python3 源码阅读-虚拟机运行原理
阅读源码版本python 3.8.3
参考书籍<<Python源码剖析>>
参考书籍<<Python学习手册 第4版>>
- Doc目录主要是官方文档的说明。
- Include:目录主要包括了Python的运行的头文件。
- Lib:目录主要包括了用Python实现的标准库。
- Modules: 该目录中包含了所有用C语言编写的模块,比如random、cStringIO等。Modules中的模块是那些对速度要求非常严格的模块,而有一些对速度没有太严格要求的模块,比如os,就是用Python编写,并且放在Lib目录下的
- Objects:该目录中包含了所有Python的内建对象,包括整数、list、dict等。同时,该目录还包括了Python在运行时需要的所有的内部使用对象的实现。
- Parser:该目录中包含了Python解释器中的Scanner和Parser部分,即对Python源码进行词法分析和语法分析的部分。除了这些,Parser目录下还包含了一些有用的工具,这些工具能够根据Python语言的语法自动生成Python语言的词法和语法分析器,将python文件编译生成语法树等相关工作。
- Programs目录主要包括了python的入口函数。
- Python:目录主要包括了Python动态运行时执行的代码,里面包括编译、字节码解释器等工作。
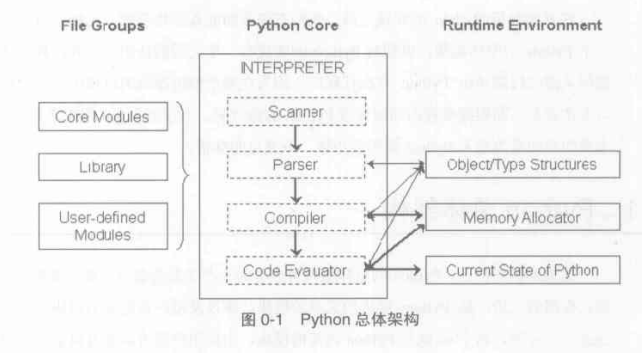
1. 总体架构
-
Runtime Env:python运行时环境,初始化对象/类型系统(Object/Type structures),内存分配器(Memory Allocator) 和 运行时状态信息 (Current state of Python)。运行时状态维护了解释器在执行字节码时不同的状态(如正常和异常)之间的切换动作,可以视为一个巨大而复杂的有穷状态机。内存管理机制可参考另外一篇文章Python3 源码阅读 - 内存管理机制。
-
Python Core: 中间部分是python的核心----解释器(
PyInterpreter), 也可以成为PVM。大致流程就是 先对.py程序进行此法分析,将文件输入的源代码或从命令行输入的一行行python代码切分一个个Token, 然后使用Parser进行语法分析,建立抽象语法树(AST),Compiler根据AST生成字节码指令集合,最后由Code Evaluator来执行这些字节码。 -
File Groups: Python Lib库和用户自己的模块包等源代码文件
2. Run Python文件的启动流程
Python启动是由Programs下的python.c文件中的main函数开始执行
/* Minimal main program -- everything is loaded from the library */
#include "Python.h"
#include "pycore_pylifecycle.h"
#ifdef MS_WINDOWS
int
wmain(int argc, wchar_t **argv)
{
return Py_Main(argc, argv);
}
#else
int
main(int argc, char **argv)
{
return Py_BytesMain(argc, argv);
}
#endif
int
Py_Main(int argc, wchar_t **argv) {
...
return pymian_main(&args);
}
static int
pymain_main(_PyArgv *args)
{
PyStatus status = pymain_init(args); // 初始化
if (_PyStatus_IS_EXIT(status)) {
pymain_free();
return status.exitcode;
}
if (_PyStatus_EXCEPTION(status)) {
pymain_exit_error(status);
}
return Py_RunMain();
}
2.1 初始化关键流程
- 初始化一些与配置项 如:开启utf-8模式,设置Python内存分配器
- 初始化
pyinit_core核心部分- 创建生命周期
pycore_init_runtime, 同时生成HashRandom - 初始化线程和解释器并创建GIL锁
pycore_create_interpreter - 初始化所有基础类型,list, int, tuple等
pycore_init_types - 初始化sys模块
_PySys_Create - 初始化内建函数或者对象,如map, None, True等
pycore_init_builtins- 其中包括内建的错误类型初始化
_PyBuiltins_AddExceptions
- 其中包括内建的错误类型初始化
- 创建生命周期
Python3.8 对Python解释器的初始化做了重构PEP 587-Python初始化配置
2.2 run 相关源码阅读
int
Py_RunMain(void)
{
int exitcode = 0;
pymain_run_python(&exitcode); //执行python脚本
if (Py_FinalizeEx() < 0) { // 释放资源
/* Value unlikely to be confused with a non-error exit status or
other special meaning */
exitcode = 120;
}
pymain_free(); // 释放资源
if (_Py_UnhandledKeyboardInterrupt) {
exitcode = exit_sigint();
}
return exitcode;
}
static void
pymain_run_python(int *exitcode)
{
// 获取一个持有GIL锁的解释器
PyInterpreterState *interp = _PyInterpreterState_GET_UNSAFE();
/* pymain_run_stdin() modify the config */
... // 添加sys_path等操作
if (config->run_command) {
// 命令行模式
*exitcode = pymain_run_command(config->run_command, &cf);
}
else if (config->run_module) {
// 模块名
*exitcode = pymain_run_module(config->run_module, 1);
}
else if (main_importer_path != NULL) {
*exitcode = pymain_run_module(L"__main__", 0);
}
else if (config->run_filename != NULL) {
// 文件名
*exitcode = pymain_run_file(config, &cf);
}
else {
*exitcode = pymain_run_stdin(config, &cf);
}
...
}
/* Parse input from a file and execute it */ //Python/pythonrun.c
int
PyRun_AnyFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
if (filename == NULL)
filename = "???";
if (Py_FdIsInteractive(fp, filename)) {
int err = PyRun_InteractiveLoopFlags(fp, filename, flags); // 是否是交互模式
if (closeit)
fclose(fp);
return err;
}
else
return PyRun_SimpleFileExFlags(fp, filename, closeit, flags); // 执行脚本
}
// 执行python .py文件
int
PyRun_SimpleFileExFlags(FILE *fp, const char *filename, int closeit,
PyCompilerFlags *flags)
{
...
if (maybe_pyc_file(fp, filename, ext, closeit)) {
FILE *pyc_fp;
/* Try to run a pyc file. First, re-open in binary */
...
v = run_pyc_file(pyc_fp, filename, d, d, flags);
} else {
/* When running from stdin, leave __main__.__loader__ alone */
...
v = PyRun_FileExFlags(fp, filename, Py_file_input, d, d,
closeit, flags);
}
...
}
PyObject *
PyRun_FileExFlags(FILE *fp, const char *filename_str, int start, PyObject *globals,
PyObject *locals, int closeit, PyCompilerFlags *flags)
{
...
// // 解析传入的脚本,解析成AST
mod = PyParser_ASTFromFileObject(fp, filename, NULL, start, 0, 0,
flags, NULL, arena);
...
// 将AST编译成字节码然后启动字节码解释器执行编译结果
ret = run_mod(mod, filename, globals, locals, flags, arena);
...
}
// 查看run_mode
static PyObject *
run_mod(mod_ty mod, PyObject *filename, PyObject *globals, PyObject *locals,
PyCompilerFlags *flags, PyArena *arena)
{
...
// 将AST编译成字节码
co = PyAST_CompileObject(mod, filename, flags, -1, arena);
...
// 解释执行编译的字节码
v = run_eval_code_obj(co, globals, locals);
Py_DECREF(co);
return v;
}
2.3 字节码查看案例
新建test.py
def show(a):
return a
if __name__ == "__main__":
print(show(10))
执行命令: python3 -m dis test.py
λ ppython3 -m dis test.py
3 0 LOAD_CONST 0 (<code object show at 0x000000E7FC89E270, file "test.py", line 3>)
2 LOAD_CONST 1 ('show')
4 MAKE_FUNCTION 0
6 STORE_NAME 0 (show)
7 8 LOAD_NAME 1 (__name__)
10 LOAD_CONST 2 ('__main__')
12 COMPARE_OP 2 (==)
14 POP_JUMP_IF_FALSE 28
8 16 LOAD_NAME 2 (print)
18 LOAD_NAME 0 (show)
20 LOAD_CONST 3 (10)
22 CALL_FUNCTION 1
24 CALL_FUNCTION 1
26 POP_TOP
>> 28 LOAD_CONST 4 (None)
左边3, 7, 8表示 test.py中的第一行和第二行,右边表示python byte code
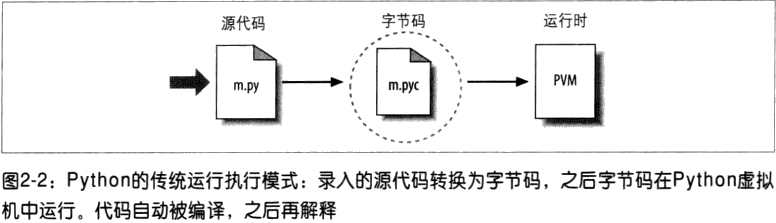
Include/opcode.h 发现总共有 163 个 opcode, 所有的 python 源文件(Lib库中的文件)都会被编译器翻译成由 opcode 组成的 pyx 文件,并缓存在执行目录,下次启动程序如果源代码没有修改过,则直接加载这个pyx文件,这个文件的存在可以加快 python 的加载速度。普通.py文件如我们的test.py 是直接进行编译解释执行的,不会生成.pyc文件,想生成test.pyc 需要使用python内置的py_compile模块来编译该文件,或者执行命令python3 -m test.py python生成.pyc文件
严格意义上来说: 只有文件导入import 的情况下字节码.pyc文件才会保存下来,
__pycache__--- 《python学习手册(第四版) Page40》
2.4 python中的code对象
字节码在python虚拟机中对应的是PyCodeObject对象, .pyc文件是字节码在磁盘上的表现形式。python编译的过程中,一个代码块就对应一个code对象,那么如何确定多少代码算是一个Code Block呢? 编译过程中遇到一个新的命名空间或者作用域时就生成一个code对象,即类或函数都是一个代码块,一个code的类型结构就是PyCodeObject, 参考Junnplus
/* Bytecode object */
typedef struct {
PyObject_HEAD
int co_argcount; /* #arguments, except *args */ // 位置参数的个数,
int co_posonlyargcount; /* #positional only arguments */
int co_kwonlyargcount; /* #keyword only arguments */
int co_nlocals; /* #local variables */
int co_stacksize; /* #entries needed for evaluation stack */
int co_flags; /* CO_..., see below */
int co_firstlineno; /* first source line number */
PyObject *co_code; /* instruction opcodes */
PyObject *co_consts; /* list (constants used) */
PyObject *co_names; /* list of strings (names used) */
PyObject *co_varnames; /* tuple of strings (local variable names) */
PyObject *co_freevars; /* tuple of strings (free variable names) */
PyObject *co_cellvars; /* tuple of strings (cell variable names) */
/* The rest aren't used in either hash or comparisons, except for co_name,
used in both. This is done to preserve the name and line number
for tracebacks and debuggers; otherwise, constant de-duplication
would collapse identical functions/lambdas defined on different lines.
*/
Py_ssize_t *co_cell2arg; /* Maps cell vars which are arguments. */
PyObject *co_filename; /* unicode (where it was loaded from) */
PyObject *co_name; /* unicode (name, for reference) */
PyObject *co_lnotab; /* string (encoding addr<->lineno mapping) See
Objects/lnotab_notes.txt for details. */
void *co_zombieframe; /* for optimization only (see frameobject.c) */
PyObject *co_weakreflist; /* to support weakrefs to code objects */
/* Scratch space for extra data relating to the code object.
Type is a void* to keep the format private in codeobject.c to force
people to go through the proper APIs. */
void *co_extra;
/* Per opcodes just-in-time cache
*
* To reduce cache size, we use indirect mapping from opcode index to
* cache object:
* cache = co_opcache[co_opcache_map[next_instr - first_instr] - 1]
*/
// co_opcache_map is indexed by (next_instr - first_instr).
// * 0 means there is no cache for this opcode.
// * n > 0 means there is cache in co_opcache[n-1].
unsigned char *co_opcache_map;
_PyOpcache *co_opcache;
int co_opcache_flag; // used to determine when create a cache.
unsigned char co_opcache_size; // length of co_opcache.
} PyCodeObject;
| Field | Content | Type |
|---|---|---|
| co_argcount | Code Block 的参数个数 | PyIntObject |
| co_posonlyargcount | Code Block 的位置参数个数 | PyIntObject |
| co_kwonlyargcount | Code Block 的关键字参数个数 | PyIntObject |
| co_nlocals | Code Block 中局部变量的个数 | PyIntObject |
| co_stacksize | Code Block 的栈大小 | PyIntObject |
| co_flags | N/A | PyIntObject |
| co_firstlineno | Code Block 对应的 .py 文件中的起始行号 | PyIntObject |
| co_code | Code Block 编译所得的字节码 | PyBytesObject |
| co_consts | Code Block 中的常量集合 | PyTupleObject |
| co_names | Code Block 中的符号集合 | PyTupleObject |
| co_varnames | Code Block 中的局部变量名集合 | PyTupleObject |
| co_freevars | Code Block 中的自由变量名集合 | PyTupleObject |
| co_cellvars | Code Block 中嵌套函数所引用的局部变量名集合 | PyTupleObject |
| co_cell2arg | N/A | PyTupleObject |
| co_filename | Code Block 对应的 .py 文件名 | PyUnicodeObject |
| co_name | Code Block 的名字,通常是函数名/类名/模块名 | PyUnicodeObject |
| co_lnotab | Code Block 的字节码指令于 .py 文件中 source code 行号对应关系 | PyBytesObject |
| co_opcache_map | python3.8新增字段,存储字节码索引与CodeBlock对象的映射关系 | PyDictObject |
2.4.1 LOAD_CONST
// Python\ceval.c
PREDICTED(LOAD_CONST); -> line 943: #define PREDICTED(op) PRED_##op:
FAST_DISPATCH(); -> line 876 #define FAST_DISPATCH() goto fast_next_opcode
额外收获: c 语言中 ##和# 号 在marco 里的作用可以参考 这篇
在宏定义里, ## 被称为连接符(concatenator) , a##b 表示将ab连接起来
a 表示把a转换成字符串,即加双引号,
所以LONAD_CONST这个指领根据宏定义展开如下:
case TARGET(LOAD_CONST): {
PRED_LOAD_CONST:
PyObject *value = GETITEM(consts, oparg); // 获取一个PyObject* 指针对象
Py_INCREF(value); // 引用计数加1
PUSH(value); // 把刚刚创建的PyObject* push到当前的frame的stack上, 以便下一个指令从这个 stack 上面获取
goto fast_next_opcode;
2.5 main_loop
// Python\ceval.c
main_loop:
for (;;) {
...
switch (opcode) {
/* BEWARE!
It is essential that any operation that fails must goto error
and that all operation that succeed call [FAST_]DISPATCH() ! */
case TARGET(NOP): {
FAST_DISPATCH();
}
case TARGET(LOAD_FAST): {
PyObject *value = GETLOCAL(oparg);
if (value == NULL) {
format_exc_check_arg(PyExc_UnboundLocalError,
UNBOUNDLOCAL_ERROR_MSG,
PyTuple_GetItem(co->co_varnames, oparg));
goto error;
}
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
case TARGET(LOAD_CONST): {
PREDICTED(LOAD_CONST);
PyObject *value = GETITEM(consts, oparg);
Py_INCREF(value);
PUSH(value);
FAST_DISPATCH();
}
...
}
}
在 python 虚拟机中,解释器主要在一个很大的循环中,不停地读入 opcode, 并根据 opcode 执行对应的指令,当执行完所有指令虚拟机退出,程序也就结束了
2.6 总结
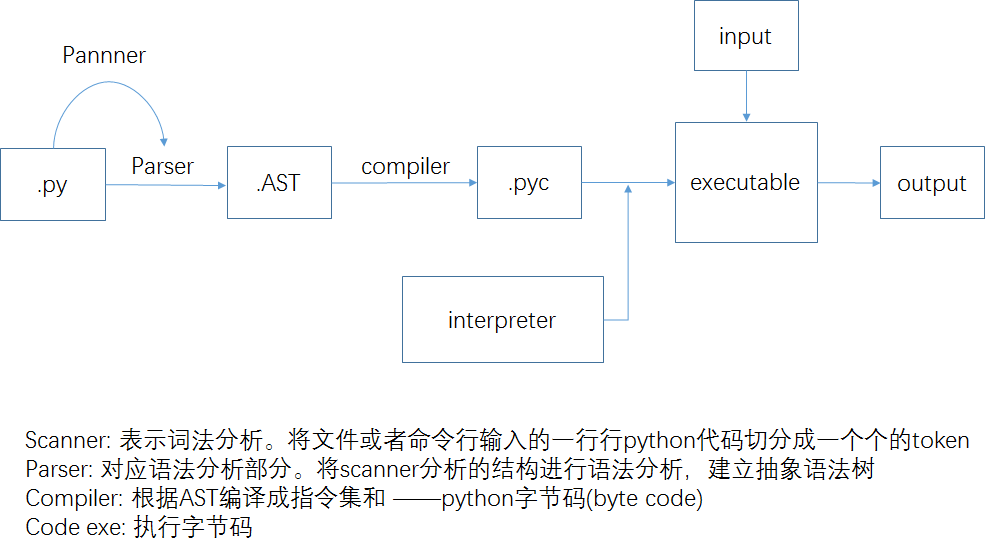
过程描述:
- python先把代码(.py文件)编译成字节码,交给字节码虚拟机,然后虚拟机会从编译得到的
PyCodeObject对象中一条一条执行字节码指令,并在当前的上下文环境中执行这条字节码指令,从而完成程序的执行。Python虚拟机实际上是在模拟操作中执行文件的过程。PyCodeObject对象中包含了字节码指令以及程序的所有静态信息,但没有包含程序运行时的动态信息——执行环境(PyFrameObject),后面会继续记录执行环境的阅读。 - 从整体上看:OS中执行程序离不开两个概念:进程和线程。python中模拟了这两个概念,模拟进程和线程的分别是PyInterpreterState和PyTreadState。即:每个
PyThreadState都对应着一个帧栈,python虚拟机在多个线程上切换(靠GIL实现线程之间的同步)。当python虚拟机开始执行时,它会先进行一些初始化操作,最后进入PyEval_EvalFramEx函数,内部实现了一个main_loop它的作用是不断读取编译好的字节码,并一条一条执行,类似CPU执行指令的过程。函数内部主要是一个switch结构,根据字节码的不同执行不同的代码
3. Python中的Frame
如上所说,PyCodeObject对象只是包含了字节码指令集以及程序的相关静态信息,虚拟机的执行还需要一个执行环境,即PyFrameObject,也就是对系统栈帧的模拟。
3.1 堆和栈的认识
堆中存的是对象。栈中存的是基本数据类型和堆中对象的引用。一个对象的大小是不可估计的,或者说是可以动态变化的,但是在栈中,一个对象只对应了一个4btye的引用(堆栈分离的好处)
内存中的堆栈和数据结构堆栈不是一个概念,可以说内存中的堆栈是真实存在的物理区,数据结构中的堆栈是抽象的数据存储结构。
内存空间在逻辑上分为三部分:代码区,静态数据区和动态数据区,动态数据区有分为堆区和栈区
- 代码区:存储的二进制代码块,高级调度(作业调度)、中级调度(内存调度)、低级调度(进程调度)控制代码区执行代码的切换
- 静态数据区:存储全局变量,静态变量,常量,系统自动分配和回收。
- 动态数据区:
- 栈区(stack):存储运行方法的形参,局部变量,返回值,有编译器自动分配和回收,操作类似数据结构中的栈
- 堆区(heap):new一个对象的引用或者地址存储在栈区,该地址指向指向对象存储在堆区中的真实数据。如c中的
malloc函数,python中的Pymalloc
3.2 PyFrameObject对象
typedef struct _frame{
PyObject_VAR_HEAD //"运行时栈"的大小是不确定的, 所以用可变长的对象
struct _frame *f_back; //执行环境链上的前一个frame,很多个PyFrameObject连接起来形成执行环境链表
PyCodeObject *f_code; //PyCodeObject 对象,这个frame就是这个PyCodeObject对象的上下文环境
PyObject *f_builtins; //builtin名字空间
PyObject *f_globals; //global名字空间
PyObject *f_locals; //local名字空间
PyObject **f_valuestack; //"运行时栈"的栈底位置
PyObject **f_stacktop; //"运行时栈"的栈顶位置
//...
int f_lasti; //上一条字节码指令在f_code中的偏移位置
int f_lineno; //当前字节码对应的源代码行
//...
//动态内存,维护(局部变量+cell对象集合+free对象集合+运行时栈)所需要的空间
PyObject *f_localsplus[1];
} PyFrameObject;
如果你想知道 PyFrameObject 中每个字段的意义, 请参考 Junnplus' blog 或者直接阅读源代码,了解frame的执行过程可以参考zpoint'blog.
名字空间实际上是维护着变量名和变量值之间关系的PyDictObject对象。
f_builtins, f_globals, f_locals名字空间分别维护了builtin, global, local的name与对应值之间的映射关系。
每一个 PyFrameObject对象都维护了一个 PyCodeObject对象,这表明每一个 PyFrameObject中的动态内存空间对象都和源代码中的一段Code相对应。
每当在解释器中做一次函数调用时,会创建一个新的PyFrameObject对象,这个对象就是当前函数调用的栈帧对象。
从调用栈理解Python协程的运行流程
具体可以参考zpoint'blog. 以下为个人小结。
python的yield是用底层虚拟机的栈状态切换来实现的,实现机制借鉴Lua5.2 的协程,
CPython的yield实现是基于栈和Frame, PyFrameObject是Cython中的一个模拟栈帧的对象,yield对应一个生成器对象genobject.c yield在虚拟机中对应一个操作码 YIELD_VALUE, 即虚拟机对应的字节码, 这样就可以很好的理解,上下文是如何保存的了,一个对象的状态保存和切换,使用一些属性来做,在虚拟机中很好实现。CPython的yield的确是单线程,或者说,其实CPython把yield和对应的生成器只是转化为一段字节码,CPython虚拟机的字节码执行是单线程的。
yield的实现我个人理解为中断机制,当一个生成器对象初始化的时候就会把对应的参数,变量值放入堆中,当加载到yield 的时候,会先执行一个 LOAD FAST 的操作码,获取yield所要返回的值如果没有就是None, 将其压入栈中, 接着由于LOAD FAST对应着FAST DISPATCH的机制,就会继续执行下一个操作码 YIELD_VALUE 紧接着 POP_TOP 推出栈顶元素。此时被调用的Frame(当前的迭代器对象)并没有被释放而是进入一个zombie的状态,下一次同个代码段执行时, 这个 frame 对象会优先被复用。
3.2.1 栈帧的获取,工作中会用到
可以通过sys._getframe([depth]), 获取指定深度的PyFrameObject对象
>>> import sys
>>> frame = sys._getframe()
>>> frame
<frame object at 0x103ab2d48>
3.2.2 python中变量名的解析规则 LEGB
Local -> Enclosed -> Global -> Built-In
-
Local 表示局部变量
-
Enclosed 表示嵌套的变量
-
Global 表示全局变量
-
Built-In 表示内建变量
如果这几个顺序都取不到,就会抛出 ValueError
可以在这个网站python执行可视化网站,观察代码执行流程,以及变量的转换赋值情况。
4. 额外收获
意外收获: 之前知道pythonGIL , 遇到I/O阻塞时会释放gil,现在从源码中看到了对应的流程
if (_Py_atomic_load_relaxed(&ceval->gil_drop_request)) {
/* Give another thread a chance */
if (_PyThreadState_Swap(&runtime->gilstate, NULL) != tstate) {
Py_FatalError("ceval: tstate mix-up");
}
drop_gil(ceval, tstate);
/* Other threads may run now */
take_gil(ceval, tstate);
/* Check if we should make a quick exit. */
exit_thread_if_finalizing(runtime, tstate);
if (_PyThreadState_Swap(&runtime->gilstate, tstate) != NULL) {
Py_FatalError("ceval: orphan tstate");
}
}
/* Check for asynchronous exceptions. */

 浙公网安备 33010602011771号
浙公网安备 33010602011771号