


部署Redis4.x单机版及配置RDB和AOF持久化
一、环境及软件
| OS | soft version |
| CentOS 7.5 | redis-4.0.12(目前是4.x最新) |
二、下载及编译Redis

[root@localhost ~]# wget http://download.redis.io/releases/redis-4.0.12.tar.gz
[root@localhost ~]# tar xf redis-4.0.12.tar.gz -C /usr/local/
[root@localhost ~]# cd /usr/local/
[root@localhost local]# ln -sv redis-4.0.12/ redis
[root@localhost local]# cd redis
[root@localhost redis]#less README.md
[root@localhost redis]#yum install tcl -y #安装依赖,需要8.5及以上版本,如果yum没有可以到官网去下载源码编译安装 官方地址:https://sourceforge.net/projects/tcl/files/Tcl/
[root@localhost redis]#make
[root@localhost redis]#make test
[root@localhost redis]#make install
三、Redis生产启动方案(centos6)
如果一般的学习,那就随便用redis-server启动一下redis,做一些实验,这样的话,没什么意义 要把redis作为一个系统的daemon进程去运行的,每次系统启动,redis进程一起启动 (1)redis utils目录下,有个redis_init_script脚本 (2)将redis_init_script脚本拷贝到linux的/etc/init.d目录中,将redis_init_script重命名为redis_6379,6379是我们希望这个redis实例监听的端口号 (3)修改redis_6379脚本的第6行的REDISPORT,设置为相同的端口号(默认就是6379) (4)创建两个目录:/etc/redis(存放redis的配置文件),/var/redis/6379(存放redis的持久化文件) (5)修改redis配置文件(默认在根目录下,redis.conf),拷贝到/etc/redis目录中,修改名称为6379.conf (6)修改redis.conf中的部分配置为生产环境
bind 0.0.0.0 绑定的端口 daemonize yes 让redis以daemon进程运行 pidfile /var/run/redis_6379.pid 设置redis的pid文件位置 port 6379 设置redis的监听端口号 dir /var/redis/6379 设置持久化文件的存储位置,需要手动创建 (7)启动redis,执行cd /etc/init.d, chmod 777 redis_6379,./redis_6379 start (8)确认redis进程是否启动,ps -ef | grep redis (9)让redis跟随系统启动自动启动 在redis_6379脚本中,最上面,加入两行注释 # chkconfig: 2345 90 10 # description: Redis is a persistent key-value database chkconfig redis_6379 on
centos7(其余参照centos6)
[root@localhost ~]# mkdir /etc/redis/ #存放配置文件(redis.service配置文件指定)
[root@localhost ~]# mkdir /var/redis #存放持久存储日志目录(dir 指令)
[root@localhost system]# cd /usr/lib/systemd/system [root@localhost system]# cat redis.service [Unit] Description=Redis persistent key-value database After=network.target After=network-online.target Wants=network-online.target [Service] Type=forking ExecStart=/usr/local/bin/redis-server /etc/redis/redis_6379.conf ExecReload=/bin/kill -s HUP $MAINPID ExecStop=/bin/kill -s QUIT $MAINPID PIDFile=/var/run/redis_6379.pid PrivateTmp=true [Install] WantedBy=multi-user.target [root@localhost system]# systemctl enable redis [root@localhost system]# systemctl start redis
redis-cli的简单使用
redis-cli SHUTDOWN,连接本机的6379端口停止redis进程 redis-cli -h 127.0.0.1 -p 6379 SHUTDOWN,制定要连接的ip和端口号 redis-cli PING,ping redis的端口,看是否正常 redis-cli,进入交互式命令行 SET k1 v1 GET k1
四、设置Redis RDB持久化及数据恢复
1.配置
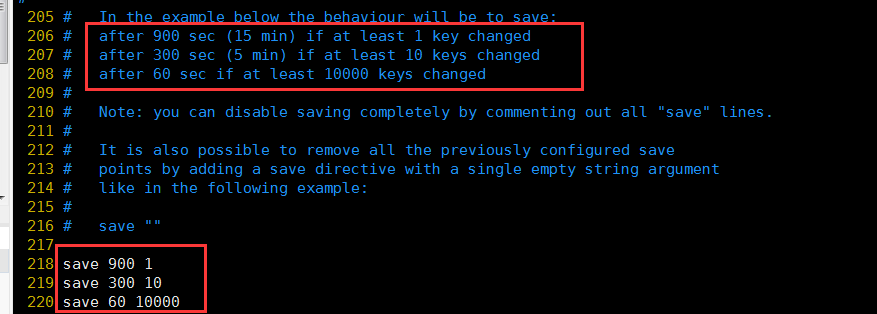
RDB默认配置,具体含义看英文注解。如果满足配置中的需求,那么就生成一个新的dump.rdb文件,就是当前redis内存中完整的数据快照,这个操作也被称之为snapshotting,快照也可以手动调用save或者bgsave命令,同步或异步执行rdb快照生成
save可以设置多个,就是多个snapshotting检查点,每到一个检查点,就会去check一下,是否有指定的key数量发生了变更,如果有,就生成一个新的dump.rdb文件
2、RDB持久化机制的工作流程
(1)redis根据配置自己尝试去生成rdb快照文件 (2)fork一个子进程出来 (3)子进程尝试将数据dump到临时的rdb快照文件中 (4)完成rdb快照文件的生成之后,就替换之前的旧的快照文件 dump.rdb,每次生成一个新的快照,都会覆盖之前的老快照
3、基于RDB持久化机制的数据恢复实验
(1)在redis中保存几条数据,立即停掉redis进程,然后重启redis,看看刚才插入的数据还在不在
[root@localhost ~]# redis-cli 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> set k2 v2 OK 127.0.0.1:6379> set k3 v3 OK 127.0.0.1:6379> exit [root@localhost ~]# redis-cli SHUTDOWN [root@localhost ~]# redis-cli 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k2 "v2"
#可以看到重启后数据还在,这是因为通过redis-cli SHUTDOWN这种方式去停掉redis,其实是一种安全退出的模式,redis在退出的时候会将内存中的数据立即生成一份完整的rdb快照
(2)在redis中再保存几条新的数据,用kill -9粗暴杀死redis进程,模拟redis故障异常退出,导致内存数据丢失的场景
[root@localhost ~]# redis-cli SHUTDOWN [root@localhost ~]# systemctl start redis [root@localhost ~]# [root@localhost ~]# [root@localhost ~]# redis-cli 127.0.0.1:6379> set k4 v4 OK 127.0.0.1:6379> set k5 v5 OK 127.0.0.1:6379> exit [root@localhost ~]# kill -9 `ps aux|grep redis|grep -v grep|awk '{print $2}'` [root@localhost ~]# ps aux|grep redis root 12732 0.0 0.0 112664 972 pts/0 S+ 22:30 0:00 grep --color=auto redis [root@localhost ~]# systemctl start redis [root@localhost ~]# ps aux|grep redis root 12740 0.1 0.4 145260 7564 ? Ssl 22:30 0:00 /usr/local/bin/redis-server 0.0.0.0:6379 root 12745 0.0 0.0 112664 972 pts/0 S+ 22:30 0:00 grep --color=auto redis [root@localhost ~]# redis-cli 127.0.0.1:6379> get k4 (nil) 127.0.0.1:6379> get k5 (nil)
# 最后结果是redis进程异常被杀掉,几条最新的数据就丢失了
五、AOF持久化的配置
1.AOF持久化配置
AOF持久化,默认是关闭的,默认是打开RDB持久化
appendonly yes,可以打开AOF持久化机制,在生产环境里面,一般来说AOF都是要打开的,除非你说随便丢个几分钟的数据也无所谓
打开AOF持久化机制之后,redis每次接收到一条写命令,就会写入日志文件中,当然是先写入os cache的,然后每隔一定时间再fsync一下
而且即使AOF和RDB都开启了,redis重启的时候,也是优先通过AOF进行数据恢复的,因为aof数据比较完整
可以配置AOF的fsync策略,有三种策略可以选择:
一种是每次写入一条数据就执行一次fsync;
always: 每次写入一条数据,立即将这个数据对应的写日志fsync到磁盘上去,性能非常非常差,吞吐量很低; 确保说redis里的数据一条都不丢,那就只能这样了
一种是每隔一秒执行一次fsync;
everysec: 每秒将os cache中的数据fsync到磁盘,这个最常用的,生产环境一般都这么配置,性能很高,QPS还是可以上万的
一种是不主动执行fsync
no: 仅仅redis负责将数据写入os cache就撒手不管了,然后后面os自己会时不时有自己的策略将数据刷入磁盘,不可控了
2、AOF持久化的数据恢复实验
[root@localhost ~]# vim /etc/redis/redis_6379.conf appendonly yes appendfilename "appendonly.aof" appendfsync everysec [root@localhost ~]# systemctl stop redis [root@localhost ~]# systemctl start redis [root@localhost ~]# redis-cli 127.0.0.1:6379> get k1 #为什么现在k1的值没有了? (nil) 127.0.0.1:6379> set k1 v1 OK 127.0.0.1:6379> set k2 v2 OK 127.0.0.1:6379> exit [root@localhost ~]# kill -9 `ps aux|grep redis|grep -v grep|awk '{print $2}'` [root@localhost ~]# systemctl start redis [root@localhost ~]# redis-cli 127.0.0.1:6379> get k1 "v1" 127.0.0.1:6379> get k2 "v2" #kill -9杀掉redis进程,重新启动redis进程,发现数据被恢复回来了,就是从AOF文件中恢复回来的 #redis进程启动的时候,直接就会从appendonly.aof中加载所有的日志,把内存中的数据恢复回来
#在有rdb的dump和aof的appendonly的同时,rdb里也有部分数据,aof里也有部分数据,这个时候其实会发现,rdb的数据不会恢复到内存中
3、AOF rewrite
redis中的数据其实有限的,很多数据可能会自动过期,可能会被用户删除,可能会被redis用缓存清除的算法清理掉 redis中的数据会不断淘汰掉旧的,就一部分常用的数据会被自动保留在redis内存中 所以可能很多之前的已经被清理掉的数据,对应的写日志还停留在AOF中,AOF日志文件就一个,会不断的膨胀,到很大很大 所以AOF会自动在后台每隔一定时间做rewrite操作,比如日志里已经存放了针对100w数据的写日志了; redis内存只剩下10万; 基于内存中当前的10万数据构建一套最新的日志,到AOF中; 覆盖之前的老日志; 确保AOF日志文件不会过大,保持跟redis内存数据量一致 redis 2.4之前,还需要手动,开发一些脚本,crontab,通过BGREWRITEAOF命令去执行AOF rewrite,但是redis 2.4之后,会自动进行rewrite操作 在redis.conf中,可以配置rewrite策略 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb 比如说上一次AOF rewrite之后,是128mb 然后就会接着128mb继续写AOF的日志,如果发现增长的比例,超过了之前的100%,256mb,就可能会去触发一次rewrite 但是此时还要去跟min-size,64mb去比较,256mb > 64mb,才会去触发rewrite (1)redis fork一个子进程 (2)子进程基于当前内存中的数据,构建日志,开始往一个新的临时的AOF文件中写入日志 (3)redis主进程,接收到client新的写操作之后,在内存中写入日志,同时新的日志也继续写入旧的AOF文件 (4)子进程写完新的日志文件之后,redis主进程将内存中的新日志再次追加到新的AOF文件中 (5)用新的日志文件替换掉旧的日志文件
4、AOF破损文件的修复
如果redis在append数据到AOF文件时,机器宕机了,可能会导致AOF文件破损
用redis-check-aof --fix命令来修复破损的AOF文件
[root@localhost ~]# redis-check-aof --fix /var/redis/appendonly.aof
AOF analyzed: size=81, ok_up_to=81, diff=0
AOF is valid
5、AOF和RDB同时工作
(1)如果RDB在执行snapshotting操作,那么redis不会执行AOF rewrite; 如果redis再执行AOF rewrite,那么就不会执行RDB snapshotting (2)如果RDB在执行snapshotting,此时用户执行BGREWRITEAOF命令,那么等RDB快照生成之后,才会去执行AOF rewrite (3)同时有RDB snapshot文件和AOF日志文件,那么redis重启的时候,会优先使用AOF进行数据恢复,因为其中的日志更完整
六、企业级的数据备份方案
1.备份方案
RDB非常适合做冷备,每次生成之后,就不会再有修改了 数据备份方案 (1)写crontab定时调度脚本去做数据备份 (2)每小时都copy一份rdb的备份,到一个目录中去,仅仅保留最近48小时的备份 (3)每天都保留一份当日的rdb的备份,到一个目录中去,仅仅保留最近1个月的备份 (4)每次copy备份的时候,都把太旧的备份给删了 (5)每天晚上将当前服务器上所有的数据备份,发送一份到远程的云服务上去
2.数据恢复方案
(1)如果是redis进程挂掉,那么重启redis进程即可,直接基于AOF日志文件恢复数据,不演示了,在AOF数据恢复那一块,演示了,fsync everysec,最多就丢一秒的数 (2)如果是redis进程所在机器挂掉,那么重启机器后,尝试重启redis进程,尝试直接基于AOF日志文件进行数据恢复,AOF没有破损,也是可以直接基于AOF恢复的,AOF append-only,顺序写入,如果AOF文件破损,那么用redis-check-aof fix (3)如果redis当前最新的AOF和RDB文件出现了丢失/损坏,那么可以尝试基于该机器上当前的某个最新的RDB数据副本进行数据恢复,当前最新的AOF和RDB文件都出现了丢失/损坏到无法恢复,找到RDB最新的一份备份,小时级的备份可以了,小时级的肯定是最新的,copy到redis里面去,就可以恢复到某一个小时的数据
3.数据恢复的坑
appendonly.aof + dump.rdb,优先用appendonly.aof去恢复数据,但是我们发现redis自动生成的appendonly.aof是没有数据的
然后我们自己的dump.rdb是有数据的,但是明显没用我们的数据
redis启动的时候,自动重新基于内存的数据,生成了一份最新的rdb快照,直接用空的数据,覆盖掉了我们有数据的,拷贝过去的那份dump.rdb
你停止redis之后,其实应该先删除appendonly.aof,然后将我们的dump.rdb拷贝过去,然后再重启redis
很简单,就是虽然你删除了appendonly.aof,但是因为打开了aof持久化,redis就一定会优先基于aof去恢复,即使文件不在,那就创建一个新的空的aof文件
停止redis,暂时在配置中关闭aof,然后拷贝一份rdb过来,再重启redis,数据能不能恢复过来,可以恢复过来
脑子一热,再关掉redis,手动修改配置文件,打开aof,再重启redis,数据又没了,空的aof文件,所有数据又没了
在数据安全丢失的情况下,基于rdb冷备,如何完美的恢复数据,同时还保持aof和rdb的双开
停止redis,关闭aof,拷贝rdb备份,重启redis,确认数据恢复,直接在命令行热修改redis配置,打开aof,这个redis就会将内存中的数据对应的日志,写入aof文件中
此时aof和rdb两份数据文件的数据就同步了,同步后关闭Redis,修改配置文件开启aof,再启动Redis就OK了
热修改命令
[root@localhost ~]# redis-cli 127.0.0.1:6379> CONFIG GET appendonly 1) "appendonly" 2) "no" 127.0.0.1:6379> CONFIG SET appendonly yes
"一劳永逸" 的话,有是有的,而 "一劳永逸" 的事却极少


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· Linux系列:如何用heaptrack跟踪.NET程序的非托管内存泄露
· 开发者必知的日志记录最佳实践
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· Manus的开源复刻OpenManus初探
· 写一个简单的SQL生成工具