第一次接触大数据
偶尔在博客看到一位写的大数据,感觉不错,之前一直没有详细了解过,看了这篇感觉对大数据有了一个简单的认识。
之前有一朋友在大数据公司上班,所以对大数据心里一直有一个问号,1:是怎样一个东西呢?2:那些公司可以做大数据呢?3:这些海量的数据怎么存储呢?
1其实大数据顾名思义就是处理庞大的数据,都是以TB级别起步的,任何存放在计算机上面的文件,都会占用一定的存储空间。文件有多大,所占用存储空间就有多大。
平常我们自己的电脑都是500GB左右,1TB=1024GB,1PB=1024TB,所以当数据规模达到一定程度的时候,电脑硬盘就显的不合适了。
2:互联网企业是最早收集大数据的行业,最典型的就是Google和百度这两个公司是做搜索引擎的,数量都非常庞大,每天都要去把互联网上的各种各样的网页信息抓取下来存储到本地,然后进行分析,处理,当用户想通过搜索引擎搜索一些他们关心的信息时,Google和百度就从海量的数据当中提取出相对于对用户而言是有用的信息,然后将提取到的结果反馈给用户,据说Google存储的数据量已经到达了上百个PB,这个数据量是非常惊人的。类似于Fackbook这样的SNS(社交网站)因为用户量比较多,用户每天在网站上面分享一些文章,图片,视频,音频等信息,因此每天产生的数据量也是非常庞大的
3:海量存储数据的问题,很早以前就出现了,一些行业或者部门的快速发展和历史的累积,比如淘宝,他们的数据量达到了一定的级别,当一台电脑无法存储这么庞大的数据时,用的解决方案是使用NFS(网络文件系统)将数据分开存储,NFS系统的架构如下图所示:(此图为转载)

NFS这种解决方案就是同时架设多台文件服务器,如下图所示:
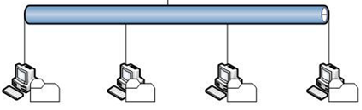
然后在文件服务器上面设置共享目录,例如图中显示的【D:\software、E:\aa\bb、F:\dd\cc、E:\images】
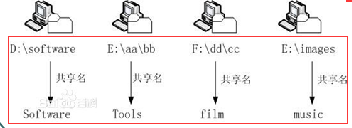
这样我们就可以把文件分类存放到各个文件服务器上面的共享目录当中,一台电脑的存储空间不够用,那么我们就将数据分散到多台电脑进行存储,而这些文件服务器上面的共享目录对于用户来说是透明的,用户会以为自己存放数据的【Software、Tools、film、music】这些目录都是属于【Itdc.com.local】这台文件服务器里面的【public】目录下的子目录,在NFS系统中,【Itdc.com.local】这台文件服务器只是起到一个中转站作用,将用户需要存放的海量数据分类存放到各个文件系统当中,这就解决了大数据的存储问题了。当用户需要访问分散在各个文件服务器中的文件资源时,它只需要访问【Itdc.com.local】这台文件服务器就可以了。
NFS虽然是解决了海量数据的存储问题,但是在大数据背景下,这种存储方案是不适用的,大数据不光是要解决数据存储问题,更重要的是海量数据的分析,而NFS在海量数据分析方面不能够充分利用多台计算机同时进行分析。
2.2、海量数据如何计算
一个实际的需求场景——日志分析
对日志中每一个用户的流量进行汇总就和,如下图所示:

对于这样的一个日志文件,如果只有这么几行数据,我们一般会采用这样的处理方式:
1、读取一行日志
2、抽取手机号和流量字段
3、累加到HashMap中
4、遍历输出结果
那么问题来了,如果数据量变得很大呢,比如一个日志文件里面有几个GB数据,
- 如果仍然一行一行去读,那么就会因为磁盘的IO瓶颈导致效率太低,速度太慢。
- 如果一次性加载到内存,那么就会因为单台计算机的内存空间有限而导致内存溢出。
- 如果将中间结果全部缓存到HashMap中,那么也会因为单台计算机的内存空间有限而导致内存溢出。
- 可以选择采用多线程处理,但是依然无法改变资源瓶颈的现实,因为一台计算器的CPU资源,内存资源,磁盘IO瓶颈是定,创建再多的线程也无法改变这个现实。
所以当一个日志文件里面存储了几个GB数据,那么这种情况下就不能采用这种传统的处理方式了。可以看到,在大数据背景下,我们一个简单的业务场景,比如这里的统计用户流量,在数据量变得很大的时候,原来不是问题的一些东西现在都成了问题。那么这些问题该如何解决呢?
解决思路一
纵向扩展,也就是升级硬件,提高单机性能(增加内存,增强CPU、用更高性能的磁盘(如固态硬盘)),比如可以购买IBM的高端服务器。

优点:
1、简单易行
缺点:
1、单台计算机的扩展空间有限,CPU、内存、磁盘再怎么扩展也是有限的,无法无限扩展。
2、成本高(高端服务器非常昂贵,几百万甚至上千万一台,一般的小公司承受不起这样高昂的成本)
解决思路二
横向扩展,用多台节点分布式集群处理 (通过增加节点数量提高处理能力,这里说的节点指的就是一台计算机)

核心思想:任务分摊,通过协作来实现单节点无法实现的任务。
优点:
1、成本相对低(可采用普通机器)
2、易于线性扩展
缺点:
系统复杂度增加,我们要将我们的web应用部署到每一个节点上面,而多个节点协同工作时就要考虑以下几个问题
1、如何调度资源
2、任务如何监控
3、中间结果如何调度
4、系统如何容错
5、如何实现众多节点间的协调
分布式计算的复杂性就体现在这样的5个问题里面。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号