内存管理 垃圾回收 C语言内存分配 垃圾回收3大算法 引用计数3个缺点 染色标记 标记清除 复制收集
小结:
1、垃圾回收的本质:找到并回收不再被使用的内存空间;
2、标记清除方式和复制收集方式的对比;
3、复制收集方式的局部性优点;
https://en.wikipedia.org/wiki/C_(programming_language)#Memory_management
Memory management
One of the most important functions of a programming language is to provide facilities for managing memory and the objects that are stored in memory. C provides three distinct ways to allocate memory for objects:[27]
- Static memory allocation: space for the object is provided in the binary at compile-time; these objects have an extent (or lifetime) as long as the binary which contains them is loaded into memory.
- Automatic memory allocation: temporary objects can be stored on the stack, and this space is automatically freed and reusable after the block in which they are declared is exited.
- Dynamic memory allocation: blocks of memory of arbitrary size can be requested at run-time using library functions such as
mallocfrom a region of memory called the heap; these blocks persist until subsequently freed for reuse by calling the library functionreallocorfree
These three approaches are appropriate in different situations and have various trade-offs. For example, static memory allocation has little allocation overhead, automatic allocation may involve slightly more overhead, and dynamic memory allocation can potentially have a great deal of overhead for both allocation and deallocation. The persistent nature of static objects is useful for maintaining state information across function calls, automatic allocation is easy to use but stack space is typically much more limited and transient than either static memory or heap space, and dynamic memory allocation allows convenient allocation of objects whose size is known only at run-time. Most C programs make extensive use of all three.
Where possible, automatic or static allocation is usually simplest because the storage is managed by the compiler, freeing the programmer of the potentially error-prone chore of manually allocating and releasing storage. However, many data structures can change in size at runtime, and since static allocations (and automatic allocations before C99) must have a fixed size at compile-time, there are many situations in which dynamic allocation is necessary.[27] Prior to the C99 standard, variable-sized arrays were a common example of this. (See the article on malloc for an example of dynamically allocated arrays.) Unlike automatic allocation, which can fail at run time with uncontrolled consequences, the dynamic allocation functions return an indication (in the form of a null pointer value) when the required storage cannot be allocated. (Static allocation that is too large is usually detected by the linker or loader, before the program can even begin execution.)
Unless otherwise specified, static objects contain zero or null pointer values upon program startup. Automatically and dynamically allocated objects are initialized only if an initial value is explicitly specified; otherwise they initially have indeterminate values (typically, whatever bit pattern happens to be present in the storage, which might not even represent a valid value for that type). If the program attempts to access an uninitialized value, the results are undefined. Many modern compilers try to detect and warn about this problem, but both false positives and false negatives can occur.
Another issue is that heap memory allocation has to be synchronized with its actual usage in any program in order for it to be reused as much as possible. For example, if the only pointer to a heap memory allocation goes out of scope or has its value overwritten before free() is called, then that memory cannot be recovered for later reuse and is essentially lost to the program, a phenomenon known as a memory leak. Conversely, it is possible for memory to be freed but continue to be referenced, leading to unpredictable results. Typically, the symptoms will appear in a portion of the program far removed from the actual error, making it difficult to track down the problem. (Such issues are ameliorated in languages with automatic garbage collection.)
https://zh.wikipedia.org/wiki/C动态内存分配
C动态内存分配是在C语言中为了实现动态内存分配而进行的手动内存管理。这种管理是通过C标准库中的 malloc、realloc、calloc、free 等函数进行的。[1][2]
C++ 为了兼容 C 语言也提供这些函数,但是更推荐使用 new、delete 操作符来完成类似的操作。[3]
malloc 所实际使用的内存分配机制有很多不同的实现,执行时间和内存消耗各有不同。
函数概述
C 动态内存分配函数在头文件 stdlib.h 中声明(C++ 中对应的头文件名称为 cstdlib)。[1]
| 函数 | 描述 |
|---|---|
malloc |
分配指定数量的字节 |
realloc |
调整指定内存块的大小,必要时会重新分配 |
calloc |
分配指定数量的字节,并初始化为 0 |
free |
释放指定的内存块 |
类型安全
malloc 所执行的内存分配基于字节数而不是类型,其返回类型为 void 指针(void *),表示该指针所指向区域的数据类型未知。C++ 由于其强类型系统,实际使用该指针时需要进行强制类型转换,而 C 语言中则不必进行。
int * ptr;
ptr = malloc(10 * sizeof(int)); /* 不进行强制类型转换 */
ptr = (int *)malloc(10 * sizeof(int)); /* 进行强制类型转换 */
另见
https://zh.wikipedia.org/wiki/C语言
内存管理
C语言的特色之一是:程序员必须亲自处理内存的分配细节。
C语言使用栈(Stack)来保存函数返回地址/栈帧基址、完成函数的参数传递和函数局部变量的存储。 如果程序需要在运行的过程中动态分配内存,可以利用堆(Heap)来实现。
基本上C程序的元素存储在内存的时候有3种分配策略:
- 静态分配
如果一个变量声明为全局变量或者是函数的静态变量,这个变量的存储将使用静态分配方式。静态分配的内存一般会被编译器放在数据段或代码段来存储,具体取决于实现。这样做的前提是,在编译时就必须确定变量的大小。 以IA32的x86平台及gcc编译器为例,全局及静态变量放在数据段的低端;全局及静态常量放在代码段的高端。
- 自动分配
函数的自动局部变量应该随着函数的返回会自动释放(失效),这个要求在一般的体系中都是利用栈(Stack)来满足的。相比于静态分配,这时候,就不必绝对要求这个变量在编译时就必须确定变量的大小,运行时才决定也不迟,但是C89仍然要求在编译时就要确定,而C99放松了这个限制。但无论是C89还是C99,都不允许一个已经分配的自动变量运行时改变大小。
所以说C函数永远不应该返回一个局部变量的地址。
要指出的是,自动分配也属于动态分配,甚至可以用alloca函数来像分配堆(Heap)一样进行分配,而且释放是自动的。
- 动态分配
还有一种更加特殊的情况,变量的大小在运行时有可能改变,或者虽然单个变量大小不变,变量的数目却有很大弹性,不能静态分配或者自动分配,这时候可以使用堆(Heap)来满足要求。ANSI C定义的堆操作函数是malloc、calloc、realloc和free。
使用堆(Heap)内存将带来额外的开销和风险。
《代码的未来》p76
垃圾回收 garbage collection GC
对象本质:
在Java和Rub中,程序在运行时会创建很多对象。从编程角度来看,它们是对象;但从计算机角度来看,它们也就是一些装有数据的内存空间而已。
麻烦来源:
在C和C++这样的语言中,这些内存空间是由人手动进行管理的。当需要内存空间时,要请求操作系统进行分配,不需要的时候要返还给操作系统。
然而,正是“不再需要”这一点,带来了各种各样的麻烦;而如果认为某些内存空间“可能还要用到”而不还给操作系统或者是用完了却忘记返还,这些无法访问的空间就会
一直保留下来,造成内存的白白浪费,最终引发性能下降和产生抖动。
术语:
1、垃圾 garbage
GC本质:
如果程序(通过某个变量)可能会直接或间接地引用一个对象,那么这个对象就被视为“存活”;
与之相反,已经引用不到的对象被视为“死亡”。将这些“死亡”的对象找出来,然后作为垃圾进行回收,这就是垃圾回收的本质。
2、根 root
判断对象是否可被引用的起始点。
至于哪里才是根,不同的语言个编编译器有不同的规定,但基本上是将变量和运行栈空间作为根。
3大垃圾回收算法
1、
标记清除 mark and sweep 1960
从根开始将可能被引用的对用递归的方式进行标记,然后将没有标记到的对象作为来及进行回收。
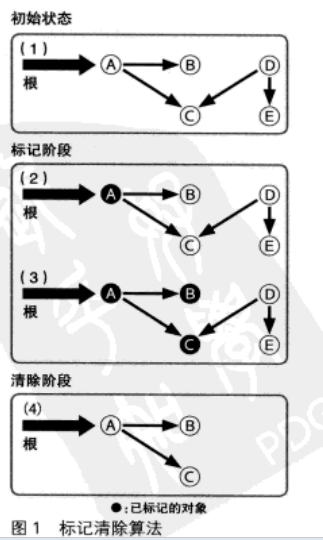
耗费时间和存活对象数的综合相关。
变形:标记压缩 mark and compact 算法,它不是将被标记的对象清除而是将它们不断压缩。
2、
复制收集方式
标记清除算法缺点:在分配了大量对象并且其中只有一小部分存活的情况下,所消耗的时间会大大超过必要的值,这是因为
在清除阶段还需要对大量死亡对象进行扫描。
复制收集 copy and collection 则试图客服这一缺点。
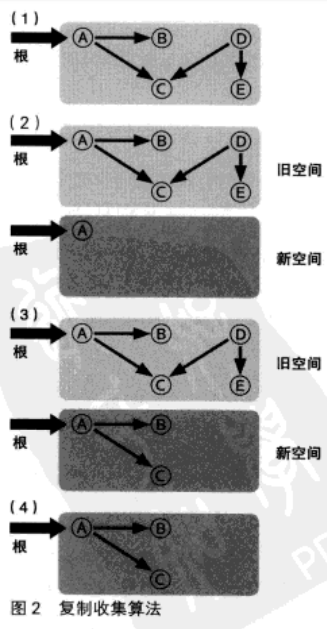
将从根开始被引用的对象复制到另外的空间中,然后,再将复制的对象所能够引用的对象 用递归的方式不断复制下去。
复制收集方式中,只存在相当于标记清除方式中的标记阶段。由于清除阶段中需要对现存的所有对象进行扫描,
在存在大量对象且其中大部分都即将死亡的情况下,全部扫描一遍的开销实在是不小。
而在复制收集方式中,就不存在这样的开销,但将对选哪个复制一份所需要的开销则比较大;
因此在“存活”对象比例比较高的情况下,反而会比较不利。
此该算法“具有局部性(locality)”的优势。
在复制收集过程中,会按照对象被引用的顺序将对象复制到新空间中。于是,关系较近的对象被放在距离较近的内存空间中的
可能性会提高,这被称为局部性。局部性高的情况下,内存缓存会更容易有效运作,程序的运行性性能也能得到提高。
3、
引用计数方式 reference count

容易实现是引用计数算法最大优点。
缺点
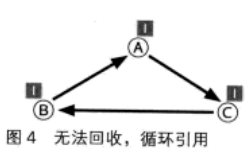
最大缺点
无法释放循环引用对象。
A、B、C三个对象没有被其他对象引用,而是互相之间循环引用,因此它们的引用计数永远不会为0,
结果这些对象就永远不会被释放。
缺点2:
必须在引用发生增减时对引用计数做出正确的增减,而如果漏掉某个增减的话,就会引发很难
找到原因的内存错误。
引用数忘了增加,会对不恰当的对象进行释放;
而引用数忘了减少的话,对象会一直残留在内存中,从而导致内存泄漏。
缺点3:
引用计数管理并不适合并行处理。如果多个线程同时对引用计数进行增减的话,引用即使的值就可能
产生不一致的问题,结果则会导致内存错误。
为了避免这种情况的而发生,对引用计数的操作必须采用独占的方式进行。如果引用操作频繁发生,每次
都要使用加锁等并发控制机制的话,其开销也是不可小觑的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号