机器学习笔记
第一章 绪论
机器学习的定义?
答:机器学习正是这样一门学科,它致力于研究如何通过计算手段,利用”经验“来改善系统自身的性能。
经验:通常是以“数据”的形式存在,因此机器学习主要研究的内容,是关于在计算机上从数据中产生“模型”的算法,即“学习算法”
从数据中获取模型的过程称为“学习”或“训练”,这个过程通过执行某个学习算法来完成。
学习任务的分类:根据训练数据是否拥有标记信息(可以理解为y值),学习任务可以分为两大类:“监督学习”和“无监督学习”,分类和回归是前者的代表,聚类是后者的代表
监督学习:分类和回归
- 线性回归、对数几率回归、决策树、支持向量机、贝叶斯分类器、神经网络
无监督学习:聚类
- 原型聚类(k均值、学习向量化、高斯混合聚类)、密度聚类(DBSVAN)、层次聚类(AGNES)、降维、话题分析、图分析
机器学习的目标:使学得的模型能很好的适用于“新样本”,而不仅仅是在训练样本上工作的很好。
学习的模型适用于新样本的能力称为泛化能力。
机器学习三要素:模型、策略、算法
人工智能的分类
基于神经网络的“连接主义”——代表感知机、Adaline
基于逻辑表示的“符号主义”——代表“结构学习系统”,“基于逻辑的归纳学习”,“概念学习系统”
以决策理论为基础的“行为主义“——代表
第一章练习题目
一、填空题
-
机器学习的目标是使学得的模型能很好地适用于新样本,而不是仅仅在训练样本上做得很好,学得模型适用于新样本的能力称为 泛化能力
-
根据 训练数据是否拥有标记信息 ,学习任务大致可以分为监督学习和无监督学习。
二、简答题
- 如何定义机器学习?
答:机器学习正是这样一门学科,它致力于研究如何通过计算手段,利用”经验“来改善系统自身的性能。
- 解释机器学习术语:什么是特征?什么是标签?
特征是描述某一样本某一属性的某种取值,是做出某个判断的依据;标签是对这一样本做出判断产生的结果。
- 最常见的两种监督学习任务是什么?
答:分类和回归
第二章 模型评估与选择
错误率:分类错误的样本占样本总数的比例,用E表示,精度= 1 - 错误率
误差:实际预测输出与样本真实值之间的差异成为误差,学习器在训练集上的误差称为“训练误差”,或“经验误差”,在新样本上的误差称为“泛化误差”。
过拟合:学习器把样本中某些样本的特点当作一般点,认为每个新样本都这样,导致泛化性能下降,这种现象称为过拟合。过拟合无法避免,只能缓解
欠拟合:指训练样本的一般性质尚未学好。
评估方法
留出法
留出法直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个集合作为测试集T,D = S + T, S ∩ T = 空。在S集上训练产生模型,在T集合上测试,作为对泛化误差的估计。
交叉验证法
交叉验证法,先将数据集D划分为 k 个大小相似的互斥子集,即D = D1 ∪ D2 ∪ D3 ∪ ... ∪ Dk ,Di ∩ Dj = 空,其中 i != j。每个子集Di 都尽可能保持数据分布的一致性,即从 D 中通过分层采样得到,然后,每次用 k - 1 个子集的并集作为训练集,余下的那个子集作为测试集,这样就可以获得 k 组 训练/测试集,从而可以进行 k 次训练和测试,最终返回是这 k 组测试结果的均值。这种验证方法也叫做“k折交叉验证”,k常用的取值是10,还有 5,20也算常用。
自助法
自助法,假定数据集 D 包含 m 个样本数据,每次从数据集 D 中选取一个样本,拷贝到最初为空集的 D’ 中,进行 m 次选取,则几乎可以确定,D中的数据在 D‘中有的出现了多次,有的没有出现过,此时采取 D’作为训练集,D‘中未出现的 D的数据作为测试数据,可以计算期望,约 36.8% 的数据在D’中不会出现。
自助法解决了因训练数据规模改变而造成的偏差,其在数据集较小、难以有效划分 训练/测试集时,很有用。
查准率、查全率与F1
对于二分类问题,可将样例根据其真实值类别与学习器预测类别的组合划分为真正例(true positive)、假正例(false positive)、真反例(true negative)、假反例(false negative),令TP、FP、TN、FN分别表示其对应的样例数,则显然有 TP + FP + TN + FN = 样例总数。分类结果用混淆矩阵表示
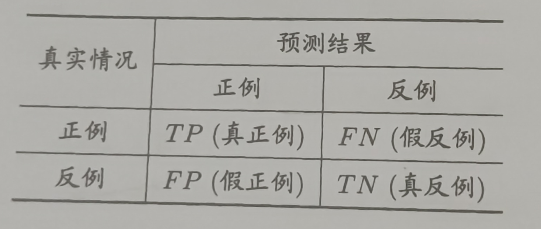
查准率P:真正例占所有预测为正例的比率
查全率R:真正例占所有正例的比率
查准率和查全率是一对矛盾的度量,一般来说,查准率高的时候,查全率就会低,反之则反
以查准率P作为纵轴、查全率R作为横轴,就得到了查准率-查全率曲线,简称 ”P-R曲线“
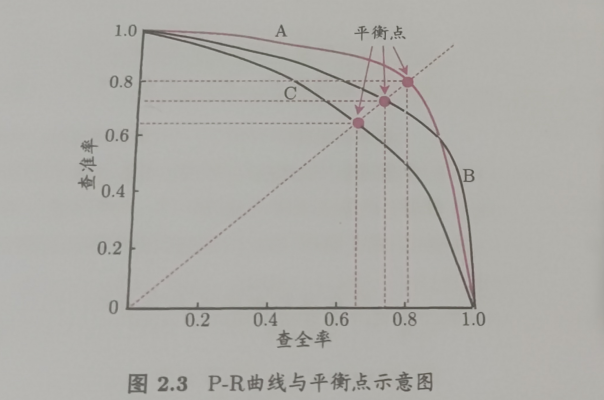
若一个学习器的P-R曲线被另一个学习器的曲线完全 ”包住“ 则可以断言,前一个学习器优于后一个,但是当相交时,不好判断,可以用面积判断,但是太麻烦,因此给出 ”平衡点(BEP)“的概念(越高越好),它是指 查准率 = 查全率时的取值。
更常用的是 F1 度量
当我们对样例进行多次训练的时候,会得到多个混淆矩阵,比如n个,我们希望对这 n 个混淆矩阵做出整体的评价,因此就出现了 宏和微 的概念
宏查全率、宏查准率、宏F1:指对 n 个混淆矩阵分别求出 P、R、F1,在求平均,用macro-P、macro-R、macro-F1表示
微查全率、微查准率、微F1:指对混淆矩阵的TP、FP、TN、FN求和,再求平均,再用均值求 P,R,F1,得到的即为对应的微,用micro-P、micro-R、micro-F1表示。
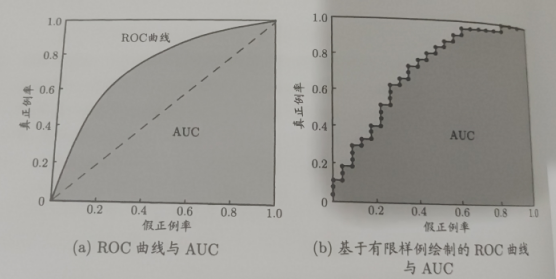
ROC曲线
全称 ”受试者工作特征“(Receiver Operating Characteristic)
根据学习器的预测结果对样例进行排序,按顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以他们为横纵坐标,就得到了ROC曲线
ROC纵轴是真正例率(TPR)、横轴是假正例率(FPR),
偏差、方差、噪声
偏差:偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了算法本身的拟合能力
方差:方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声:噪声则表达了在当前任务上任何学习算法所能达到的期望泛化误差下界,即刻画了学习问题本身的难度
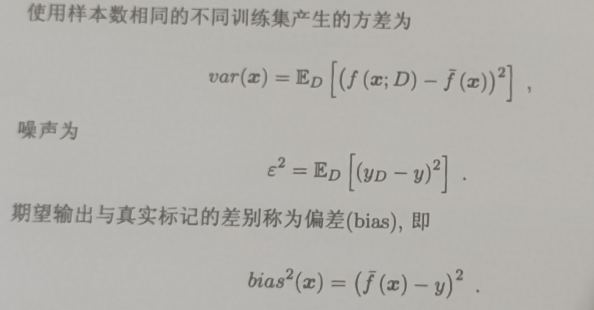
第二章练习题目
1、以二分类任务为例,假定数据集D包含1000个样本,将其划分为训练集S和测试集T,其中S包含800个样本, T包含200个样本,用S进行训练后,如果模型在T上有50个样本分类错误,那么模型的正确率为_____75%_______。
2、PR(Precision-Recall)曲线的横轴和纵轴分别是___查全率________和_____查准率_______。
3、ROC曲线的横轴和纵轴分别是_____假正例率______和____真正例率_______。
4、对于二分类问题,可将样本根据其真实类别与学习器预测类别的组合划分为真正例(true positive,TP)、假正例(false positive,FP)、真反例(true negative,TN)和假反例(false negative,FN)四种情形,请画出分类结果的混淆矩阵。
| 真实情况 | 预测结果 | |
|---|---|---|
| 正例 | 反例 | |
| 正例 | TP(真正例) | FN(假反例) |
| 反例 | FP(假正例) | TN(真反例) |
5、F1度量是综合考虑了查准率和查全率的性能度量指标,请写出其公式。

6、有多种因素可能导致过拟合,其中最常见的情况是由于___学习能力过于强大________________,以至于把训练样本所包含的不太一般的特性都学到了,而欠拟合则通常是由于___学习能力低下___________________而造成的。
7、查准率和查全率是分类任务中常用的性能度量指标,请写出其公式并对这两种指标进行分析。
查准率
查全率
\8. 简述折交叉验证法。
K折交叉验证法是先将数据集D划分成k个大小相似的互斥子集,即,任意两个子集交集为空,每个自己都尽可能保持数据分布的一致性,即从D中通过分层抽样得到,然后每次使用k-1个子集作为训练集,余下的作为测试集,这样就可以获得k组训练/测试集,从而可以进行k次训练和测试,最终返回的是这k个测试结果的均值。
9、分析偏差和方差的含义。
描述的是预测值(估计值)的期望与真实值之间的差距,偏差越大,越偏离真实数据。方差描述的是真实值到预测值的期望的大小,是离散程度,方差越大越分散。
10、对于一个三分类问题,数据集的真实标签和模型预测标签如下:
| 真实标签 | 1 | 1 | 2 | 2 | 2 | 3 | 3 | 3 | 3 |
|---|---|---|---|---|---|---|---|---|---|
| 预测标签 | 1 | 2 | 2 | 2 | 3 | 3 | 3 | 1 | 2 |
分别计算模型的精确率、召回率、F1值以及它们的宏平均和微平均。
混淆矩阵为:
为了方便观察将1,2,3映射为a,b,c
| 真实情况 | 预测结果 | ||
|---|---|---|---|
| a | b | c | |
| a | 1 | 1 | 0 |
| b | 0 | 2 | 1 |
| c | 1 | 1 | 2 |
准确率 p = 5/9 = 0.5555556
 = 0.5
 = 1/2 = 0.5
 = 2/4 = 0.5
 = 2/3 = 0.66667
 = 2/3 = 0.66667
 = 2/4 = 0.5
F1a = 1/2 = 0.5
F1b = 4/7 = 0.571428
F1c = 4/7 = 0.571428
宏平均:
macro_P = (Pa + Pb + Pc)/3 = 5/9
macro_R = (Ra + Rb + Rc)/3 = 5/9
macro_F1 = 5/9
微平均:
平均后的混淆矩阵为
| 5 | 4 |
|---|---|
| 4 | 10 |
macro_P = 5/9
macro_R = 5/9
macro_F1 = 5/9
第三章 线性模型
基本形式
向量形式
均方误差是回归任务中最常用的性能度量,因此可以试图让均方误差最小化,来求w 和 b
arg min下面加(w, b)意思是,让后面式子最小时,w,b的取值
基于均方误差最小化求模型的方法称为 ”最小二乘法“















 浙公网安备 33010602011771号
浙公网安备 33010602011771号