苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA
苏宁基于Spark Streaming的实时日志分析系统实践
原创: AI+落地实践 AI前线 2018-03-07
前言
目前业界基于 Hadoop 技术栈的底层计算平台越发稳定成熟,计算能力不再成为主要瓶颈。 多样化的数据、复杂的业务分析需求、系统稳定性、数据可靠性, 这些软性要求, 逐渐成为日志分析系统面对的主要问题。2018 年线上线下融合已成大势,苏宁易购提出并践行双线融合模式,提出了智慧零售的大战略,其本质是数据驱动,为消费者提供更好的服务, 苏宁日志分析系统作为数据分析的第一环节,为数据运营打下了坚实基础。
数据分析流程与架构介绍业务背景
苏宁线上、线下运营人员,对数据分析需求多样化、时效性要求越来越高。目前实时日志分析系统每天处理数十亿条流量日志,不仅需要保证:低延迟、数据不丢失等要求,还要面对复杂的分析计算逻辑,这些都给系统建设提出了高标准、高要求。如下图所示:
-
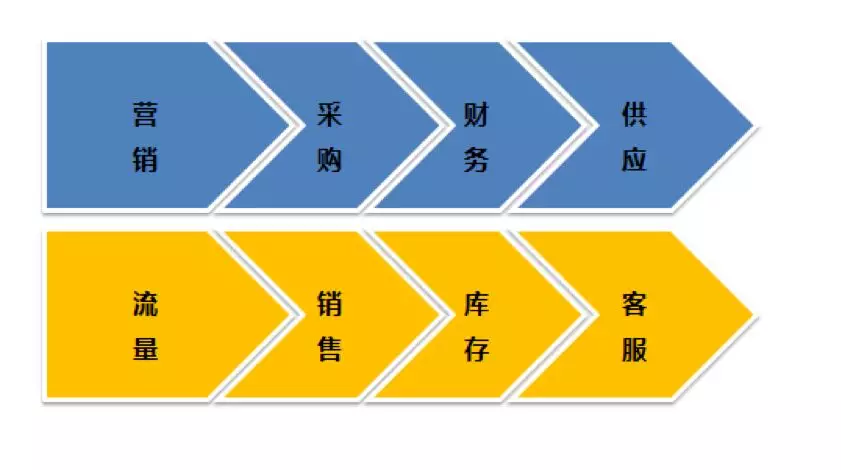
数据来源丰富:线上线下流量数据、销售数据、客服数据等
-
业务需求多样: 支撑营销、采购、财务、供应链商户等数据需求
流程与架构
苏宁实时日志分析系统底层数据处理分为三个环节:采集、清洗、指标计算,如图 1 所示。
-
采集模块:收集各数据源日志,通过 Flume 实时发送 Kafka。
-
清洗模块:实时接收日志数据,进行数据处理、转换,清洗任务基于 Storm 实现,目前每天处理十亿级别流量数据,经过清洗任务处理后的结构化数据将再次发送到 Kafka 队列
-
指标计算:从 Kafka 实时接收结构化流量数据,实时计算相关指标, 指标计算任务主要分两种:Storm 任务、Spark Streaming 任务,两种方式都有各自的应用场景, 其中 Spark Streaming 适合准实时场景,其优点是:吞吐量高、支持标准 SQL、开发简单、支持窗函数计算Storm、Spark 得益于苏宁数据云平台提供的支撑,目前苏宁数据云平台集成了:Hive、Spark、Storm、Druid、ES、Hbase、Kafka 等大数据开发组件,支撑了集团大数据计算、存储需求。
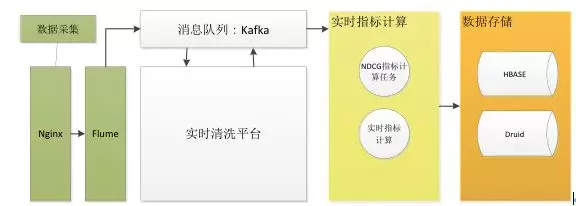
指标计算后数据主要存储到 HBase、Druid 等存储引擎,业务系统读取实时计算好的指标数据,为运营人员提供数据分析服务。
Spark Streaming 在指标分析实践Spark Streaming 介绍
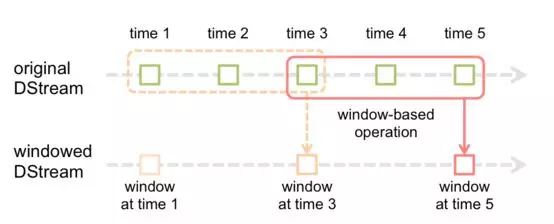
众所周知 Spark 是批处理框架,而 Spark Streaming 借鉴批处理的理念实现的准实时算框架,通过将数据按时间分批处理,实际应用中根据延迟要求合理设置分批间隔,如下图所示。Spark Streaming 支持多种数据源:Kafka、Flume、HDFS、Kenisis 等,平台原生支持写入到 HDFS、常见关系数据库等存储介质。


对比 Storm, Spark Streaming 准实时架构,吞吐量更高,支持 SQL,与 HDFS、数据库等存储介质支持的更好,开发方便,并且支持 Window 特性,能支持复杂的窗口函数计算。
NDCG 指标分析
Normalized Discounted Cumulative Gain,即 NDCG,常用作搜索排序的评价指标,理想情况下排序越靠前的搜索结果,点击概率越大,即得分越高 (gain)。CG = 排序结果的得分求和, discounted 是根据排名,对每个结果得分 * 排名权重,权重 = 1/ log(1 + 排名) , 排名越靠前的权重越高。首先我们计算理想 DCG(称之为 IDCG), 再根据用户点击结果, 计算真实的 DCG, NDCG = DCG / IDCG,值越接近 1, 则代表搜索结果越好。DCG 计算公式如下:

在苏宁易购搜索关键词"苹果",取第一排 4 个结果为例子。

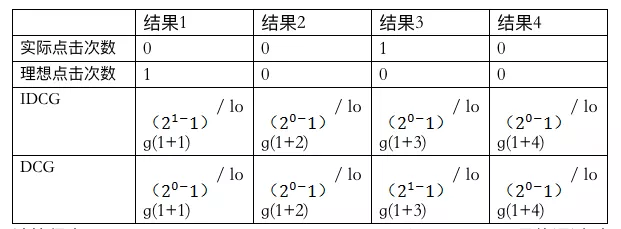
计算得出 IDCG = 1, DCG = 0.5,NDCG = DCG / IDCG = 0.5 , 最终通过对每次搜索计算 NDCG 得分,用来作为判断搜索结果好坏的一个评价指标。
NDCG 计算方案设计
通过统计搜索行为时间跨度,86% 的搜索行为在 5 分钟内完成、90% 的在 10 分钟内完成(从搜索开始到最后一次点击结果列表时间间隔),通过分析比较, NDCG 实时计算时间范围设定在 15 分钟。这就提出了两个计算难点:
-
时间窗口计算:每一次都是对前 15 分钟数据的整体分析
-
去重: 时间窗口内保证一次搜索只计算一次
最终我们选择了 Spark Streaming 框架,利用其 Window 特性,实现时间窗口计算。时间窗口为 15 分钟,步进 5 分钟,意味着每 5 分钟计算一次。每次计算,只对在区间[15 分钟前, 10 分钟前]发起的搜索行为进行 NDCG 计算,这样就不会造成重复计算。
按照方案开发后,线上测试很快发现问题,保存 15 分钟的数据消耗资源太多,通过分析发现:搜索数据仅占流量数据很小一部分, 清洗任务在 Kafka 单独存储一份搜索数据,NDCG 计算订阅新的搜索数据,大大减小了资源消耗。
性能与数据安全保障性能保障 容量预估与扩展
容量预估不是一个静态工作
-
流量日志在不断增长,而系统处理能力是有限的
-
大促活动会造成额外的数据高峰。
针对这些情况, 提前根据业务增长情况进行扩容是最重要的保障手段。扩容依赖系统的水平扩展能力,通过 Kafka Topic 分区数量、Storm 处理节点和并发数、Spark Streaming 并发数等参数调节,保障数据处理性能满足业务需求。
多维分析计算优化
以 NDCG 指标为例子,目前支持 4 个维度组合的计算:大区、城市、渠道、搜索词,为了支持 4 个维度任意组合,需要进行 15 次计算,在 HBase 进行 15 次存储更新操作。如下图所示。
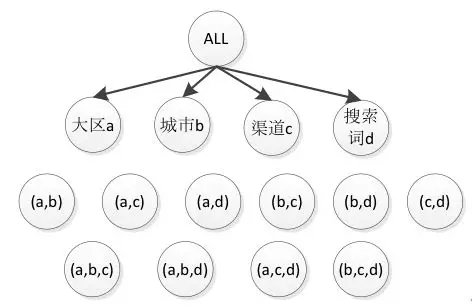
目前时间粒度是只到天,如果加上小时、周、月等时间维度,任务数、存储都要翻几倍。此时,一个高性能的 OLAP 计算引擎,来提升指标分析效率,变得更加迫切。
16 下半年数据云平台启动 OLAP 引擎建设,17 年正式对外提供 Druid 服务。 Druid 支持 sum、max、min、avg、count、distinct count 等常规聚合计算,支持从 Kafka 实时数据接入,其列式存储结构提升数据检索效率, 通过数据预聚合提升了计算效率。
经过方案预研以及性能测试,Druid 大大提升了 NDCG 这类指标的计算分析效率,让指标分析任务变得更轻量级,指标多维分析能力交给 Druid 来解决。
数据保障 保障数据不丢失
Storm 与 Spark 数据任务经常会需要重启进行发布操作,保障数据在一定时间内不丢失,尤为重要。分解下来需要保证两点:
-
数据源保证数据不丢失
-
数据任务保证数据被处理。
第一点,Kafka 通过数据落磁盘、备份机制保证数据不丢失
第二点,Storm 提供了 Ack 机制,保障数据必须被处理。
Spark Streaming 提供了 check point(WAL 日志) 备份机制,任务失败或重启后,可以利用 check point 数据进行恢复,保障数据被处理完成, 但是 wal 日志会把所有数据存储一份放到 HDFS, 非常耗时, Spark Streaming 针对 Kafka 进行了优化,提供了 Kafka direct API, 写 WAL 日志时候只需要记录 Kafka 队列的 offset, 任务恢复的时候,根据 offset 重新读取 Kafka 数据即可,整个流程如下图所示。

exactly-once 语义保障
对于销售类数据,不仅要保证数据被处理,还需要保证数据仅被处理一次,涉及销售财务指标数据必须 100% 准确。
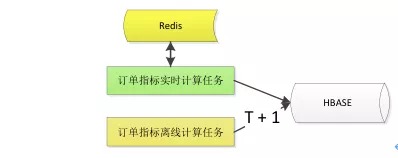
第一种方案:Labmda 架构 + Redis 去重
-
实时去重:一个订单被计算后,将订单号写入 Redis,通过比对订单号,保证数据不重复处理。
-
离线更新:每天凌晨重新计算销售指标,更新前一天指标数据
第二种方案:MPP + 主键
-
使用场景:适于外部使用场景,外部系统从 Mpp 数据查询、分析数据
-
技术方案:MPP 选用 PG CITUS 数据库,在 MPP 数据库建表,对订单号等唯一性字段设为主键。
未来架构演进与优化
目前整个底层处理系统都是基于业界的开源框架,系统还远远谈不上完美,尤其是做底层数据是个比较细致、辛苦的工作,数据质量问题频发,由于没有监控系统,经常是被动发现、解决问题。由于新业务长势喜人,数据清洗逻辑变更是家常便饭,代码发布频繁。
在 17 年底,开始对系统进行架构优化设计,主要增加了两个模块。
-
数据质量监控: 通过配置质量监控规则, 对实时、离线数据进行规则校验,支持:抽样校验、全量校验两种方式, 对数据异常通过告警方式及时通知开发人员。
-
数据清洗规则配置系统:让清洗逻辑抽象成可配置的规则,通过定义变更清晰规则,实现数据清洗逻辑的变更,这里的难点是规则抽象化,经过技术预研,初步确定使用 Drools、Groovy 两种方式配合实现清洗规则配置化。
总结与展望
日志处理分析系统作为数据挖掘、BI 分析等高阶应用的幕后支撑, 起着承上启下的作用, 尤其对于业务线多、大数据量场景,没有系统化平台化的支撑,大数据终将是一句空话。我相信不止是算法模型,底层的数据质量、时效性、系统稳定性,都将成为智慧零售的胜负手。
作者简介
王富平,苏宁易购大数据中心数据中台技术负责人,历任百度大数据部高级工程师、1 号店搜索与精准化部门架构师。多年来,一直从事大数据方向的研发工作,对大数据工具、机器学习有深刻的认知,在实时计算领域经验丰富,对 Storm、Spark Streaming 有深入了解。热爱分享和技术传播,目前关注数据分析平台的建设,旨在打通数据建模到数据分析,基于 Druid、Kylin 等 OLAP 技术,提供一个平台级别的数据指标服务,打造"数据即服务"的一站式解决方案。
https://mp.weixin.qq.com/s/bGXhC9hvDj4lzK7wYYHGDg
Spark Streaming 在数据平台日志解析功能的应用
文 | Pirate on 大数据
一、日志解析功能的背景
通过日志,我们可以获得很多有用的信息,最常见的日志信息包括应用产生的访问日志、系统的监控日志,本文所针对的日志是大数据离线任务产生的运行日志。目前日志解析功能依附于有赞大数据平台,也就是有赞的 data_platform,为该平台的一个功能。
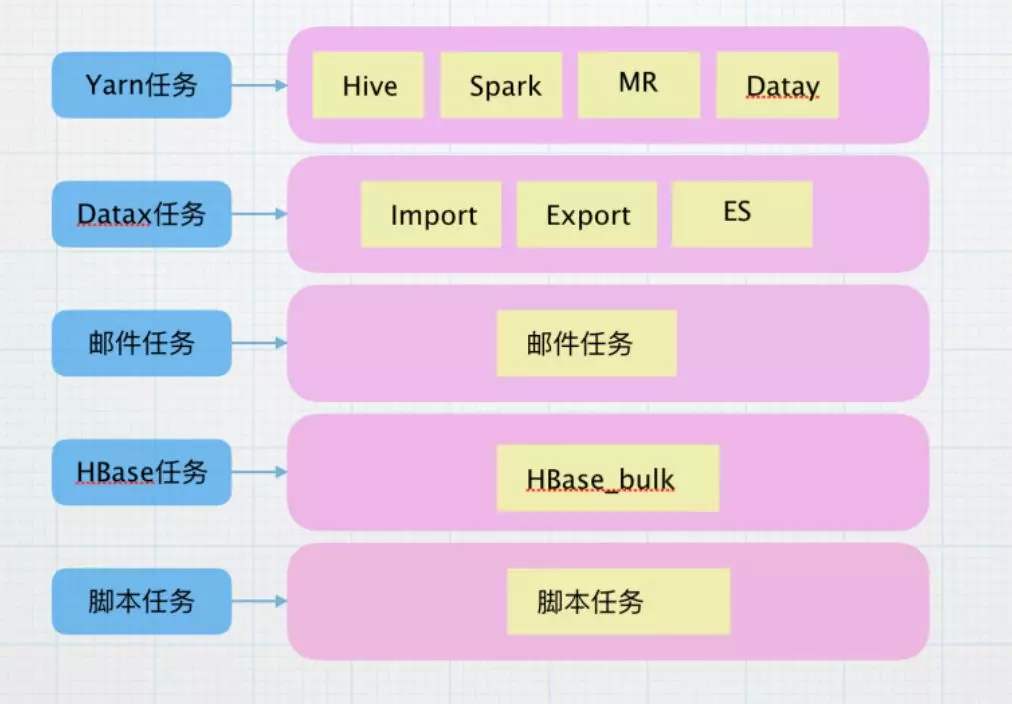
目前支持解析的日志类型包括:Hive 任务、Spark 任务、Datay 增量任务、导入任务、导出、MR 任务、Hbasebulk、脚本任务等。dataplatform 支持的调度类型为:批量重跑、测试类型、正常调度和手动导入任务。
做这个日志解析部分的目的分为几个,首先,在调度页面主要显示的是正常调度的任务,希望通过该功能了解不同调度类型的占比,比如测试类型,第二,了解每种任务类型的调度情况,比如查看运行成功、失败、重试等情况,第三,了解每种任务类型的资源占比,比如读写 byte 数量。
二、设计分析
2.1 针对不同类型的任务,日志的结构也不相同,针对这些任务进行了划分
目前,使用 yarn 进行调度的任务,资源情况已经进行了收集,主要获取总读取量、总写入量、shuffle 量、和 gc 时间等指标,进行存储汇总和展示,解析该种类型的日志时,需要将任务开始时间、结束时间等通用的信息进行保存,解析之后读取收集的指标表,进行统一封装,存储到缓存。
Datax 任务类型是导表任务,支持Hive -> Mysql ,Mysql -> Hive , Mysql -> ElasticSearch,Datax 任务类型的日志结构类似,主要的指标是读出总记录数、读写失败数、任务耗时、读取表、总比特数、使用表等信息。
不同的任务有不同的运行情况和需求指标,但是大体逻辑和以上两个类似。
2.2 根据调度类型进行划分
由于不同的调度类型在存储的时候目录信息不同,并且日志的开始、结束、失败等等标识不同,这些可以解析出来,标记任务的运行情况。根据任务类型进行分类,可以将任务分为正常调度、测试类型、手动导表和批量重跑,进而方便在后续解析过程中使用以及标记任务状态。
2.3 使用架构
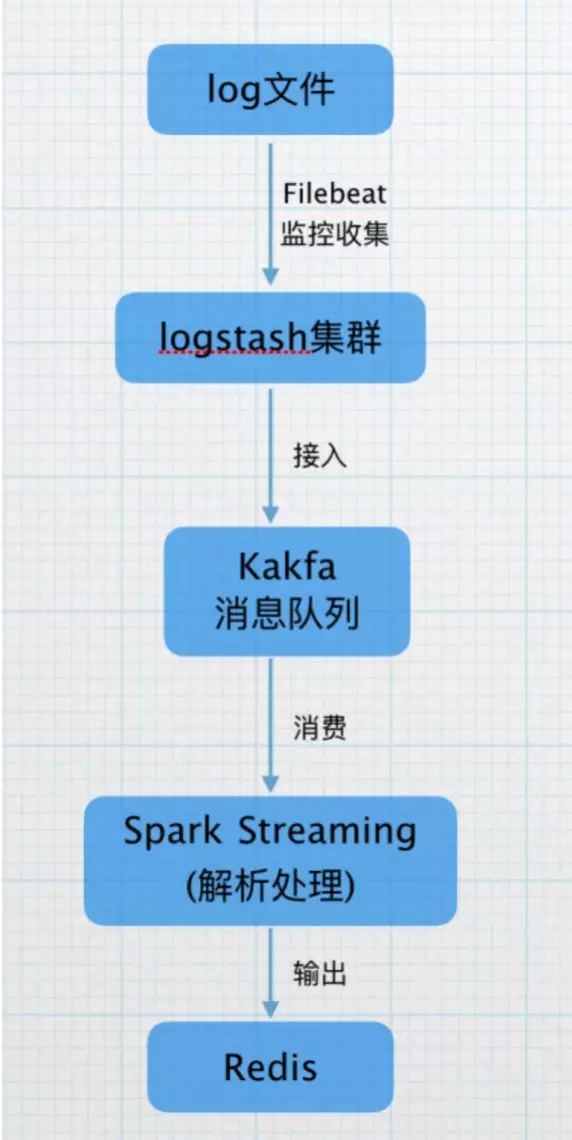
由于数据平台的任务调度日志是实时产生,所以我们选择流处理框架进行日志的处理。并且日志是从调度的集群上进行收集,目前调度数量是每日一万以上,而在每日凌晨会是任务调度的高峰期,对于吞吐量的要求也比较高,在调研了 Spark Streaming 后,考虑 Spark 支持高吞吐、具备容错机制的实时流数据的处理的特性,我们选择 Spark Streaming 进行处理。
目前,我们使用Filebeat监控日志产生的目录,收集产生的日志,打到logstash集群,接入kafka的topic,再由Spark Streaming 进行实时解析,将解析的结果打入Redis缓存,供后续统计查询使用。
三、功能实现
1. 实现资源统计
可以一目了然的看到,任务的运行情况,可以让用户一目了然的查看自己任务的运行情况,查看当天失败、成功、重试的数量以及统计。

2. 针对失败的任务和重试的任务进行集中的关注,进而实现 task 级别的优化,同时简化用户的操作成本,再这个页面就可以集中查看。
3. 实现资源量的排名统计,可以让 data_platform 的用户根据自己使用的情况,尤其是一些特别注意的地方,比如 GC 时间、Shuffle 量等影响大的指标进行集中的管理和优化,同时进行实时的监测。
四、一些注意事项
1. 由于 Spark standalone 模式只支持简单的资源分配策略,每个任务按照固定的 core 数分配资源,不够时会出现资源等待的情况,这种简单的模式并不适用于多用户的场景,而 Yarn 的动态分配策略可以很好的解决这个问题,可以实现资源的动态共享以及更加灵活的调度策略,所以公司也是采用 Spark on Yarn 的模式。
但是,目前 Spark on Yarn 支持 2 种方式的提交,一种是 Client 模式,这种模 dirver 运行在客户端,运行情况会收到启动机器的影响,推荐使用 Cluster 模式,这种模式是将 driver 运行在 Yarn 集群上,可以在客户端启动进程消失后进行平稳的运行,同时运行日志也保存在 Yarn 集群上,方便管理和问题排查。
2. 集群上分配给 Spark Streaming 的核数一定要大于接收器的数量,一个核占据一个 core,否则的话只会接收,没有 core 进行 process。
3. Spark 有 2 中接收器,可靠接收器和不可靠接收器,可靠接收器保存数据时带有备份,只有可靠接收器发送 acknowledgment 给可靠的数据源才可以保证在 Spark 端不丢失数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号