MongoDB 大文件处理 _ Building MongoDB Applications with Binary Files Using GridFS
GridFS![]()

GridFS is a specification for storing and retrieving files that exceed the BSON-document size limit of 16 MB.
NOTE
GridFS does not support multi-document transactions.
Instead of storing a file in a single document, GridFS divides the file into parts, or chunks [1], and stores each chunk as a separate document. By default, GridFS uses a default chunk size of 255 kB; that is, GridFS divides a file into chunks of 255 kB with the exception of the last chunk. The last chunk is only as large as necessary. Similarly, files that are no larger than the chunk size only have a final chunk, using only as much space as needed plus some additional metadata.
GridFS uses two collections to store files. One collection stores the file chunks, and the other stores file metadata. The section GridFS Collections describes each collection in detail.
When you query GridFS for a file, the driver will reassemble the chunks as needed. You can perform range queries on files stored through GridFS. You can also access information from arbitrary sections of files, such as to "skip" to the middle of a video or audio file.
GridFS is useful not only for storing files that exceed 16 MB but also for storing any files for which you want access without having to load the entire file into memory. See also When to Use GridFS.
When to Use GridFS![]()
In MongoDB, use GridFS for storing files larger than 16 MB.
In some situations, storing large files may be more efficient in a MongoDB database than on a system-level filesystem.
-
If your filesystem limits the number of files in a directory, you can use GridFS to store as many files as needed.
-
When you want to access information from portions of large files without having to load whole files into memory, you can use GridFS to recall sections of files without reading the entire file into memory.
-
When you want to keep your files and metadata automatically synced and deployed across a number of systems and facilities, you can use GridFS. When using geographically distributed replica sets, MongoDB can distribute files and their metadata automatically to a number of
mongodinstances and facilities.
Do not use GridFS if you need to update the content of the entire file atomically. As an alternative you can store multiple versions of each file and specify the current version of the file in the metadata. You can update the metadata field that indicates "latest" status in an atomic update after uploading the new version of the file, and later remove previous versions if needed.
Furthermore, if your files are all smaller than the 16 MB BSON Document Size limit, consider storing each file in a single document instead of using GridFS. You may use the BinData data type to store the binary data. See your drivers documentation for details on using BinData.
https://www.mongodb.com/blog/post/building-mongodb-applications-binary-files-using-gridfs-part-1
Use Cases
This is a two-part series that explores a powerful feature in MongoDB for managing large files called GridFS. In the first part, we discuss use cases appropriate for GridFS, and in part 2 we discuss how GridFS works and how to use it in your apps.
In my position at MongoDB, I speak with many teams that are building applications that manage large files (videos, images, PDFs, etc.) along with supporting information that fits naturally into JSON documents. Content management systems are an obvious example of this pattern, where is it necessary to both manage binary artifacts as well as all the supporting information about those artifacts (e.g., author, creation date, workflow state, version information, classification tags, etc.).
MongoDB manages data as documents, with a maximum size of 16MB. So what happens when your image, video, or other file exceeds 16MB? GridFS is a specification implemented by all of the MongoDB drivers that manage large files and their associated metadata as a group of small files. When you query for a large file, GridFS automatically reassembles the smaller files into the original large file.
Content management is just one of the many uses of GridFS. For example, McAfee optimizes delivery of analytics and incremental updates in MongoDB as binary packages for efficiently delivery to customers. Pearson stores student data in GridFS and leverages MongoDB’s replication to distribute data and keep it synchronized across facilities.
There are also many other systems with this requirement, many of which are in healthcare. Hospitals and other care-providing organizations want to centralize patient record information to provide a single view of the patient making this information more accessible to doctors, care providers, and patients themselves. The central system improves the quality of patient care (care providers get a more complete and global view of the patient’s health status) as well as the efficiency of providing care.
A typical patient health record repository includes general information about the patient (name, address, insurance provider, etc.) along with all various types of medical records (office visits, blood tests and labs, medical procedures, etc.). Much of this information fits nicely into JSON documents and the flexibility of MongoDB makes it easy to accommodate variability in content and structure. Healthcare applications also manage large binary files such as radiology tests, x-ray and MRI images, CAT scans, or even legacy medical records created by scanning paper documents. It is not uncommon for a large hospital or insurance provider to have 50-100 TB of patient data and as much as 90% is large binary files.
When building an application like this, organizations usually have to decide whether to store the binary data in a separate repository, or along with the metadata. With MongoDB, there are a number of compelling reasons for storing the binary data in the same system as the rest of the information. They include:
- The resulting application will have a simpler architecture: one system for all types of data;
- Document metadata can be expressed using the rich flexible document structure, and documents can be retrieved using all the flexibility of MongoDB’s query language;
- MongoDB’s high availability (replica sets) and scalability (sharding) infrastructure can be leveraged for binary data as well as the structured data;
- One consistent security model for authenticating and authorizing access to the metadata and files;
- GridFS doesn’t have the limitations of some filesystems, like the number of documents per directory, or file naming rules.
How GridFS Works
In part 1 we looked at some of the use cases that are appropriate for GridFS. In this post we take a closer look at how GridFS works and how you can use it in your apps.
GridFS stores large binary files by breaking the files into smaller files called “chunks” and saving them in MongoDB. It essentially saves you, the application developer, from having to write all the code to break large files up into chunks, saving all the individual chunks into MongoDB, and then, when retrieving the files, combining all the chunks back together. GridFS gives you all this functionality for free.
The way GridFS works is shown in Figure 1. GridFS uses two collections to save a file to a database: fs.files and fs.chunks. (The default prefix is “fs”, but you can rename it.) The fs.chunks collection contains the binary file broken up into 255k chunks. The fs.files collection contains the metadata for the document.
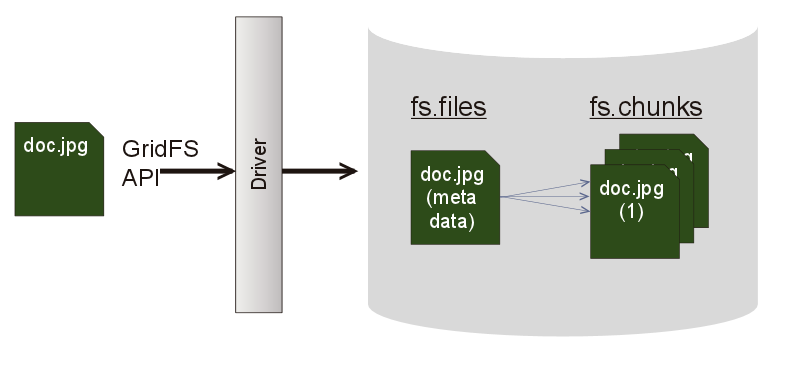
An Example
Let’s work through an example to see how this works. I wrote a small Perl program to load a set of videos my wife had taken on her iPhone of my son’s baseball games and my daughter’s gymnastics meets. Figure 2 shows the core of the program (you can download the entire program from github). The program performs the following steps:
- Establishes a connection to MongoDB and creates database object for the “digital” database into which we want to load the files
- Creates a gridFS object for the database to gain access to the gridFS API
- Reads the Movies directory on my laptop and finds all the .MOV files
- Each .MOV file is inserted into MongoDB with three metadata fields: `filename`, `content-type`, and `author`.
my $movieDir = "/Users/jayrunkel/Movies";
my $client = MongoDB::MongoClient->new(host => 'localhost',
port => 27017);
my $database = $client->get_database( 'digital' );
my $grid = $database->get_gridfs;
my @vidFiles = getFiles($movieDir);
$grid->drop();
foreach my $file (@vidFiles) {
my $fh = IO::File->new("$movieDir/$file", "r");
$grid->insert($fh, {"filename" => $file,
"content-type" => "video/quicktime",
"author" => "deb"});
}
As the files are inserted into the database, MongoDB calculates the MD5 checksum of the file and compares that to the checksum calculated by the file system. If they don’t match an error condition occurs. My program will simply die, but it could handle the error and do something more intelligent.
Going to the mongoshell and looking at the digital database shows that there are two collections: fs.chunks and fs.files, just as we expect.
> use digital > show collections fs.chunks fs.files system.indexes
Let’s first look at the fs.files collection (Figure 3). This collection contains one document for each of the MOV files we loaded into MongoDB. Each document contains the metadata for the corresponding file. This metadata consists of the GridFS defined metadata fields (length, chunksize, and uploadDate) plus the metadata fields I supplied when I inserted the MOV files: content-type, author, and filename. The length field is the size of the document in bytes, the chunk field is the size of each chunk in bytes, and the uploadDate is the date the document was first inserted into MongoDB.
You can define any metadata fields as appropriate and due to the flexibility of MongoDB, each document can have the specific set of fields that make sense. There isn’t a requirement that all files have the same set of metadata fields and you can feel free to add or modify fields as your application evolves.
{
"_id": ObjectId("546fb304f9781507293f9891"),
"length": NumberLong("834284"),
"content-type": "video/quicktime",
"uploadDate": ISODate("2014-11-21T21:47:48Z"),
"chunkSize": NumberLong("261120"),
"filename": "IMG_0425.MOV",
"author": "deb"
}
Each document in the fs.files collection is associated with a set of documents in the fs.chunks collection (Figure 4). The fs.chunks documents are numbered from 0 to n (see the “n” field) with binary data for the chunk stored in the “data” field. The fs.files document is related to its corresponding chunk documents in the fs.chunks collection by the files_id field. The files_id field is the _id of the corresponding document in the fs.files collection. Here are the first two chunks associated with the document whose ObjectId is 546fb304f9781507293f9896.
{
"_id": ObjectId("546fb304f9781507293f98a6"),
"files_id": ObjectId("546fb304f9781507293f9896"),
"data": BinData(0, "+QWU+Pwf1u03d………..."),
"n": NumberLong("0")
}
{
"_id": ObjectId("546fb304f9781507293f9898"),
"files_id": ObjectId("546fb304f9781507293f9896"),
"data": BinData(0, "EgKwOoOAOYEwFoi…."),
"n": NumberLong("1")
}
...
Because the goal of the GridFS API is to make it easy and efficient to retrieve and reassemble the binary document, GridFS will automatically create a compound index on the fs.chunks collection on the files_id and n fields. This will enable MongoDB to quickly identify all the chunks associated with a particular file, sort them from 0 to n using the n field, and return them to the driver so that they can be assembled back into the original document. To demonstrate this, here is the output of running getIndexes on the fs.chunks collection. As you see the Perl driver automatically created the compound index when I inserted the first document into my database.
> db.fs.chunks.getIndexes()
[
{
"v": 1,
"key": {
"_id": 1
},
"name": "_id_",
"ns": "digital.fs.chunks"
},
{
"v": 1,
"unique": true,
"key": {
"files_id": NumberLong("1"),
"n": NumberLong("1")
},
"name": "files_id_1_n_1",
"ns": "digital.fs.chunks"
}
]
How do you use the GridFS API to build an application
Using the GridFS API to build an application is simple. GridFS does all the hard work. All you need to do is insert your binary documents into MongoDB using the GridFS API. When you insert the documents, you can provide the document metadata and you can update this metadata during the life of the document in your application using the same update queries you use to update other documents in MongoDB.
Retrieving and deleting documents is simple as well. The GridFS API provides methods for retrieving a document, as a whole or in parts, which can be very useful for “skipping” to the middle of an audio or video file. This function combines the chunk files to recreate the original file and returns a file object to your application. The delete method removes the documents from the fs.file and fs.chunks collection so that the original document has been removed from MongoDB.
Fortunately, GridFS makes working with large binary files in MongoDB easy. In part two, I will walk through in detail how you use GridFS to store and manage binary content in MongoDB. In the meantime if you’re looking to learn more, download our architecture guide:Download the Architecture Guide

 浙公网安备 33010602011771号
浙公网安备 33010602011771号