java内存模型知识点汇总
1.像windows/linux这种操作系统中,自带jvm么?以方便java程序的运行?
答:是的,一般操作系统都自带jvm的。但不带jdk,也就是说java的运行环境有,但编译环境没有。
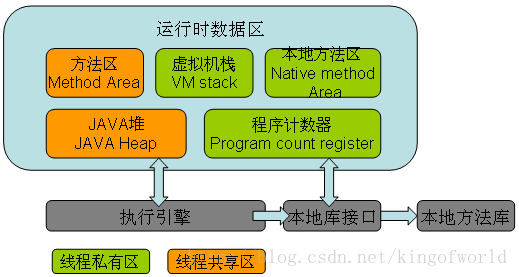
1.java程序运行时分哪几种内存区域?
答:大概分为5种内存区域。这5种内存区域,又分为共享区内存,线程私有内存区。
方法区,堆,线程栈,本地方法区,程序计数器。
共享区:堆,方法区。
线程私有区:本地方法区,程序计数器,线程栈。
2.java虚拟机内存划分不同区域的目的什么?
答:为了提高运算效率,就对数据进行了不同空间的划分,每一片区域采用特定的处理数据方式和内存管理方式。
3.java虚拟机都包括哪些知识点?
答:从虚拟机启动开始算起考虑嘛,包括类加载机制,内存分配(内存模型),垃圾回收。
所以,java虚拟机就包括三方面知识点,类加载机制,内存分配和垃圾回收。
2.每种内存区域里存储什么数据?
各区介绍:
1)方法区(线程共享):用于存放被虚拟机加载的类的信息(就是类的全部代码),静态变量,常量。
2)Java堆(线程共享):存放对象实例和数组,这里是内存回收的主要地方。可以分为新生代(young)和年老代(tenured)。从字面也可以知道,新生代存放刚刚建立的对象,而年老代存放长久没有被垃圾回收机制回收的对象。一般新生代有分为eden,from survivor和to survivor。这是和回收算法相关的分配(通过-Xms和-Xmx来配置)。
3)线程栈(线程私有):随线程一起建立,是方法执行的内存模型。当方法开始执行时,载入局部变量(引用变量),参数,返回值。栈的大小决定了方法调用的可达深度(递归多少层次,或嵌套调用多少层其他方法,-Xss参数可以设置虚拟机栈大小)。栈的大小可以是固定的,或者是动态扩展的。如果请求的栈深度大于最大可用深度,则抛出stackOverflowError;如果栈是可动态扩展的,但没有内存空间支持扩展,则抛出OutofMemoryError。
4)程序计数器(线程私有):java被编译成class,并被JVM解释执行,执行的是每一条指令。程序计数器记录当前线程执行的字节码地址,使得程序在轮询获取CPU时间片执行的时候能够知道从何处执行。因此很好想到,这篇区域是线程私有的,因为这里记录的就是不同线程的执行地址。(程序计数器一般都比较小,所以在内存资源的分析时都会忽略这片内存的占用)。
5)本地方法栈(线程私有):本地方法栈和虚拟机栈类似,只是这是存储本地方法的内存模型,管理本地方法的执行(Native)
3.java 堆和栈之间是怎样联系的?
答:new创建对象时,是在堆和栈中都分配内存的。Java中对象的存储空间都是在堆中分配的,但是这对象的引用却是在栈中分配,也就是说在建立一个对象时在堆和栈中都分配内存,在堆中分配的内存实际存放这个被创建的对象的本身,而在栈中分配的内存只是存放指向这个堆对象的引用而已。
4.方法退出时,怎么样处理栈内存和堆内存?
答:方法退出时,栈空间立刻被回收,局部变量生命周期立即,堆空间中的刚才方法中创建的对象等待GC回收。
5.栈内存是什么时候建立的?
答:程序是由main()方法开始执行的,java程序总是最少两个线程,main()线程和gc垃圾回收线程。所以main线程是立即建立的,同时立即创建main线程的栈内存。
6.堆,栈,方法区的创建时间是在什么时候创建的?
答:虚拟机启动时自动创建堆。
方法区在被虚拟机加载类的时候,载入类信息、常量、静态常量。
栈是在线程启动时候自动创建。
7.java虚拟机主要包括哪些知识点?
答:Java虚拟机知识点包括内存模型和垃圾回收器。
8.方法区是由什么组成的?
答:方法区中包含的都是在整个程序中永远唯一的元素,如class,static变量。
9.线程内存是怎样与主内存交互的?
答:当线程与内存区域进行交互时,数据从主存拷贝到工作内存,进而交由线程处理(操作码+操作数)。
Java 虚拟机规范的规定,Java 堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可。
10.线程栈的具体组成是?
答:虚拟机栈描述的是Java 方法执行的内存模型:每个方法被执行的时候都会同时创建一个栈帧(Stack Frame ①)用于存储局部变量表、操作栈、动态
链接、方法出口等信息。每一个方法被调用直至执行完成的过程,就对应着一个栈帧在虚拟机栈中从入栈到出栈的过程。
局部变量表存放了编译期可知的各种基本数据类型(boolean、byte、char、short、int、float、long、double)、对象引用(reference 类型,它不等同于对象本身。
栈区:
1.每个线程包含一个栈区,栈中只保存基础数据类型本身和自定义对象的引用;
2.每个栈中的数据(原始类型和对象引用)都是私有的,其他栈不能访问;
3.栈分为3个部分:基本类型变量区、执行环境上下文、操作指令区(存放操作指令);
3、 JVM的进程中,每个线程都会拥有一个方法调用栈,用来跟踪线程运行中一系列的方法调用过程,栈中的每一个元素就被称为栈帧,每当线程调用一个方法的时候就会向方法栈压入一个新帧。这里的帧用来存储方法的参数、局部变量和运算过程中的临时数据。
11.java虚拟机垃圾回收机制
12.程序运行时内存分配情况分析
答:首先 启动一个Java虚拟机进程,这个进程首先从classpath中找到AppMain.class文件,读取这个文件中的二进制数据,然后把Appmain类的类信息存放到运行时数据区的 方法区 中,这就是AppMain类的加载过程。
接着,Java虚拟机定位到方法区中AppMain类的Main()方法的字节码,开始执行它的指令。这个main()方法的第一条语句就是:
Sample test1=new Sample("测试1");
该语句的执行过程:
1、 Java虚拟机到方法区找到Sample类的类型信息,没有找到,因为Sample类还没有加载到方法区(这里可以看出,java中的内部类是单独存在的,而且刚开始的时候不会跟随包含类一起被加载,等到要用的时候才被加载)。
Java虚拟机立马加载Sample类,把Sample类的类型信息存放在方法区里。
2、 Java虚拟机首先在堆区中为一个新的Sample实例分配内存, 并在Sample实例的内存中存放一个方法区中存放Sample类的类型信息的内存地址。
3、位于“=”前的Test1是一个在main()方法中定义的一个变量(一个Sample对象的引用),因此,它被会添加到了执行main()方法的主线程的JAVA方法调用栈中。
而“=”将把这个test1变量指向堆区中的Sample实例。
4、JVM依次执行它们的printName()方法。当JAVA虚拟机执行test1.printName()方法时,JAVA虚拟机根据局部变量test1持有的引用,定位到堆区中的Sample实例,再根据Sample实例持有的引用,
定位到方法去中Sample类的类型信息,从而获得printName()方法的字节码,接着执行printName()方法包含的指令,开始执行。
AppMain.java 2 3 public class AppMain //运行时, jvm 把appmain的代码全部都放入方法区 4 { 5 public static void main(String[] args) //main 方法本身放入方法区。 6 { 7 Sample test1 = new Sample( " 测试1 " ); //test1是引用,所以放到栈区里, Sample是自定义对象应该放到堆里面 8 Sample test2 = new Sample( " 测试2 " ); 9 10 test1.printName(); 11 test2.printName(); 12 } 13 } 14 15 public class Sample //运行时, jvm 把appmain的信息都放入方法区 16 { 17 /** 范例名称 */ 18 private String name; //new Sample实例后, name 引用放入栈区里, name 对应的 String 对象放入堆里 19 20 /** 构造方法 */ 21 public Sample(String name) 22 { 23 this .name = name; 24 } 25 26 /** 输出 */ 27 public void printName() //在没有对象的时候,print方法跟随sample类被放入方法区里。 28 { 29 System.out.println(name); 30 } 31 }
13.在Java语言里堆(heap)和栈(stack)里的区别 :
1. 栈(stack)与堆(heap)都是Java用来在Ram中存放数据的地方。与C++不同,Java自动管理栈和堆,程序员不能直接地设置栈或堆。
2. 栈的优势是,存取速度比堆要快,仅次于直接位于CPU中的寄存器。但缺点是,存在栈中的数据大小与生存期必须是确定的,缺乏灵活性。另外,栈数据可以共享(详见下面的介绍)。堆的优势是可以动态地分配内存大小,生存期也不必事先告诉编译器,Java的垃圾收集器会自动收走这些不再使用的数据。但缺点是,由于要在运行时动态分配内存,存取速度较慢。
Java中的2种数据类型:
一种是 基本类型 (primitive types), 共有8类,即int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。这种类型的定义是通过诸如int a = 3; long b = 255L;的形式来定义的,称为自动变量。 自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在 。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。 这些 字面值 的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存 在于栈中 。
栈有一个很重要的特性:存在栈中的数据可以共享。 假设我们同时定义: int a = 3; int b = 3; 编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,如果没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
另一种是 包装类数据, 如Integer, String, Double等将相应的基本数据类型包装起来的类。这些类数据全部 存在于堆中, Java用new()语句来显示地告诉编译器,在运行时才根据需要动态创建,因此比较灵活,但缺点是要占用更多的时间。
15.字面变量的引用和类变量引用有什么区别?
答:8种基本类型的引用变量叫字面变量引用,8种基本数据类型是存储在栈中的,不是堆中,因为字面变量的大小是已知的,且生命周期是已知的。int, short, long, byte, float, double, boolean, char(注意,并没有string的基本类型)。栈有一个很重要的特性--栈的数据是可以共享的。说的就是字面变量内容是可以共享的。
假设我们同时定义: int a = 3; int b = 3; 编译器先处理int a = 3;首先它会在栈中创建一个变量为a的引用,然后查找有没有字面值为3的地址,如果没找到,就开辟一个存放3这个字面值的地址,然后将a指向3的地址。接着处理int b = 3;在创建完b的引用变量后,由于在栈中已经有3这个字面值,便将b直接指向3的地址。这样,就出现了a与b同时均指向3的情况。
这种字面值的引用与类对象的引用不同。假定两个类对象的引用同时指向一个对象,如果一个对象引用变量修改了这个对象的内部状态,那么另一个对象引用变量也即刻反映出这个变化。相反,通过字面值的引用来修改其值,不会导致另一个指向此字面值的引用的值也跟着改变的情况。如上例,我们定义完a与 b的值后,再令a=4;那么,b不会等于4,还是等于3。在编译器内部,遇到a=4;时,它就会重新搜索栈中是否有4的字面值,如果没有,重新开辟地址存放4的值;如果已经有了,则直接将a指向这个地址。因此a值的改变不会影响到b的值。
自动变量存的是字面值,不是类的实例,即不是类的引用,这里并没有类的存在 。如int a = 3; 这里的a是一个指向int类型的引用,指向3这个字面值。 这些 字面值 的数据,由于大小可知,生存期可知(这些字面值固定定义在某个程序块里面,程序块退出后,字段值就消失了),出于追求速度的原因,就存 在于栈中 。
16.程序中new创建的对象为什么在程序运行后才根据new命令在堆中创建内存空间?
答:因为new创建的对象是程序猿写的,大小未知啊。所以编译时期不能创建内存空间,程序实际运行时,才知道啊。new创建的对象不像int这种基本数据类型,在编译时期就知道大小,就可以存储在栈中。
15.java的内存分配条理清楚么?
答: java内存分配条理还是很清楚的,如果要彻底搞懂,可以去查阅JVM相关的书籍。
在java中,内存分配最让人头疼的是String对象,由于其特殊性,所以很多程序员容易搞混淆。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号