zookeeper
一、Zookeeper简介
1.1 简介
Zookeeper 是一个开源的分布式协调服务,目前由 Apache 进行维护。 Zookeeper 可以用于实现分布式系统中常见的发布/订阅、负载均衡、命令服务、 分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。其 具有以下特性:
- 顺序一致性 :从一个客户端发起的事务请求,最终都会严格按照其发起顺序被 应用到 Zookeeper 中;
- 原子性 :所有事务请求的处理结果在整个集群中所有机器上都是一致的;不存 在部分机器应用了该事务,而另一部分没有应用的情况;
- 单一视图 :所有客户端看到的服务端数据模型都是一致的;
- 可靠性 :一旦服务端成功应用了一个事务,则其引起的改变会一直保留,直到 被另外一个事务所更改;
- 实时性 :一旦一个事务被成功应用后,Zookeeper 可以保证客户端立即可以读 取到这个事务变更后的最新状态的数据。
ZooKeeper 最早起源于雅虎研究院的一个研究小组。在当时,研究人员发现,在 雅虎内部很多大型系统基本都需要依赖一个类似的系统来进行分布式协调,但是 这些系统往往都存在分布式单点问题,所以,雅虎的开发人员就试图开发一个通 用的无单点问题的分布式协调框架,以便让开发人员将精力集中在处理业务逻 辑上。
关于"ZooKeeper"这个项目的名字,其实也有一段趣闻:在立项初期,考虑到之前 内部很多项目都是使用动物的名字来命名的(例如著名的 Pig 项目),雅虎的工程 师希望给这个项目也取一个动物的名字。时任研究院的首席科学家 RaghuRamakrishnan 开玩笑地说:“在这样下去,我们这儿就变成动物园了!“此 话一出,大家纷纷表示就叫动物园管理员吧–因为各个以动物命名的分布式 组件放在一起,雅虎的整个分布式系统看上去就像一个大型的动物园了,而 Zookeeper 正好要用来进行分布式环境的协调,于是 Zookeeper 的名字也就由 此诞生了
1.2 zookeeper使用场景
利用 ZooKeeper 可以非常方便构建一系列分布式应用中都会涉及到的核心功能。
- 数据发布/订阅
- 负载均衡
- 命名服务
- 分布式协调/通知
- 集群管理
- Master 选举
- 分布式锁
- 分布式队列
多个开源项目中都应用到了 ZooKeeper,例如 HBase, Spark, Flink, Storm, Kafka, Dubbo 等等
参考:ZooKeeper 的应用场景 - 知乎 (zhihu.com)
二、zookeeper安装
注:生产中一般不使用单机模式
2.1 Java环境
wget https://repo.huaweicloud.com/java/jdk/8u191-b12/jdk-8u191-linux-x64.tar.gz
[zookeeper@controller1 ~]$ java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
2.3 安装Zookeeper
1、获取安装包
wget https://apache.website-solution.net/zookeeper/zookeeper-3.5.8/apache-zookeeper-3.5.8-bin.tar.gz
2、解压并创建软连接
tar -xf apache-zookeeper-3.5.8-bin.tar.gz
ln -sv /usr/local/src/apache-zookeeper-3.5.8-bin /opt/zookeeper-3.5.8
3、修改配置
[root@zookeeper-node1 ~]# mkdir /data/zookeeper -pv
mkdir: created directory '/data'
mkdir: created directory '/data/zookeeper'
[root@zookeeper-node1 conf]# cp zoo_sample.cfg zoo.cfg
[root@zookeeper-node1 conf]# grep "[a-Z]" zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
3、修改属主
使用zookeeper启动服务
[root@zookeeper-node1 conf]# useradd zookeeper
[root@zookeeper-node1 conf]# chown -R zookeeper. zookeeper-3.5.8/
[root@zookeeper-node1 conf]# chown -R zookeeper. /data/zookeeper/
3、启动服务
[root@zookeeper-node1 conf]# su - zookeeper
Last login: Thu Dec 3 18:07:55 CST 2020 on pts/0
[zookeeper@zookeeper-node1 ~]$ cd /opt/zookeeper-3.5.8/bin/
[zookeeper@zookeeper-node1 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
4、查看状态
[zookeeper@zookeeper-node1 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone
三、zookeeper集群
3.1 zookeeper集群介绍
ZooKeeper 集群用于解决单点和单机性能及数据高可用等问题:
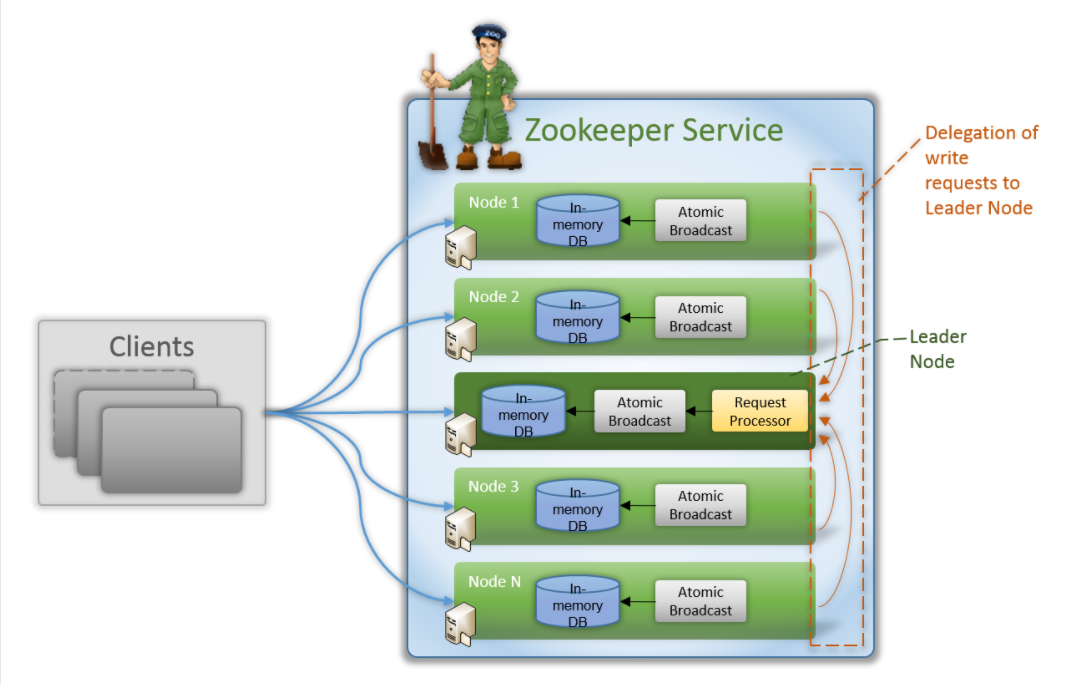
上图中每一个 node 代表一个安装 Zookeeper 服务的服务器。组成 ZooKeeper 服务的服务器都会在内存中维护当前的服务器状态,并且每台服务器之间都互相保 持着通信。集群间通过 Zab 协议(Zookeeper Atomic Broadcast)来保持数据 的一致性。
最典型集群模式为 Master/Slave 模式(主备模式)。在这种模式中,通常 Master 服务器作为主服务器提供写服务,其他的 Slave 服务器从服务器通 过异步复制的方式获取 Master 服务器最新的数据提供读服务。而在 ZooKeeper 中没有选择传统的 Master/Slave 概念,而是引入了 Leader、Follower 和 Observer 三种角色。如下图所示:
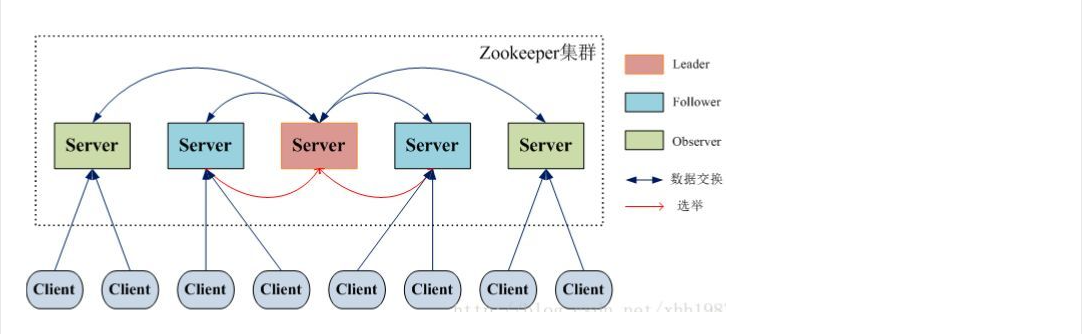
集群角色:
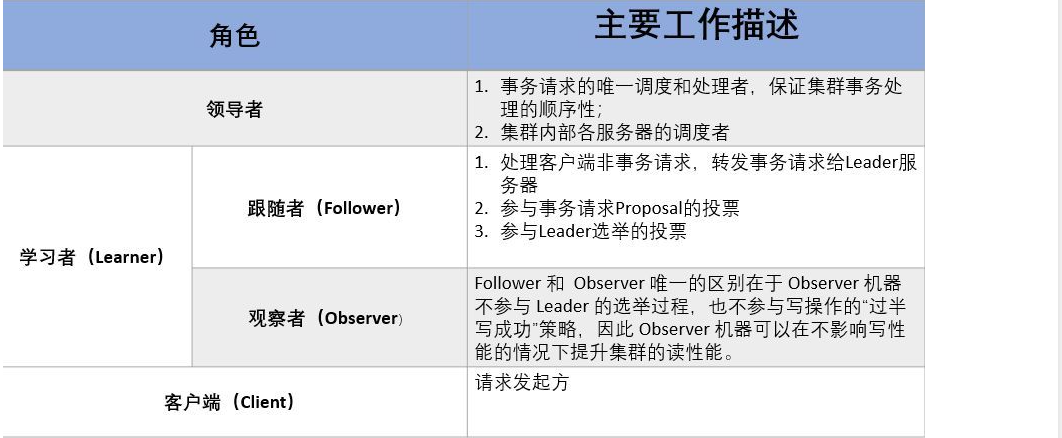
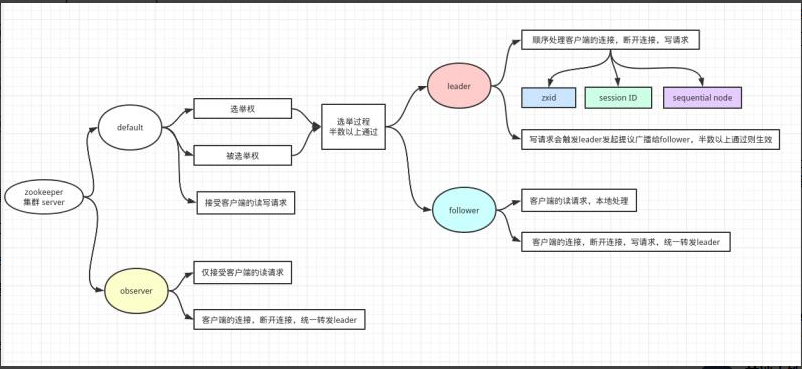
当 Leader 服务器出现网络中断、崩溃退出与重启等异常情况时,ZAB 协议就会进人 恢复模式并选举产生新的 Leader 服务器。这个过程大致是这样的:
- Leader election(选举阶段):节点在一开始都处于选举阶段,只要有一个节点 得到超半数节点的票数,它就可以当选准 leader。
- Discovery(发现阶段):在这个阶段,followers 跟准 leader 进行通信,同步 followers 最近接收的事务提议。
- Synchronization(同步阶段):同步阶段主要是利用 leader 前一阶段获得的最 新提议历史,同步集群中所有的副本。同步完成之后 准 leader 才会成为真正的 leader。
- Broadcast(广播阶段) :到了这个阶段,Zookeeper 集群才能正式对外提供事务 服务,并且 leader 可以进行消息广播。同时如果有新的节点加入,还需要对新节点进行同步。
3.2 集群特点
在 ZooKeeper 集群中,只要有超过集群数量一半的 zookeeper 节点工作正常,那么 整个集群对外就是可用的,假如有 2 台服务器做了一个 zookeeper 集群,只要有任 何一台故障或宕机,那么这个 zookeeper 集群就不可用了,因为剩下的一台没有超过 集群一半的数量,但是假如有三台 zookeeper 组成一个集群,那么损坏一台就还剩两 台,大于 3 台的一半,所以损坏一台还是可以正常运行的,但是再损坏一台就只剩一 台集群就不可用了。那么要是 4 台组成一个 zookeeper 集群,损坏一台集群肯定是 正常的,那么损坏两台就还剩两台,那么 2 台不大于集群数量的一半,所以 3 台的 zookeeper 集群和 4 台的 zookeeper 集群损坏两台的结果都是集群不可用,以此类推
四、集群部署
4.1 集群环境
| 主机名 | IP地址 | 环境 |
|---|---|---|
| zookeeper-node1 | 192.168.130.11 | CentOS 7.6 |
| zookeeper-node2 | 192.168.130.12 | CentOS 7.6 |
| zookeeper-node3 | 192.168.130.13 | CentOS 7.6 |
4.2 部署前准备
各节点都需要部署
zookeeper 服务器都配置 java 环境并配置解析
1、java环境
[root@zookeeper-node3 ~]# java -version
java version "1.8.0_191"
Java(TM) SE Runtime Environment (build 1.8.0_191-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.191-b12, mixed mode)
2、配置解析
[root@zookeeper-node1 opt]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.130.11 zookeeper-node1 zk1.pansn.cn
192.168.130.12 zookeeper-node2 zk2.pansn.cn
192.168.130.13 zookeeper-node3 zk3.pansn.cn
[root@zookeeper-node1 opt]# scp /etc/hosts 192.168.130.12:/etc
[root@zookeeper-node1 opt]# scp /etc/hosts 192.168.130.13:/etc
4.3 各节点部署ZooKeeper
4.3.1 node1
~# pwd
/usr/local/src
~# tar xf apache-zookeeper-3.5.8-bin.tar.gz
~# ln -sv /usr/local/src/apache-zookeeper-3.5.8-bin /opt/zookeeper-3.5.8
~# cd /opt/zookeeper-3.5.8/conf
~# cp zoo_sample.cfg zoo.cfg # 基于模板配置文件来生成配置
~# vim zoo.cfg
~# mkdir /data/zookeeper -pv # 存放数据的目录
~# grep "^[a-Z]" zoo.cfg
[root@zookeeper-node1 src]# cat /opt/zookeeper-3.5.8/conf/zoo.cfg
## 服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
## 集群中leader服务器与follower服务器初始连接心跳次数,即多少个2000毫秒
initLimit=10
# leader与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果
## 该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower
## 将被视为不可用
syncLimit=5
## 自定义的zookeeper保存数据的目录
dataDir=/data/zookeeper
## 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
## 一个客户端IP可以和zookeeper保持的连接数
maxClientCnxns=4096
## 最新快照和相应的事务日志分别保留在dataDir和dataLogDir中,并删除其余部分,默认值
## 为3,最小值为3。
autopurge.snapRetainCount=3
## 3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,
## 单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能
autopurge.purgeInterval=1
# server.服务器编号=服务器IP:数据同步端口:leader选举端口
server.1=192.168.130.11:2888:3888
server.2=192.168.130.12:2888:3888
server.3=192.168.130.13:2888:3888
You have new mail in /var/spool/mail/root
## 写入当前node的集群ID,此处为1
root@zoo-server-node1:~# echo "1" > /data/zookeeper/myid
root@zoo-server-node1:~# cat /data/zookeeper/myid
1
#修改属主
[root@zookeeper-node1 conf]# useradd zookeeper
[root@zookeeper-node1 conf]# chown -R zookeeper. zookeeper-3.5.8/
[root@zookeeper-node1 conf]# chown -R zookeeper. /data/zookeeper/
4.3.2 node2
~# pwd
/usr/local/src
~# tar xf apache-zookeeper-3.5.8-bin.tar.gz
~# ln -sv /usr/local/src/apache-zookeeper-3.5.8-bin /opt/zookeeper-3.5.8
~# cd /opt/zookeeper-3.5.8/conf
~# cp zoo_sample.cfg zoo.cfg # 基于模板配置文件来生成配置
~# vim zoo.cfg
~# mkdir /data/zookeeper -pv # 存放数据的目录
~# grep "^[a-Z]" zoo.cfg
[root@zookeeper-node1 src]# cat /opt/zookeeper-3.5.8/conf/zoo.cfg
## 服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
## 集群中leader服务器与follower服务器初始连接心跳次数,即多少个2000毫秒
initLimit=10
# leader与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果
## 该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower
## 将被视为不可用
syncLimit=5
## 自定义的zookeeper保存数据的目录
dataDir=/data/zookeeper
## 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
## 一个客户端IP可以和zookeeper保持的连接数
maxClientCnxns=4096
## 最新快照和相应的事务日志分别保留在dataDir和dataLogDir中,并删除其余部分,默认值
## 为3,最小值为3。
autopurge.snapRetainCount=3
## 3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,
## 单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能
autopurge.purgeInterval=1
# server.服务器编号=服务器IP:数据同步端口:leader选举端口
server.1=192.168.130.11:2888:3888
server.2=192.168.130.12:2888:3888
server.3=192.168.130.13:2888:3888
You have new mail in /var/spool/mail/root
## 写入当前node的集群ID,此处为1
root@zoo-server-node1:~# echo "2" > /data/zookeeper/myid
root@zoo-server-node1:~# cat /data/zookeeper/myid
1
#修改属主
[root@zookeeper-node1 conf]# useradd zookeeper
[root@zookeeper-node1 conf]# chown -R zookeeper. zookeeper-3.5.8/
[root@zookeeper-node1 conf]# chown -R zookeeper. /data/zookeeper/
4.3.3 node3
~# pwd
/usr/local/src
~# tar xf apache-zookeeper-3.5.8-bin.tar.gz
~# ln -sv /usr/local/src/apache-zookeeper-3.5.8-bin /opt/zookeeper-3.5.8
~# cd /opt/zookeeper-3.5.8/conf
~# cp zoo_sample.cfg zoo.cfg # 基于模板配置文件来生成配置
~# vim zoo.cfg
~# mkdir /data/zookeeper -pv # 存放数据的目录
~# grep "^[a-Z]" zoo.cfg
[root@zookeeper-node1 src]# cat /opt/zookeeper-3.5.8/conf/zoo.cfg
## 服务器与服务器之间的单次心跳检测时间间隔,单位为毫秒
tickTime=2000
## 集群中leader服务器与follower服务器初始连接心跳次数,即多少个2000毫秒
initLimit=10
# leader与follower之间连接完成之后,后期检测发送和应答的心跳次数,如果
## 该follower在设置的时间内(5*2000)不能与leader 进行通信,那么此 follower
## 将被视为不可用
syncLimit=5
## 自定义的zookeeper保存数据的目录
dataDir=/data/zookeeper
## 客户端连接 Zookeeper 服务器的端口,Zookeeper 会监听这个端口,接受客户端的访问请求
clientPort=2181
## 一个客户端IP可以和zookeeper保持的连接数
maxClientCnxns=4096
## 最新快照和相应的事务日志分别保留在dataDir和dataLogDir中,并删除其余部分,默认值
## 为3,最小值为3。
autopurge.snapRetainCount=3
## 3.4.0及之后版本,ZK提供了自动清理日志和快照文件的功能,这个参数指定了清理频率,
## 单位是小时,需要配置一个1或更大的整数,默认是0,表示不开启自动清理功能
autopurge.purgeInterval=1
# server.服务器编号=服务器IP:数据同步端口:leader选举端口
server.1=192.168.130.11:2888:3888
server.2=192.168.130.12:2888:3888
server.3=192.168.130.13:2888:3888
You have new mail in /var/spool/mail/root
## 写入当前node的集群ID,此处为1
root@zoo-server-node1:~# echo "3" > /data/zookeeper/myid
root@zoo-server-node1:~# cat /data/zookeeper/myid
1
#修改属主
[root@zookeeper-node1 conf]# useradd zookeeper
[root@zookeeper-node1 conf]# chown -R zookeeper. zookeeper-3.5.8/
[root@zookeeper-node1 conf]# chown -R zookeeper. /data/zookeeper/
4.4 启动集群
node1
[zookeeper@zookeeper-node1 zookeeper-3.5.8]$ ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
node2
[zookeeper@zookeeper-node2 zookeeper-3.5.8]$ ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
node3
[zookeeper@zookeeper-node3 zookeeper-3.5.8]$ ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
4.5 验证集群状态
[root@zookeeper-node1 bin]# ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
[zookeeper@zookeeper-node2 zookeeper-3.5.8]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
[zookeeper@zookeeper-node3 zookeeper-3.5.8]$ ./bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
五、ZooKeeper命令
5.1 查看状态
[zookeeper@zookeeper-node2 bin]$ ./zkServer.sh --help
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Usage: ./zkServer.sh [--config <conf-dir>] {start|start-foreground|stop|restart|status|print-cmd}
[zookeeper@zookeeper-node2 bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.5.8/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: leader
5.2 交互命令
参考:zookeeper客户端 zkCli使用及常用命令 )
可连接至 zookeeper 集群中的任意一台 zookeeper 节点进行交互命令操作, 如写入数据,删除数据等
[zookeeper@zookeeper-node2 bin]$ ./zkCli.sh -server zk1.pansn.cn:2181
Connecting to zk1.pansn.cn:2181
......
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
## 光标会在这里停下,按一下Enter
[zk: zk1.pansn.cn:2181(CONNECTED) 0] # 连接上了
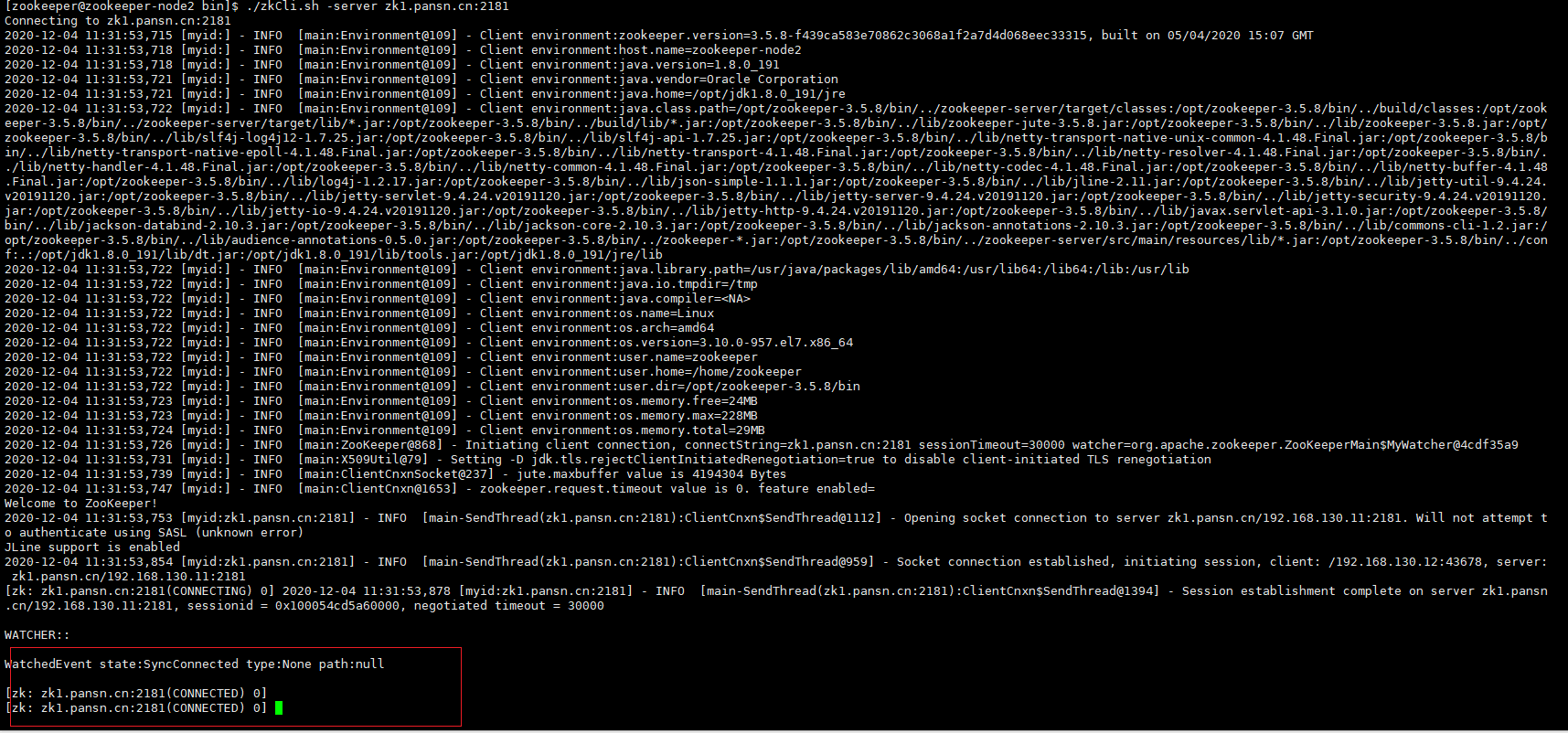
查看zk客户端帮助
命令 h
[zk: zk3.pansn.cn:2181(CONNECTED) 6] h
ZooKeeper -server host:port cmd args
addauth scheme auth
close
config [-c] [-w] [-s]
connect host:port #连接节点
create [-s] [-e] [-c] [-t ttl] path [data] [acl]
delete [-v version] path
deleteall path
delquota [-n|-b] path
get [-s] [-w] path
getAcl [-s] path
history
listquota path
ls [-s] [-w] [-R] path
ls2 path [watch]
printwatches on|off
quit
reconfig [-s] [-v version] [[-file path] | [-members serverID=host:port1:port2;port3[,...]*]] | [-add serverId=host:port1:port2;port3[,...]]* [-remove serverId[,...]*]
redo cmdno
removewatches path [-c|-d|-a] [-l]
rmr path
set [-s] [-v version] path data
setAcl [-s] [-v version] [-R] path acl
setquota -n|-b val path
stat [-w] path
sync path
查看根目录节点: ls /
[zk: zk3.pansn.cn:2181(CONNECTED) 9] ls /
[zookeeper]
查看状态
[zk: zk3.pansn.cn:2181(CONNECTED) 10] stat /
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x100000005
cversion = 1
dataVersion = 0 数据版本,每次更新则加1
aclVersion = 0 acl权限
ephemeralOwner = 0x0
dataLength = 0 数据长度
numChildren = 3 子节点数量
创建数据节点(Znode),并写入数据:
## 创建数据节点
[zk: zk3.pansn.cn:2181(CONNECTED) 25] create /data-string "Hello, zookeeper."
Created /data-string
[zk: zk3.pansn.cn:2181(CONNECTED) 26] get -w /data-string
Hello, zookeeper.
[zk: zk3.pansn.cn:2181(CONNECTED) 27] get -s /data-string
Hello, zookeeper.
cZxid = 0x10000000e
ctime = Fri Dec 04 12:00:24 CST 2020
mZxid = 0x10000000e
mtime = Fri Dec 04 12:00:24 CST 2020
pZxid = 0x10000000e
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 17
numChildren = 0
## 创建子数据节点
[zk: zk3.pansn.cn:2181(CONNECTED) 28] create /data-string/reply "Hi, I'm zookeeper."
Created /data-string/reply
## 获取数据及信息
[zk: zk3.pansn.cn:2181(CONNECTED) 29] get -s /data-string/reply
Hi, I'm zookeeper.
cZxid = 0x10000000f
ctime = Fri Dec 04 12:01:53 CST 2020
mZxid = 0x10000000f
mtime = Fri Dec 04 12:01:53 CST 2020
pZxid = 0x10000000f
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 18
numChildren = 0
六. ZooKeeper 客户端 zooinspector
6.1 windows平台安装
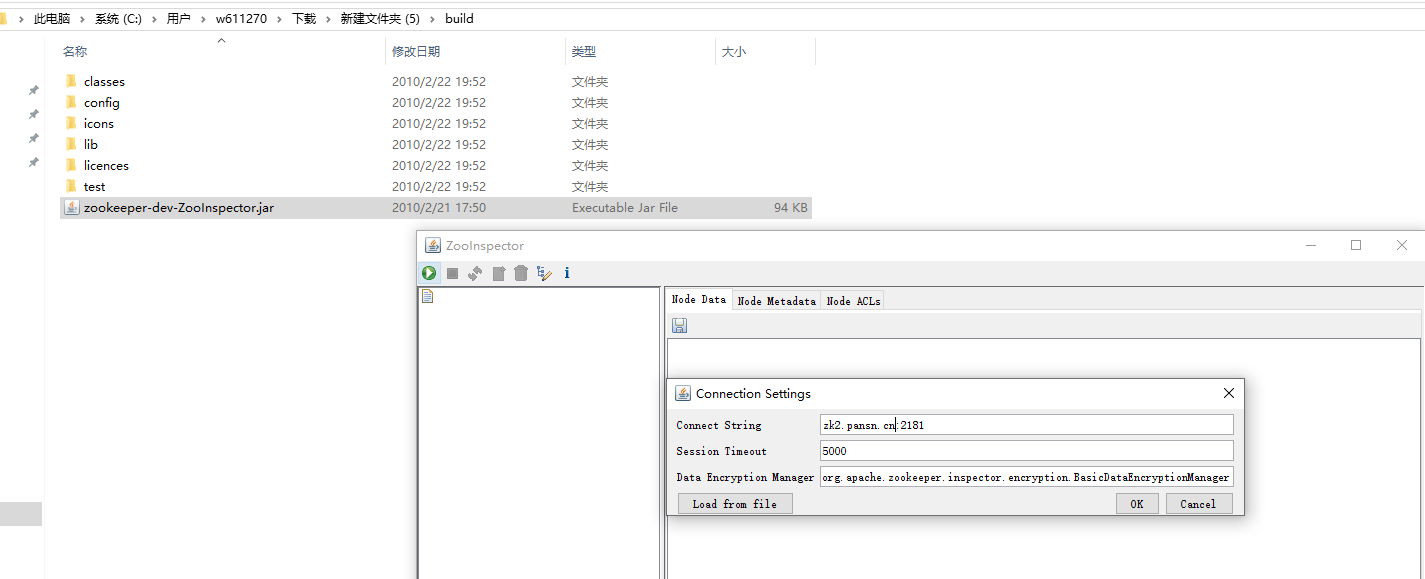
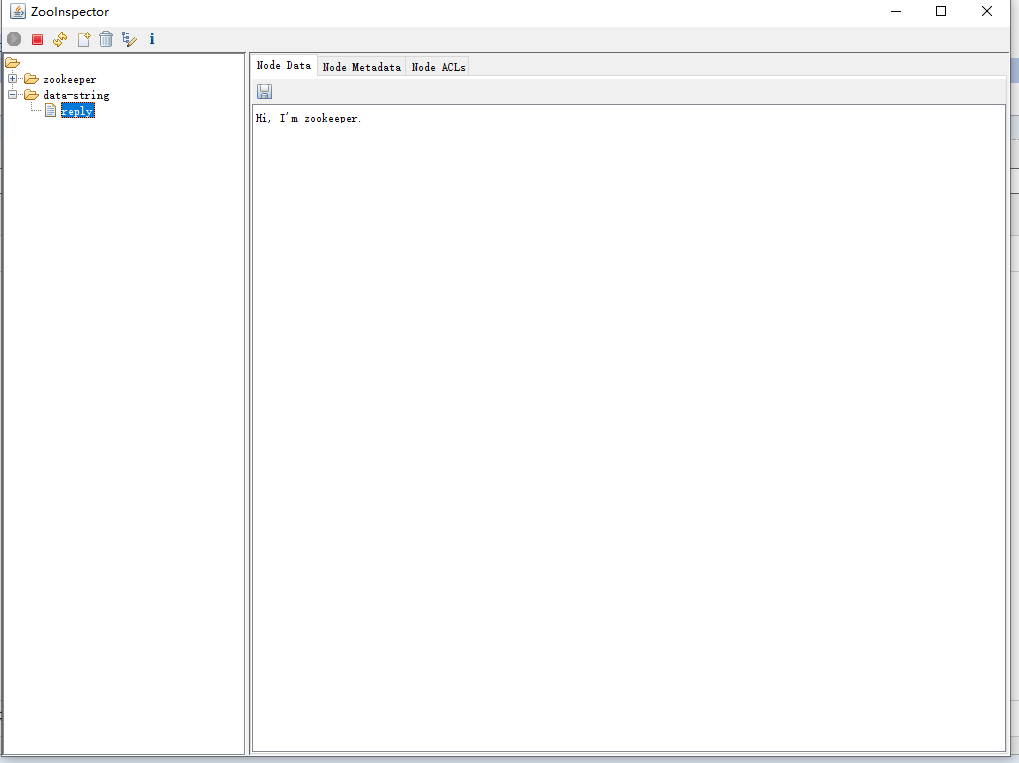

 浙公网安备 33010602011771号
浙公网安备 33010602011771号