ASCII 二进制数表示字符 二进制 Oct 八进制 Dec 十进制 Hex 十六进制 全部国标汉字及符号组成一个94×94的矩阵 mysql 字符集和校验规则
mysql 字符集和校验规则( CHARSET & COLLATE) - 知乎 https://zhuanlan.zhihu.com/p/78080951

mallAllGoodsCREATE TABLE `qywl`.`mallAllGoods` ( `id` varchar(64) NOT NULL COMMENT '主键id',`userId` varchar(64) NOT NULL DEFAULT '' COMMENT '发布人id',`storeId` varchar(64) NOT NULL DEFAULT '' COMMENT '发布商号id',`data` varchar(1000) NOT NULL DEFAULT '' COMMENT '服务详情',`type` tinyint(1) UNSIGNED NOT NULL DEFAULT 0 COMMENT '服务类型(2车源,3货源,4酒店、5本地生活,6卡车)',`createTime` timestamp(6) default CURRENT_TIMESTAMP(6) NOT NULL COMMENT '创建时间',`updateTime` timestamp(6) default CURRENT_TIMESTAMP(6) NOT NULL ON update CURRENT_TIMESTAMP(6) COMMENT '更新时间',`logicalDel` tinyint(1) DEFAULT '0' NOT NULL COMMENT '逻辑删除标识(0未删除,1已删除)',PRIMARY KEY (`id`),INDEX `idx_userId` (`userId`),INDEX `idx_storeId` (`storeId`)) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='所有服务信息表';
定义:
CHARSET :给定一系列字符并赋予对应的编码后,所有这些字符和编码对组成的集合就是字符集(Character Set)。例如,给定字符列表为{‘A’,’B’}时,{‘A’=>0, ‘B’=>1}就是一个字符集;
COLLATE 是指在同一字符集内字符之间的比较规则;确定比较规则后,才能在一个字符集上定义什么是等价的字符,以及字符之间的大小关系;
COLLATE 会影响到ORDER BY语句的顺序,会影响到WHERE条件中大于小于号筛选出来的结果,会影响DISTINCT、GROUP BY、HAVING语句的查询结果。另外,mysql建索引的时候,如果索引列是字符类型,也会影响索引创建,总之,凡是涉及到字符类型比较或排序的地方,都和COLLATE有关。
命名惯例:以对应的字符集名称开头;以_ci(表示大小写不敏感)、_cs(表示大小写敏感)或_bin(表示按编码值比较)结尾。例如:在字符序“utf8_general_ci”下,字符“a”和“A”是等价的;
mysql字符集和校验规则的对应关系:
每个校验规则唯一对应一种字符集,但一个字符集可以对应多种校验规则,其中有一个是默认(Default Collation);
查询mysql数据库所支持的字符集种类:
sql
1show character set;
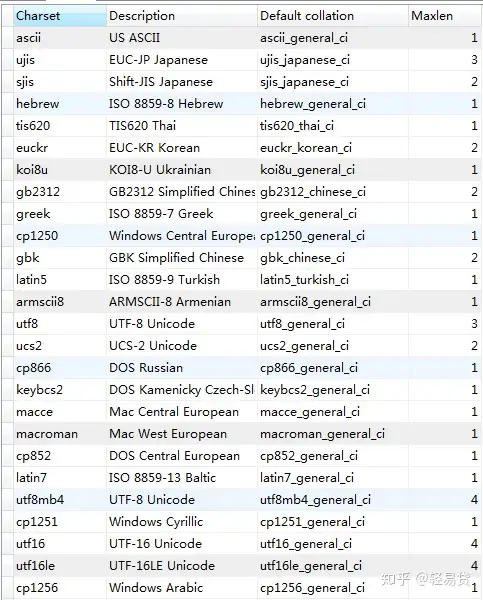
查询mysql数据库所支持字符集的校验规则:
sql
1show collation;
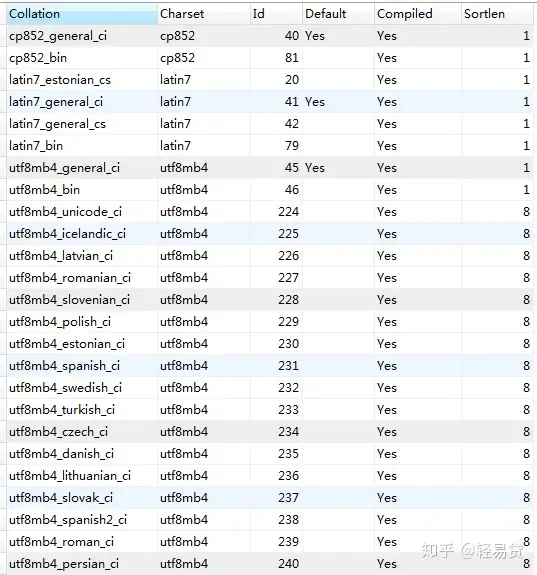
Mysql的字符集和校验规则有4个级别的默认设置:服务器级,数据库级,表级和字段级
客户端交互时,也可以指定校验规则
查看服务器级字符编码
sql
1show variables like 'character_set_server'
查看服务器级校验规则
sql
1show variables like 'collation_server'
服务器级字符集和校验规则,在Mysql启动时确定,在my.cnf中设置,如果没有指定字符集,默认为latin1,如果没有设置校验规则,默认使用字符集校验规则。
在mysql8.0以下版本中,默认的CHARSET是Latin1,默认的COLLATE是latin1_swedish_ci。从mysql8.0开始,默认的CHARSET已经改为了utf8mb4,默认的COLLATE改为了utf8mb4_0900_ai_ci。
sql
1
2
3[mysqld]character-set-server=utf8collation_server=utf8_general_ci
数据库级字符集和校验规则:
查看数据库级字符编码
sql
1show variables like 'character_set_database'
查看数据库级校验规则
sql
1show variables like 'collation_database'
库级别设置
sql
1CREATE DATABASE <db_name> DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;
如果库级别没有设置,则库级别默认使用服务器级别的设置。
表级别设置
sql
1
2
3CREATE TABLE (……) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
如果表级别没有设置,则表级别会继承库级别的设置。
列级别的设置
sql
1
2
3
4CREATE TABLE (`field1` VARCHAR(64) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL DEFAULT '',……) ……
如果列级别没有设置,则列级别会继承表级别的设置。
也可以在写SQL查询的时候显示声明COLLATE来覆盖任何库表列的COLLATE设置
sql
1
2SELECT DISTINCT field1 COLLATE utf8mb4_general_ci FROM table1;SELECT field1, field2 FROM table1 ORDER BY field1 COLLATE utf8mb4_unicode_ci;
优先级:
如果全都显示设置了,那么优先级顺序是 SQL语句 > 列级别设置 > 表级别设置 > 库级别设置 > 服务器别设置
几个需要注意的点:
1. 不同校验规则连表查会报错
sqlselect * from mallPageView as mLEFT JOIN mallStore as son m.storeId=s.id;[Err] 1267 - Illegal mix of collations (utf8mb4_general_ci,IMPLICIT) and (utf8mb4_unicode_ci,IMPLICIT) for operation '='可以指定排序规则:select * from mallPageView as mLEFT JOIN mallStore as son CONVERT(m.storeId USING utf8) COLLATE utf8_unicode_ci=s.id;
2. utf8和utf8mb4
utf-8 是变化长度的编码,储存需要1~4个字节
然而,mysql的utf8只存储最多3个字节。所以有些字符存不进去,像emoji表情等。
为了兼容4字节,MySQL在5.5.3之后增加了这个utf8mb4的编码。
建库,建表时,强烈建议编码使用utf8mb4。
3. utf8_unicode_ci、utf8_general_ci该用哪一个
当前,utf8_unicode_ci校对规则仅部分支持Unicode校对规则算法。一些字符还是不能支持。并且,不能完全支持组合的记号。这主要影响越南和俄罗斯的一些少数民族语言。
utf8_unicode_ci的最主要的特色是支持扩展,即当把一个字母看作与其它字母组合相等时。例如,在德语和一些其它语言中‘ß'等于‘ss'。
utf8_general_ci是一个遗留的 校对规则,不支持扩展。它仅能够在字符之间进行逐个比较。这意味着utf8_general_ci校对规则进行的比较速度很快,但是与使用utf8_unicode_ci的 校对规则相比,比较正确性较差。
例如,使用utf8_general_ci和utf8_unicode_ci两种校对规则下面的比较相等:
Ä = A
Ö = O
Ü = U
两种校对规则之间的区别是,对于utf8_general_ci下面的等式成立:
ß = s
但是,对于utf8_unicode_ci下面等式成立:
ß = ss
总结:
utf8_general_ci校对速度快,但准确度稍差
utf8_unicode_ci准确度高,但校对速度稍慢
DBA建议使用传统的utf8_general_ci
1、ASCII(American Standard Code for Information Interchange,美国信息交换标准代码);在GB2312—1980中规定,全部国标汉字及符号组成一个94×94的矩阵。
计算机系统基础(一):程序的表示、转换与链接-模块二 第5讲 非数值数据的编码表示-网易公开课 https://open.163.com/newview/movie/free?pid=WFVPGEQSL&mid=TFVPGF03G
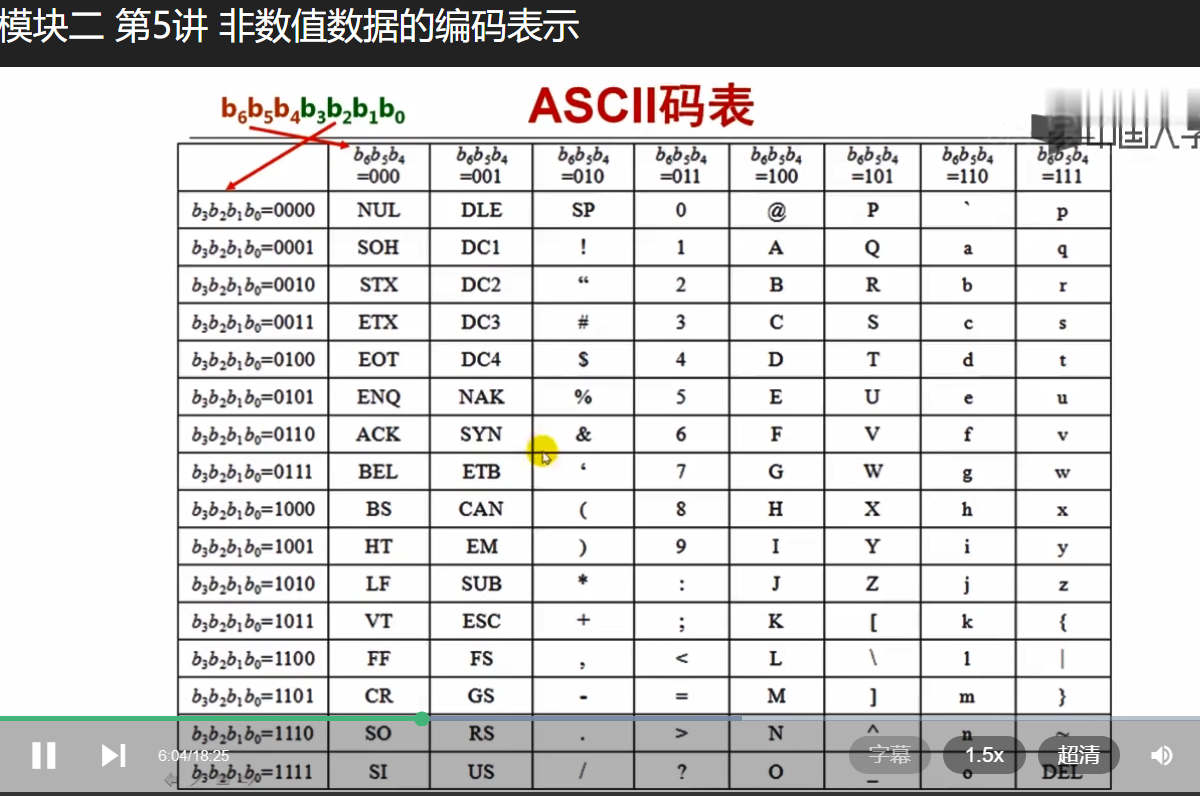
https://baike.baidu.com/item/ASCII/309296
- 中文名
- 美国信息交换标准代码
- 外文名
- American Standard Code for Information Interchange
- 简 称
- ASCII
- 别 称
- ASCII代码
- 类 别
- 编码标准
- 作 用
- 显示现代英语和其他西欧语言
|
Bin
(二进制)
|
Oct
(八进制)
|
Dec
(十进制)
|
Hex
(十六进制)
|
缩写/字符
|
解释
|
|
0000 0000
|
00
|
0
|
0x00
|
NUL(null)
|
空字符
|
|
0000 0001
|
01
|
1
|
0x01
|
SOH(start of headline)
|
标题开始
|
|
0000 0010
|
02
|
2
|
0x02
|
STX (start of text)
|
正文开始
|
|
0000 0011
|
03
|
3
|
0x03
|
ETX (end of text)
|
正文结束
|
|
0000 0100
|
04
|
4
|
0x04
|
EOT (end of transmission)
|
传输结束
|
|
0000 0101
|
05
|
5
|
0x05
|
ENQ (enquiry)
|
请求
|
|
0000 0110
|
06
|
6
|
0x06
|
ACK (acknowledge)
|
收到通知
|
|
0000 0111
|
07
|
7
|
0x07
|
BEL (bell)
|
响铃
|
|
0000 1000
|
010
|
8
|
0x08
|
BS (backspace)
|
退格
|
|
0000 1001
|
011
|
9
|
0x09
|
HT (horizontal tab)
|
水平制表符
|
|
0000 1010
|
012
|
10
|
0x0A
|
LF (NL line feed, new line)
|
换行键
|
|
0000 1011
|
013
|
11
|
0x0B
|
VT (vertical tab)
|
垂直制表符
|
|
0000 1100
|
014
|
12
|
0x0C
|
FF (NP form feed, new page)
|
换页键
|
|
0000 1101
|
015
|
13
|
0x0D
|
CR (carriage return)
|
回车键
|
|
0000 1110
|
016
|
14
|
0x0E
|
SO (shift out)
|
不用切换
|
|
0000 1111
|
017
|
15
|
0x0F
|
SI (shift in)
|
启用切换
|
|
0001 0000
|
020
|
16
|
0x10
|
DLE (data link escape)
|
数据链路转义
|
|
0001 0001
|
021
|
17
|
0x11
|
DC1 (device control 1)
|
设备控制1
|
|
0001 0010
|
022
|
18
|
0x12
|
DC2 (device control 2)
|
设备控制2
|
|
0001 0011
|
023
|
19
|
0x13
|
DC3 (device control 3)
|
设备控制3
|
|
0001 0100
|
024
|
20
|
0x14
|
DC4 (device control 4)
|
设备控制4
|
|
0001 0101
|
025
|
21
|
0x15
|
NAK (negative acknowledge)
|
拒绝接收
|
|
0001 0110
|
026
|
22
|
0x16
|
SYN (synchronous idle)
|
同步空闲
|
|
0001 0111
|
027
|
23
|
0x17
|
ETB (end of trans. block)
|
结束传输块
|
|
0001 1000
|
030
|
24
|
0x18
|
CAN (cancel)
|
取消
|
|
0001 1001
|
031
|
25
|
0x19
|
EM (end of medium)
|
媒介结束
|
|
0001 1010
|
032
|
26
|
0x1A
|
SUB (substitute)
|
代替
|
|
0001 1011
|
033
|
27
|
0x1B
|
ESC (escape)
|
换码(溢出)
|
|
0001 1100
|
034
|
28
|
0x1C
|
FS (file separator)
|
文件分隔符
|
|
0001 1101
|
035
|
29
|
0x1D
|
GS (group separator)
|
分组符
|
|
0001 1110
|
036
|
30
|
0x1E
|
RS (record separator)
|
记录分隔符
|
|
0001 1111
|
037
|
31
|
0x1F
|
US (unit separator)
|
单元分隔符
|
|
0010 0000
|
040
|
32
|
0x20
|
(space)
|
空格
|
|
0010 0001
|
041
|
33
|
0x21
|
!
|
叹号 |
|
0010 0010
|
042
|
34
|
0x22
|
"
|
双引号 |
|
0010 0011
|
043
|
35
|
0x23
|
#
|
井号 |
|
0010 0100
|
044
|
36
|
0x24
|
$
|
美元符 |
|
0010 0101
|
045
|
37
|
0x25
|
%
|
百分号 |
|
0010 0110
|
046
|
38
|
0x26
|
&
|
和号 |
|
0010 0111
|
047
|
39
|
0x27
|
'
|
闭单引号 |
|
0010 1000
|
050
|
40
|
0x28
|
(
|
开括号
|
|
0010 1001
|
051
|
41
|
0x29
|
)
|
闭括号
|
|
0010 1010
|
052
|
42
|
0x2A
|
*
|
星号 |
|
0010 1011
|
053
|
43
|
0x2B
|
+
|
加号 |
|
0010 1100
|
054
|
44
|
0x2C
|
,
|
逗号 |
|
0010 1101
|
055
|
45
|
0x2D
|
-
|
减号/破折号 |
|
0010 1110
|
056
|
46
|
0x2E
|
.
|
句号 |
|
0010 1111
|
057
|
47
|
0x2F
|
/
|
斜杠 |
|
0011 0000
|
060
|
48
|
0x30
|
0
|
字符0 |
|
0011 0001
|
061
|
49
|
0x31
|
1
|
字符1 |
|
0011 0010
|
062
|
50
|
0x32
|
2
|
字符2 |
|
0011 0011
|
063
|
51
|
0x33
|
3
|
字符3 |
|
0011 0100
|
064
|
52
|
0x34
|
4
|
字符4 |
|
0011 0101
|
065
|
53
|
0x35
|
5
|
字符5 |
|
0011 0110
|
066
|
54
|
0x36
|
6
|
字符6 |
|
0011 0111
|
067
|
55
|
0x37
|
7
|
字符7 |
|
0011 1000
|
070
|
56
|
0x38
|
8
|
字符8 |
|
0011 1001
|
071
|
57
|
0x39
|
9
|
字符9 |
|
0011 1010
|
072
|
58
|
0x3A
|
:
|
冒号 |
|
0011 1011
|
073
|
59
|
0x3B
|
;
|
分号 |
|
0011 1100
|
074
|
60
|
0x3C
|
<
|
小于 |
|
0011 1101
|
075
|
61
|
0x3D
|
=
|
等号 |
|
0011 1110
|
076
|
62
|
0x3E
|
>
|
大于 |
|
0011 1111
|
077
|
63
|
0x3F
|
?
|
问号 |
|
0100 0000
|
0100
|
64
|
0x40
|
@
|
电子邮件符号 |
|
0100 0001
|
0101
|
65
|
0x41
|
A
|
大写字母A |
|
0100 0010
|
0102
|
66
|
0x42
|
B
|
大写字母B |
|
0100 0011
|
0103
|
67
|
0x43
|
C
|
大写字母C |
|
0100 0100
|
0104
|
68
|
0x44
|
D
|
大写字母D |
|
0100 0101
|
0105
|
69
|
0x45
|
E
|
大写字母E |
|
0100 0110
|
0106
|
70
|
0x46
|
F
|
大写字母F |
|
0100 0111
|
0107
|
71
|
0x47
|
G
|
大写字母G |
|
0100 1000
|
0110
|
72
|
0x48
|
H
|
大写字母H |
|
0100 1001
|
0111
|
73
|
0x49
|
I
|
大写字母I |
|
01001010
|
0112
|
74
|
0x4A
|
J
|
大写字母J |
|
0100 1011
|
0113
|
75
|
0x4B
|
K
|
大写字母K |
|
0100 1100
|
0114
|
76
|
0x4C
|
L
|
大写字母L |
|
0100 1101
|
0115
|
77
|
0x4D
|
M
|
大写字母M |
|
0100 1110
|
0116
|
78
|
0x4E
|
N
|
大写字母N |
|
0100 1111
|
0117
|
79
|
0x4F
|
O
|
大写字母O |
|
0101 0000
|
0120
|
80
|
0x50
|
P
|
大写字母P |
|
0101 0001
|
0121
|
81
|
0x51
|
Q
|
大写字母Q |
|
0101 0010
|
0122
|
82
|
0x52
|
R
|
大写字母R |
|
0101 0011
|
0123
|
83
|
0x53
|
S
|
大写字母S |
|
0101 0100
|
0124
|
84
|
0x54
|
T
|
大写字母T |
|
0101 0101
|
0125
|
85
|
0x55
|
U
|
大写字母U |
|
0101 0110
|
0126
|
86
|
0x56
|
V
|
大写字母V |
|
0101 0111
|
0127
|
87
|
0x57
|
W
|
大写字母W |
|
0101 1000
|
0130
|
88
|
0x58
|
X
|
大写字母X |
|
0101 1001
|
0131
|
89
|
0x59
|
Y
|
大写字母Y |
|
0101 1010
|
0132
|
90
|
0x5A
|
Z
|
大写字母Z |
|
0101 1011
|
0133
|
91
|
0x5B
|
[
|
开方括号 |
|
0101 1100
|
0134
|
92
|
0x5C
|
\
|
反斜杠 |
|
0101 1101
|
0135
|
93
|
0x5D
|
]
|
闭方括号 |
|
0101 1110
|
0136
|
94
|
0x5E
|
^
|
脱字符 |
|
0101 1111
|
0137
|
95
|
0x5F
|
_
|
下划线 |
|
0110 0000
|
0140
|
96
|
0x60
|
`
|
开单引号 |
|
0110 0001
|
0141
|
97
|
0x61
|
a
|
小写字母a |
|
0110 0010
|
0142
|
98
|
0x62
|
b
|
小写字母b |
|
0110 0011
|
0143
|
99
|
0x63
|
c
|
小写字母c |
|
0110 0100
|
0144
|
100
|
0x64
|
d
|
小写字母d |
|
0110 0101
|
0145
|
101
|
0x65
|
e
|
小写字母e |
|
0110 0110
|
0146
|
102
|
0x66
|
f
|
小写字母f |
|
0110 0111
|
0147
|
103
|
0x67
|
g
|
小写字母g |
|
0110 1000
|
0150
|
104
|
0x68
|
h
|
小写字母h |
|
0110 1001
|
0151
|
105
|
0x69
|
i
|
小写字母i |
|
0110 1010
|
0152
|
106
|
0x6A
|
j
|
小写字母j |
|
0110 1011
|
0153
|
107
|
0x6B
|
k
|
小写字母k |
|
0110 1100
|
0154
|
108
|
0x6C
|
l
|
小写字母l |
|
0110 1101
|
0155
|
109
|
0x6D
|
m
|
小写字母m |
|
0110 1110
|
0156
|
110
|
0x6E
|
n
|
小写字母n |
|
0110 1111
|
0157
|
111
|
0x6F
|
o
|
小写字母o |
|
0111 0000
|
0160
|
112
|
0x70
|
p
|
小写字母p |
|
0111 0001
|
0161
|
113
|
0x71
|
q
|
小写字母q |
|
0111 0010
|
0162
|
114
|
0x72
|
r
|
小写字母r |
|
0111 0011
|
0163
|
115
|
0x73
|
s
|
小写字母s |
|
0111 0100
|
0164
|
116
|
0x74
|
t
|
小写字母t |
|
0111 0101
|
0165
|
117
|
0x75
|
u
|
小写字母u |
|
0111 0110
|
0166
|
118
|
0x76
|
v
|
小写字母v |
|
0111 0111
|
0167
|
119
|
0x77
|
w
|
小写字母w |
|
0111 1000
|
0170
|
120
|
0x78
|
x
|
小写字母x |
|
0111 1001
|
0171
|
121
|
0x79
|
y
|
小写字母y |
|
0111 1010
|
0172
|
122
|
0x7A
|
z
|
小写字母z |
|
0111 1011
|
0173
|
123
|
0x7B
|
{
|
开花括号 |
|
0111 1100
|
0174
|
124
|
0x7C
|
|
|
垂线 |
|
0111 1101
|
0175
|
125
|
0x7D
|
}
|
闭花括号 |
|
0111 1110
|
0176
|
126
|
0x7E
|
~
|
波浪号 |
|
0111 1111
|
0177
|
127
|
0x7F
|
DEL (delete)
|
删除
|

 浙公网安备 33010602011771号
浙公网安备 33010602011771号