Redis底层数据结构
String
如果一个字符串对象保存的是整数值,并且这个整数值可以用long类型来表示,那么将会把字符串对象的编码设置为int,底层数据结构为一个整数

如果字符串对象保存的是一个字符串值,那么底层将会使用SDS(simple dynamic string)来保存。如果这个字符串值的长度小于等于32字节,那么字符串对象将使用embstr编码的方式来保存这个字符串值,反之使用raw编码保存。
embstr编码是专门用于保存短字符串的一种优化编码方式,这种编码和raw编码一样,都使用redisobject结构和sdshdr结构来表示字符串对象,但raw编码会调用两次内存分配函数来分别创建redisobject结构和sdshdr结构,而embstr编码则通过调用一次内存分配函数来分配一块连续的空间,空间中依次包含redisobject和sdshdr两个结构。

embstr编码的字符串对象在执行命令时,产生的效果和raw编码的字符串对象执行命令时产生的效果是相同的,但使用 embstr编码的字符串对象来保存短字符串值有以下好处:
- embstr编码将创建字符串对象所需的内存分配次数从raw编码的两次降低为一次。
- 释放embstr编码的字符串对象只需要调用一次内存释放函数,而释放raw编码的字符串对象需要调用两次内存释放函数。
- 因为embstr编码的字符串对象的所有数据都保存在一块连续的内存里面,所以这种编码的字符串对象比起raw编码的字符串对象能够更好地利用缓存带来的优势。
总结:

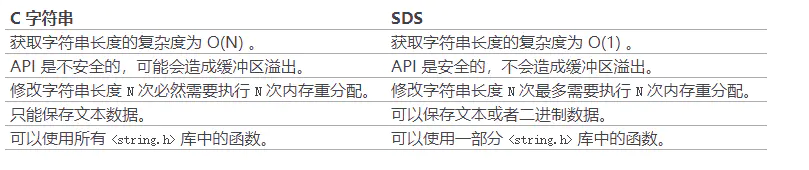
SDS的优势:
- O(1)获取长度 : C字符串需要遍历而SDS中有len可以直接获得
- 防止缓冲区溢出bufferoverflow : 当sds需要对字符串进行修改时,首先借助于len和alloc检查空间是否满足修改所需的要求,如果空间不够的话,SDS会 自动扩展空间 ,避免了像C字符串操作中的覆盖情况
- 有效降低内存分配次数 :C字符串在涉及增加或者清除操作时会改变底层数组的大小造成重新分配、sds使用了 空间预分配和惰性空间释放 机制,说白了就是每次在扩展时是成倍的多分配的,在缩容是也是先留着并不正式归还给OS,这两个机制也是比较好理解的
- 二进制安全 :C语言字符串只能保存ascii码,对于图片、音频等信息无法保存,sds是 二进制安全 的,写入什么读取就是什么,不做任何过滤和限制
List
Redis中的List在版本3.2之前,列表底层的编码是ziplist(压缩列表)和linkedlist(双端列表)实现的,但是在版本3.2之后,重新引入了一个quicklist的数据结构,列表的底层都由quicklist实现。在早期的设计中,当列表对象中元素的长度比较小或者数量比较少的时候,采用ziplist(压缩列表)来存储,当列表对象中元素的长度比较大或者数量比较多的时候,则会转而使用双端列表linkedlist来存储。
quicklist实际上是ziplist与linkedList的混合,它将linkedList按段切分,每一个段使用ziplist来存储。多个ziplist使用双向指针串联起来。

ziplist(压缩列表)和linkedlist(双端列表)优缺点:
- 双向链表linkedlist便于在表的两端进行push和pop操作,在插入节点上复杂度很低,但是它的内存开销比较大。首先,它在每个节点上除了要保存数据之外,还要额外保存两个指针;其次,双向链表的各个节点是单独的内存块,地址不连续,节点多了容易产生内存碎片。
- ziplist存储在一段连续的内存上,所以存储效率很高。但是,它不利于修改操作,插入和删除操作需要频繁的申请和释放内存。特别是当ziplist长度很长的时候,一次realloc可能会导致大批量的数据拷贝。
quicklist介绍待完善
Hash
哈希对象的编码可以是ziplist(压缩列表)或者hashtable(字典)。
ziplist编码的哈希对象使用压缩列表作为底层实现,每当有新的键值对要加入到哈希对象时,程序会先将保存了键的压缩列表节点推入到压缩列表表尾,然后再将保存了值的压缩列表节点推入到压缩列表表尾,因此:
- 保存了同一键值对的两个节点总是紧挨在一起,保存键的节点在前,保存值的节点在后;
- 先添加到哈希对象中的键值对会被放在压缩列表的表头方向,而后来添加到哈希对象中的键值对会被放在压缩列表的表尾方向。

hashtable编码的哈希对象使用字典作为底层实现,哈希对象中的每个键值对都使用一个字典键值对来保存:
- 字典的每个键都是一个字符串对象,对象中保存了键值对的键;
- 字典的每个值都是一个字符串对象,对象中保存了键值对的值。
当哈希对象可以同时满足以下两个条件时,哈希对象使用 ziplist编码:
- 哈希对象保存的所有键值对的键和值的字符串长度都小于64字节;
- 哈希对象保存的键值对数量小于512个;
不能满足这两个条件的哈希对象需要使用hashtable编码。
Set
集合对象的编码可以是intset(整数集合)或者hashtable(字典)。
intset编码的集合对象使用整数集合作为底层实现,集合对象包含的所有元素都被保存在整数集合里面。

hashtable编码的集合对象使用字典作为底层实现,字典的每个键都是符串对象,每个字符串对象包含了一个集合元素,而字典的值则全部被设置为NULL。

当集合对象可以同时满足以下两个条件时,对象使用intset编码:
- 集合对象保存的所有元素都是整数值;
- 集合对象保存的元素数量不超过512个。
不能满足这两个条件的集合对象需要使用hashtable编码。
ZSet
有序集合的编码可以是ziplist(压缩列表)或者skiplist(跳表)。
ziplist编码使用压缩列表作为底现,每个集合元素使用两个紧挨在一起的压缩列表节点来保存,第一个节点保存元素的成员( member),而第二个元素则保存元素的分值( score)。
压缩列表内的集合元素按分值从小到大进行排序,分值较小的元素被放置在靠近表头的方向,而分值较大的元素则被放置在靠近表尾的方向。

当有序集合对象可以同时满足以下两个条件时,对象使用ziplist编码:
- 有序集合保存的元素数量小于128个;
- 有序集合保存的所有元素成员的长度都小于64字节;
不能满足以上两个条件的有序集合对象将使用skiplist编码。
摘抄自《Redis设计与实现》

