爱奇艺直播 - 春晚直播业务API架构
小结:
1、服务熔断策略
在网关服务中经常会对后端不同api接口做服务聚合,比如A服务 -> B服务 -> C服务 ,如果C服务出现问题,那么在调用C服务之前需要做熔断。而在设计熔断器的时候主要实现了以下三个状态:
|
状态 |
具体策略 |
|
Closed |
熔断器关闭状态,如果服务调用失败,则使失败次数加1,失败次数到了一定阈值或者一定比例,则启动熔断机制。 |
|
Open |
熔断器打开状态,在该状态下会对出错的服务请求立即返回错误响应,同时设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态。 |
|
Half-Open |
允许定量的服务请求,如果调用在一定比例上都成功了则认为已恢复,关闭熔断器(重置失败次数),否则打开熔断器。 |
2、提高单机并发承载能力
一级缓存local cache+二级分布式缓存Redis
解决数据一致性的问题:
利用Redis Pub/Sub(发布/订阅)的特性以及设计合理的Redis key 来避免以上问题。
每个业务机上有个后台线程订阅redis消息,如果计算中心更新Redis成功会publish消息,后台线程收到Redis的消息会更新当前本地缓存,保证每次更新数据时用户看到的数据都是相同的。
https://mp.weixin.qq.com/s/qts9huG0V91AfhRN4cts0Q
干货|爱奇艺直播 - 春晚直播业务API架构
导读
家人团聚共赏春晚,已经成为国人欢度春节必不可少的庆祝方式。如今,爱奇艺春晚直播,成为千千万万家庭同享这份欢乐的新途径。根据以往的统计数据,春晚期间爱奇艺的访问量是平时的数倍甚至是数十倍,不亚于12306春节抢票的“盛况”,这也给系统带来了前所未有的访问压力。我们在2019年直播中加入了个性化节目和互动元素,接口复杂度更高,团队重点任务则是保障直播间信息、直播互动等后端直播内容流畅响应。除了春晚直播,像明星演唱会、综艺节目等大型直播也是我们重点服务对象。简而言之我们团队提供的是大型直播业务API服务,我们简称“QLive”。
大型直播往往带来的就是大流量和高并发,而我们的“QLive”也经受住了多次业务洪峰的洗礼和考验,下面是我们团队经历过的一些大型直播。

在春晚这种高并发的场景下,对“QLive”伸缩扩容和高可用具有较高的要求。而在互联网分布式架构设计中,为了提高系统并发能力主要有两种方法论:
方法/实施策略/优点/缺点
垂直扩展/提升单机并发处理能力/节省机器采购成本/单机性能有极限
水平拓展/增加对应业务机或者存储的服务器数量/机器资源足够的话能线性提升并发能力/有一定的机器采购成本
我们综合考虑了这两种方法,设计了多级缓存策略提升接口响应速度同时也提高了单机承载并发的上限,在应用层部署了双机房从而线性增加了整个服务的并发承载能力。经过线上压测,“QLive”目前承载40万+的qps。
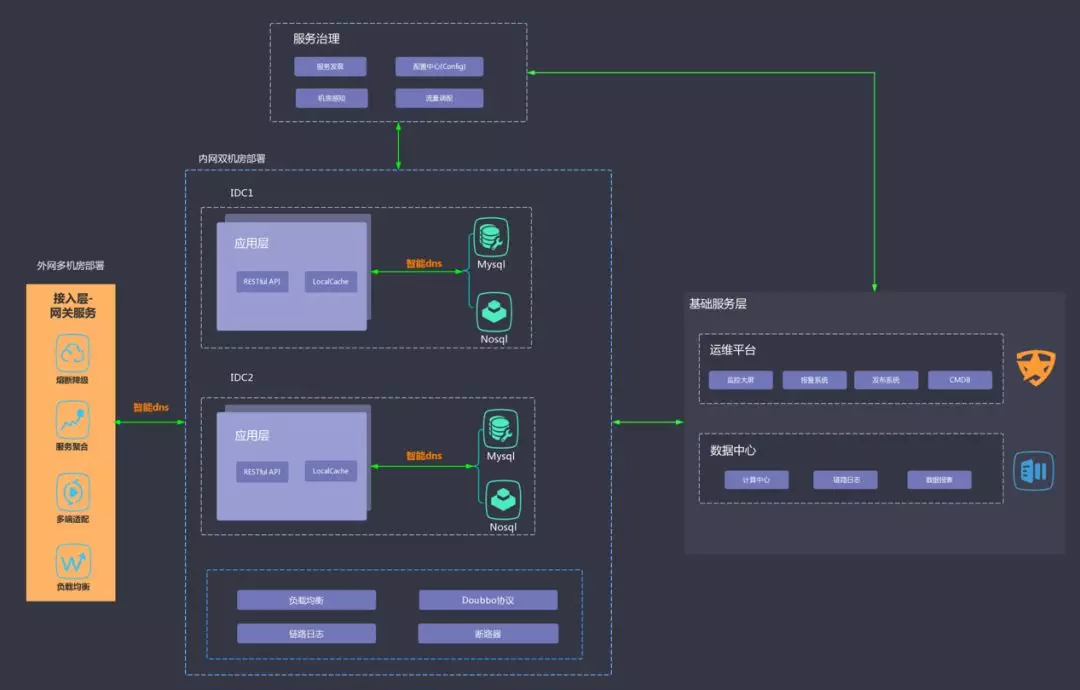
接下来具体看下“QLive”的整体架构,整体上分成三层:
1. 接入层(业务中台):
主要扮演的角色是负载均衡、降级、业务封装、避免复杂性扩散,而且考虑到接入层位置的特殊性(物理上最接近用户),我们部署了外网多机房,主要有以下两个明显的作用:
· 让不同运营商的用户以最短路径接入系统。
· 避免由于部分主干网络故障导致的单点故障。
2.应用层(双机房架构):
实现了机房隔离、服务隔离、热点隔离等策略,提高了集群可用性和水平扩展的灵活性。
3.基础服务层:
运维平台
· 监控报警:通过分钟级报警感知、多维度监控图表做到业务提前预警和故障快速定位。
· CMDB:资源管理、依赖管理、流程规范。
· 发布系统:管理代码上线、审计、回滚等功能。
数据中心
· 计算中心:基于Quartz的分布式任务调度系统,异步处理数据量大或者耗时长的业务。
· Trace链路日志:Agent无侵入式部署、快速定位代码性能问题、可追溯的性能数据。
· 数据中心:前端PingBack、收集外网用户故障形成闭环、实时生成数据报表。
接入层—业务中台
接入层主要有两部分组成:网关服务、业务中台。为了防止系统过载,在接入网关服务中加入了熔断降级的策略,保证在极端情况下部分核心服务是可用的。
首先我们需要明确熔断和降级这两种概念:服务熔断一般是某个下游服务故障引起的;服务降级是整体服务压力过大需要保护核心业务采取的一些降级策略。
服务熔断:
在网关服务中经常会对后端不同api接口做服务聚合,比如A服务 -> B服务 -> C服务 ,如果C服务出现问题,那么在调用C服务之前需要做熔断。而在设计熔断器的时候主要实现了以下三个状态:
状态
具体策略
Closed
熔断器关闭状态,如果服务调用失败,则使失败次数加1,失败次数到了一定阈值或者一定比例,则启动熔断机制。
Open
熔断器打开状态,在该状态下会对出错的服务请求立即返回错误响应,同时设计了一个时钟选项,默认的时钟达到了一定时间(这个时间一般设置成平均故障处理时间,也就是MTTR),到了这个时间,进入半熔断状态。
Half-Open
允许定量的服务请求,如果调用在一定比例上都成功了则认为已恢复,关闭熔断器(重置失败次数),否则打开熔断器。
服务降级:
我们主要使用了自动开关降级、人工开关降级这两种策略。
· 自动开关降级:根据系统负载、整体超时率、失败次数等指标选择对次要功能(比如视频播放次数)做降级,降级后的处理方案有返回默认值、兜底数据、缓存等方案。
· 人工开关降级:通过监控报警发现线上一些服务存在问题,这个时候需要暂时将有问题的服务摘掉,比如某个缓存节点异常读取不到数据 ;如果发现某些写的服务调用量太大,如果不是强实时性,同步写的方式可以改成异步缓解存储压力。
应用层—双机房架构
双机房的主要技术挑战是机房间的延时、数据同步的问题。
1.机房延时问题:A城市的两个核心机房延时大概在1ms内,但是A城市到B城市则可能有近30ms的延时,如果应用依赖的服务都跨机房访问那么性能会惨不忍睹。
2.数据同步问题:如果MySQL、Redis等数据存储需要做不同机房的数据同步,如果有几十毫秒的延时,整个数据同步是非常大的挑战。
3.解决方案:
· 同城机房部署,机房延时可以忽略不计。
· 机房隔离,服务和服务之间,服务和资源之间使用智能DNS连接,尽量保证服务不跨机房调用。
应用层—多级缓存
为了提高单机并发承载能力,我们设计了多级缓存架构,最终线上服务端核心接口平均响应耗时在10ms内。
· 主要技术挑战:不同缓存之间数据一致性问题。
· 缓存中间件:一级缓存local cache+二级分布式缓存Redis。
· 解决数据一致性的问题:利用Redis Pub/Sub(发布/订阅)的特性以及设计合理的Redis key 来避免以上问题。每个业务机上有个后台线程订阅redis消息,如果计算中心更新Redis成功会publish消息,后台线程收到Redis的消息会更新当前本地缓存,保证每次更新数据时用户看到的数据都是相同的。
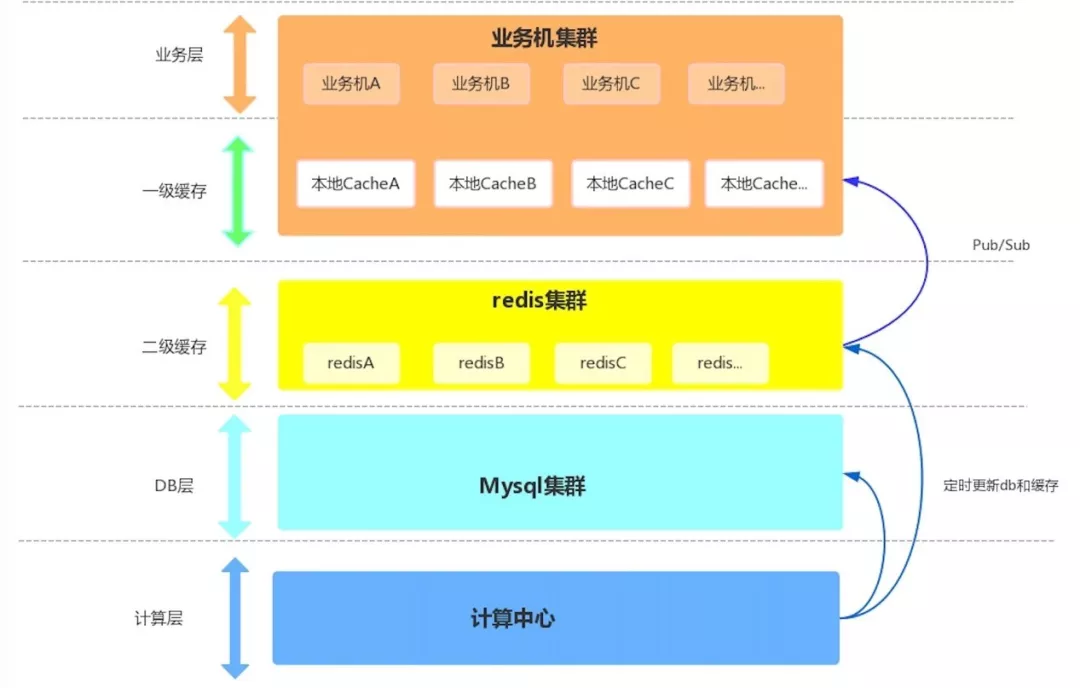
· 代理层缓存:用户访问量很多时候是无法预期的,机器数量不变的情况下,如何性能最大化是我们经常思考的问题。上图可以看出主要并发压力来自业务WebServer,直播节目有个特性,直播节目信息、流地址不会发生变化,通常只有在开播状态变更和直播结束时间延后会更改直播信息。在实际实践过程中发现,可以将核心节目接口功能上移到Nginx层,只有在配置中心加入缓存头的节目才会进行动态文件的缓存,保证缓存量控制极少的量,这样可以利用Nginx缓存文件优势,结合自身业务系统的特点,让静态缓存的灵活性和效率都能得到保障。

基础服务层—监控大屏
监控大屏主要分数据采集和图表展示,数据采集流程如下:
· flume Agent收集采集Nginx的访问日志。
· 多个Agent数据汇聚到同一个Agent。
· Kafka作为消息通道将数据存储到Hive。
· 通过大数据平台(babel)将不同纬度的数据汇总到业务mysql数据库中。
· 监控大屏最终展示汇总数据。

展望
以上是爱奇艺直播团队在大型直播场景下应对大流量高并发的一些思考,整个系统也经过了多次大型直播的考验,始终保持在低故障率,可用性做到了99.9999%。除了应对高流量,如何降低访问链路、加快业务方对接、直播组件化也是目前探索的方向。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号