从零一起学Spring Boot之LayIM项目长成记(三) 数据库的简单设计和JPA的简单使用。
前言
今天是第三篇了,上一篇简单模拟了数据,实现了LayIM页面的数据加载。那么今天呢就要用数据库的数据了。闲言少叙,书归正传,让我们开始吧。
数据库
之前有好多小伙伴问我数据库是怎么设计的。我个人用关系型数据库比较多,一般就是根据业务来分析,一对一的关系,一对多的关系,多对多的关系等,那么对于LayIM就根据这几个关系出发。而且先根据业务来设计。它初始化的数据我们都见过了,数据中分别包含以下四个部分。
- 个人用户信息
- 好友分组信息
- 群组信息
大部分业务都是围绕着用户转的,那么我们一条一条的分析。首先,个人用户信息不必说,这里我们就根据LayIM所需的用户字段设计就好,另外加上createAt字段或者其他字段都行。很简单,用户表SQL如下:
CREATE TABLE `user` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `avatar` varchar(255) DEFAULT NULL, `sign` varchar(255) DEFAULT NULL, `user_name` varchar(255) DEFAULT NULL, `create_at` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=984389 DEFAULT CHARSET=utf8;
好友分组信息,一个用户可以拥有多个分组,而每个分组下又可以有多个好友。 所以,维护好友关系需要两张表,分组表和用户(好友)分组关系表
CREATE TABLE `friend_group` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `create_at` bigint(20) DEFAULT NULL, `name` varchar(255) DEFAULT NULL, `uid` bigint(20) DEFAULT NULL, PRIMARY KEY (`id`), KEY `FKawe6k1o9mujam11lxiwcwbqpu` (`uid`), CONSTRAINT `FKawe6k1o9mujam11lxiwcwbqpu` FOREIGN KEY (`uid`) REFERENCES `user` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=770369 DEFAULT CHARSET=utf8;
群组信息,一个用户可以有多个群,一个群内有多个用户,他们是多对多的关系。所以维护这个关系需要两张表。群组表和群员关系表。
CREATE TABLE `big_group` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `create_at` bigint(20) DEFAULT NULL, `avatar` varchar(255) DEFAULT NULL, `create_uid` bigint(20) DEFAULT NULL, `description` varchar(255) DEFAULT NULL, `group_name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`), KEY `FKdw1jlswinwe6gas1tqk1trgia` (`create_uid`), CONSTRAINT `FKdw1jlswinwe6gas1tqk1trgia` FOREIGN KEY (`create_uid`) REFERENCES `user` (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
剩下的两个表没有写,分别是 (分组,用户)关系表,(群组,用户)关系表。 没错,他们都是多对多的关系。你可以在张三的好友列表里,也可以在李四的好友列表。同理,你可以在多个群里。
JPA-表的创建
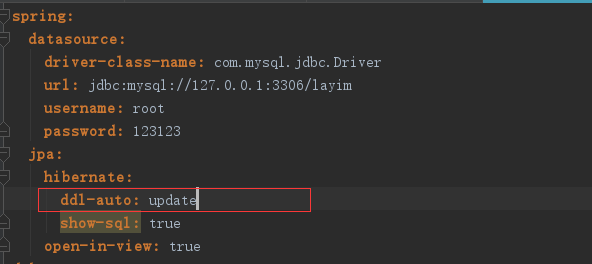
上面简单介绍了表的结构,虽然写出了SQL语句,但是呢在项目里我们并不会手动创建表。因为JPA会帮我们实现自动创建。如下图,我使用的是update,(即实体类变化等会重新修改表结构)
下面就用户表写一个对应的类。(例)
//加上@Entity注解 @Entity public class UserInfo { //主键注解 @Id @GeneratedValue @Column(nullable = false) private long id; //列 可以自定义列名,长度等,或者是否为空 @Column(name = "user_name",length = 20) private String name; }
运行程序,查看一下表,已经成功创建,没有问题。
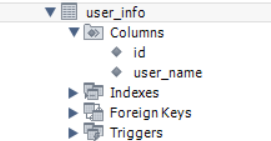
但是只是简单的表还不够,因为我们知道,表之间是有关系的,于是JPA中的关系注解就派上用场了。
JPA-关系的映射
之所以在上文中提到了一对多,多对多等词,其实就是为了在这里具体解释。JPA提供了关系注解。@OneToMany,@OneToOne,@ManyToOne,@ManyToMany等。下面我会根据LayIM所需要的关系一一讲解。
首先,一个用户对应多个好友分组。而一个分组只属于某个(当前)用户。这里可以理解为用户与好友分组的关系是一对多,即 @OneToMany。代码中是这样体现的。
//一对多,一个用户有多个好友分组 @OneToMany(mappedBy = "user") private List<FriendGroup> friendGroups;
在FriendGroup类中
@ManyToOne @JoinColumn(name = "uid",nullable = false) private User user;
其中呢,name ="uid" 代表,FriendGroup表中的uid字段对应的是User表中的主键(id)字段。也就是说,当我们查询一个User实体时,friendGroups字段会带上该用户下的好友分组。当然其中还涉及到了懒加载机制。(具体我也没研究,大体就是说,当调用 getFriendGroups()方法的时候才会根据关系从数据库查询相应的结果,这个后边会有体现)
其次,LayIM加载中会把当前用户的群组信息直接加载出来。这里我们也可以直接用 @OneToMany实现,原理同上。(刚开始我做错了,我只是列出了该用户创建的群,没有考虑到用户加入的群)
第三,@OneToOne 。这个注解呢在获取好友分组下的好友列表中用到了。比如,一个好友分组对应多个好友关系。那么每个好友关系从当前登录者的角度来说就是一对一的。这句话要怎么理解呢?就是说从程序上来讲,我们知道每个分组ID对应的多个UserId,因为表中存的是Id,但是我们取数据的时候需要把该用户的其他信息拿出来,那么使用@OneToOne注解,就会帮我们自动关联查询。代码如下:
@OneToOne @JoinColumn(name="friend_uid") private User friend;
代码中的friend_uid字段即用户id。(因为User类中的主键已经确定,所以不用再User类中增加 @OneToOne注解)
代码实现
(2017-11-7 日晚:此段代码已重构,为了写出我当时的思路,下文内容不会删掉,重构后代码讲解:http://www.cnblogs.com/panzi/p/7793854.html)
说了这么多,想必大家都有点晕了,下面就是代码实现了。在这里呢,我将拿好友分组举例,这个最简单。写一个单元测试,如下:
public User getUser(Long userId){ return userRepository.findOne(userId); }
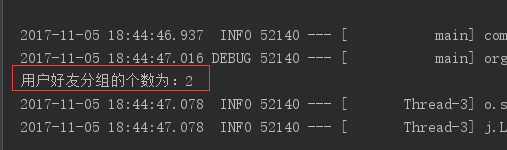
@Test public void testGetUserFriendGroups() { User user = userService.getUser(100000L); System.out.println("用户好友分组的个数为:"+user.getFriendGroups().size()); }
运行结果:
小 tips
当你做单元测试的时候,会遇到懒加载没有Session的问题,如果遇到了,在字段上面添加 FetchType.EAGER即可
@OneToMany(mappedBy = "user",fetch = FetchType.EAGER)
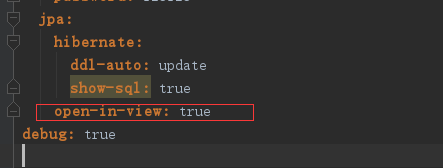
但是程序运行可以不用加这个,可以在配置文件中增加open-in-view :true 解决
JPA默认方法
在讲解具体实现之前呢,还要介绍一下JpaRepository这个接口,这个玩意挺好玩的,除了默认的方法,还可以自定义比如 findBy,getBy,findBy..OrderBy..等等方法。这里只介绍当前用到的,至于没有用到的,有兴趣的同学可以自行研究。代码很简单,新建一个UserRepository继承自JpaRepository即可
public interface UserRepository extends JpaRepository<User,Long> { }
这样写了之后,UserRepository默认会有一些方法,增删改查或者分页。这里呢,我们没有用到分页,只是简单的查询。没错就是 findOne方法
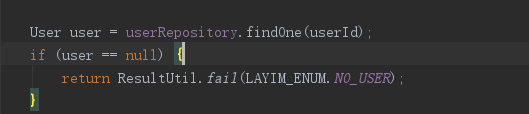
LayIM init接口实现
好了,讲了这么多,可能大家都云里雾里的,没有关系,下面就进入LayIM init接口实现部分。当然作为初学者来说,我就使用了笨方法,为什么说笨方法呢,方法思路如下:
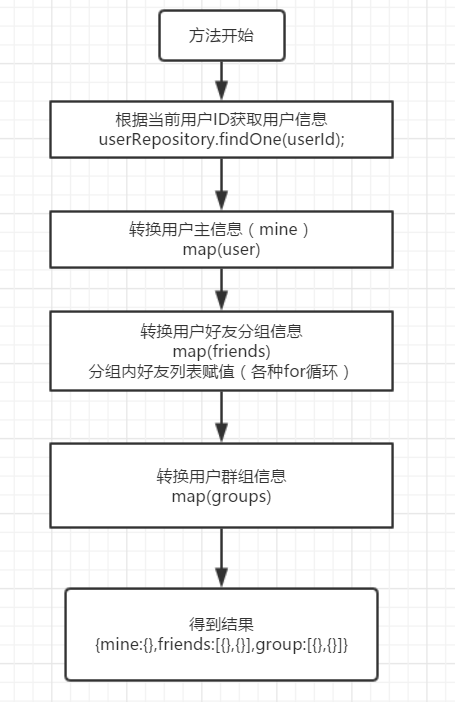
方法笨就笨在里面的for循环。(应该是有优化的,后期在看)
for(FriendGroup friendGroup : friendGroups) { List<RelationShip> relationShips = friendGroup.getRelationShips(); List<UserViewModel> userViewModels = new ArrayList<UserViewModel>(); //遍历 relationShips 获取userViewModels的集合 for(RelationShip relationShip : relationShips){ UserViewModel userViewModel = LayimMapper.INSTANCE.mapUser(relationShip.getFriend()); userViewModels.add(userViewModel); } //获取主键 Long friendGroupId = friendGroup.getId(); for (FriendGroupViewModel viewModel : friends) { if (viewModel.getId().equals(friendGroupId)) { viewModel.setList(userViewModels); } } }
代码当中我使用了 LayimMapper,他依赖于一个实体转换工具:MapStruct。有兴趣大家自行去官网看看。不过我个人觉得有点类似代码生成器,因为在编译过后,target里面会多出一个类来。

其实还是挺方便的,毕竟自己写也是这么写,这样还大大节约了时间。
好了,本篇内容啰嗦了一大堆,我也不知道讲了些啥,总之就是我在学习之中的一些问题和开发思路。知识点很多,所以在我这里介绍的都是皮毛,要深追究下去,每个知识点都可以写上几篇。最后看一下运行效果。接口同上一篇的一样。
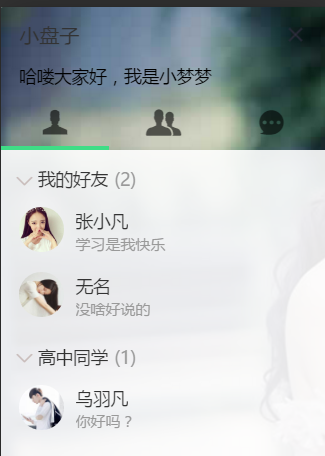
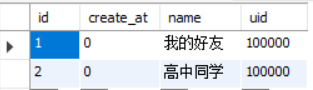
对应数据库:
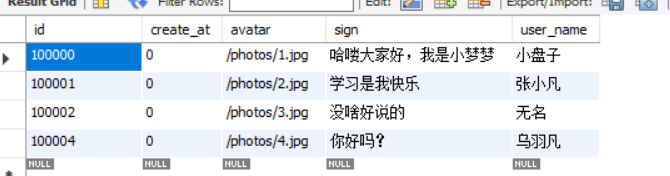

后台执行的语句:

总结
本篇到此为止就结束啦,Jpa部分讲解的比较少,决定下一篇重点学习记录一下。这个基础接口实现了。LayIM还有一个getMembers接口,你是不是也会了呢?在我学习的过程中,包括关系注解,MapStruct应用和其他实践上自己给自己挖了很多坑,也出现过很多莫名奇妙的问题,有些东西自己动手了才知道。愉快的周末结束啦。我们下一篇见。
下篇预告:从零一起学Spring Boot之LayIM项目长成记(四) Spring Boot JPA 深入了解

 浙公网安备 33010602011771号
浙公网安备 33010602011771号