

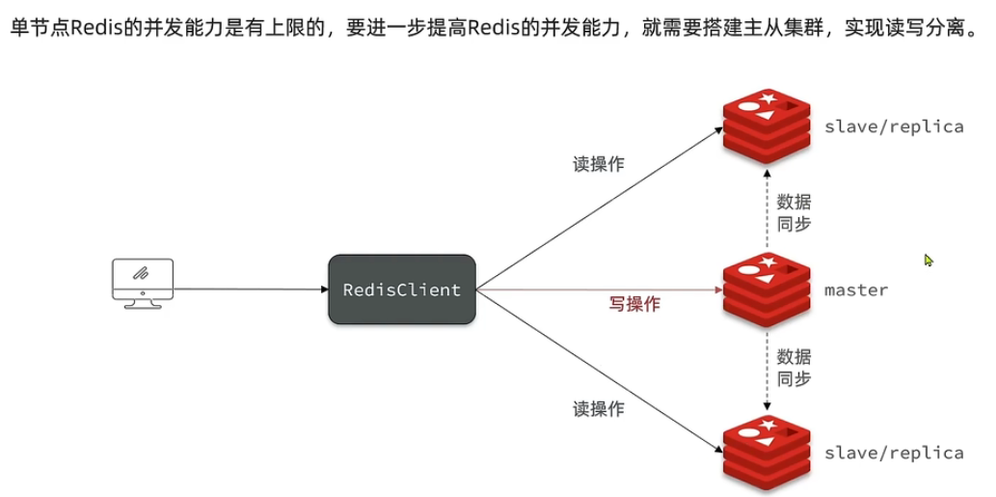
Redis主从架构
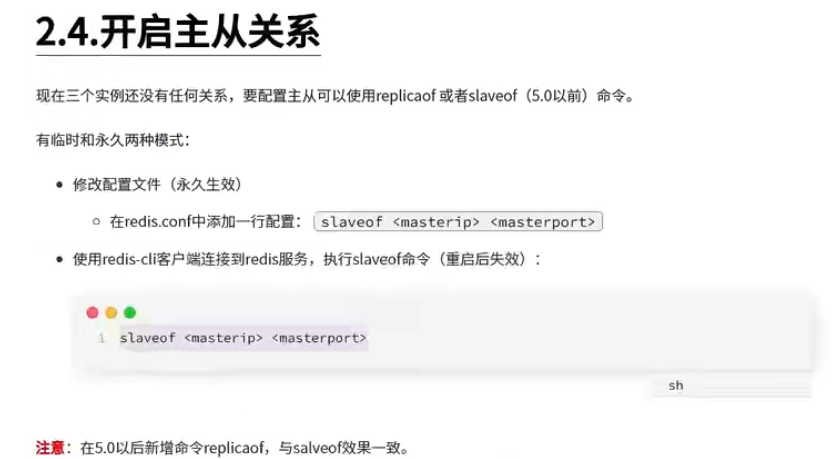
搭建主从架构
为什么要搭建主从集群呢?
- 因为使用redis的场景大多都是 ”读多写少“,为了提高读操作的并发能力,需要配置多台redis从节点,接收读操作请求。
- 主节点主要负责写操作。
- 主节点接收写操作,更新redis中数据后,需要及时同步到其他从节点。保证客户端读取到redis集群中任意一台机器上的数据都是相同的(保证数据一致性)。
一般的redis主从集群架构,包含3个节点:一个主节点,两个从节点。

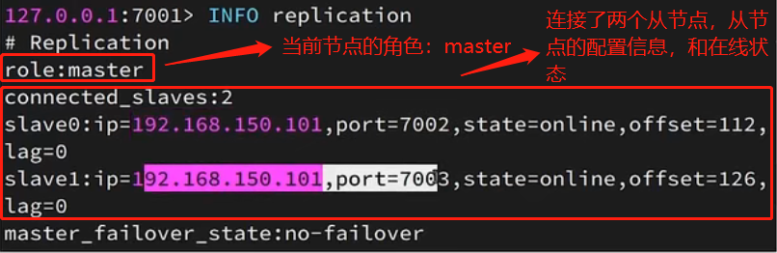
集群搭建好后,如何查看集群的信息呢?
在主节点上执行命令:
INFO replication
测试主写,从读?
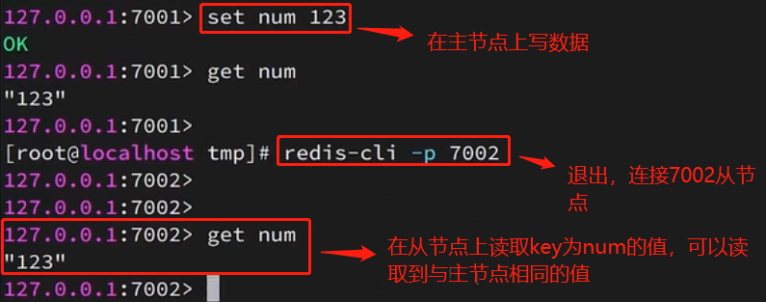
可以看到,在主节点上写入数据后,主节点会自动将数据同步到与之相连的从节点上。客户端切换连接redis从节点,可以读到在主节点上写入的数据。
从节点上只能读数据,无法执行写命令。

数据同步原理
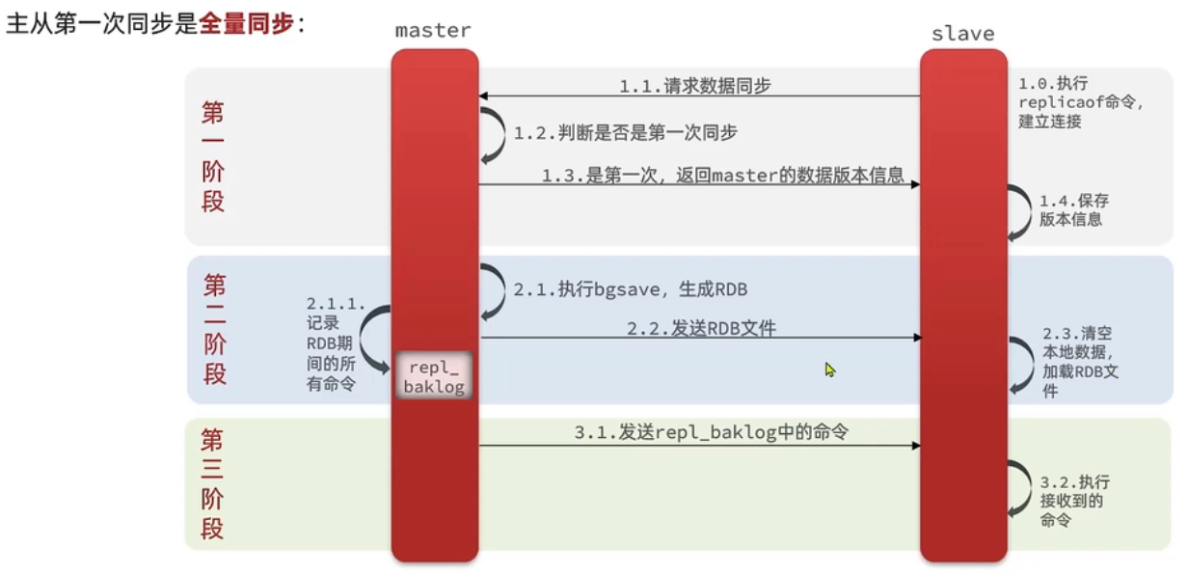
1. 全量同步
那master如何判断slave是不是第一次来同步数据呢?
- 通过判断slave的replid与master的replid是否一致,来确定
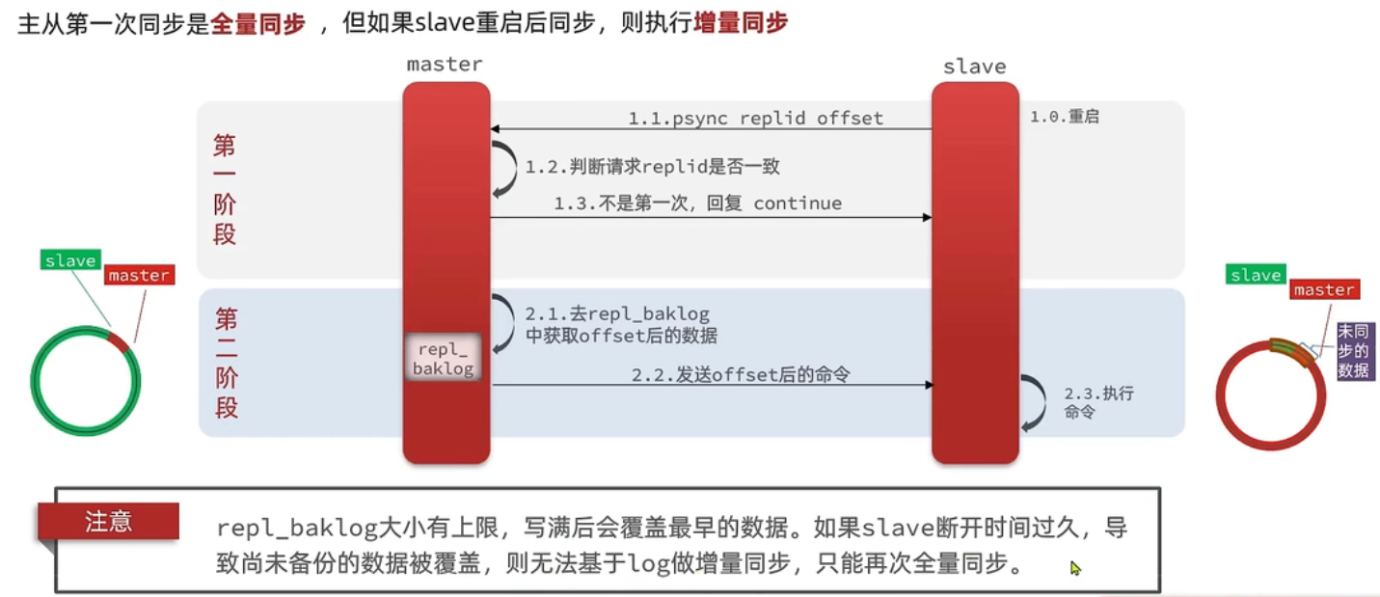
- 如果slave是master的从节点,slave的offset永远是小于等于master的offset的。master可以通过offset来分析当前slave的数据同步到哪个位置了,还有多少没同步,以此进行后续的增量同步。


简述全量同步过程
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整的内存数据生成RDB(这个过程中,master还会持续接收redis命令),发送RDB文件到slave
- slave清空本地数据,加载master中的RDB
- master将生成RDB期间执行的命令记录在repl_baklog中,并持续将repl_baklog中的命令发送给slave
- slave执行接收到的命令,保持与master之间的数据同步
2. 增量同步
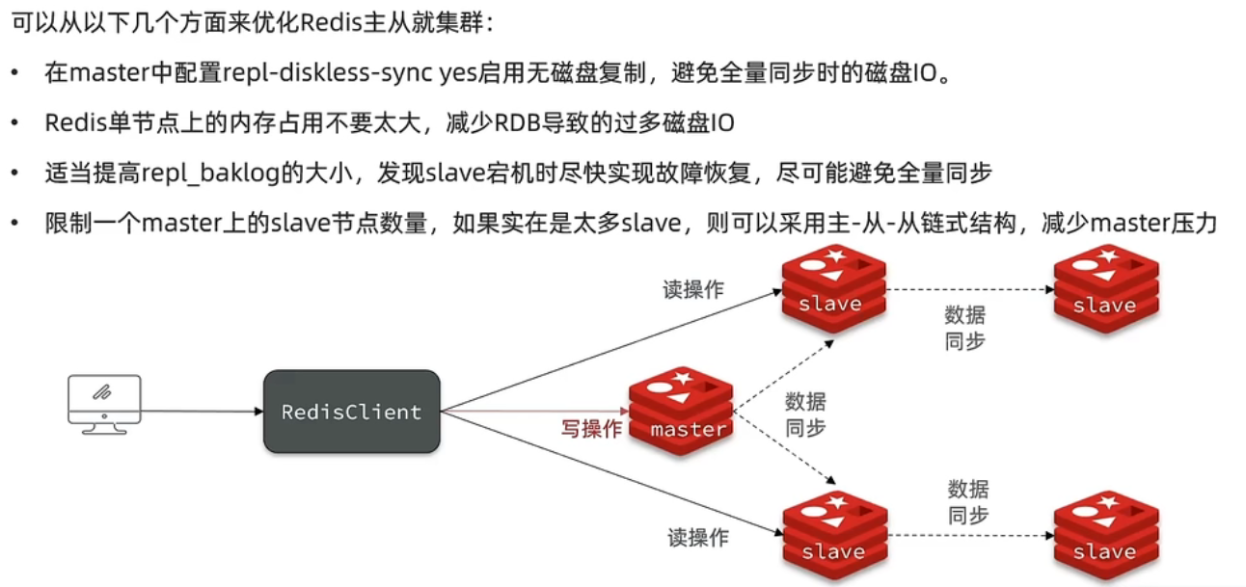
数据同步优化
总结数据同步


