MySQL 基础回顾(2020/06/14修改)
20200705修改,修改排版和增加BTree&B+tree 数据库引擎底层的数据结构
mysql 回顾
数据库的设计必须满足三范式
- 1NF: 强调列的原子性,列不可拆分
eg: 一张表(联系人) 有(姓名,性别,电话)三列,但是现实中电话又可分为家庭电话和公司电话,这种表结构设计就不符合第一范式了,
正确的应该是继续拆分(姓名,性别,家庭电话,公司电话)
-
2NF: 首先满足1NF,另外包含两点:
- 表必须有一个主键
- 非主键列必须完全依赖于主键,而不能只依赖与主键的一部分
eg: 有这样一张表
OrderDetail:(OrderID,ProductID,UnitPrice,Discount,Quantity,ProductName)。
我们知道在一个订单中可以订购多种产品,所以单单一个 OrderID 是不足以成为主键的,主键应该是(OrderID,ProductID)。
显而易见 Discount(折扣),Quantity(数量)完全依赖(取决)于主键(OderID,ProductID),而 UnitPrice,ProductName
只依赖于 ProductID。所以 OrderDetail 表不符合 2NF。不符合 2NF 的设计容易产生冗余数据
正确的做法应该是进行分表:
【OrderDetail】表拆分为【OrderDetail】(OrderID,ProductID,Discount,Quantity)和【Product】(ProductID,UnitPrice,ProductName)来消除原订单表中UnitPrice,ProductName多次重复的情况。
-
3NF 首先要满足2NF,另外非主键列必须直接依赖于主键,不能存在传递关系,即:非主键列A 依赖于非主键列B, 非主键列B依赖于主键的情况
eg: 订单表
Order(OrderID,OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity)主键是(OrderID)
其中 OrderDate,CustomerID,CustomerName,CustomerAddr,CustomerCity 等非主键列都完全依赖于主键
(OrderID),所以符合 2NF。不过问题是 CustomerName,CustomerAddr,CustomerCity 直接依赖的是 CustomerID(非主键列),而不是直接依赖于主键,它是通过传递才依赖于主键,所以不符合 3NF。
正确的方式:Order 拆分为【Order】(OrderID,OrderDate,CustomerID)和【Customer】(CustomerID,CustomerName,CustomerAddr,CustomerCity)从而达到 3NF
范式小结
第二范式 和 第三范式容易混淆,关键在于, 2NF: 非主键列是否完全依赖于主键,还是依赖于主键的一部分; 3NF: 非主键列是直接依赖于主键,还是直接依赖于非主键列。
SQL:
- DDL 数据定义语言 如: create, alter, drop
- TPL 事务处理语言 如:commit, rollback
- DCL 数据控制语言 如:grant, 控制数据库对象访问权限的一些语句
- DML 数据操作语言 如:select, insert , update, delete, 等操作数据的语句
数据库的 CURD
数据源:
-- students表
create table students(
id int unsigned primary key auto_increment not null,
name varchar(20) default '',
age tinyint unsigned default 0,
height decimal(5,2),
gender enum('男','女','中性','保密') default '保密',
cls_id int unsigned default 0,
is_delete bit default 0
);
-- classes表
create table classes (
id int unsigned auto_increment primary key not null,
name varchar(30) not null
);
添加数据:
-- 向students表中插入数据
# 主键id 是自动增长的,使用全列插入时需要占位,通常用0,default、null 来占位
insert into students values
(0,'小明',18,180.00,2,1,0),
(0,'彭于晏',29,185.00,1,1,0),
(0,'刘德华',59,175.00,1,2,1),
(0,'黄蓉',38,160.00,2,1,0),
(0,'凤姐',28,150.00,4,2,1),
(0,'王祖贤',18,172.00,2,1,1),
(0,'周杰伦',36,NULL,1,1,0),
(0,'静香',12,180.00,2,4,0),
(0,'郭靖',12,170.00,1,4,0),
(0,'周杰',34,176.00,2,5,0);
-- 向classes表中插入数据
insert into classes values (0, "一班"), (0, "二班");
基本命令
create databse db_name charset=utf8; # 创建数据库
show databses; # 显示所有数据库
show create database db_name; # 查看数据库的基本信息
use db_name; # 切换数据库
select database(); # 查看当前所用数据库
select now(); # 查看当前时间
MySQL查询语句
- as 可给字段,或者给表起别名
select s.id, s.name, s.gender from students as s;
- 消除重复行
select distinct gender from students;
- 条件where 子句
优先级(由高到低): 小括号,not, 比较运算符,逻辑运算符,and比or先运算
注意: 不推荐使用
a) 负向查询条件:NOT、!=、<>、!<、!>、NOT IN、NOT LIKE等,会导致全表扫描
b) %开头的模糊查询,会导致全表扫描 -
- 比较运算符
- 逻辑运算符
- 模糊查询
- like
eg: select * from students where name like; '黄%' # 查询姓黄的学生 - % 表示任意多个任意字符
eg: select * from students where name like; '黄_' # 查询姓黄且名字是一个字的学生 - _ 表示一个任意字符
- like
- 范围查询
- in 表示在一个非连续的范围内
eg: select * from students where id in (1, 3, 8); - between...and... 表示在一个连续的范围内
eg: select * from students where id between 3 and 8;
- in 表示在一个非连续的范围内
- 空判断
- null (与''不同)
- is not null
- 排序 order by 默认升序 asc
- asc 升序
- desc 降序
eg: 查询未删除的男生信息,按学号降序
select * from students where gender=1 and is_delete=0 order by id desc;
-
聚合函数
- count
- max
- min
- sum
- avg
-
分组 group by 一般结合聚合函数使用
将查询结果按照1个或多个字段进行分组,字段值相同的为一组- group by + group_concat(字段名) 将分组结果 根据字段名 输出对应字段值的集合
select gender, group_concat(name) from students group by gender; - group by + 聚合函数
eg: 按性别分别统计年龄的平均值
select gender, avg(age) from students group by gender; - group by + having
用来分组查询后指定一些条件来输出查询结果, 作用和where一样,但是只能用于group by
select gender,count() from students group by gender having count()>2; - gounp by + with rollup
with rollup作用: 最后新增一行,来记录当前列里所有记录的总和
- group by + group_concat(字段名) 将分组结果 根据字段名 输出对应字段值的集合
-
连接查询多表查询 join 表连接原理: 笛卡尔积
- 内连接
- 右连接 在内连接的基础上添加右表数据,右表中没有的数据字段使用null填充
- 左连接 在内连接的基础上添加左表数据,右表中没有的数据字段使用null填充
# 笛卡尔积 在其他数据库中内连接和笛卡尔积石油区别的,在mysql中 join 和 inner join 是一样的
select * from table1 [inner] join table2;
条件查询(on子句 过滤笛卡尔积)
语法: select * from table1 inner|left|right join table2 on table1.field = table2.field
-
自关联
应用场景 区域信息,分类信息(如淘宝分类栏,大类,小类,具体分类) -
子查询
- 标量子查询 一行一列
子查询的结果是一个标量
eg: 查询大于平年龄的学生
select * from students where age > (select avg(age) from students);- 列子查询 返回的结果是一列多行
- 行子查询 返回的结果是一行多列
行元素: 将多个字段合成一个行元素,在行级子查询中会使用到行元素
select * from students where (height, age) = (select max(height),max(age) from students);主查询和子查询的关系
· 子查询是嵌入主查询的
· 子查询要么充当条件,要么作为数据源
· 子查询也是一条完整的select语句 - 标量子查询 一行一列
MySQL的事务及其实现原理
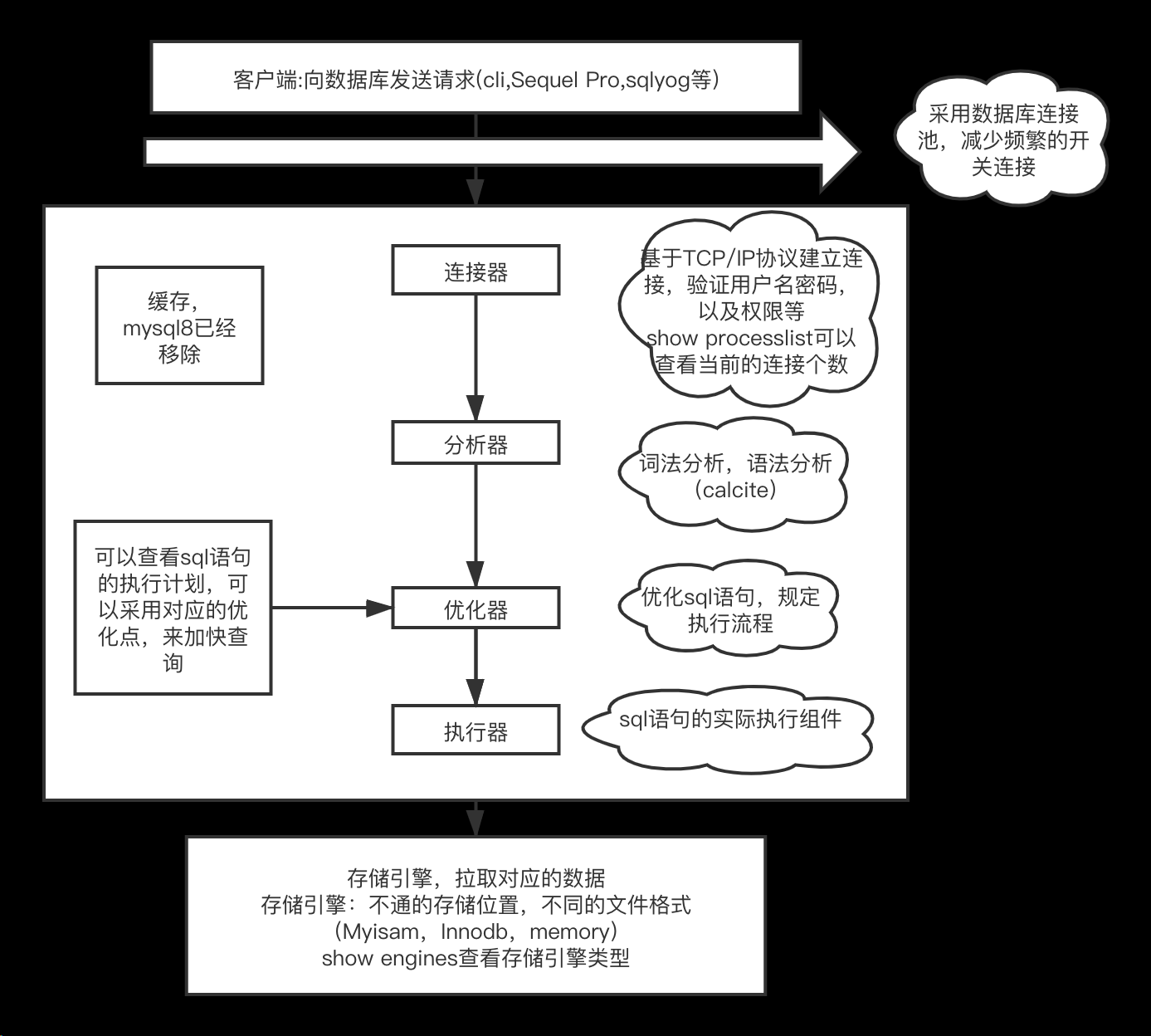
MySQL中默认采用的是自动提交(autocommit)模式,如下所示:
mysql> show variables like 'autocommit';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| autocommit | ON |
+---------------+-------+
1 row in set (0.00 sec)
在自动提交模式下,如果没有start transaction显式地开始一个事务,那么每个sql语句都会被当做一个事务执行提交操作。
在MySQL中,存在一些特殊的命令,如果在事务中执行了这些命令,会马上强制执行commit提交事务;如DDL语句(create table/drop table/alter/table)、lock tables语句等等, 常用的select、insert、update和delete命令,都不会强制提交事务。但是默认是自动commit的
事务是多个SQL语句操作的序列,这些操作要么都执行,要么都不执行,如有有一个失败,便回滚到原始状态 +
应用场景: 充话费,银行转账,地铁卡充值等
原子性 Atomicity
原子性是指一个事务是一个不可分割的工作单位,其中的操作要么都做,要么都不做;如果事务中一个sql语句执行失败,则已执行的语句也必须回滚,数据库退回到事务前的状态。
简单来说,就是要么全部失败,要么全部成功。
实现原理:
InnoDB存储引擎提供了两种事务日志:redo log(重做日志)和undo log(回滚日志)。其中redo log用于保证事务持久性;undo log则是事务原子性和隔离性实现的基础。
实现原子性的关键,是当事务回滚时能够撤销所有已经成功执行的sql语句。InnoDB实现回滚,靠的是undo log:当事务对数据库进行修改时,InnoDB会生成对应的undo log;如果事务执行失败或调用了rollback,导致事务需要回滚,便可以利用undo log中的信息将数据回滚到修改之前的样子。
undo log属于逻辑日志,它记录的是sql执行相关的信息。当发生回滚时,InnoDB会根据undo log的内容做与之前相反的工作:对于每个insert,回滚时会执行delete;对于每个delete,回滚时会执行insert;对于每个update,回滚时会执行一个相反的update,把数据改回去。
以update操作为例:当事务执行update时,其生成的undo log中会包含被修改行的主键(以便知道修改了哪些行)、修改了哪些列、这些列在修改前后的值等信息,回滚时便可以使用这些信息将数据还原到update之前的状态。
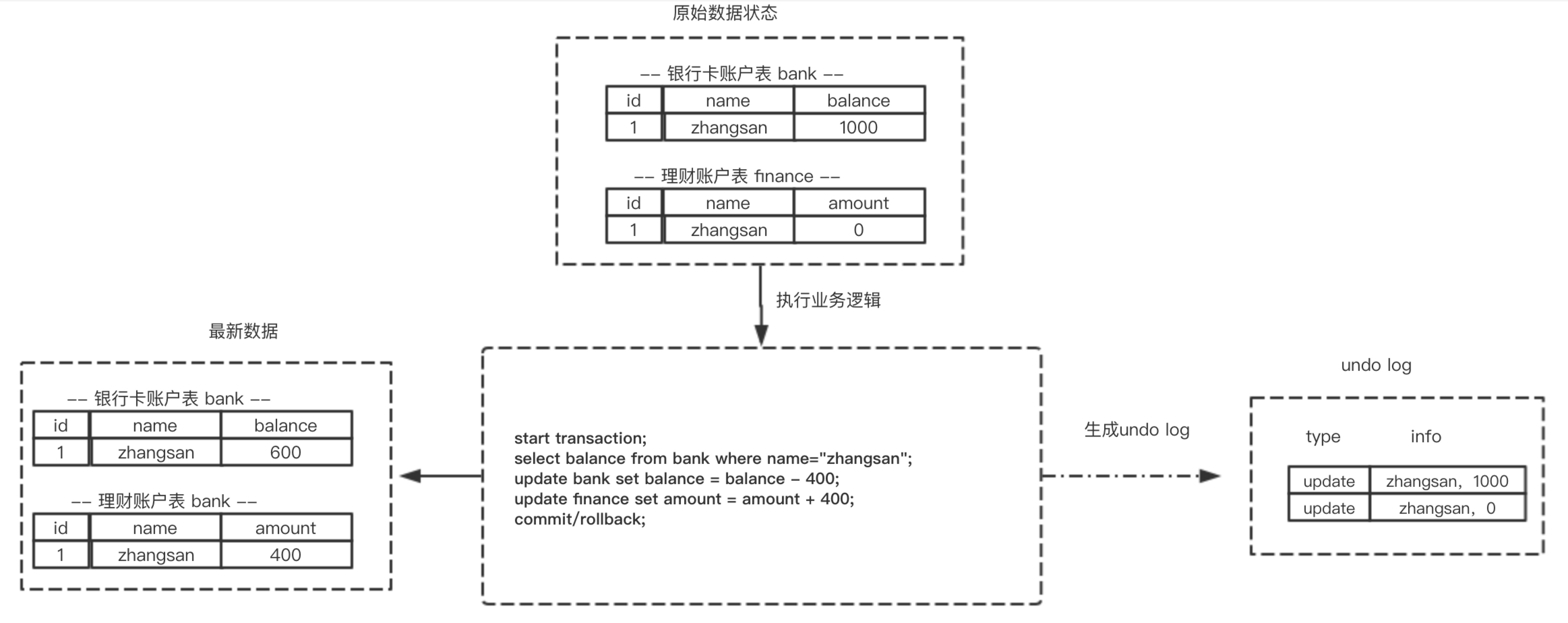

每条数据变更(insert/update/delete)操作都会伴随一条undo log的生成,并回滚日志必须先于数据持久化到磁盘上。
所以为的回滚就是根据回滚日志做逆向操作,比如delete的逆向操作为insert,insert的逆向操作为delete,update的逆向为update等。
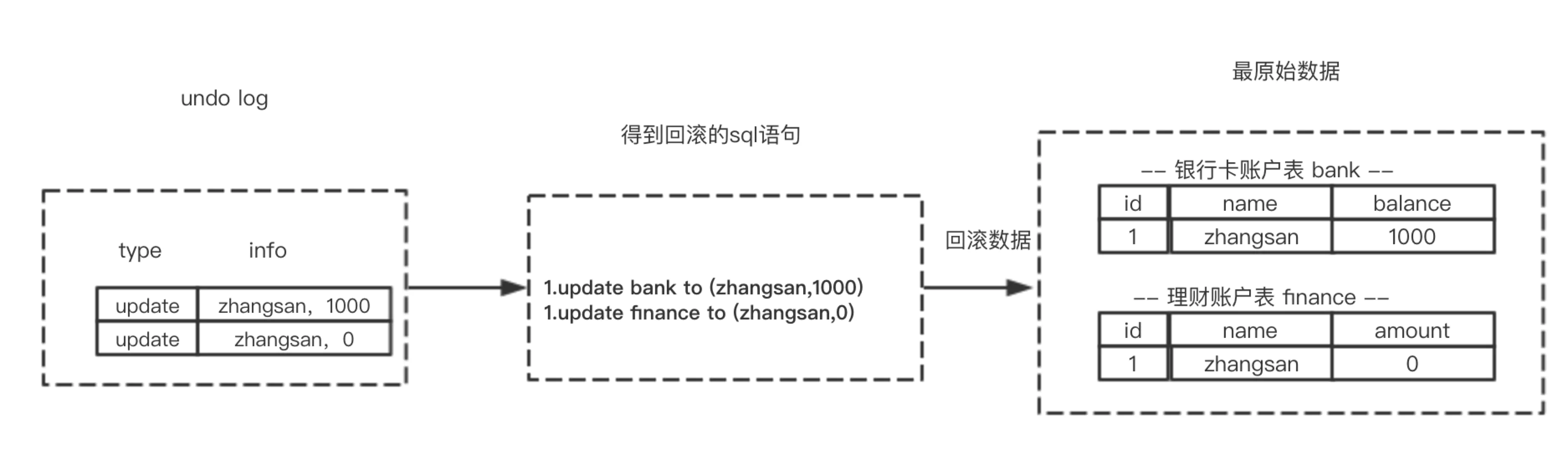
持久性(Durability)
事务一旦提交,其所作做的修改会永久保存到数据库中,此时即使系统崩溃修改的数据也不会丢失。
实现原理: Redo log(WAL write ahead log)
先了解一下MySQL的数据存储机制,MySQL的表数据是存放在磁盘上的,因此想要存取的时候都要经历磁盘IO,然而即使是使用SSD磁盘IO也是非常消耗性能的。
为此,为了提升性能InnoDB提供了缓冲池(Buffer Pool),Buffer Pool中包含了磁盘数据页的映射,可以当做缓存来使用:
读数据:会首先从缓冲池中读取,如果缓冲池中没有,则从磁盘读取在放入缓冲池;
写数据:会首先写入缓冲池,缓冲池中的数据会定期同步到磁盘中(这一过程称为刷脏);
但是缓冲池机制,在系统宕机断电的时候可能会丢数据。因为我们的数据已经提交了,但此时是在缓冲池里头,还没来得及在磁盘持久化,所以我们急需一种机制需要存一下已提交事务的数据,为恢复数据使用
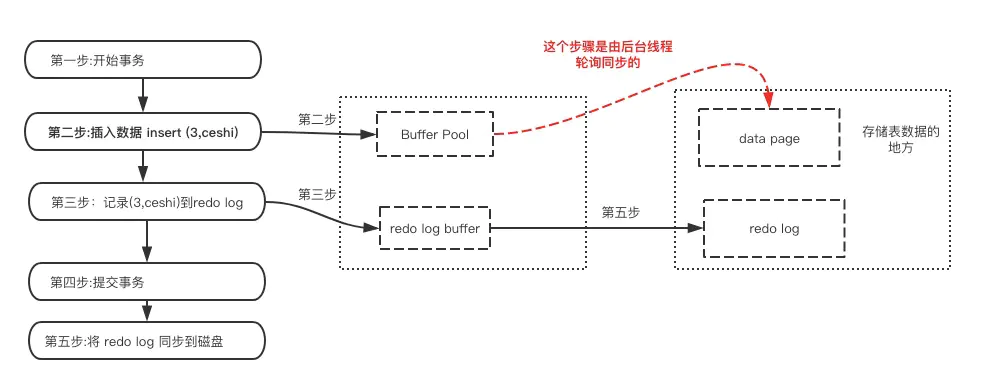
既然redo log也需要存储,也涉及磁盘IO为啥还用它?
- 刷脏是随机IO, 因为每次修改的数据位置随机,但写redolog是追加操作,属于顺序IO
- 刷脏是以数据页为单位的,MySQL默认页大小是16KB, 一个page上一个小修改都要整页写入,而redo log 中只包含真正需要写入的部分,无效IO大大减少
redo log与binlog
我们知道,在MySQL中还存在binlog(二进制日志)也可以记录写操作并用于数据的恢复,但二者是有着根本的不同的:
(1)作用不同:redo log是用于crash recovery的,保证MySQL宕机也不会影响持久性;binlog是用于point-in-time recovery的,保证服务器可以基于时间点恢复数据,此外binlog还用于主从复制。
(2)层次不同:redo log是InnoDB存储引擎实现的,而binlog是MySQL的服务器层(可以参考文章前面对MySQL逻辑架构的介绍)实现的,同时支持InnoDB和其他存储引擎。
(3)内容不同:redo log是物理日志,内容基于磁盘的Page;binlog的内容是二进制的,根据binlog_format参数的不同,可能基于sql语句、基于数据本身或者二者的混合。
(4)写入时机不同:binlog在事务提交时写入;redo log的写入时机相对多元,binlog日志先于redo log被近路
前面曾提到:当事务提交时会调用fsync对redo log进行刷盘;这是默认情况下的策略,修改innodb_flush_log_at_trx_commit参数可以改变该策略,但事务的持久性将无法保证。
除了事务提交时,还有其他刷盘时机:如master thread每秒刷盘一次redo log等,这样的好处是不一定要等到commit时刷盘,commit速度大大加快。
隔离性(Isolation)
与原子性、持久性侧重于研究事务本身不同,隔离性研究的是不同事务之间的相互影响。隔离性是指,事务内部的操作与其他事务是隔离的,并发执行的各个事务之间不能互相干扰。严格的隔离性,对应了事务隔离级别中的Serializable (可串行化),但实际应用中出于性能方面的考虑很少会使用可串行化。
实现原理
隔离性追求的是并发情形下事务之间互不干扰。简单起见,我们仅考虑最简单的读操作和写操作(暂时不考虑带锁读等特殊操作),那么隔离性的探讨,主要可以分为两个方面:
(一个事务)写操作对(另一个事务)写操作的影响:锁机制保证隔离性
(一个事务)写操作对(另一个事务)读操作的影响:MVCC保证隔离性
脏读、不可重复读和幻读
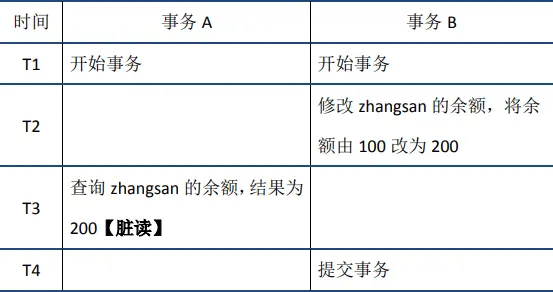
- 脏读:当前事务(A)中可以读到其他事务(B)未提交的数据(脏数据),这种现象是脏读。举例如下(以账户余额表为例)
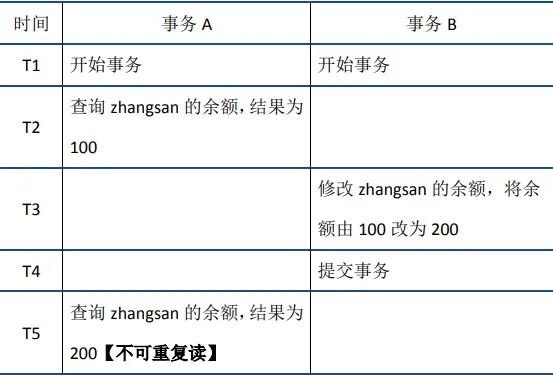
- 不可重复读:在事务A中先后两次读取同一个数据,两次读取的结果不一样,这种现象称为不可重复读。脏读与不可重复读的区别在于:前者读到的是其他事务未提交的数据,后者读到的是其他事务已提交的数据。举例如下:
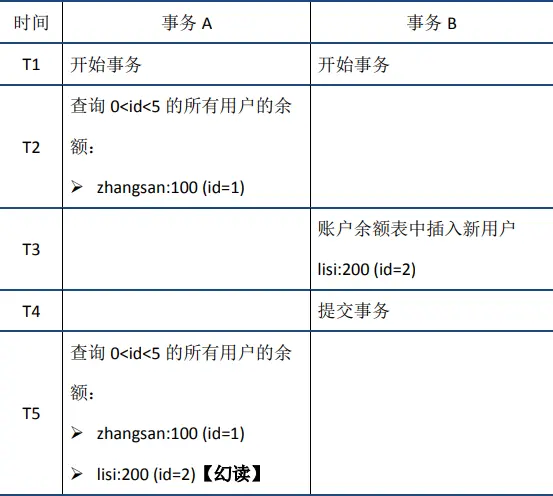
- 幻读:在事务A中按照某个条件先后两次查询数据库,两次查询结果的条数不同,这种现象称为幻读。不可重复读与幻读的区别可以通俗的理解为:前者是数据变了,后者是数据的行数变了。举例如下
事务的隔离级别
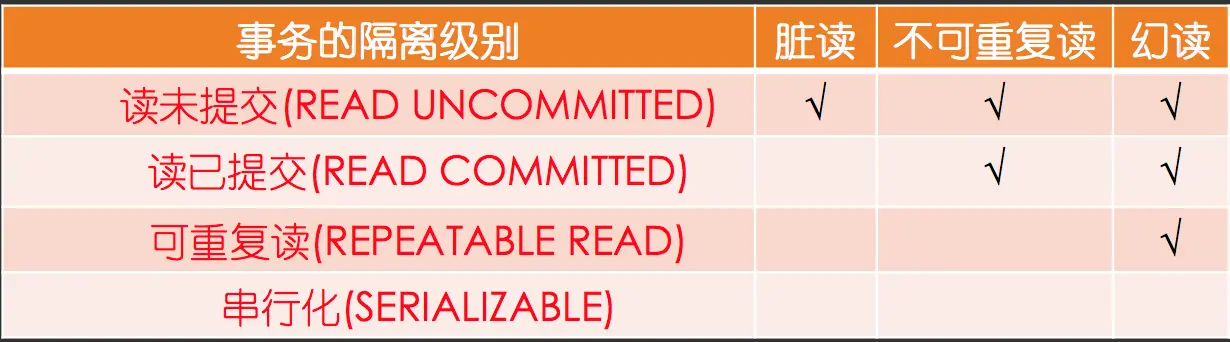
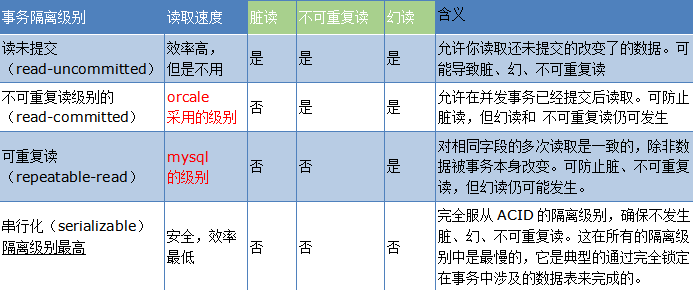
在实际应用中,读未提交在并发时会导致很多问题,而性能相对于其他隔离级别提高却很有限,因此使用较少。可串行化强制事务串行,并发效率很低,只有当对数据一致性要求极高且可以接受没有并发时使用,因此使用也较少。因此在大多数数据库系统中,默认的隔离级别是读已提交(如Oracle)或可重复读(后文简称RR)
可以通过如下两个命令分别查看隔离级别:
select @@tx_isolation;
+-----------------+
| @@tx_isolation |
+-----------------+
| REPEATABLE-READ |
+-----------------+
1 row in set (0.00 sec)
MVCC
RR解决脏读,不可重复读,幻读等问题,使用的是MVCC:MVCC全称Multi-Version Concurrency Control,即多版本的并发控制协议。下面的例子很好的体现了MVCC的特点:在同一时刻,不同的事务读取到的数据可能是不同的(即多版本)——在T5时刻,事务A和事务C可以读取到不同版本的数据。
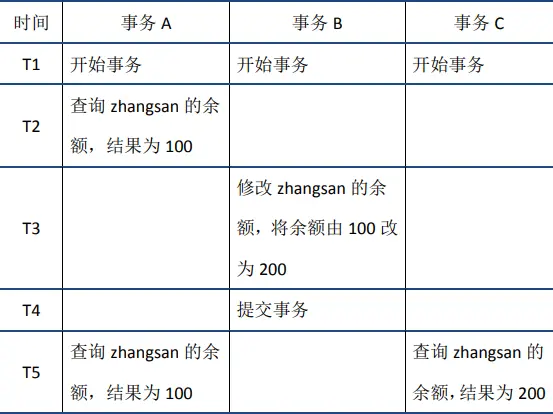
MVCC最大的优点是读不加锁,因此读写不冲突,并发性能好。InnoDB实现MVCC,多个版本的数据可以共存,主要是依靠数据的隐藏列(也可以称之为标记位)和undo log。其中数据的隐藏列包括了该行数据的版本号、删除时间、指向undo log的指针等等;当读取数据时,MySQL可以通过隐藏列判断是否需要回滚并找到回滚需要的undo log,从而实现MVCC;隐藏列的详细格式不再展开。MySQL 的MVCC机制
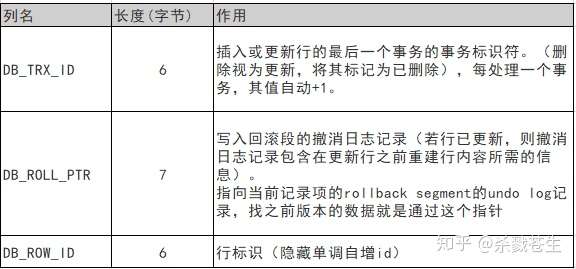
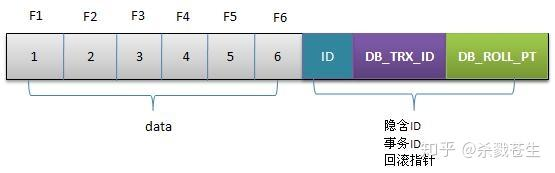
下面结合前文提到的几个问题分别说明
-
脏读
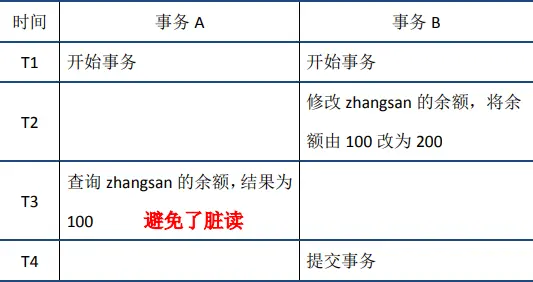
当事务A在T3时间节点读取zhangsan的余额时,会发现数据已被其他事务修改,且状态为未提交。此时事务A读取最新数据后,根据数据的undo log执行回滚操作,得到事务B修改前的数据,从而避免了脏读。
-
不可重复读
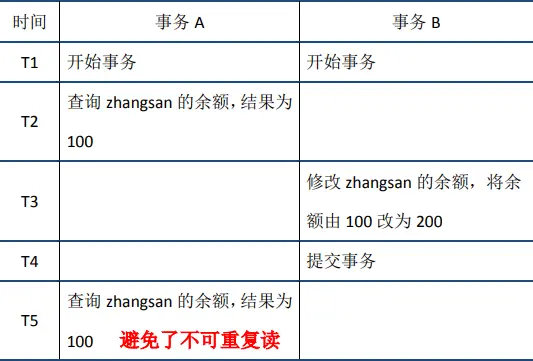
当事务A在T2节点第一次读取数据时,会记录该数据的版本号(数据的版本号是以row为单位记录的),假设版本号为1;当事务B提交时,该行记录的版本号增加,假设版本号为2;当事务A在T5再一次读取数据时,发现数据的版本号(2)大于第一次读取时记录的版本号(1),因此会根据undo log执行回滚操作,得到版本号为1时的数据,从而实现了可重复读。
-
幻读
InnoDB实现的RR通过next-key lock机制避免了幻读现象。
next-key lock是行锁的一种,实现相当于record lock(记录锁) + gap lock(间隙锁);其特点是不仅会锁住记录本身(record lock的功能),还会锁定一个范围(gap lock的功能)。当然,这里我们讨论的是不加锁读:此时的next-key lock并不是真的加锁,只是为读取的数据增加了标记(标记内容包括数据的版本号等);准确起见姑且称之为类next-key lock机制。还是以前面的例子来说明:
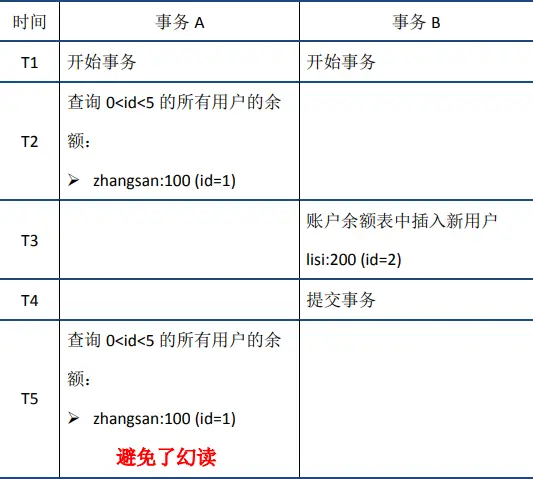
当事务A在T2节点第一次读取0<id<5数据时,标记的不只是id=1的数据,而是将范围(0,5)进行了标记,这样当T5时刻再次读取0<id<5数据时,便可以发现id=2的数据比之前标记的版本号更高,此时再结合undo log执行回滚操作,避免了幻读。
小结
概括来说,InnoDB实现的RR,通过锁机制、数据的隐藏列、undo log和类next-key lock,实现了一定程度的隔离性,可以满足大多数场景的需要。
一致性
一致性是指事务执行结束后,数据库的完整性约束没有被破坏,事务执行的前后都是合法的数据状态。数据库的完整性约束包括但不限于:实体完整性(如行的主键存在且唯一)、列完整性(如字段的类型、大小、长度要符合要求)、外键约束、用户自定义完整性(如转账前后,两个账户余额的和应该不变)。
实现原理:
可以说,一致性是事务追求的最终目标:前面提到的原子性、持久性和隔离性,都是为了保证数据库状态的一致性。此外,除了数据库层面的保障,一致性的实现也需要应用层面进行保障。
实现一致性的措施包括:
- 保证原子性,持久性,隔离性,如果这些特征无法保证,事务的一致性也无法保证
- 数据库本身提供保障,例如不允许你向整形列插入字符串数字,字符串0长度不能超过列的限制等
- 应用层面进行保障,例如如果转账操作只扣除转账者的余额,而没有增加接收者的余额,无论数据库实现的多么完美,也无法保证状态的一致
详细分析MySQL事务日志(redo log和undo log)
账户管理
-
账户创建和授权
查看user表结构
desc user;
- Host表示允许访问的主机
- User表示用户名
- authentication_string表示密码,为加密后的值
查看所有用户
select host, user, authentication_string from user;
创建账户&授权
常用权限主要包括:create、alter、drop、insert、update、delete、select,如果分配所有权限,可以使用
all privilegesgrant 权限列表 on 数据库 to '用户名'@'允许访问的主机' identified by '密码';
案例:创建一个
Alex的账号,密码为123456,只能通过本地访问, 并且只能对jing_dong数据库中的所有表进行读操作grant select on jind_dong.* to 'Alex'@'localhost' indentify by 123456;
说明:
- python可以操作该数据的所有表,方式为:
jind_dong.* - 访问主机通常使用百分号
%表示此账户可以使用任何ip访问
查看用户有哪些权限
show grants for Alex@localhost;
-
账户操作
注意修改完成后需要刷新权限:
flush privileges修改权限
grant 权限名称 on 数据库 to 账户@主机 with grant option;
eg:
grant select, insert on jing_dong.* to Alex@localhost with grant option;
flush privileges;
修改密码
方式1
update user set authentication_string=password('新密码') where user = '用户名';
flush privileges;
方式2
set password for username@host=password('new password');
删除账户
方式1
drop user 'username'@'host';
方式2-删除mysql数据库的user表中数据
delete from user where user='用户名';
-----操作结束之后需要刷新权限
flush privileges;
用show profile进行sql分析
show profile命令可以分析当前会话中语句执行的资源消耗情况。用于查找SQL耗时瓶颈 。默认处于关闭状态,并保存最近15次的运行结果
查看是否开始 :
show variables like 'profiling';
MariaDB [test_sql]> show variables like 'profiling';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| profiling | ON |
+---------------+-------+
1 row in set (0.001 sec)
开启功能:
set profiling = on;
执行命令查询:
show profiles;
MariaDB [test_sql]> show profiles;
+----------+------------+------------------------------------------------+
| Query_ID | Duration | Query |
+----------+------------+------------------------------------------------+
| 1 | 0.00058802 | select distinct name from stu |
| 2 | 0.00049052 | select max(age) from stu where id in (1,2,3,6) |
| 3 | 0.00038703 | select * from stu where id>2 |
+----------+------------+------------------------------------------------+
3 rows in set (0.000 sec)
查看更详细的信息:
show profile cpu, block io for query 3;
MariaDB [test_sql]> show profile cpu, block io for query 3;
+------------------------+----------+----------+------------+--------------+---------------+
| Status | Duration | CPU_user | CPU_system | Block_ops_in | Block_ops_out |
+------------------------+----------+----------+------------+--------------+---------------+
| Starting | 0.000067 | 0.000000 | 0.000000 | 0 | 0 |
| Checking permissions | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| Opening tables | 0.000017 | 0.000000 | 0.000000 | 0 | 0 |
| After opening tables | 0.000005 | 0.000000 | 0.000000 | 0 | 0 |
| System lock | 0.000004 | 0.000000 | 0.000000 | 0 | 0 |
| Table lock | 0.000007 | 0.000000 | 0.000000 | 0 | 0 |
| Init | 0.000038 | 0.000000 | 0.000000 | 0 | 0 |
| Optimizing | 0.000014 | 0.000000 | 0.000000 | 0 | 0 |
| Statistics | 0.000054 | 0.000000 | 0.000000 | 0 | 0 |
| Preparing | 0.000019 | 0.000000 | 0.000000 | 0 | 0 |
| Executing | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Sending data | 0.000049 | 0.000000 | 0.000000 | 0 | 0 |
| End of update loop | 0.000005 | 0.000000 | 0.000000 | 0 | 0 |
| Query end | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Commit | 0.000004 | 0.000000 | 0.000000 | 0 | 0 |
| Closing tables | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Unlocking tables | 0.000002 | 0.000000 | 0.000000 | 0 | 0 |
| Closing tables | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| Starting cleanup | 0.000003 | 0.000000 | 0.000000 | 0 | 0 |
| Freeing items | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
| Updating status | 0.000065 | 0.000000 | 0.000000 | 0 | 0 |
| Reset for next command | 0.000006 | 0.000000 | 0.000000 | 0 | 0 |
+------------------------+----------+----------+------------+--------------+---------------+
22 rows in set (0.054 sec)
Show profile后面的一些参数:
-
All:显示所有的开销信息
-
Block io:显示块IO相关开销
-
Context switches: 上下文切换相关开销
-
Cpu:显示cpu相关开销
-
Memory:显示内存相关开销
-
Source:显示和source_function,source_file,source_line相关的开销信息
MySQL慢日志查询
MySQL的慢日志查询是MySQL提供的一种日志记录,它用了记录在MySql中响应时间超过阈值的语句,具体运行时间超过long_query_time值的SQL,则会被记录到慢日志中。long_query_time的默认时间为10s,意思是运行10s以上的语句。
默认情况下,MySQL数据库没有开启慢查询日志,需要我们手动来设置这个参数。当然,如果不是调优需要,一般不建议启动该参数,因为慢日志会或多或少带来一定的性能影响。
#查看是否开启
show variables like '%slow_query_log%';
#开启
set global slow_query_log = 1;
使用set global slow_query_log=1开启了慢查询日志只对当前数据库生效,如果MySQL重启后则会失效。如果要永久生效,就必须修改配置文件my.cnf。
MySql提供了日志分析工具mysqldumpslow, 将SQL日志导出分析。
#得到返回记录集最多的10个SQL
Mysqldumpslow –s r –t 10 D:\Program Files\mysql\data\DESKTOP-VN2D5OU-slow.log
#得到访问次数最多的10个SQL
Mysqldumpslow –s c –t 10 D:\Program Files\mysql\data\DESKTOP-VN2D5OU-slow.log
#得到按照时间排序的前10条里面含有左连接的查询
Mysqldumpslow –s t –t 10 –g “left join” D:\Program Files\mysql\data\DESKTOP-VN2D5OU-slow.log
#另外建议在使用这些命令时结合|和more使用,否则可能出现爆破情况
Mysqldumpslow –s r –t 10 D:\Program Files\mysql\data\DESKTOP-VN2D5OU-slow.log|more
参数含义
- s: 表示按照何种方式排序
- c:访问次数
- l:锁定时间
- r:返回记录
- t:查询时间
- al:平均锁定时间
- t:返回前面多少条的数据
- g:后面搭配一个正则表达式
用Explain关键字查看是否使用索引查询
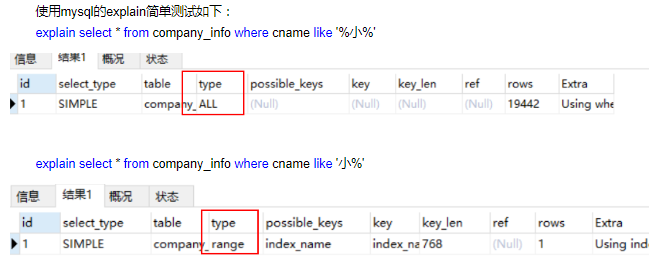
mysql查看是否使用索引,简单的看type类型就可以。如果它是all,那说明这条查询语句遍历了所有的行,并没有使用到索引。
以下转自:
mysql explain执行计划详解

1)、id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询。
2)、select_type列常见的有:
A:simple:表示不需要union操作或者不包含子查询的简单select查询。有连接查询时,外层的查询为simple,且只有一个
B:primary:一个需要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且只有一个
C:union:union连接的两个select查询,第一个查询是dervied派生表,除了第一个表外,第二个以后的表select_type都是union
D:dependent union:与union一样,出现在union 或union all语句中,但是这个查询要受到外部查询的影响
E:union result:包含union的结果集,在union和union all语句中,因为它不需要参与查询,所以id字段为null
F:subquery:除了from字句中包含的子查询外,其他地方出现的子查询都可能是subquery
G:dependent subquery:与dependent union类似,表示这个subquery的查询要受到外部表查询的影响
H:derived:from字句中出现的子查询,也叫做派生表,其他数据库中可能叫做内联视图或嵌套select
3)、table
显示的查询表名,如果查询使用了别名,那么这里显示的是别名,如果不涉及对数据表的操作,那么这显示为null,如果显示为尖括号括起来的
4)、type
依次从好到差:system,const,eq_ref,ref,fulltext,ref_or_null,unique_subquery,index_subquery,range,index_merge,index,ALL,除了all之外,其他的type都可以使用到索引,除了index_merge之外,其他的type只可以用到一个索引
A:system:表中只有一行数据或者是空表,且只能用于myisam和memory表。如果是Innodb引擎表,type列在这个情况通常都是all或者index
B:const:使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其他数据库也叫做唯一索引扫描
C:eq_ref:出现在要连接过个表的查询计划中,驱动表只返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null,唯一索引和主键是多列时,只有所有的列都用作比较时才会出现eq_ref
D:ref:不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,只要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
E:fulltext:全文索引检索,要注意,全文索引的优先级很高,若全文索引和普通索引同时存在时,mysql不管代价,优先选择使用全文索引
F:ref_or_null:与ref方法类似,只是增加了null值的比较。实际用的不多。
G:unique_subquery:用于where中的in形式子查询,子查询返回不重复值唯一值
H:index_subquery:用于in形式子查询使用到了辅助索引或者in常数列表,子查询可能返回重复值,可以使用索引将子查询去重。
I:range:索引范围扫描,常见于使用>,<,is null,between ,in ,like等运算符的查询中。
J:index_merge:表示查询使用了两个以上的索引,最后取交集或者并集,常见and ,or的条件使用了不同的索引,官方排序这个在ref_or_null之后,但是实际上由于要读取所个索引,性能可能大部分时间都不如range
K:index:索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就可以处理不需要读取数据文件的查询、可以使用索引排序或者分组的查询。
L:all:这个就是全表扫描数据文件,然后再在server层进行过滤返回符合要求的记录。
5)、possible_keys
查询可能使用到的索引都会在这里列出来
6)、key
查询真正使用到的索引,select_type为index_merge时,这里可能出现两个以上的索引,其他的select_type这里只会出现一个。
7)、key_len
用于处理查询的索引长度,如果是单列索引,那就整个索引长度算进去,如果是多列索引,那么查询不一定都能使用到所有的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列,这里不会计算进去。留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到所有的列了。要注意,mysql的ICP特性使用到的索引不会计入其中。另外,key_len只计算where条件用到的索引长度,而排序和分组就算用到了索引,也不会计算到key_len中。
8)、ref
如果是使用的常数等值查询,这里会显示const,如果是连接查询,被驱动表的执行计划这里会显示驱动表的关联字段,如果是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9)、rows
这里是执行计划中估算的扫描行数,不是精确值
10)、extra
这个列可以显示的信息非常多,有几十种,常用的有
A:distinct:在select部分使用了distinc关键字
B:no tables used:不带from字句的查询或者From dual查询
C:使用not in()形式子查询或not exists运算符的连接查询,这种叫做反连接。即,一般连接查询是先查询内表,再查询外表,反连接就是先查询外表,再查询内表。
D:using filesort:排序时无法使用到索引时,就会出现这个。常见于order by和group by语句中
E:using index:查询时不需要回表查询,直接通过索引就可以获取查询的数据。
F:using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本优化关联查询的BNL,BKA特性。主要是减少内表的循环数量以及比较顺序地扫描查询。
G:using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个对应的类似,只是他们是出现在用and和or查询信息量大时,先查询主键,然后进行排序合并后,才能读取记录并返回。
H:using temporary:表示使用了临时表存储中间结果。临时表可以是内存临时表和磁盘临时表,执行计划中看不出来,需要查看status变量,used_tmp_table,used_tmp_disk_table才能看出来。
I:using where:表示存储引擎返回的记录并不是所有的都满足查询条件,需要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎只能根据限制条件扫描数据并返回,然后server层根据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,可以把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据,直接不读取,这样就大大减少了存储引擎扫描的记录数量。extra列显示using index condition
J:firstmatch(tb_name):5.6.x开始引入的优化子查询的新特性之一,常见于where字句含有in()类型的子查询。如果内表的数据量比较大,就可能出现这个
K:loosescan(m..n):5.6.x之后引入的优化子查询的新特性之一,在in()类型的子查询中,子查询返回的可能有重复记录时,就可能出现这个
除了这些之外,还有很多查询数据字典库,执行计划过程中就发现不可能存在结果的一些提示信息
11)、filtered
使用explain extended时会出现这个列,5.7之后的版本默认就有这个字段,不需要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例,注意是百分比,不是具体记录数。
Like是否使用索引?
- like %keyword 索引失效,使用全表扫描。但可以通过翻转函数+like前模糊查询+建立翻转函数索引=走翻转函数索引,不走全表扫描。
- like keyword% 索引有效。
- like %keyword% 索引失效,也无法使用反向索引。
数据内核引擎比较及其底层实现

B树(B-Tree)
一种对读写操作进行优化的自平衡的二叉查找树,能够保持数据有序,拥有多余两个子树。B树是多路平衡查找树,2阶B树才是平衡二叉树
应用: 数据库存储
M阶的Btree的几个重要特性:
- 节点最多含有m棵字树(指针), m-1个关键字(存的数据,空间)(m > 2)
- 除根节点和叶子节点外,其他每个节点至少有ceil(m / 2)个子节点,(ceil为上取整)
- 若根节点不是叶子节点,则至少有两棵子树
M阶: 这个由磁盘的页大小决定,页内存是4KB, 好处是一次性取数据就可以取出这个节点即这个页数据,不会造成IO读取的浪费。

B+Tree
- 每个节点最多有m个子节点
- 除根节点外,每个节点至少有m/2个子节点,注意如果结果除不尽,就取上蒸,如 5/2=3
- 根节点要么是空,要么是独根,否则至少有2个子节点
- 有k个子节点的节点必有k个关键字
- 叶节点的高度一致
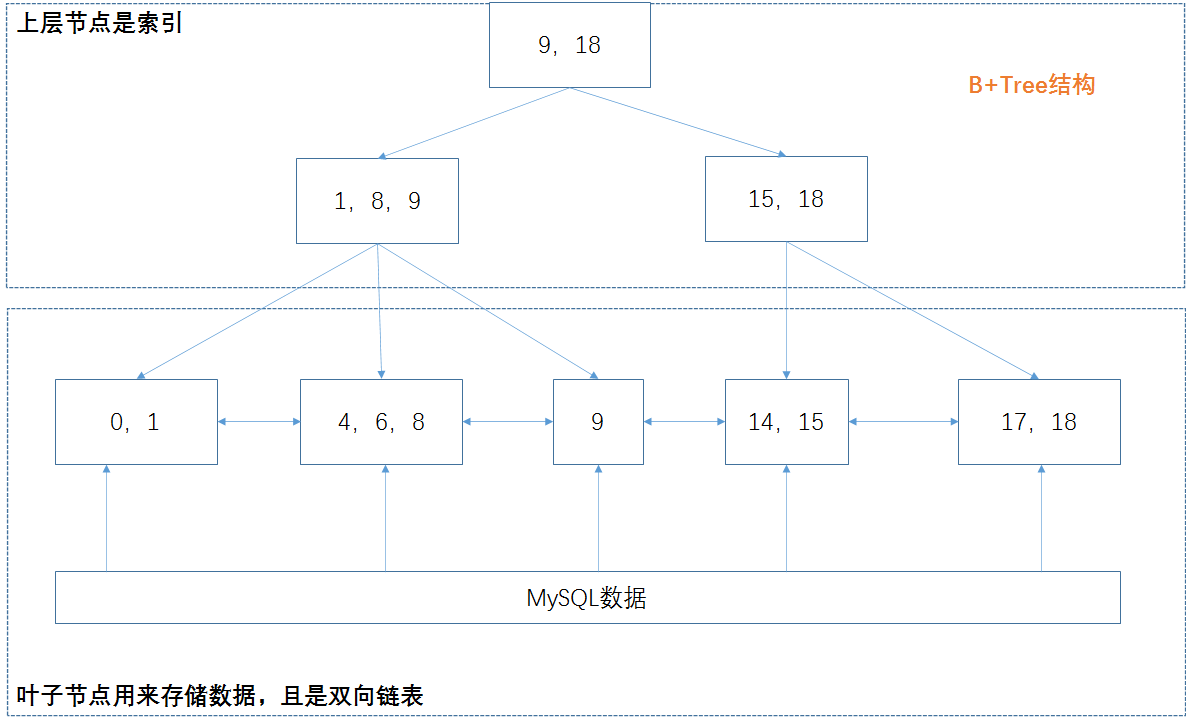

适合大数据的磁盘索引,经典的MySQL,所有的数据都存在叶子节点,其他上层节点都是索引,增加了系统的稳定性以及遍历查找效率。叶子节点之间是双向指针,这一点就有利于范围查找。
MyISAM存储引擎的数据结构(非聚集)
索引文件和数据文件是分离的,非聚集(非聚族)
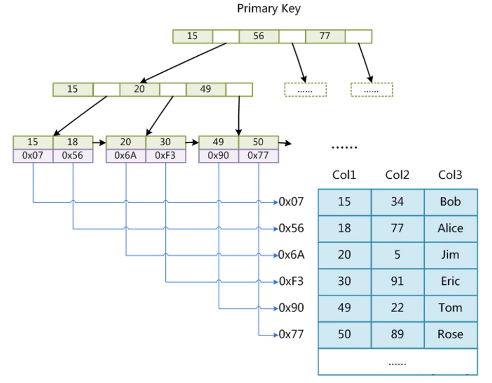
.MYD 存储数据的文件
.MYI 存储索引的文件
.FRM 表结构文件,管理索引和数据的框架
InnoDB索引的实现(聚集)
- 表数据本身就是按B+Tree组织的一个索引结构文件
- 聚集索引-叶子节点包含了完整的数据记录,索引跟数据合并,MySQL默认节点大小为16KB,所以说高度为3的B+树就能够存储千万级别的数据。
- 为什么InnoDB表必须有主键,并且推荐使用整形的自增主键?
- 整形存储占用比较少,且比较容易,如果是uuid字符串还需要进行转换且占用空间大
- 使用自增是为了避免二叉树的频繁自平衡分裂,自增主键,只需要每次都忘后面增加即可,不会造成大范围的性能开销
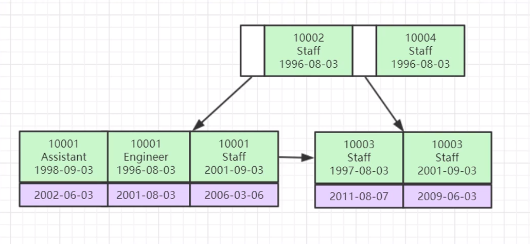
- 为什么非主键索引结构叶子节点存储的是主键值?(一直性)
-
减少数据冗余和存储空间:
如果辅助索引的叶子节点存储的是实际的行数据,那么每创建一个辅助索引,都会重复存储整行数据,造成大量的数据冗余和存储浪费。
通过存储主键值,InnoDB只需维护一个较小的主键索引,这样即使有多个辅助索引也不会显著增加存储开销。 -
提高查询效率:
在使用辅助索引进行查询时,InnoDB首先通过辅助索引找到对应的主键值,然后通过主键值快速定位到聚簇索引中的实际行数据。
这种方式叫做“回表”操作(即通过辅助索引找到主键值,再通过主键值访问聚簇索引中的行数据),尽管增加了一次访问,但仍然比直接存储行数据的冗余方式更高效和灵活。 -
保持索引的一致性和易维护性:
当行数据发生变化(如插入、删除或更新)时,只需更新聚簇索引中的数据和相关辅助索引中的主键值,减少了数据一致性和维护的复杂度。
-
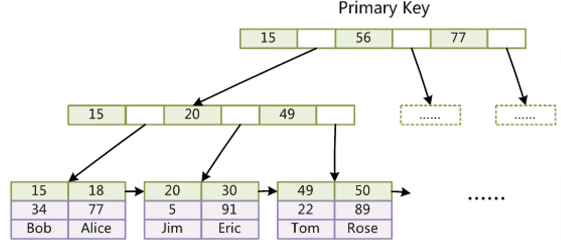
联合索引的底层存储结构
参考:MySQL底层索引算法
参考:MYSQL-B+TREE索引原理-详细解释了SQL语句的执行过程
数据库操作常见报错
ERROR 1064 (42000): You have an error in your SQL syntax;
ERROR 1452 添加外键失败,错误原因,可能在表1中存在不在表2的值,需要先删除
其他
1️⃣ ubuntu mysql 终端无法输入中文解决方法
export LANG=en_US.UTF-8 # 修改本地用户的字符集即可
2️⃣ 数据库默认字符集为utf8 只能存储3个字节的数据,标准的emoji表情是4个字节,所以要支持emoi表情的话就要修改字符集
utf8 --> utf8mb4 # 前提是mysql版本 > 5.5.3
mb4: most byte 4,专门兼容四个字节的,utf8mb4是向下兼容utf8的,即使修改了字符集也不会影响线上数据。
好文推荐
-
- 本文深入介绍Mysql Binlog的应用场景,以及如何与MQ、elasticsearch、redis等组件的保持数据最终一致。最后通过案例深入分析binlog中几乎所有event是如何产生的,作用是什么。
-
- 全局事务 ID (Global Transaction ID, GTID) 是用来强化数据库在主备复制场景下,可以有效保证主备一致性、提高故障恢复、容错能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号