1// The minimum size of stack used by Go code
2_StackMin = 2048
3...
4var maxstacksize uintptr = 1 << 20 // enough until runtime.main sets it for real
而堆则会大很多,从1.11之后,Go采用了稀疏的内存布局,在Linux的x86-64架构上运行时,整个堆区最大可以管理到256TB的内存。所以,为了不造成栈溢出和频繁的扩缩容,大的对象分配在堆上更加合理。那么,多大的对象会被分配到堆上呢。
通过测试,小菜刀发现该大小为64KB(这在Go内存分配中是属于大对象的范围:>32kb),即s :=make([]int, n, n)中,一旦n达到8192,就一定会逃逸。注意,网上有人通过fmt.Println(unsafe.Sizeof(s))得到s的大小为24字节,就误以为只需分配24个字节的内存,这是错误的,因为实际还有底层数组的内存需要分配。
情况四:变量大小不确定
我们将情况三种的示例,简单更改一下。
1package main
2
3func foo() {
4 n := 1
5 s := make([]int, n)
6 for i := 0; i < len(s); i++ {
7 s[i] = i
8 }
9}
10
11func main() {
12 foo()
13}
得到逃逸分析结果如下
1$ go build -gcflags '-m -m -l' main.go
2# command-line-arguments
3./main.go:5:11: make([]int, n) escapes to heap:
4./main.go:5:11: flow: {heap} = &{storage for make([]int, n)}:
5./main.go:5:11: from make([]int, n) (non-constant size) at ./main.go:5:11
6./main.go:5:11: make([]int, n) escapes to heap
这次,我们在make方法中,没有直接指定大小,而是填入了变量n,这时Go逃逸分析也会将其分配到堆区去。可见,为了保证内存的绝对安全,Go的编译器可能会将一些变量不合时宜地分配到堆上,但是因为这些对象最终也会被垃圾收集器处理,所以也能接受。
总结
本文只列举了逃逸分析的部分例子,实际的情况还有很多,理解思想最重要。这里就不过多列举了。
既然Go的堆栈分配对于开发者来说是透明的,编译器已经通过逃逸分析为对象选择好了分配方式。那么我们还可以从中获益什么?
答案是肯定的,理解逃逸分析一定能帮助我们写出更好的程序。知道变量分配在栈堆之上的差别,那么我们就要尽量写出分配在栈上的代码,堆上的变量变少了,可以减轻内存分配的开销,减小gc的压力,提高程序的运行速度。
所以,你会发现有些Go上线项目,它们在函数传参的时候,并没有传递结构体指针,而是直接传递的结构体。这个做法,虽然它需要值拷贝,但是这是在栈上完成的操作,开销远比变量逃逸后动态地在堆上分配内存少的多。当然该做法不是绝对的,如果结构体较大,传递指针将更合适。
因此,从GC的角度来看,指针传递是个双刃剑,需要谨慎使用,否则线上调优解决GC延时可能会让你崩溃。
https://mp.weixin.qq.com/s/iiBfxy_S3aFRuQew2ggdaA
Golang面试必问——内存逃逸分析
这个题是小编面试遇到次数最多的题目之一了。在开始之前,我们先思考以下几个问题,当然,后面小编也会一一解答。
1,什么是内存逃逸。
2,内存逃逸的场景有哪些。
3,分析内存逃逸的意义。
4,怎么避免内存逃逸。
什么是内存逃逸
在了解什么是内存逃逸之前,我们先来简单的熟悉一下两个概念。栈内存和堆内存。本次主要是讲述的是Golang的内存逃逸,故而关于内存分配和垃圾回收就不做赘述了。后面小编会单独出两篇来写这个,有需要的同学可以关注小编。关于这一块,我们现在只需要了解三点。
-
Golang的GC主要是针对堆的,不是栈。
-
引用类型的全局变量分配在堆上,值类型的全局变量分配在栈上。
-
局部变量内存分配可能在栈上也可能在堆上。
有了前面的基础知识,那我们简单粗暴的介绍一下内存逃逸。一个对象本应该分配在栈上面,结果分配在了堆上面,这就是内存逃逸。如下
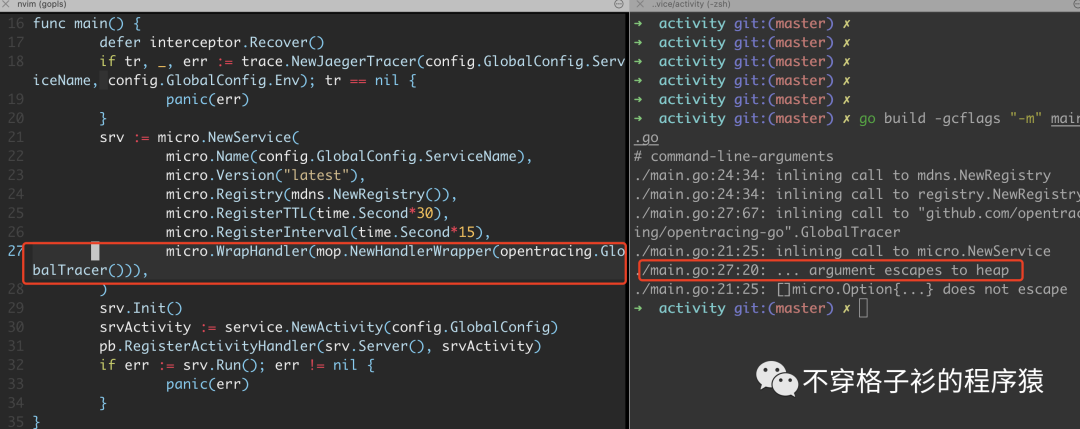
内存逃逸的场景有哪些
要了解内存逃逸的场景,首先我们要学会怎么分析内存逃逸。其实分析起来很简单,只需要一条简单的命令,即gcflags。这个是有很多参数的,此处只举一个最基本的例子。
go build -gcflags "-m" main.go接下来我们就来讨论一下内存逃逸的场景有哪些。常见的场景有四种,小编总结为:局部指针返回,栈空间不足,动态类型,闭包引用。
局部指针返回
当我们在某个方法内定义了一个局部指针,并且将这个指针作为返回值返回时,此时就发生了逃逸。这种类型的逃逸是比较常见的,如下。
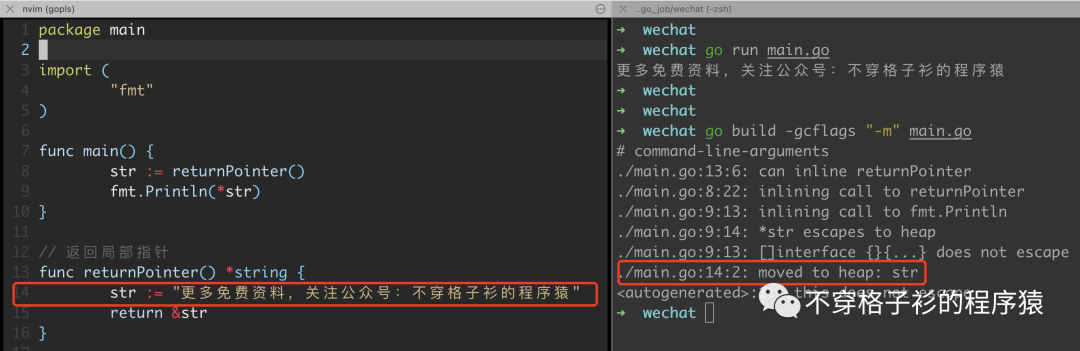
package mainimport ("fmt")func main() {str := returnPointer()fmt.Println(*str)}// 返回局部指针func returnPointer() *string {str := "更多免费资料,关注公众号:不穿格子衫的程序猿"return &str}
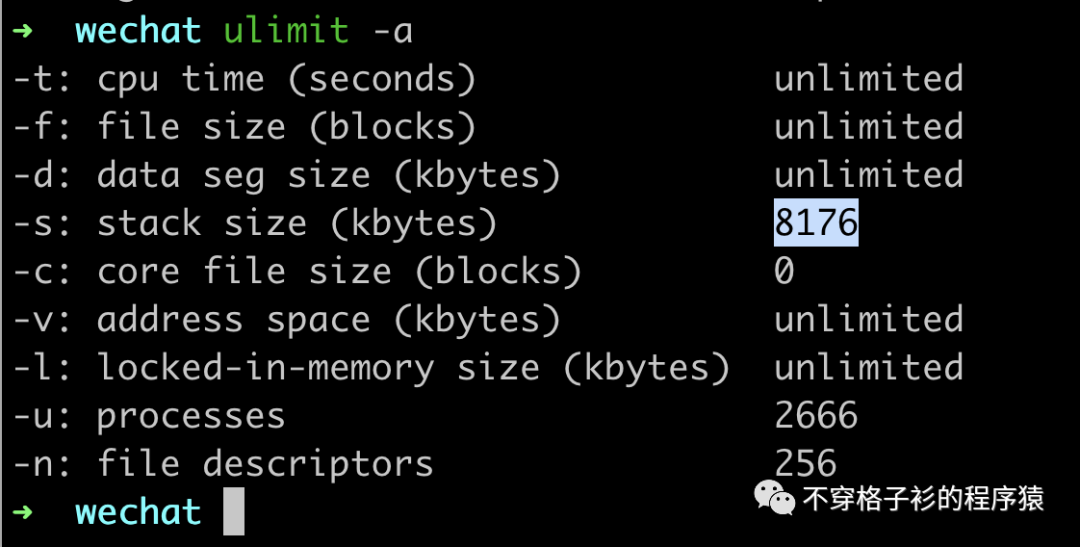
栈空间不足
众所周知,在系统中栈空间相比与总的内存来说是非常小的。如下,小编的Mac是16G*512G的,可是整个系统中栈空间大小也才8M。
而在我们的实际编码过程中,大部分Goroutine的占用空间不到10KB(这也是Golang能支持高并发的原因之一)。而其中分配给栈的更是少之又少。所以一旦某个对象体积过大时候就会发生逃逸,从栈上面转到堆上面。
如下,有两个map,space1和space2,space1长度大小都是100,space2长度大小都是10000,结果space2发生了逃逸,space1没有。
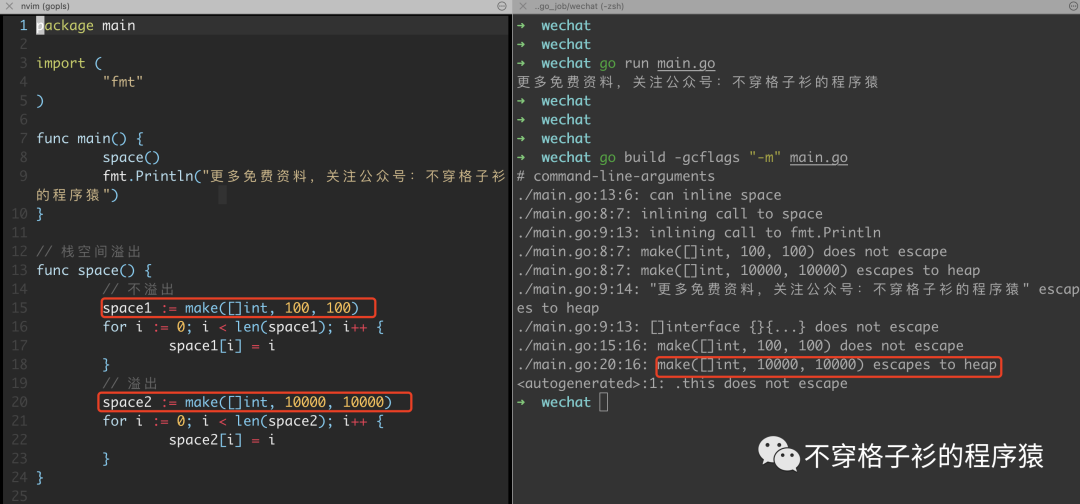
package mainimport ("fmt")func main() {space()fmt.Println("更多免费资料,关注公众号:不穿格子衫的程序猿")}// 栈空间溢出func space() {// 不溢出space1 := make([]int, 100, 100)for i := 0; i < len(space1); i++ {space1[i] = i}// 溢出space2 := make([]int, 10000, 10000)for i := 0; i < len(space2); i++ {space2[i] = i}}
动态类型
小编认为,这种内存逃逸应该是最多的,最常见的,而且还无法避免。简单的说就是被调用函数的入参是interface或者是不定参数,此时就会发生内存逃逸。如下:

package mainimport ("fmt")func main() {fmt.Println("关注公众号:不穿格子衫的程序猿")}
哈哈哈,同学们是不是大跌眼镜,一个简简单单的Println居然也会发生内存逃逸。那么问题来了,这个是怎么导致的呢,废话不多说,直接拔掉底裤撸源码。此处就是所谓的动态类型。

闭包调用
首先说一下,这种场景是非常少的,一般没有人写这种可读性这么差的代码,小编这串代码都是参考别人的。所以小编认为,这种场景,我们只需要知道即可,大概率是碰不上的。
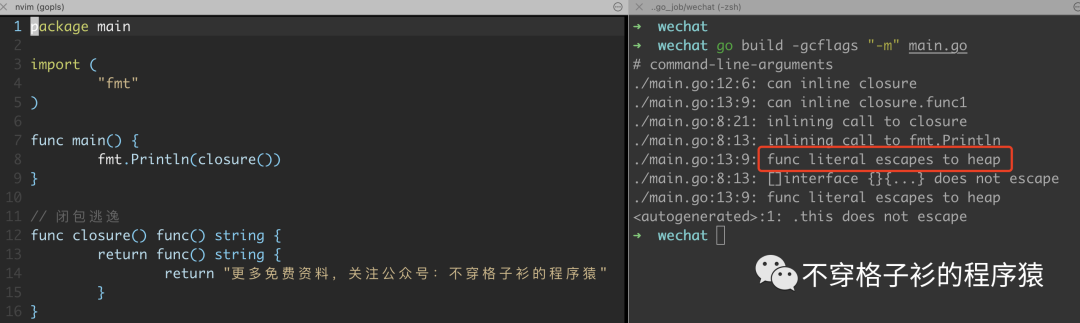
package mainimport ("fmt")func main() {fmt.Println(closure())}// 闭包逃逸func closure() func() string {return func() string {return "更多免费资料,关注公众号:不穿格子衫的程序猿"}}
分析内存逃逸的意义
前面给大家列举了四种内存逃逸的场景,那么问题来了,分析内存逃逸有什么用呢?简单的总结就是两点:减轻GC的压力,提高分配速度。
上文已经说过,Golang的GC主要是针对堆的,而不是栈。试想一下,如果大量的对象从栈逃逸到堆上,是不是就会增加GC的压力。在GC的过程中会占用比较大的系统开销(一般可达到CPU容量的25%)。而且目前所有的GC都有STW这个死结,而STW会造成用户直观的"卡顿"。非常影响用户体验。
此外,堆和栈相比,堆适合不可预知大小的内存分配。但是为此付出的代价是分配速度较慢,而且会形成内存碎片。栈内存分配则会非常快。栈分配内存只需要两个CPU指令:“PUSH”和“RELEASE”,分配和释放;而堆分配内存首先需要去找到一块大小合适的内存块,之后要通过垃圾回收才能释放。
通过逃逸分析,可以尽量把那些不需要分配到堆上的变量直接分配到栈上,堆上的变量少了,会减轻分配堆内存的开销,同时也会减少GC的压力,提高程序的运行速度。
怎么避免内存逃逸
最后说一下怎么避免内存逃逸吧。首先需要注意的是,Golang在编译的时候就可以确立逃逸,并不需要等到运行时。这样就给了咱们避免内存逃逸的机会。
首先咱们明确一点,小编认为没有任何方式能绝对避免内存逃逸。原因嘛,就是存在【动态类型】这种逃逸方式,几乎所有的库函数都是动态类型的。当然也不是说咱么要破罐子破摔,该避免还是要避免一下的,主要的原则有以下几种,分别针对上面几种场景。
-
尽量减少外部指针引用,必要的时候可以使用值传递。
-
对于自己定义的数据大小,有一个基本的预判,尽量不要出现栈空间溢出的情况。
-
Golang中的接口类型的方法调用是动态调度,如果对于性能要求比较高且访问频次比较高的函数调用,应该尽量避免使用接口类型。
-
尽量不要写闭包函数,可读性差还逃逸。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号