go/wiki/MutexOrChannel Golang并发:选channel还是选锁?
https://mp.weixin.qq.com/s/JcED2qgJEj8LaBckVZBhDA
https://github.com/golang/go/wiki/MutexOrChannel
Use a sync.Mutex or a channel?
One of Go's mottos is "Share memory by communicating, don't communicate by sharing memory."
That said, Go does provide traditional locking mechanisms in the sync package. Most locking issues can be solved using either channels or traditional locks.
So which should you use?
Use whichever is most expressive and/or most simple.
A common Go newbie mistake is to over-use channels and goroutines just because it's possible, and/or because it's fun. Don't be afraid to use a sync.Mutex if that fits your problem best. Go is pragmatic in letting you use the tools that solve your problem best and not forcing you into one style of code.
As a general guide, though:
| Channel | Mutex |
|---|---|
| passing ownership of data, distributing units of work, communicating async results |
caches, state |
If you ever find your sync.Mutex locking rules are getting too complex, ask yourself whether using channel(s) might be simpler.
Wait Group
Another important synchronisation primitive is sync.WaitGroup. These allow co-operating goroutines to collectively wait for a threshold event before proceeding independently again. This is useful typically in two cases.
Firstly, when 'cleaning up', a sync.WaitGroup can be used to ensure that all goroutines - including the main one - wait before all terminating cleanly.
The second more general case is of a cyclic algorithm that involves a set of goroutines that all work independently for a while, then all wait on a barrier, before proceeding independently again. This pattern might be repeated many times. Data might be exchanged at the barrier event. This strategy is the basis of Bulk Synchronous Parallelism (BSP).
Channel communication, mutexes and wait-groups are complementary and can be combined.
More Info
- Channels in Effective Go: http://golang.org/doc/effective_go.html#channels
- The sync package: http://golang.org/pkg/sync/
末又到了,为大家准备了一份实用干货:如何使用channel和Mutex解决并发问题,利用周末的好时光,配上音乐,思考一下吧🤔。
来,问自己个问题:面对并发问题,是用channel解决,还是用Mutex解决?
如果自己心里还没有清晰的答案,那就读下这篇文章,你会了解到:
-
使用channel解决并发问题的核心思路和示例
-
channel擅长解决什么样的并发问题,Mutex擅长解决什么样的并发问题
-
一个并发问题该怎么入手解解决
-
一个重要的plus思维
前戏
前面很多篇的文章都在围绕channel介绍,而只有前一篇sync的文章介绍到了Mutex,不是我偏心,而是channel在Golang是first class级别的,设计在语言特性中的,而Mutex只是一个包中的。这就注定了一个是主角,一个是配角。
并且Golang还有一个并发座右铭,在《Effective Go》的channel介绍中写到:
Share memory by communicating, don't communicate by sharing memory.
通过通信共享内存,而不是通过共享内存而通信。
Golang以如此明显的方式告诉我们:面对并发问题,你首先想到的应该是channel,因为channel是线程安全的并且不会有数据冲突,比锁好用多了。
既生瑜,何生亮。既然有channel了,为啥还提供sync.Mutex呢?
主角不是万能的,他也需要配角。在Golang里,channel也不是万能的,这是由channel的特性和局限造成的。
下面就给大家介绍channel的特点、核心方法和缺点。
channel解决并发问题的思路和示例
channel的核心是数据流动,关注到并发问题中的数据流动,把流动的数据放到channel中,就能使用channel解决这个并发问题。这个思路是从Go语言的核心开发者的演讲中学来的,然而视频我已经找不到了,不然直接共享给大家,他提到了Golang并发的核心实践的4个点:
DataFlow -> Drawing -> Pipieline -> Exiting
DataFlow指数据流动,Drawing指把数据流动画出来,Pipeline指的是流水线,Exit指协程的退出。DataFlow + Drawing就是我提到到channel解决并发问题的思路,Pipeline和Exit是具体的实践模式,Pipeline和Exit我都写过文章,有需要自取:
下面我使用例子具体解释DataFlow + Drawing。借用《Golang并发的次优选择:sync包》中银行的例子,介绍如何使用channel解决例子中银行的并发问题:银行支持多个用户的同时操作。顺便看下同一个并发问题,使用channel和Mutex解决是什么差别。
一起分析下多个用户同时操作银行的数据流动:
-
每个人都可以向银行发起请求,请求可以是存、取、查3种操作,并且包含操作时必要的数据,包含的数据只和自身相关。
-
银行处理请求后给用户发送响应,包含的数据只和操作用户相关。
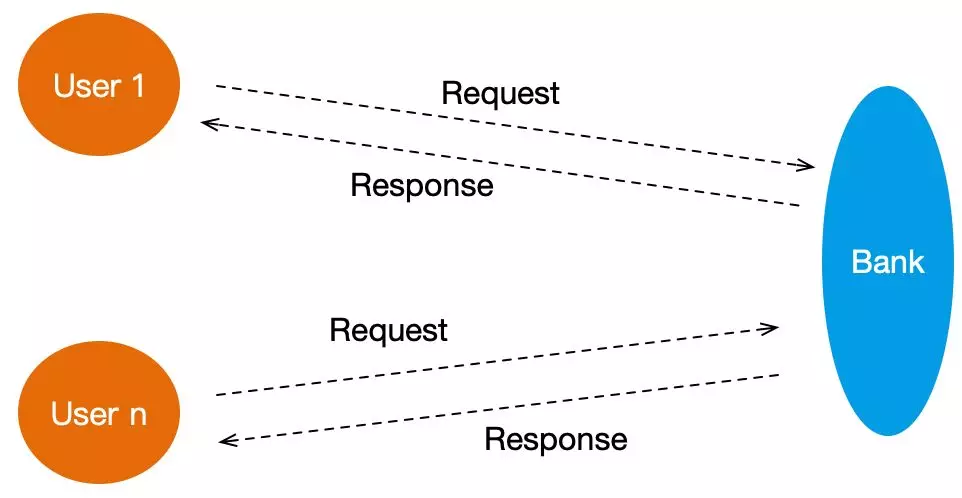
你一定发现了上面的数据流动:
-
请求数据:个人请求数据流向银行。
-
响应数据:银行处理结果数据流向用户。
channel是数据流动的通道/管道,为流动的数据建立通道,这里需要建立2类channel:
-
reqCh:传送请求的channel,把请求从个人发送给银行。
-
retCh:传送响应的channel,把响应从银行发给个人。
我们把channel添加到上图中,得到下面的图:

以上就是从数据流动的角度,发现如何使用channel解决并发问题。思路有了,再思考下代码层面需要怎么做:
-
银行:
-
定义银行,只保存1个map即可
-
银行操作:接收和解析请求,并把请求分发给存、取、查函数
-
实现存、取、查函数:处理请求,并把结果写入到用户提供的响应通道
-
定义请求和响应
-
用户:创建请求和接收响应的通道,发送请求后等待响应,提取响应结果
-
mian函数:创建银行和用户间的请求通道,创建银行、用户等协程,并等待操作完成
以上,我们这个并发问题的逻辑实现和各块工作就清晰了,写起来也方便、简单。代码实现有200多行,公众号不方便查看,可以点阅读原文,一键直达。
代码不能贴了,运行结果还是可以的,为了方便理解结果,介绍下示例代码做了什么。main函数创建了银行、小明、小刚3个并发协程:
-
银行:从
reqCh接收请求,依次处理每个请求,直到通道关闭,把请求交给处理函数,处理函数把结果写入到请求中的retCh。 -
用户小明:创建了存100、取20、查余额的3个请求,每个请求得到响应后,再把下一个请求写入到
reqCh。 -
用户小刚:流程和小明相同,但存100取200,造成取钱操作失败,他查询下自己又多少钱,得到100。
main函数最后使用WaitGroup等待小明、小刚结束后退出。
下面是运行结果:
1$ go run channel_map.go
2xiaogang deposite 100 success
3xiaoming deposite 100 success
4xiaogang withdraw 200 failed
5xiaoming withdraw 20 success
6xiaogang has 100
7xiaoming has 80
8Bank exit
这一遭搞完,发现啥没有?用Mutex直接加锁、解锁完事了,但channel搞出来一坨,是不是用channel解决这个问题不太适合?是的。对于当前这个问题,和Mutex的方案相比,channel的方案显的有点“重”,不够简洁、高效、易用。
但这个例子展示了3点:
-
使用channel解决并发问题的核心在于关注数据的流动
-
channel不一定是某个并发问题最好的解决方案
-
map在并发中,可以不用锁进行保护,而是使用channel
现在,回到了开篇的问题:同一个并发问题,你是用channel解决,还是用mutex解决?下面,一起看看怎么选择。
channel和mutex的选择
面对一个并发问题的时候,应当选择合适的并发方式:channel还是mutex。选择的依据是他们的能力/特性:channel的能力是让数据流动起来,擅长的是数据流动的场景,《Channel or Mutex》中给了3个数据流动的场景:
-
传递数据的所有权,即把某个数据发送给其他协程
-
分发任务,每个任务都是一个数据
-
交流异步结果,结果是一个数据
mutex的能力是数据不动,某段时间只给一个协程访问数据的权限擅长数据位置固定的场景,《Channel or Mutex》中给了2个数据不动场景:
-
缓存
-
状态,我们银行例子中的
map就是一种状态
提供解决并发问题的一个思路:
-
先找到数据的流动,并且还要画出来,数据流动的路径换成channel,channel的两端设计成协程
-
基于画出来的图设计简要的channel方案,代码需要做什么
-
这个方案是不是有点复杂,是不是用Mutex更好一点?设计一个简要的Mutex方案,对比&选择易做的、高效的
channel + mutex思维
面对并发问题,除了channel or mutex,你还有另外一个选择:channel plus mutex。
一个大并发问题,可以分解成很多小的并发问题,每个小的并发都可以单独选型:channel or mutex。但对于整个大的问题,通常不是channel or mutex,而是channel plus mutex。
如果你是认为是channel and mutex也行,但我更喜欢plus,体现相互配合。
总结
读到这里,感觉这篇文章头重脚轻,channel的讲了很多,而channel和mutex的选择却讲的很少。在channel和mutex的选择,实际并没有一个固定答案,也没有固定的方法,但提供了一个简单的思路:设计出channel和Mutex的简单方案,然后选择最适合当前业务、问题的那个。
思考比结论更重要,希望你有所收获:
-
关注数据的流动,就可以使用channel解决并发问题。
-
不流动的数据,如果存在并发访问,尝试使用sync.Mutex保护数据。
-
channel不一定某个并发问题的最优解。
-
不要害怕、拒绝使用mutex,如果mutex是问题的最优解,那就大胆使用。
-
对于大问题,channel plus mutex也许才是更好的方案。
参考资料
-
《Effective Go》,https://golang.org/doc/effective_go.html#sharing
-
《Mutex Or Channel》,https://github.com/golang/go/wiki/MutexOrChannel
文章推荐
致歉
上一篇文章《Golang并发的次优选择:sync包》,WaitGroup用在worker pool上的示例代码贴错了,非常抱歉,以后写完文章后,加强校审,为大家提供高质量的文章。
下面是WaitGroup用在worker pool上正确的示例代码。
1func workerPool(n int, jobCh <-chan int, retCh chan<- string) {
2 var wg sync.WaitGroup
3 wg.Add(n)
4 for i := 0; i < n; i++ {
5 go worker(&wg, i, jobCh, retCh)
6 }
7
8 wg.Wait()
9 close(retCh)
10}
11
12func worker(wg *sync.WaitGroup, id int, jobCh <-chan int, retCh chan<- string) {
13 cnt := 0
14 for job := range jobCh {
15 cnt++
16 ret := fmt.Sprintf("worker %d processed job: %d, it's the %dth processed by me.", id, job, cnt)
17 retCh <- ret
18 }
19
20 wg.Done()
21}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号