消息规模超千亿,同程艺龙的消息系统建设实践
小结:
1、
/1/退订请求入库--->消息队列异步--->调用供应商对接系统
调用
成功--->标识数据库
失败--->补偿脚本--->重新调用
我们引入RocketMQ将同步改为异步,当前端用户发出退订需求,退订系统接收到请求后就会记录到退订系统的数据库里面,表示这个用户正在退订,同时通过消息引擎把这条退订消息发送到和供应商对接的系统,去调用供应商的接口。
如果调用成功,就会把数据库进行标识,表示已经退订成功。同时,加了一个补偿的脚本,去数据库捞那些未退订成功的消息,重新退订,避免消息丢失引起的退订失败的情况。
2、
同一Group和同一Topic下,一个是消费Tag1的数据,另一个是消费Tag2的数据。
正常情况下,启动应该是没问题的,但是有一天我们发现一个应用起不来了,另外一个应用,因为他只消费Tag2的数据,但是因为RocketMQ的机制会把Tag1的数据拿过来,拿过来过后会把Tag1的数据丢弃。
3、
对于大量老数据读取的改进方式是
- > 对于新消费组,默认从LAST_OFFSET消费而不是初始默认的0;
- > Broker中单Topic堆积超过1000万时,禁止消费,需联系管理员开启消费;
https://mp.weixin.qq.com/s/Uj0lirsq0zyCIb8AlEoNBg
消息规模超千亿,同程艺龙的消息系统建设实践
导读:
同程艺龙的机票、火车票、汽车票、酒店相关业务已经接入了RocketMQ,用于流量高峰时候的削峰,以减少后端的压力。同时,对常规的系统进行解耦,将一些同步处理改成异步处理,每天处理的数据达1500亿条。
在近期的Apache RockeMQ Meetup上,同程艺龙机票事业部架构师查江,分享了同程艺龙的消息系统如何应对每天1500亿条的数据处理,通过此文,您将了解到:
-
同程艺龙在消息方面的使用情况;
-
消息在同程艺龙的应用场景;
-
技术上踩过哪些坑;
-
基于RocketMQ,做了哪些改进;
同程艺龙在消息方面的使用情况
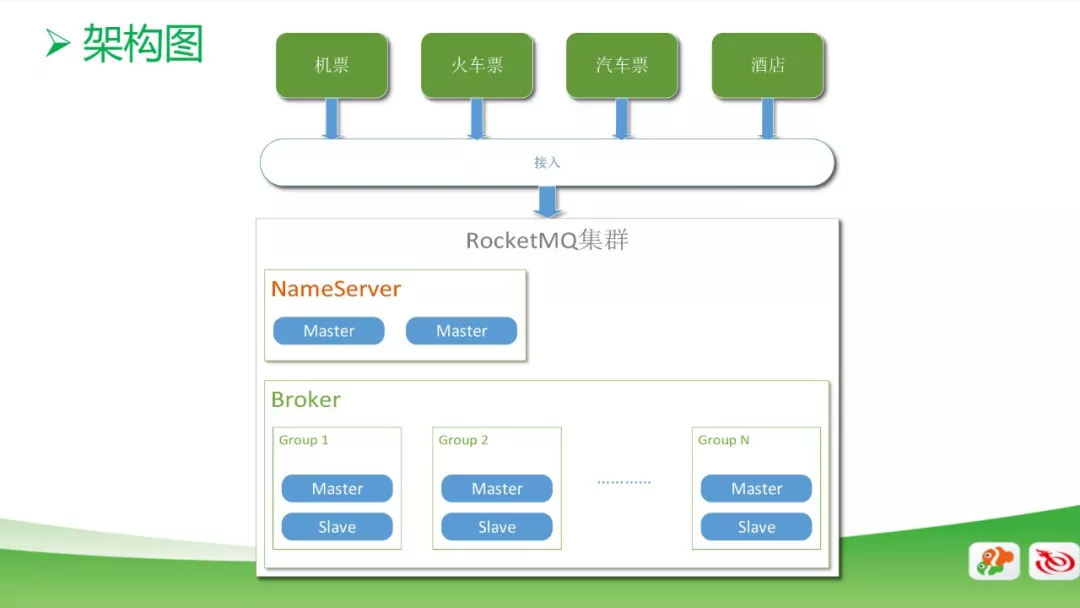
虑性能,另一个考虑安全性。 在纯数据的Broker分成很多组,每个组里面分为Master和Slave。目前,我们的机票、火车票、汽车票、酒店相关业务已经接入了RocketMQ,用于流量高峰时候的削峰,以减少后端的压力。同时,对常规的系统进行解耦,将一些同步处理改成异步处理,每天处理的数据达1500亿条。
选择RocketMQ的原因是:
-
接入简单,引入的Java包比较少;
-
纯Java开发,设计逻辑比较清晰;
-
整体性能比较稳定的,Topic数量大的情况下,可以保持性能;
消息在同程艺龙的应用场景
退订系统
这个是我们退订系统中的一个应用场景。用户点击前端的退订按钮,系统调用退订接口,再去调用供应商的退订接口,从而完成一个退订功能。
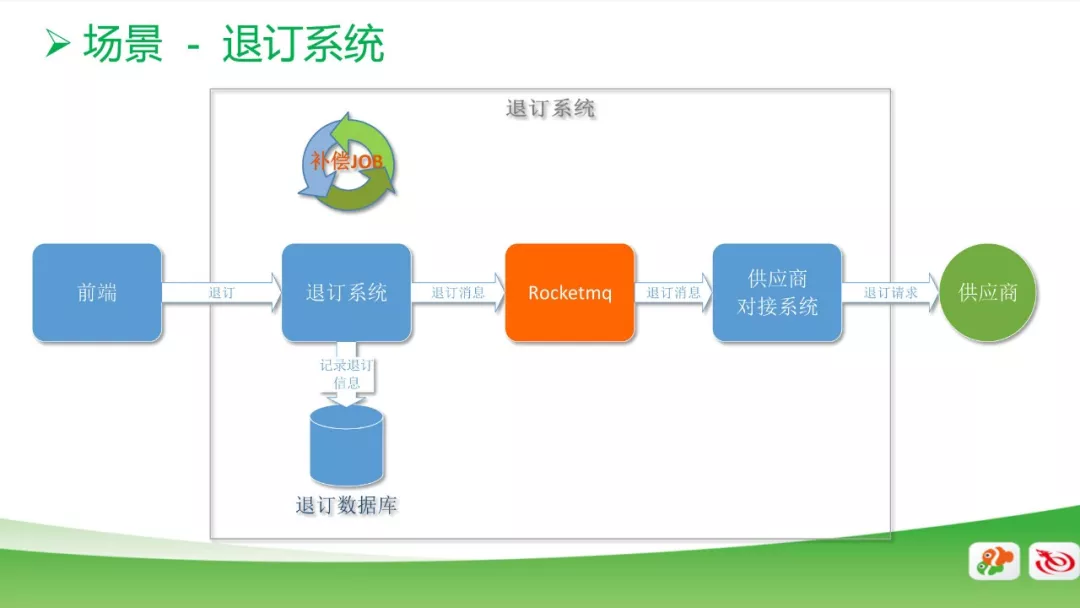
如果供应商的系统接口不可靠,就会导致用户退订失败,如果系统设置为同步操作,会导致用户需要再去点一次。所以,我们引入RocketMQ将同步改为异步,当前端用户发出退订需求,退订系统接收到请求后就会记录到退订系统的数据库里面,表示这个用户正在退订,同时通过消息引擎把这条退订消息发送到和供应商对接的系统,去调用供应商的接口。
如果调用成功,就会把数据库进行标识,表示已经退订成功。同时,加了一个补偿的脚本,去数据库捞那些未退订成功的消息,重新退订,避免消息丢失引起的退订失败的情况。
房仓系统
第二个应用场景是我们的房仓系统。这是一个比较常规的消息使用场景,我们从供应商处采集一些酒店的基本信息数据和详情数据,然后接入到消息系统,由后端的分销系统、最小价系统和库存系统来进行计算。同时当供应商有变价的时候,变价事件也会通过消息系统传递给我们的后端业务系统,来保证数据的实时性和准确性。

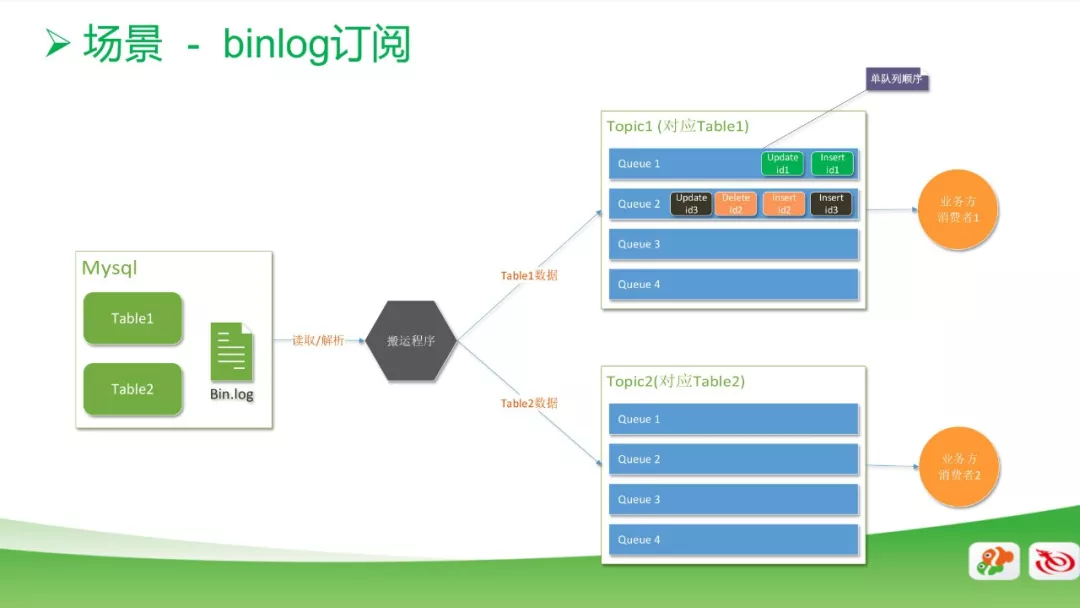
供应库的订阅系统
数据库的订阅系统也用到了消息的应用。一般情况下做数据库同步,都是通过binlog去读里面的数据,然后搬运到数据库。搬运过程中我们最关注的是数据的顺序性,因此在数据库row模式的基础上,新增了一个功能,以确保每一个Queue里面的顺序是唯一的。
我们踩过哪些坑
供应商系统的场景
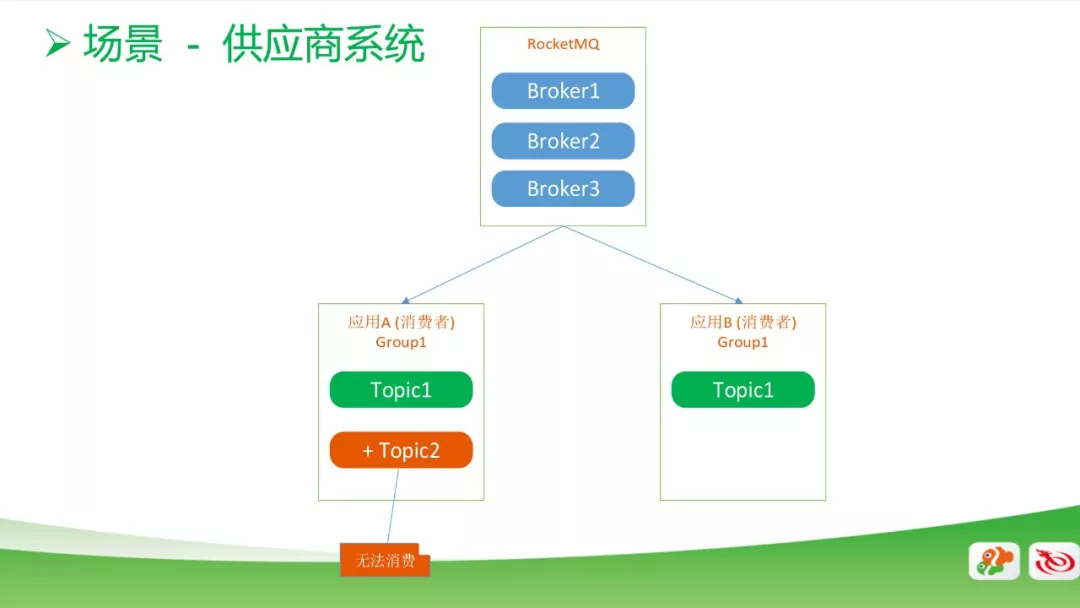
上图中,一个MQ对应有两个消费者,他们是在同一个Group1中,起初大家都只有Topic1,这时候是正常消费的。但如果在第一个消费者里面加入一个Topic2,这时候是无法消费或消费不正常了。这是RocketMQ本身的机制引起的问题,需要在第二个消费者里面加入Topic2才能正常消费。
支付交易系统的场景
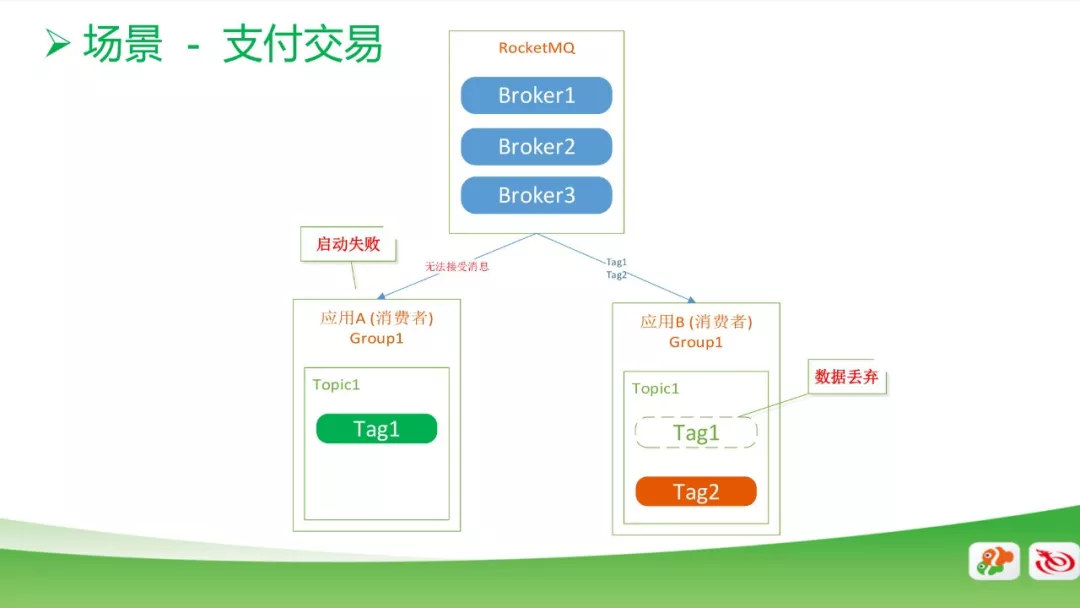
另外一个是支付交易系统,这个场景下也是有两个应用,他们都是在同一Group和同一Topic下,一个是消费Tag1的数据,另一个是消费Tag2的数据。正常情况下,启动应该是没问题的,但是有一天我们发现一个应用起不来了,另外一个应用,因为他只消费Tag2的数据,但是因为RocketMQ的机制会把Tag1的数据拿过来,拿过来过后会把Tag1的数据丢弃。这会导致用户在支付过程中出现支付失败的情况。
对此,我们把Tag2放到Group2里面,两个Group就不会消费相同的消息了。个人建议RocketMQ能够实现一个机制,即只接受自己的Tag消息,非相关的Tag不去接收。
大量老数据读取的场景
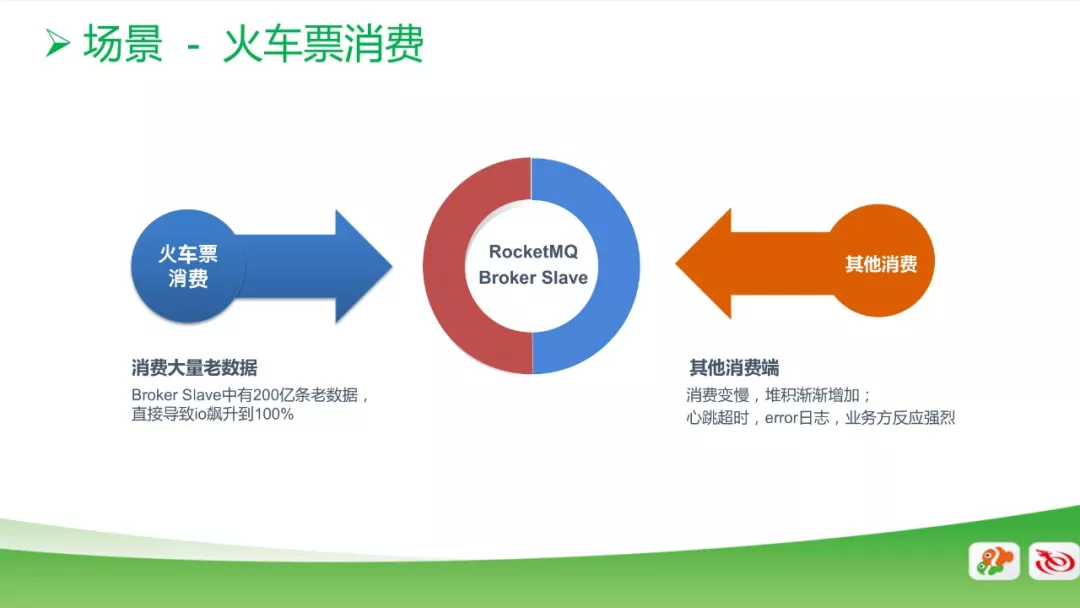
在火车票消费的场景中,我们发现有200亿条老数据没有被消费。当我们消费启动的时候,RocketMQ会默认从第0个数据开始读,这时候磁盘IO飙升到100%,从而影响到其他消费端数据的读取,但这些老数据被加载后后,并没有实际作用。因此,对于大量老数据读取的改进方式是:
- > 对于新消费组,默认从LAST_OFFSET消费;
- > Broker中单Topic堆积超过1000万时,禁止消费,需联系管理员开启消费;
- > 监控要到位,磁盘IO飙升时,能立刻联系到消费方处理。
服务端的场景
CentOS 6.6中 Futex Kernel bug, 导致Name Server, Broker进程经常挂起,无法正常工作;
- > 升级到6.7
服务端2个线程会创建相同CommitLog放入List,导致计算消息offset错误,解析消息失败,无法消费,重启没法解决问题。
- > 线程安全问题,改为单线程
Pull模式下重置消费进度,导致服务端填充大量数据到Map中,broker cpu使用率飙升100%。
- > Map局部变量场景用不到,删除
Master建议客户端到Slave消费时,若数据还没同步到Slave, 会重置pullOffset, 导致大量重复消费。
- > 不重置offset
同步没有MagicCode,安全组扫描同步端口时,Master解析错误,导致一些问题。
- > 同步时添加magicCode校验
基于RocketMQ,我们做了哪些改进
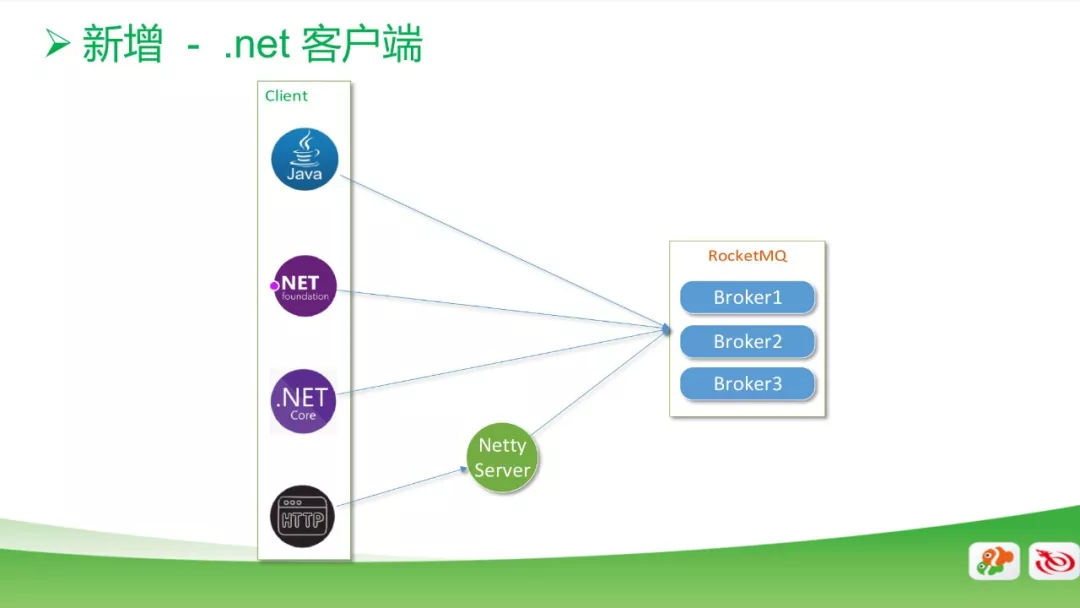
新增客户端
新增.net客户端,基于Java源代码原生开发;
新增HTTP客户端,实现部分功能,并通过Netty Server连接RocketMQ;
新增消息限流功能
如果客户端代码写错产生死循环,就会产生大量的重复数据,这时候会把生产线程打满,导致队列溢出,严重影响我们MQ集群的稳定性,从而影响其他业务。
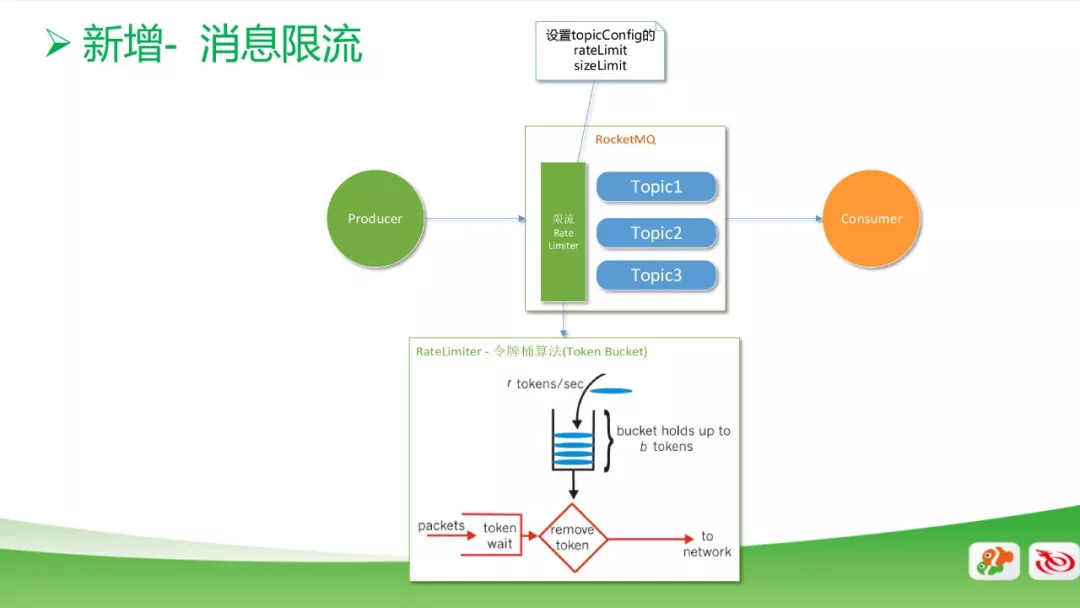
上图是限流的模型图,我们把限流功能加在Topic之前。通过限流功能可以设置rate limit和size limit等。其中rate limit是通过令牌桶算法来实现的,即每秒往桶里放多少个令牌,每秒就消费多少速度,或者是往Topic里写多少数据。以上的两个配置是支持动态修改的。
后台监控
我们还做了一个监控后台,用于监控消息的全链路过程,包括:
-
消息全链路追踪,覆盖消息产生、消费、过期整个生命周期;
-
消息生产、消费曲线;
-
消息生产异常报警;
-
消息堆积报警,通知哪个IP消费过慢。
其他功能
-
HTTP方式生产,消费消息;
-
Topic消费权限设置,Topic只能被指定Group消费,防止线上错乱订阅;
-
支持新消费组从最新位置消费 (默认是从第一条开始消费);
-
广播模式消费进度同步 (服务端显示进度)。
以上便是同程艺龙在消息系统建设方面的实践。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号