Linux 相关学习内容(不定期更新)
Linux 主要目录
| / | 根目录,在 linux 下有且只有一个根目录,所有的东西都是从这里开始 |
|---|---|
| /bin | 可执行二进制文件的目录,如常用的命令,ls, tar, mv, cat.. |
| /boot | 放置linux系统启动时用到的文件,linux的内核文件/boot/vmlinuz,系引导管理器/boot/grub |
| /dev | 存放linux系统下的设备文件,常用的是挂载光驱 mount /dev/chrom /mnt /dev/ttl 表示终端 , /dev/null 表示无底洞垃圾桶 |
| /etc | 系统配置文件存放的目录,不建议在此目录下存放可执行文件 |
| /home | 用户家目录,每个用户有自己的目录 ~表示当前用户的家目录 |
| /lib | 系统使用的函数库的目录,程序在执行过程中,需要调用一些额外的参数时需要函数库协助 |
| /lost+fount | 系统异常产生错误时,会将一些遗失的片段放置在此目录下 |
| /opt | 给主机额外安装软件所存放的目录 |
| /proc | 此目录的数据都在内存中,如系统核心,外部设备,网络状态,由于数据都存放于内存中,所以不占用磁盘空间,比较重要的文件, 系统内存的映射目录,提供内核和进程信息有:/proc/cpuinfo、/proc/interrupts、/proc/dma、/proc/ioports、/proc/net/* 等 |
| /root | 系统管理员的家目录 |
| /sbin | 放置系统管理员使用的可执行命令,如:fdisk,shutdown, mount,与 /bin 不同的是,这几个目录是给系统管理员 root 使用的命令,一般用户只能"查看"而不能设置和使用 |
| /tmp | 一般用户或正在执行的程序临时存放文件的目录,任何人都可以访问,重要数据不可放置在此目录下 |
| /srv | 服务启动之后需要访问的数据目录,如 www 服务需要访问的网页数据存放在 /srv/www 内 |
| /usr | usr并不是user的缩写,而是Unix Software Resource的缩写,即“Unix 操作系统软件资源”放在该目录。这个目录 相当于Windows操作系统的“C:\Windows\”和“C:\Program files\”这两个目录的综合体 |
| /var | 放置系统执行过程中经常变化的文件 |
-
/usr/bin:存放应用程序
-
/usr/share:存放共享数据
-
/usr/lib:存放不能直接运行的,却是许多程序运行所必需的一些函数库文件
-
/usr/local:存放软件升级包
-
/usr/share/doc:系统说明文件存放目录
-
/usr/share/man:程序说明文件存放目录
-
/var/log:随时更改的日志文件
-
/var/spool/mail:邮件存放的目录
-
/var/run:程序或服务启动后,其 PID 存放在该目录下
查看Linux内核版本信息
cat /proc/version
uname # 查看系统名称
uname -a # 获取详细信息
uname -r
查看Linux系统版本信息
cat /ect/issue
cat /etc/lsb-release
lsb-release -a
常用Linux命令
| 序号 | 命令 | 对应英文 | 作用 |
|---|---|---|---|
| 01 | ls | list | 查看当前文件夹下的内容 |
| 02 | pwd | print wrok directory | 查看当前所在文件夹 |
| 03 | cd [目录名] | change directory | 切换文件夹 |
| 04 | touch [文件名] | touch | 如果文件不存在,新建文件 |
| 05 | mkdir [目录名] | make directory | 创建目录 |
| 06 | rm [文件名] | remove | 删除指定的文件名 |
| 07 | clear | clear | 清屏 |
| 08 | which | which | 查看命令位置,如果找到则显示 which ls --> /bin/ls |
| 09 | who | who | 查看当前所有登录系统的用户信息 |
| 10 | reboot | reboot | 重新启动操作系统 |
| 11 | shutdown | shotdown | shotdown -r now 重新启动操作系统,shutdown会给别的用户提示 shutdown -h now 立刻关机,其中now相当于时间为0的状态 shutdown -h 20:25 系统在今天的20:25 会关机 shutdown -h +10 系统再过十分钟后自动关机 |
| 12 | wc | Word Count | - c 统计字节数 - l 统计行数 - w 统计字数 |
| 13 | grep |
Linux查找命令
- find
- locate
- grep
- which
- whereis
归档管理:tar
tar命令很特殊,其参数前面可以使用“-”,也可以不使用。
| 参数 | 含义 |
|---|---|
| -c | 生成档案文件,创建打包文件 |
| -v | 列出归档解档的详细过程,显示进度 |
| -f | 指定档案文件名称,f后面一定是.tar文件,所以必须放选项最后 |
| -t | 列出档案中包含的文件 |
| -x | 解开档案文件 |
注意:除了f需要放在参数的最后,其它参数的顺序任意。
C:\Users\asus\Desktop\review\testlinuk
λ tar -cvf test.tar *
1.txt
2.txt
3.txt
tes1/
tes2/
tes2/tes3/
C:\Users\asus\Desktop\review\testlinuk
λ ls
1.txt 2.txt 3.txt tes1/ tes2/ test.tar
C:\Users\asus\Desktop\review\testlinuk
λ rm *.txt
C:\Users\asus\Desktop\review\testlinuk
λ rm -r *[12]
C:\Users\asus\Desktop\review\testlinuk
λ ls
test.tar
C:\Users\asus\Desktop\review\testlinuk
λ tar -xvf test.tar
1.txt
2.txt
3.txt
tes1/
tes2/
tes2/tes3/
C:\Users\asus\Desktop\review\testlinuk
λ ls
1.txt 2.txt 3.txt tes1/ tes2/ test.tar
文件解压缩:gzip
tar与gzip命令结合使用实现文件打包、压缩。 tar只负责打包文件,但不压缩,用gzip压缩tar打包后的文件,其扩展名一般用xxxx.tar.gz
gzip [options] compressfile
| 选项 | 含义 |
|---|---|
| -d | 解压 |
| -r | 压缩所有子目录 |
tar这个命令并没有压缩的功能,它只是一个打包的命令,但是在tar命令中增加一个选项(-z)可以调用gzip实现了一个压缩的功能,实行一个先打包后压缩的过程。
tar -zcvf test.tar.gz * # 将当前目录下的文件以及文件夹打包并压缩为test.tar.gz
- 文件解压缩:bzip2
tar与bzip2命令结合使用实现文件打包、压缩(用法和gzip一样)。
tar只负责打包文件,但不压缩,用bzip2压缩tar打包后的文件,其扩展名一般用xxxx.tar.gz2。
在tar命令中增加一个选项(-j)可以调用bzip2实现了一个压缩的功能,实行一个先打包后压缩的过程。。
压缩用法:tar -jcvf 压缩包包名 文件...(tar jcvf bk.tar.bz2 *.c)
解压用法:tar -jxvf 压缩包报名 (tar jxvf bk.tar.bz2)
修改文件权限:chmod
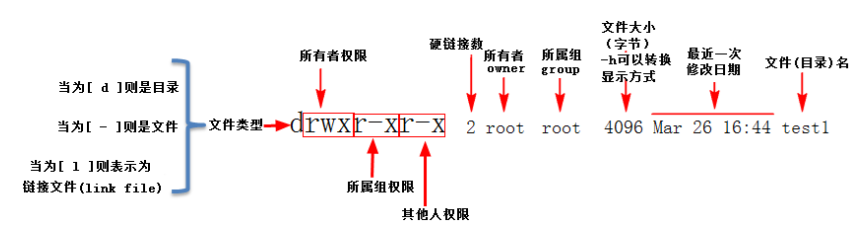
chmod 修改文件权限有两种使用格式:字母法与数字法。
字母法:chmod u/g/o/a +/-/= rwx 文件
| [ u/g/o/a ] | 含义 |
|---|---|
| u | user 表示该文件的所有者 |
| g | group 表示与该文件的所有者属于同一组( group )者,即用户组 |
| o | other 表示其他以外的人 |
| a | all 表示这三者皆是 |
| [ +-= ] | 含义 |
|---|---|
| + | 增加权限 |
| - | 撤销权限 |
| = | 设定权限 |
| rwx | 含义 |
|---|---|
| r | read 表示可读取,对于一个目录,如果没有r权限,那么就意味着不能通过ls查看这个目录的内容。 |
| w | write 表示可写入,对于一个目录,如果没有w权限,那么就意味着不能在目录下创建新的文件。 |
| x | excute 表示可执行,对于一个目录,如果没有x权限,那么就意味着不能通过cd进入这个目录。 |
数字法:“rwx” 这些权限也可以用数字来代替
| 字母 | 说明 |
|---|---|
| r | 读取权限,数字代号为 "4" |
| w | 写入权限,数字代号为 "2" |
| x | 执行权限,数字代号为 "1" |
| - | 不具任何权限,数字代号为 "0" |
如执行:chmod u=rwx,g=rx,o=r filename 就等同于:chmod u=7,g=5,o=4 filename
注意:如果想递归所有目录加上相同权限,需要加上参数“ -R ”。 如:chmod 777 test/ -R 递归 test 目录下所有文件加 777 权限
windows 递归修改文件权限: Icacls ${dirName} /grant ${userName}:F
赋予test用户d:/workspace目录下所有文件的完全访问权限
Icacls d:/workspace /grant test:F
grep (Global Regular Expression Print)
Linux系统中grep命令是一种强大的文本搜索工具,grep允许对文本文件进行模式查找。如果找到匹配模式, grep打印包含模式的所有行。每日一个linux-grep
| 选项 | 含义 |
|---|---|
| -v | 显示不包含匹配文本的所有行(相当于求反) |
| -n | 显示匹配行及行号 |
| -i | 忽略大小写 |
| -c | 输出匹配到的个数 |
| -n | 输出匹配内容,同时显示行数 |
| -v | 输出除匹配外的内容 |
λ cat -n 1.txt
1 sdfsdfsdfsd
2 sdfsdfs
3 sdfsdf
4 sfsd
5 asaa
6 aaa
7
8 AAA
9 CBB
10 CCC
11 CBB
12 1df
13 sdfsd
14 EOF
15 jsldf
C:\Users\asus\Desktop\review\testlinuk
λ ls
1.txt 2.txt 3.txt tes1/ tes2/ test.tart.gz
C:\Users\asus\Desktop\review\testlinuk
λ grep -c sdf 1.txt
4
C:\Users\asus\Desktop\review\testlinuk
λ grep -n sdf 1.txt
1: sdfsdfsdfsd
2: sdfsdfs
3: sdfsdf
13:sdfsd
**ps ** Process Status
linux上进程有5种状态:
-
运行(正在运行或在运行队列中等待)
-
中断(休眠中, 受阻, 在等待某个条件的形成或接受到信号)
-
不可中断(收到信号不唤醒和不可运行, 进程必须等待直到有中断发生)
-
僵死(进程已终止, 但进程描述符存在, 直到父进程调用wait4()系统调用后释放)
-
停止(进程收到SIGSTOP, SIGSTP, SIGTIN, SIGTOU信号后停止运行运行)
ps工具标识进程的5种状态码:
D 不可中断 uninterruptible sleep (usually IO)
R 运行 runnable (on run queue)
S 中断休眠 sleeping
T 停止 traced or stopped
Z 僵死 a defunct (”zombie”) process
常用参数
| a | 显示所有进程 |
|---|---|
| -a | 显示同一终端下的所有程序 |
| -A | 显示所有进程 |
| c | 显示进程的真实名字 |
| -e | 等于-A |
| e | 显示环境变量 |
| f | 显示程序间的关系 |
| -H | 显示树状结构 |
| -aux | 显示所有包含其他使用者的进程 |
[root@localhost test6]# ps -l
F S UID PID PPID C PRI NI ADDR SZ WCHAN TTY TIME CMD
4 S 0 17398 17394 0 75 0 - 16543 wait pts/0 00:00:00 bash
4 R 0 17469 17398 0 77 0 - 15877 - pts/0 00:00:00 ps
列出目前所有的正在内存当中的程序
ps aux
root@localhost test6]# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.0 10368 676 ? Ss Nov02 0:00 init [3]
root 2 0.0 0.0 0 0 ? S< Nov02 0:01 [migration/0]
root 3 0.0 0.0 0 0 ? SN Nov02 0:00 [ksoftirqd/0]
root 4 0.0 0.0 0 0 ? S< Nov02 0:01 [migration/1]
root 5 0.0 0.0 0 0 ? SN Nov02 0:00 [ksoftirqd/1]
root 6 0.0 0.0 0 0 ? S< Nov02 29:57 [events/0]
root 7 0.0 0.0 0 0 ? S< Nov02 0:00 [events/1]
- USER:该 process 属于那个使用者账号的
- PID :该 process 的号码
- %CPU:该 process 使用掉的 CPU 资源百分比
- %MEM:该 process 所占用的物理内存百分比
- VSZ :该 process 使用掉的虚拟内存量 (Kbytes)
- RSS :该 process 占用的固定的内存量 (Kbytes)
- TTY :该 process 是在那个终端机上面运作,若与终端机无关,则显示 ?,另外, tty1-tty6 是本机上面的登入者程序,若为 pts/0 等等的,则表示为由网络连接进主机的程序。
- STAT:该程序目前的状态,主要的状态有
- R :该程序目前正在运作,或者是可被运作
- S :该程序目前正在睡眠当中 (可说是 idle 状态),但可被某些讯号 (signal) 唤醒。
- T :该程序目前正在侦测或者是停止了
- Z :该程序应该已经终止,但是其父程序却无法正常的终止他,造成 zombie (疆尸) 程序的状态
- START:该 process 被触发启动的时间
- TIME :该 process 实际使用 CPU 运作的时间
- COMMAND:该程序的实际指令
有一个脚本运行时间可能超过2天,如何做才能使其不间断的运行,而且还可以随时观察脚本运行时的输出信息?
答:使用screen工具
awk 参考阮一峰-awk 入门教程
awk是处理文本文件的一个应用程序,几乎所有 Linux 系统都自带这个程序。
它依次处理文件的每一行,并读取里面的每一个字段。对于日志、CSV 那样的每行格式相同的文本文件,awk可能是最方便的工具, awk其实不仅仅是工具软件,还是一种编程语言
# 格式
$ awk 动作 文件名
# 示例
$ awk '{print $0}' demo.txt
demo.txt是awk所要处理的文本文件。前面单引号内部有一个大括号,里面就是每一行的处理动作print $0。其中,print是打印命令,$0代表当前行,因此上面命令的执行结果,就是把每一行原样打印出来
变量
$ + 数字表示某个字段
变量NF表示当前行有多少个字段,因此$NF就代表最后一个字段。
$ echo 'this is a test' | awk '{print $NF}'
test
变量NR表示当前处理的是第几行。
$ awk -F ':' '{print NR ") " $1}' demo.txt
1) root
2) daemon
3) bin
4) sys
5) sync
条件
$ awk '条件 动作' 文件名
$ awk -F ':' '/usr/ {print $1}' demo.txt
root
daemon
bin
sys
print命令前面是一个正则表达式,只输出包含usr的行
# 输出奇数行
$ awk -F ':' 'NR % 2 == 1 {print $1}' demo.txt
root
bin
sync
输出第一个字段的第一个字符大于m的行,否则输出‘---’
$ awk -F ':' '{if ($1 > "m") print $1; else print "---"}' demo.txt
root
---
---
sys
sync
查看特定IP的日志
cat ip.log | awk -F '\t' '($1~/112.15.5.36/){print $0}'
查看访问量前10的IP
awk '{print &1}' 17.log | sort | uniq -c | sort -nr | head -n 10
[linux下使用awk命令按时间段筛选日志](https://segmentfault.com/a/1190000011626977)
参考awk 常用命令
sed命令
sed行文件编辑命令,编辑文件以行为单位
sed [参数] '[动作]<匹配条件>' [文件名]
- -i 标识对文件进行行编辑
- a\ 在匹配到的内容下一行增加内容
sed -i 3a\nihao hello world test.txt - i\ 在匹配到的内容上一行增加内容
- d 删除匹配到的内容
- s 替换匹配到的内容
- 住:上面的动作只有在加上参数-i的时候才会生效
命令格式:
sed -i '行号s#原内容#替换后的内容#列号' # 只替换第一个匹配到的项,替换所有内容在尾部加g
sed -n '5,10p' mywork.log查看5行到10行的日志。
screen
能够在一个真实终端下运行多个全屏的伪终端,可以避免HUP信号的影响
常用命令:
screen -S session name # 建立一个指定会话名的 伪终端, 并跳转到该窗口
screen -ls # 列出所有screen 启动的会话
screen -r session name # 重连会话
screen -x session name # 重连会话
screen -wipe # 检查目前所有screen 作业, 并删除已经无效的作用
CTRL -a d # 暂时断开当前会话
CTRL -a k # kill window and process 关闭当前screen窗口和里面的进程,也可以使用exit退出当前窗口
kill
作用: 想进程发送信号,而不是直接杀死进程
kil [参数] [信号]
kill [信号] [进程ID]
- -l 列出全部的信号名称
- -a 当处理当前进程时,不限制命令名和进程号的对应关系
- -p 指定kill 命令只打印相关进程的进程号,而不发送任何信号
- -s 指定发送信号
- -u 指定用户
如果不指定信号编号,则默认发送15号SIGTERM 信号。该信号是程序结束(terminate)信号,将终止所有不能捕获该信号的进程,通常用来要求程序自己正常退出。如果进程仍然终止不了,可尝试发送9号SIGKILL信号,强制杀死进程。
一共有64个信号。其中,前32个信号属于Unix经典信号(即所有类Unix操作系统都提供的信号);后32个信号属于实时信号(用户实时自定义信号),即与特定的硬件驱动相匹配的信号。常用的是前32个信号,而后32个信号做底层驱动开发时能用到。
信号是进程间通信机制中唯一的异步通信机制,可以看作是异步通知,通知接收信号的进程有哪些事情发生了。也可以简单理解为信号是某种形式上的软中断
以下列出几个常用的信号:
| 信号 | 值 | 描述 |
|---|---|---|
| SIGHUP | 1 | 当用户退出终端时,由该终端开启的所有进程都退接收到这个信号,默认动作为终止进程。 |
| SIGINT | 2 | 程序终止(interrupt)信号, 在用户键入INTR字符(通常是Ctrl+C)时发出,用于通知前台进程组终止进程。 |
| SIGQUIT | 3 | 和SIGINT类似, 但由QUIT字符(通常是Ctrl+\)来控制. 进程在因收到SIGQUIT退出时会产生core文件, 在这个意义上类似于一个程序错误信号。 |
| SIGKILL | 9 | 用来立即结束程序的运行. 本信号不能被阻塞、处理和忽略。 |
| SIGTERM | 15 | 程序结束(terminate)信号, 与SIGKILL不同的是该信号可以被阻塞和处理。通常用来要求程序自己正常退出。 |
| SIGSTOP | 19 | 停止(stopped)进程的执行. 注意它和terminate以及interrupt的区别:该进程还未结束, 只是暂停执行. 本信号不能被阻塞, 处理或忽略. (Ctrl+Z) |
| SIGCONT | 18 | 继续信号(对应19号暂停信号) fg, bg |
| SIGSEGV | 11 | 段错误信号,指程序段出错的时候报错,或者访问非法地址,如 向不存在的内存地址进行写操作、对内核空间(注:在32位Linux操作系统中,地址空间的划分为:0~3G为用户空间,3~4G为内核空间)进行写操作、对只读数据区进行写操作(如实例1所示)等 |
信号的捕获机制
内核处理一个进程收到的信号的时机是在一个进程从内核态返回用户态时。 所以,当一个进程在内核态下运行时,软中断信号并不立即起作用,要等到将返回用户态时才处理。进程只有处理完信号才会返回用户态,进程在用户态下不会有未处理完的信号。
内核处理一个进程收到的软中断信号是在该进程的上下文中,因此,进程必须处于运行状态。当进程接收到一个它忽略的信号时,进程丢弃该信号,就像没有收到该信号似的继续运行。
如果进程收到一个要捕捉的信号,那么进程从内核态返回用户态时执行用户定义的函数。而且执行用户定义的函数的方法很巧妙,内核在用户栈上创建一个新的层,该层中将返回地址的值设置成用户定义的处理函数的地址,这样进程从内核返回弹出栈顶时就返回到用户定义的函数处,从函数返回再弹出栈顶时,才返回原先进入内核的地方。 这样做的原因是用户定义的处理函数不能且不允许在内核态下执行(如果用户定义的函数在内核态下运行的话,用户就可以获得任何权限)。
下面引用一个例子说明这个过程:
- 用户程序注册了
SIGQUIT信号的处理函数sighandler。 - 当前正在执行
main函数,这时发生中断或异常切换到内核态。 - 在中断处理完毕后要返回用户态的
main函数之前检查到有信号SIGQUIT递达。 - 内核决定返回用户态后不是恢复
main函数的上下文继续执行,而是执行sighandler函数,sighandler和main函数使用不同的堆栈空间,它们之间不存在调用和被调用的关系,是两个独立的控制流程。 sighandler函数返回后自动执行特殊的系统调用sigreturn再次进入内核态。- 如果没有新的信号要递达,这次再返回用户态就是恢复
main函数的上下文继续执行了。
jobs
查看当前有多少在后台运行的程序, jobs命令显示的是当前shell环境中所起的后台正在运行或者被挂起的任务信息
job的状态可以使running, terminated, stopped
jobs -l 显示所有后台运行的任务PID
fg
将后台中的进程调至前台继续运行
fg %jobnumber %jobnumber是通过jobs命令查到的后台正在执行的命令的序号(不是pid)
bg
将一个在后台暂停的进程,变成继续执行(在后台执行)
bg jonnumber
批量kill 包含某字段的所有进程
ps -ef | grep field | grep -v grep | cut -c 9-15 | xargs kill -9
ps -ef|grep field查看所有包含某字段的进程grep -v grep在列出的进程中去除包含有关键字grep的进程cut -c 9-15截取输入行的第9-15个字符,而这正好是进程的PIDxargs kill -9其中xargs命令是用来把前面命令的输出结果(PID)作为kill -9命令的参数, 并执行该命令
ps x | grep field | grep -v grep | awk '{print $1}' | xargs kill -9
# 统计僵尸进程
ps -ef | grep defunct |grep -v grep | wc -l
# 查看所有运行的进程
ps aux | less
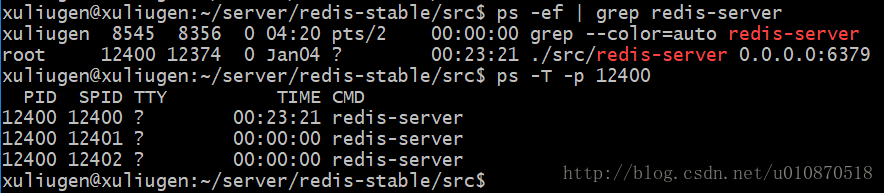
# 查看某进程下的线程
ps -ef | grep redis-sever
# ->redis-server pid:12400
ps -T -p 12400
# ps命令的“-T”参数表示显示线程(Show threads, possibly with SPID column.)“SID”栏表示线程ID,而“CMD”栏则显示了线程名称
xargs
批量删除含有大量内容的文件
ls | grep '.csv' | xargs -n 100 rm -rf
查找所有的 jpg 文件,并且压缩它们
find . -type f -name '*.jpg' -print | xargs tar -czvf images.tar.gz
假如你有一个文件包含了很多你希望下载的 URL,你能够使用 xargs下载所有链接
cat url-list.txt | xargs wget -c
linux后台执行命令:&和nohup
&
当在前台运行某个作业时,终端被该作业占据;可以在命令后面加上& 实现后台运行。例如:sh test.sh &
command > out.file 2>&1 &
当你成功地提交进程以后,就会显示出一个进程号,可以用它来监控该进程,或杀死它。(ps -ef | grep 进程号 或者 kill -9 进程号)
nohup
使用&命令后,作业被提交到后台运行,当前控制台没有被占用,但是一但把当前控制台关掉(退出帐户时),作业就会停止运行。nohup命令可以在你退出帐户之后继续运行相应的进程。nohup就是不挂起的意思( no hang up),可以让进程在后台可靠运行
nohub ./program > /dev/null 2>&1 &
/dev/null 一个文件无底洞, 所有的重定向到它的信息都会消失得无影无踪
如果使用nohup命令提交作业,那么在缺省情况下该作业的所有输出都被重定向到一个名为nohup.out的文件中,除非另外指定了输出文件
nohub command > out.file 2>&1 &
使用了nohup之后,很多人就这样不管了,其实这样有可能在当前账户非正常退出或者结束的时候,命令还是自己结束了。所以在使用nohup命令后台运行命令之后,需要使用exit正常退出当前账户,这样才能保证命令一直在后台运行
-
ctrl + z
可以将一个正在前台执行的命令放到后台,并且处于暂停状态。 -
Ctrl+c
终止前台命令。 -
jobs
查看当前有多少在后台运行的命令。
jobs -l选项可显示所有任务的PID,jobs的状态可以是running, stopped, Terminated。但是如果任务被终止了(kill),shell 从当前的shell环境已知的列表中删除任务的进程标识
2>&1解析
command >out.file 2>&1 &
-
command>out.file是将command的输出重定向到out.file文件,即输出内容不打印到屏幕上,而是输出到out.file文件中
-
2>&1 是将标准出错重定向到标准输出,这里的标准输出已经重定向到out.file文件,即将标准出错也输出到out.file文件中,最后一个 & 是让该命令在后台运行
-
试想2>1代表什么,2与>结合代表错误重定向,而1则代表错误重定向到一个文件1,而不代表标准输出;换成2>&1,&与1结合就代表标准输出了,就变成错误重定向到标准输出
Linux中的3种重定向
- 0: 表示标准输入
- 1: 标准输出,在一般使用时,默认是标准输出
- 2: 标准错误信息输出
./program.py 2>log # 将某个程序的错误信息输出到log 标准输出打印还是在屏幕, 但是错误信息会输出到log文件中
网络相关
netstat
常用参数-anplt
- -a 显示所有活动的连接以及本机侦听的TCP、UDP端口
- -l 显示监听的server port
- -n 直接使用IP地址,不通过域名服务器
- -p 正在使用Socket的程序PID和程序名称
- -r 显示路由表
- -t 显示TCP传输协议的连线状况
- -u 显示UDP传输协议的连线状况
- -w 显示RAW传输协议的连线状况
# 服务端查看当前TCP 半连接队列的大小
netstat -antp | grep SYN_RECV | wc -l
# 观察半连接队列溢出的情况
netstat -s | grep "SYNs to LISTEN"
# 查看TCP全连接队列是否溢出
netstat -s | grep overflowed
ss
常用参数和netstat类似,如-anp
- -a显示所有的sockets
- -l显示正在监听的
- -n显示数字IP和端口,不通过域名服务器
- -p显示使用socket的对应的程序
- -t只显示TCP sockets
- -u只显示UDP sockets
- -4 -6 只显示v4或v6V版本的sockets
- -s打印出统计信息。这个选项不解析从各种源获得的socket。对于解析/proc/net/top大量的sockets计数时很有效
- -0 显示PACKET sockets
- -w 只显示RAW sockets
- -x只显示UNIX域sockets
- -r尝试进行域名解析,地址/端口
# 查看某个端口全连接队列的使用情况和最大值
ss -lnt | grep port
ss比netstat快的主要原因是,netstat是遍历/proc下面每个PID目录,ss直接读/proc/net下面的统计信息。所以ss执行的时候消耗资源以及消耗的时间都比netstat少很多。当服务器的socket连接数量非常大时(如上万个),无论是使用netstat命令还是直接cat /proc/net/tcp执行速度都会很慢,相比之下ss可以节省很多时间。ss快的秘诀在于,它利用了TCP协议栈中tcp_diag,这是一个用于分析统计的模块,可以获得Linux内核中的第一手信息。如果系统中没有tcp_diag,ss也可以正常运行,只是效率会变得稍微慢但仍然比netstat要快。
iptables
使用iptables 写一条规则:把来源IP为192.168.1.101访问本机80端口的包直接拒绝
iptables -I INPUT -s 192.168.1.101 -p tcp --dport 80 -j REJECT
要想把iptable的规则保存到一个文件中如何做?如何恢复?
iptables-save > 1.ipt
使用iptables-restore反重定向回来:
iptables-restore < 1.ipt
rsync
rsync 同步命令中,下面两种方式有什么不同呢?
(1) rsync -av /dira/ ip:/dirb/ #通过ssh方式同步
(2) rsync -av /dira/ ip::dirb #通过rsync服务的方式同步
rsync 同步时,如果要同步的源中有软连接,如何把软连接的目标文件或者目录同步?
答:同步源文件需要加-L选项
rsync 同步数据时,如何过滤出所有.txt的文件不同步?
答:加上--exclude选项:
--exclude=“*.txt”
rsync同步数据时,如果目标文件比源文件还新,则忽略该文件,如何做?
答:保留更新使用-u或者--update选项
使用rsync同步数据时,假如我们采用的是ssh方式,并且目标机器的sshd端口并不是默认的22端口,那我们如何做?
rsync "--rsh=ssh -p 10022"或者rsync -e "ssh -p 10022"
rsync同步时,如何删除目标数据多出来的数据,即源上不存在,但目标却存在的文件或者目录?
答:加上--delete选项
有一天你突然发现公司网站访问速度变的很慢很慢,你该怎么办呢?
(服务器可以登陆,提示:你可以从系统负载和网卡流量入手)
答:可以从两个方面入手分析:分析系统负载,使用w命令或者uptime命令查看系统负载,如果负载很高,则使用top命令查看CPU,MEM等占用情况,要么是CPU繁忙,要么是内存不够,如果这二者都正常,再去使用sar命令分析网卡流量,分析是不是遭到了攻击。一旦分析出问题的原因,采取对应的措施解决,如决定要不要杀死一些进程,或者禁止一些访问等。
在Linux下如何指定dns服务器,来解析某个域名?
# 使用dig命令:dig @DNSip http://domain.com
dig @8.8.8.8 www.baidu.com#使用谷歌DNS解析百度
tcpdump抓包工具
$ tcpdump -i eth0 -nn -s0 -v port 80 -w test.pcap
-
-i : 选择要捕获的接口,通常是以太网卡或无线网卡,也可以是
vlan或其他特殊接口。如果该系统上只有一个网络接口,则无需指定。 -
-nn : 单个 n 表示不解析域名,直接显示 IP;两个 n 表示不解析域名和端口。这样不仅方便查看 IP 和端口号,而且在抓取大量数据时非常高效,因为域名解析会降低抓取速度。
-
-s0 : tcpdump 默认只会截取前
96字节的内容,要想截取所有的报文内容,可以使用-s number,number就是你要截取的报文字节数,如果是 0 的话,表示截取报文全部内容。 -
-v : 使用
-v,-vv和-vvv来显示更多的详细信息,通常会显示更多与特定协议相关的信息。 -
port 80: 这是一个常见的端口过滤器,表示仅抓取80端口上的流量,通常是 HTTP -
host 10.10.1.1: host过滤器, 抓取特定目的地和源IP地址的流量,也可以使用src或dst只抓取源或目的地 -
-w: 把数据报文输出到文件
-
-p : 不让网络接口进入混杂模式。默认情况下使用 tcpdump 抓包时,会让网络接口进入混杂模式。一般计算机网卡都工作在非混杂模式下,此时网卡只接受来自网络端口的目的地址指向自己的数据。当网卡工作在混杂模式下时,网卡将来自接口的所有数据都捕获并交给相应的驱动程序。如果设备接入的交换机开启了混杂模式,使用
-p选项可以有效地过滤噪声。 -
-e : 显示数据链路层信息。默认情况下 tcpdump 不会显示数据链路层信息,使用
-e选项可以显示源和目的 MAC 地址,以及 VLAN tag 信息
如果想实时将抓取到的数据通过管道传递给其他工具来处理,需要使用 -l 选项来开启行缓冲模式(或使用 -c 选项来开启数据包缓冲模式)。使用 -l 选项可以将输出通过立即发送给其他命令,其他命令会立即响应。
tcpdump -i eth0 -s0 -l port 80 | grep 'Server:'
硬链接和软连接的本质区别
- 硬链接
文件都有文件名与数据,这在 Linux 上被分成两个部分:用户数据 (user data) 与元数据 (metadata)。用户数据,即文件数据块 (data block),数据块是记录文件真实内容的地方;而元数据则是文件的附加属性,如文件大小、创建时间、所有者等信息。在 Linux 中,元数据中的 inode 号(inode 是文件元数据的一部分但其并不包含文件名,inode 号即索引节点号)才是文件的唯一标识而非文件名。文件名仅是为了方便人们的记忆和使用,系统或程序通过 inode 号寻找正确的文件数据块。下图展示了程序通过文件名获取文件内容的过程。

由于硬链接是有着相同 inode 号仅文件名不同的文件,因此硬链接存在以下几点特性:
- 文件有相同的 inode 及 data block;
- 只能对已存在的文件进行创建;
- 不能交叉文件系统进行硬链接的创建;
- 不能对目录进行创建,只可对文件创建;
- 删除一个硬链接文件并不影响其他有相同 inode 号的文件。
- 软连接
软链接与硬链接不同,若文件用户数据块中存放的内容是另一文件的路径名的指向,则该文件就是软连接。软链接就是一个普通文件,只是数据块内容有点特殊。软链接有着自己的 inode 号以及用户数据块。因此软链接的创建与使用没有类似硬链接的诸多限制:
- 软连接有自己的文件属性及权限
- 可对不存在的文件或目录创建软链接
- 软链接可交叉文件系统
- 软链接可对文件或目录创建
- 创建软链接时,链接计数i_nlink不会增加
- 删除软链接并不影响被指向的文件,但若被指向的原文件被删除,则相关软连接被称为死链接(即 dangling link,若被指向路径文件被重新创建,死链接可恢复为正常的软链接)。

软连接格式: ln -s 源文件 链接文件
硬链接格式: ln 源文件 链接文件
小结:
- 硬链接: 与普通文件没什么不同,可以理解为引用,新增一个别名,引用计数+1文件的inode都一样,指向同一个数据区块
- 软链接:data block中保存了其代表的文件的绝对路径,是另外一种文件,有自己的inode,在硬盘中有独立的区块,访问时替换自身路径
参考资料和书籍
- 《Linux基础千锤百炼》-- 骏马金龙
- Linux工具快速教程-参考教程命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号