


Hadoop高可用集群搭建
一、HDFS HA简介
1.1 QJM简介
1.Quorum Journal Manager(仲裁日志管理器),是Hadoop官方推荐的HDFS HA解决方案之一
2.使用zookeeper中ZKFC来实现主备切换;
3.使用Journal Node(JN)集群实现edits log的共享以达到数据同步的目的
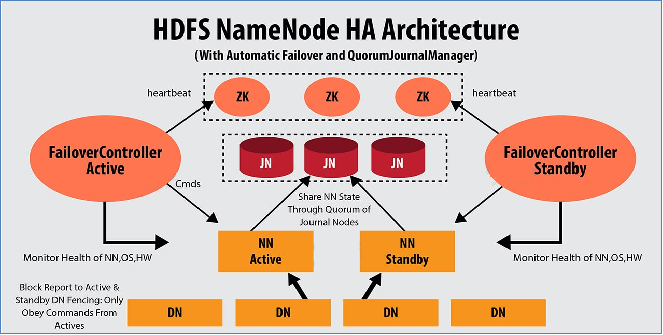
1.2 主备切换问题解决方案--ZKFailoverController(zkfc)
ZK Failover Controller(ZKFC)是一个ZooKeeper客户端。主要职责:
1.监视和管理NameNode健康状态
2.ZKFC通过命令监视的NameNode节点及机器的健康状态。
3.维持和ZK集群联系
如果本地NameNode运行状况良好,并且ZKFC看到当前没有其他节点持有锁znode,它将自己尝试获取该锁。如果成功,则表明它“赢得了选举”,并负责运行故障转移以使其本地NameNode处于Active状态。如果已经有其他节点持有锁,zkfc选举失败,则会对该节点注册监听,等待下次继续选举。
1.3 主备脑裂问题解决方案-Fencing(隔离)机制
故障转移过程也就是俗称的主备角色切换的过程,切换过程中最怕的就是脑裂的发生。因此需要Fencing机制来避免,将先前的Active节点隔离,然后将Standby转换为Active状态。
Hadoop公共库中对外提供了两种Fenching实现,分别是sshfence和shellfence(缺省实现)。
sshfence是指通过ssh登陆目标节点上,使用命令fuser将进程杀死(通过tcp端口号定位进程pid,该方法比jps命令更准确);
shellfence是指执行一个用户事先定义的shell命令(脚本)完成隔离。
1.4 主备数据状态同步问题解决
Journal Node(JN)集群是轻量级分布式系统,主要用于高速读写数据、存储数据。
通常使用2N+1台JournalNode存储共享Edits Log(编辑日志)。--底层类似于zk的分布式一致性算法。
任何修改操作在 Active NN上执行时,JournalNode进程同时也会记录edits log到至少半数以上的JN中,这时 Standby NN 监测到JN 里面的同步log发生变化了会读取JN里面的edits log,然后重演操作记录同步到自己的目录镜像树里面。

二、集群角色规划及基础环境要求
角色规划

基础环境要求

1.修改Linux主机名
2.修改IP
3.修改主机名和IP的映射关系
4.关闭防火墙
5.ssh免登陆
6.安装JDK,配置环境变量等
7.集群时间同步
8.配置主备NN之间的互相免密登录
9.安装fuser nc命令,Fence状态检测时需要 #yum install nc psmisc -y
三、安装配置Hadoop
此篇文档及Hadoop相关文档相关软件包统一在此百度网盘:
链接:https://pan.baidu.com/s/11F4THdIfgrULMn2gNcObRA?pwd=cjll
3.1 解压及创建软链接
tar xf hadoop-3.1.4-bin-snappy-CentOS7.tar.gz -C /usr/local/
cd /usr/local/
ln -sv hadoop-3.1.4 hadoop
3.2 全局环境变量配置
vim /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
. /etc/profile.d/hadoop.sh
3.3 修改hadoop-env.sh文件,设置运行环境变量及运行用户
export JAVA_HOME=/usr/local/java
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_ZKFC_USER=root
3.4 修改core-site.xml
主要注意A集群名称要和hdfs-site.xml中的配置保持一致
<configuration>
<!-- HA集群名称,自定义,该值要和hdfs-site.xml中的配置保持一致 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop运行时产生文件的存储路径 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/Hadoop/ha-hadoop</value>
</property>
<!-- 设置HDFS web UI访问用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- ZooKeeper集群的地址和端口-->
<property>
<name>ha.zookeeper.quorum</name>
<value>hdp01.dialev.com:2181,hdp02.dialev.com:2181,hdp03.dialev.com:2181</value>
</property>
</configuration>
3.5 修改hdfs-site.xml
主要注意集群名称和core-site中保持一致,集群相关节点及属性name cluster名称记得替换,再一次检查节点之间是否可以免密登录
<configuration>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hdp01.dialev.com:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hdp01.dialev.com:9870</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hdp02.dialev.com:8020</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hdp02.dialev.com:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hdp01.dialev.com:8485;hdp02.dialev.com:8485;hdp03.dialev.com:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 生产环境应当和数据盘分开-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/Hadoop/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定该集群出故障时,哪个实现类负责执行故障切换 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 避免脑裂,配置隔离机制方法-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
3.6 修改mapred-site.xml
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
3.7 修改 yarn-site.xml
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hdp01.dialev.com</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hdp02.dialev.com</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hdp01.dialev.com:2181,hdp02.dialev.com,hdp03.dialev.com:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
3.8 修改workers
hdp01.dialev.com
hdp02.dialev.com
hdp03.dialev.com
3.9 同步配置到其他节点
scp -r hadoop-3.1.4 192.168.1.132:/usr/local/
scp -r hadoop-3.1.4 192.168.1.133:/usr/local/
#其他节点做好软连接
cd /usr/local/
ln -sv hadoop-3.1.4 hadoop
四、启动服务
4.1 启动ZK
参考此文档部署,不再赘述:https://www.cnblogs.com/panwenbin-logs/p/10369402.html
4.2 启动journalnode
# 在每一个节点上执行
hadoop-daemon.sh start journalnode
jps #运行jps命令检验,多了JournalNode进程
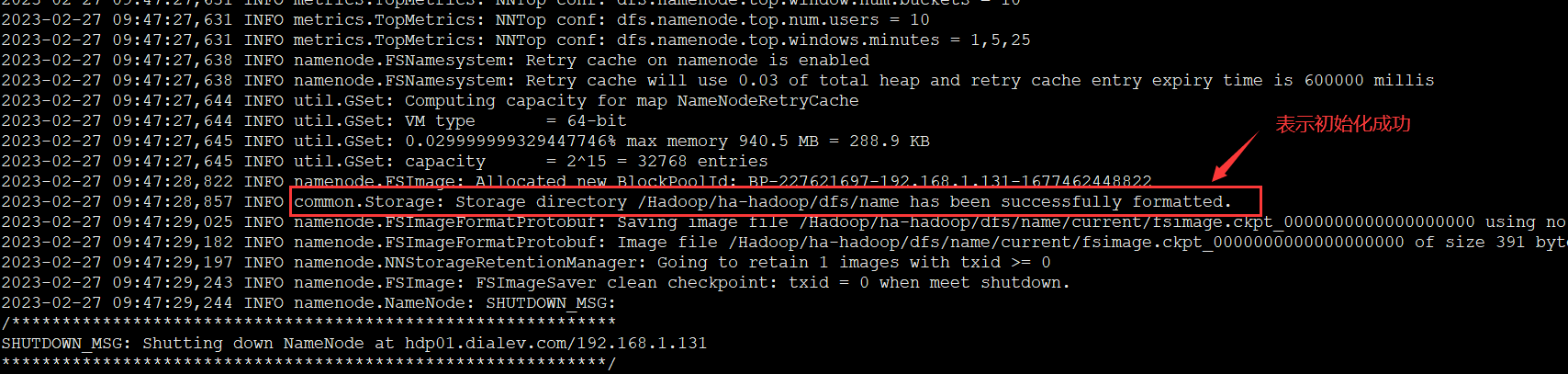
4.3 格式namenode
#在hdp01上执行命令:
hdfs namenode -format
#格式化后会在根据core-site.xml中的hadoop.tmp.dir配置的目录下生成个hdfs初始化文件,
#在hdp01启动namenode进程
hdfs --daemon start namenode
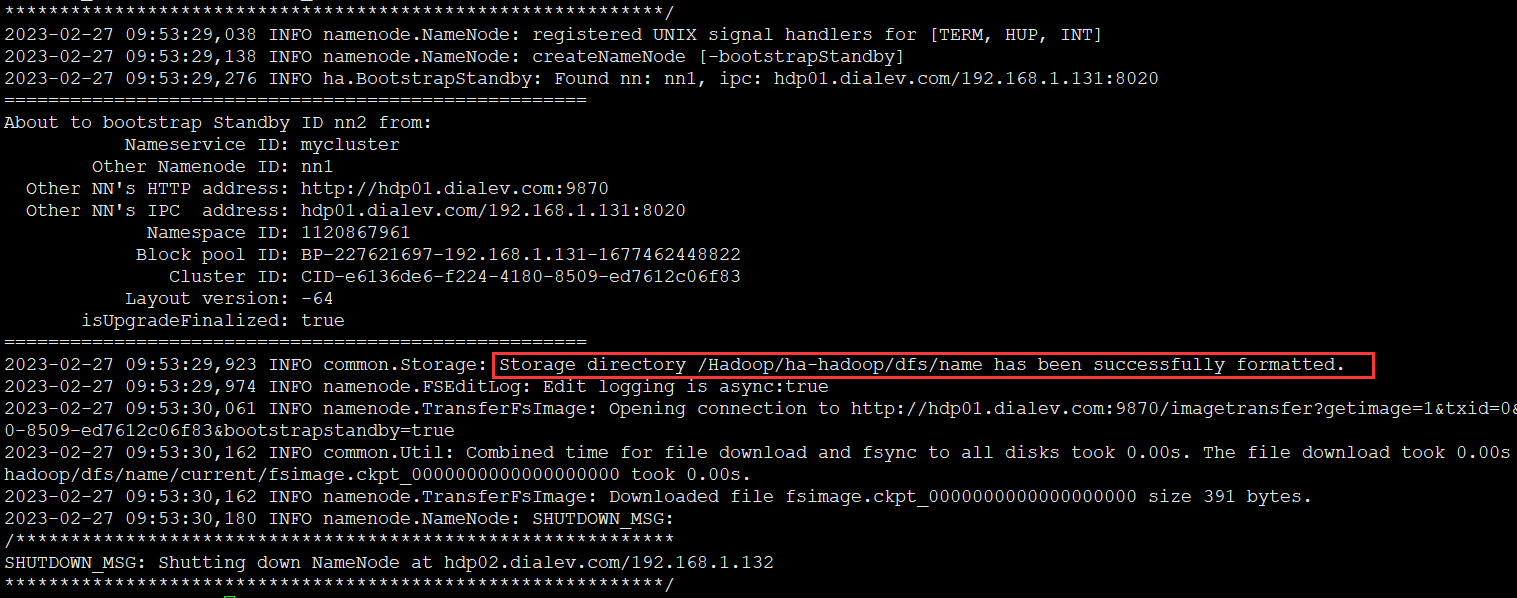
4.4 hdp02进行元数据同步
#在hdp02上进行元数据同步
hdfs namenode -bootstrapStandby
4.5 格式化ZKFC
# namenode首次选举需要用户指定,下面命令在哪个节点执行,哪个节点就是active,当前我们在hdp01即可
hdfs zkfc -formatZK

4.6 启动 HDFS
# 在hdp01上执行
start-dfs.sh
4.7 启动
start-yarn.sh
# 还需要手动在standby上手动启动备份的 resourcemanager
yarn-daemon.sh start resourcemanager
五、集群验证
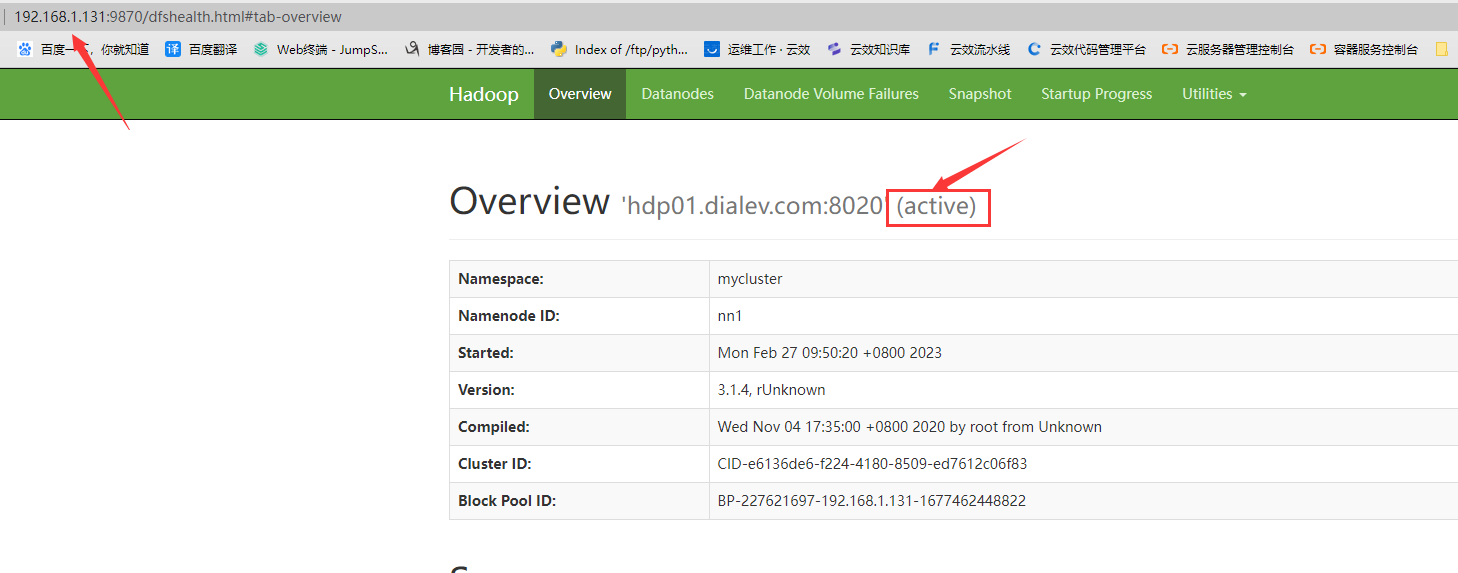
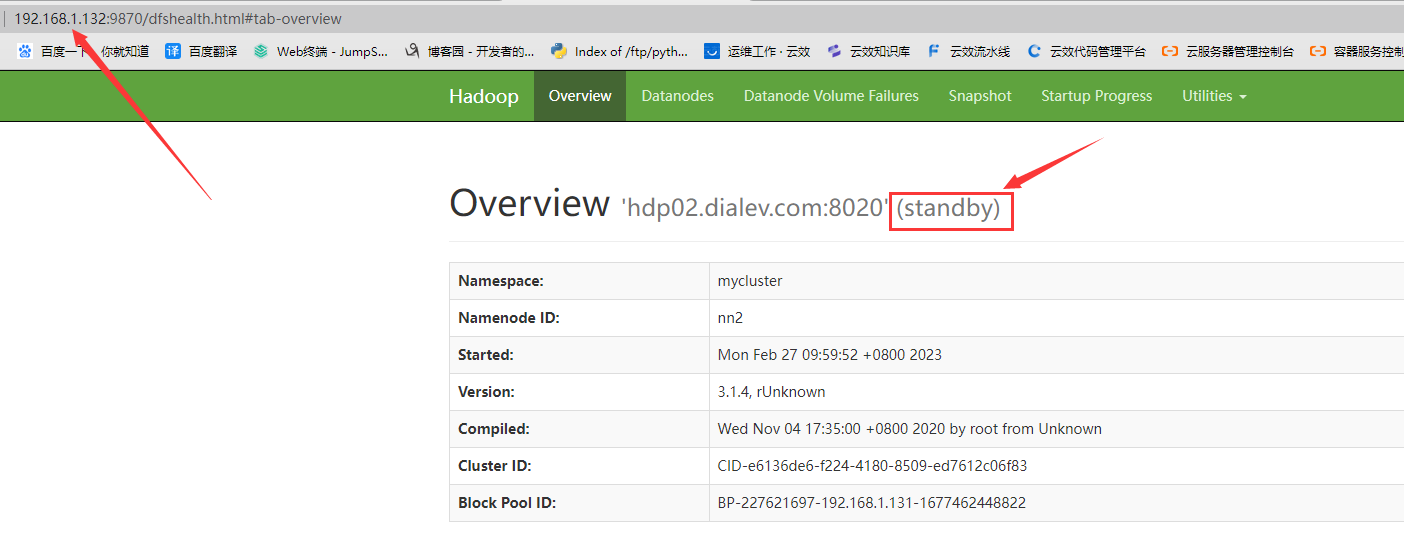
5.1 浏览器访问namenode web界面
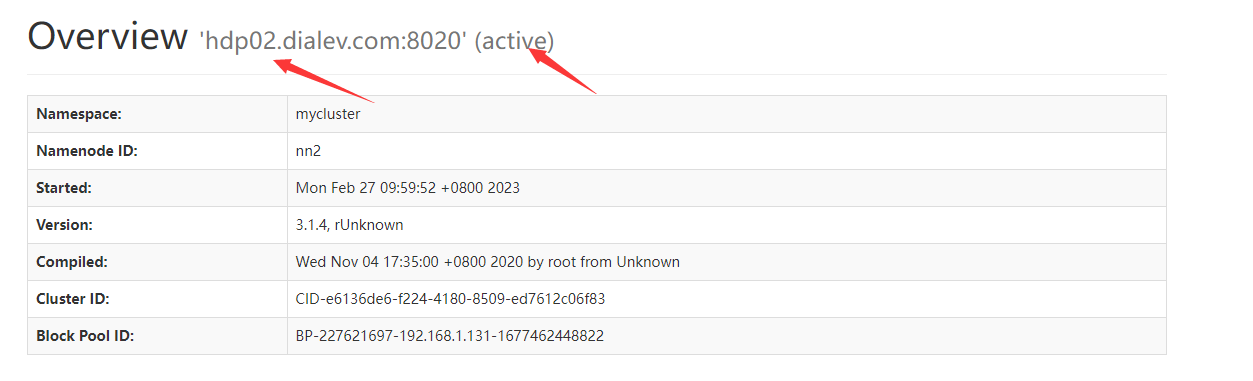
可以看到节点1当前状态为active,节点2为standby
5.2 查看集群操作是否正常
hdfs dfsadmin -report
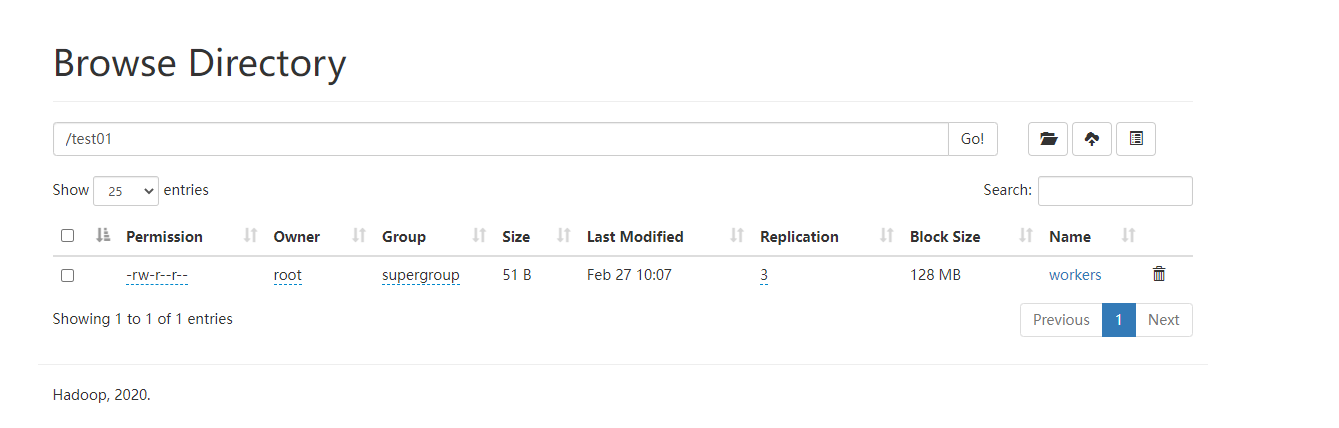
hadoop fs -mkdir /test01
hadoop fs -put workers /test01
hadoop fs -ls /test01
5.3 验证namenode工作状态
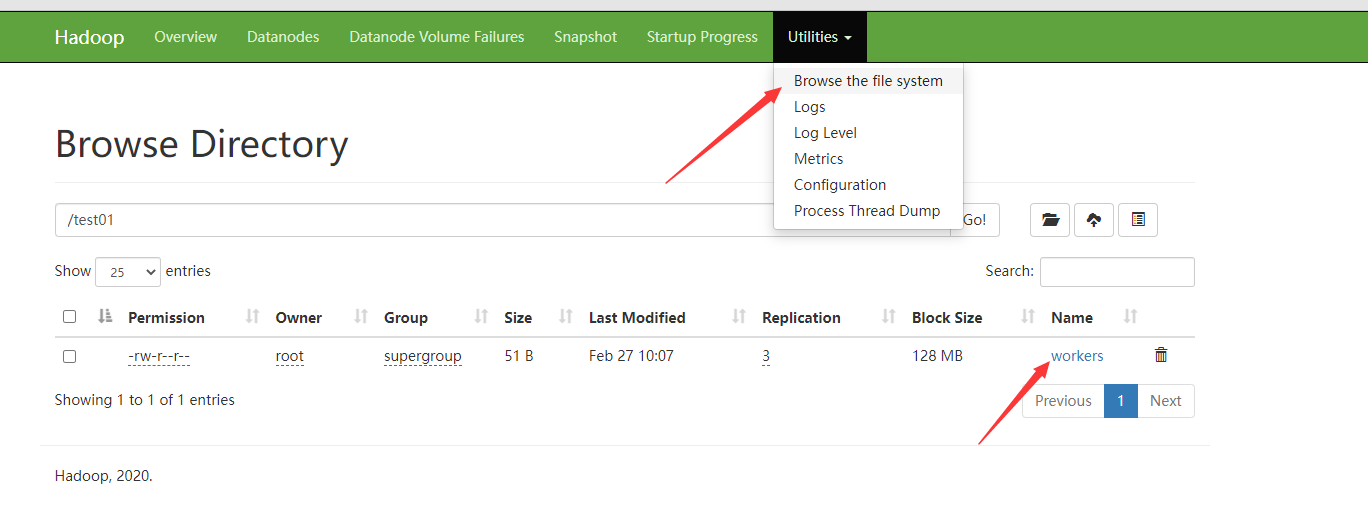
节点2报错
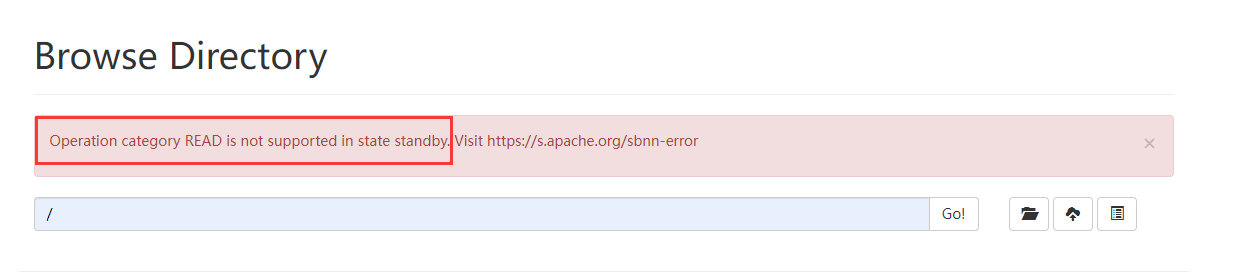
5.4 验证namenode故障转移
# 杀死namenode active节点进程
[root@hdp01 hadoop]# jps |grep -i namenode
50305 NameNode
[root@hdp01 hadoop]# kill 50305
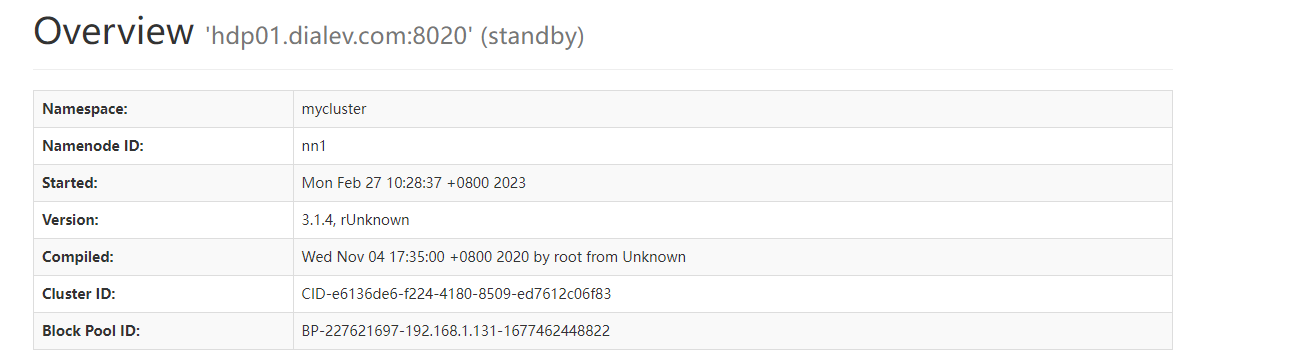
节点1浏览器无法打开,查看节点2,可以看到节点2切换到active
数据也可以正常浏览
hdfs --daemon start namenode
查看节点1状态,自动切换为standby
"一劳永逸" 的话,有是有的,而 "一劳永逸" 的事却极少


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具