


GitlabCI学习笔记之五:GitLabRunner pipeline语法之cache
cache 缓存
用来指定需要在job之间缓存的文件或目录。只能使用该项目工作空间内的路径。不要使用缓存在阶段之间传递工件,因为缓存旨在存储编译项目所需的运行时依赖项。
如果在job范围之外定义了cache ,则意味着它是全局设置,所有job都将使用该定义。如果未全局定义或未按job定义则禁用该功能。
1.cache:paths
使用paths指令选择要缓存的文件或目录,路径是相对于项目目录,不能直接链接到项目目录之外。
$CI_PROJECT_DIR 项目目录
示例:在job build中定义缓存,将会缓存target目录下的所有.jar文件。
build:
script: test
cache:
paths:
- target/*.jar
如果job中定义,则会覆盖全局定cache:paths。以下实例将缓存binaries目录。

cache:
paths:
- my/files
build:
script: echo "hello"
cache:
key: build
paths:
- target/
由于缓存是在job之间共享的,如果不同的job使用不同的路径就出现了上一个缓存被覆盖的问题。如何让不同的job缓存不同的cache呢?设置不同的cache:key。
2.cache:key 缓存标记
为缓存做个标记,可以配置job、分支为key来实现分支、作业特定的缓存。为不同 job 定义了不同的 cache:key 时, 会为每个 job 分配一个独立的 cache。cache:key变量可以使用任何预定义变量,默认default ,从GitLab 9.0开始,默认情况下所有内容都在管道和作业之间共享。
示例:按照分支设置缓存
cache:
key: ${CI_COMMIT_REF_SLUG}
files: 文件发生变化自动重新生成缓存(files最多指定两个文件),提交的时候检查指定的文件。
示例:根据指定的文件生成密钥计算SHA校验和,如果文件未改变值为default。
cache:
key:
files:
- Gemfile.lock
- package.json
paths:
- vendor/ruby
- node_modules
prefix: 允许给定prefix的值与指定文件生成的秘钥组合。
示例:在这里定义了全局的cache,如果文件发生变化则值为 rspec-xxx111111111222222 ,未发生变化为rspec-default。
cache:
key:
files:
- Gemfile.lock
prefix: ${CI_JOB_NAME}
paths:
- vendor/ruby
rspec:
script:
- bundle exec rspec
例如,添加$CI_JOB_NAME prefix将使密钥看起来像: rspec-feef9576d21ee9b6a32e30c5c79d0a0ceb68d1e5 ,并且作业缓存在不同分支之间共享,如果分支更改了Gemfile.lock ,则该分支将为cache:key:files具有新的SHA校验和. 将生成一个新的缓存密钥,并为该密钥创建一个新的缓存. 如果Gemfile.lock未发生变化 ,则将前缀添加default ,因此示例中的键为rspec-default 。
3.cache:policy 策略
默认:在执行开始时下载缓存文件,并在结束时重新上传缓存文件。称为” pull-push缓存策略.
policy: pull 跳过下载步骤
policy: push 跳过上传步骤
示例
stages:
- setup
- test
prepare:
stage: setup
cache:
key: gems
paths:
- vendor/bundle
script:
- bundle install --deployment
rspec:
stage: test
cache:
key: gems
paths:
- vendor/bundle
policy: pull
script:
- bundle exec rspec ...
4.综合示例:全局缓存
before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
cache:
paths:
- target/
stages:
- build
- test
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
tags:
- build
only:
- master
script:
- ls
- id
- mvn clean package -DskipTests
- ls target
- echo "$DOMAIN"
- false && true ; exit_code=$?
- if [ $exit_code -ne 0 ]; then echo "Previous command failed"; fi;
- sleep 2;
after_script:
- echo "after script in job"
unittest:
stage: test
tags:
- build
only:
- master
script:
- echo "run test"
- echo 'test' >> target/a.txt
- ls target
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- build
only:
- master
script:
- echo "run deploy"
- ls target
retry:
max: 2
when:
- script_failure
after_script:
- echo "after-script"
Pipeline日志分析
build作业运行时会对项目代码打包,然后生成target目录。作业结束创建缓存。
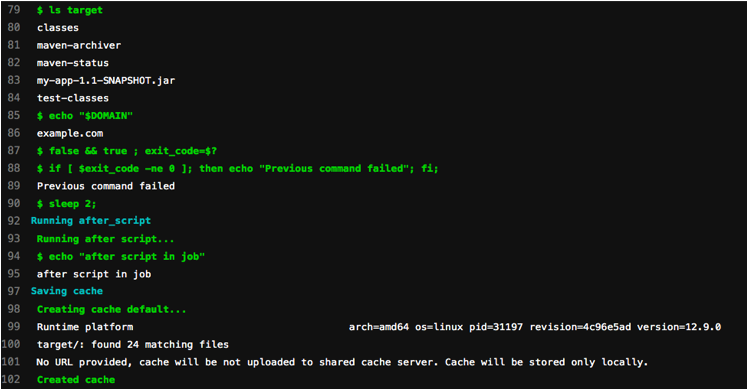
开始第二个作业test,此时会把当前目录中的target目录删除掉(因为做了git 对比)。
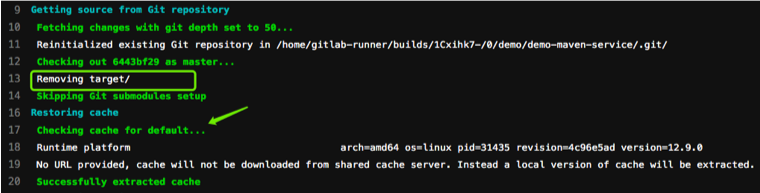
开始第三个作业,同样先删除了target目录,然后获取了第二个作业的缓存。最后生成了当前的缓存。

结论: 全局缓存生效于未在作业中定义缓存的所有作业,这种情况如果每个作业都对缓存目录做了更改,会出现缓存被覆盖的场景。
5.综合示例:控制缓存策略
例如build阶段我们需要生成新的target目录内容,可以优化设置job运行时不下载缓存。

before_script:
- echo "before-script!!"
variables:
DOMAIN: example.com
cache:
paths:
- target/
stages:
- build
- test
- deploy
build:
before_script:
- echo "before-script in job"
stage: build
tags:
- build
only:
- master
script:
- ls
- id
- cat target/a.txt #此时流水线会报错,应用设置了缓存策略为pull,也就是不下载缓存,target目录是第一次运行后缓存生成的,如果不下载则目录不存在cat命令会报错
- mvn clean package -DskipTests
- ls target
- echo "$DOMAIN"
- false && true ; exit_code=$?
- if [ $exit_code -ne 0 ]; then echo "Previous command failed"; fi;
- sleep 2;
after_script:
- echo "after script in job"
cache:
policy: pull #不下载缓存,因为build节点就是生成缓存的,实际使用过程中应当禁止下载缓存
unittest:
stage: test
tags:
- build
only:
- master
script:
- echo "run test"
- echo 'test' >> target/a.txt
- ls target
- cat target/a.txt
retry:
max: 2
when:
- script_failure
deploy:
stage: deploy
tags:
- build
only:
- master
script:
- cat target/a.txt
- echo "run deploy"
- ls target
- echo "deploy" >> target/a.txt
retry:
max: 2
when:
- script_failure
after_script:
- echo "after-script"


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!