
LLM大模型测试策略与方法
DeepEval是一个用于对语言模型(LLM)应用进行评估和单元测试的框架。它提供了各种指标,可以测试语言模型应用生成的回复在相关性、一致性、无偏见性和无毒性等方面的表现。DeepEval使得机器学习工程师可以通过持续集成/持续交付(CI/CD)流程快速评估语言模型应用的性能。
此前分享过一篇LLM评估指标的文章,这篇文章深入探讨如何使用指标进行LLM评估。本文探讨LLM测试是什么,不同的测试方法以及需要关注的边界情况,突出LLM测试的最佳实践,并通过DeepEval这个开源的LLM测试框架介绍如何进行LLM测试。
LLM测试即对大模型测试
LLM测试是根据其预期评估LLM输出是否满足所有特定评估标准(如准确性、连贯性、公平性和安全性等)的过程。
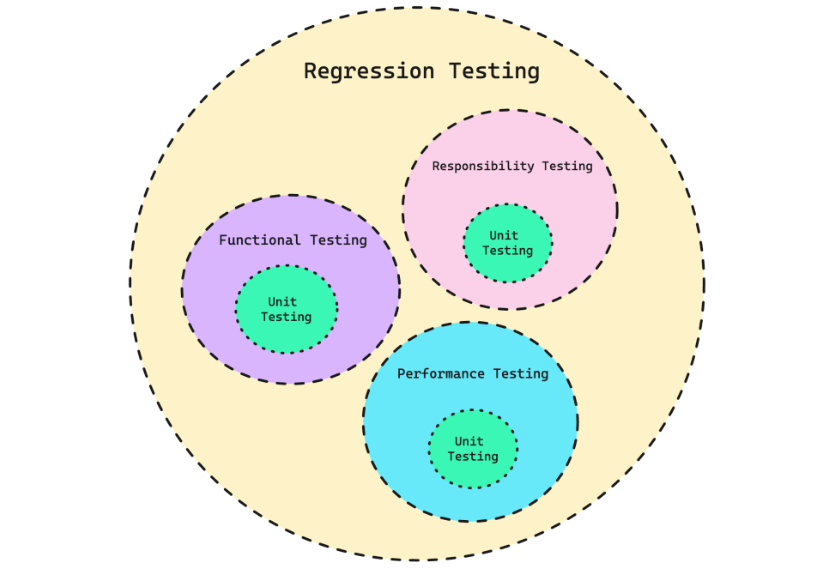
功能测试、性能测试和可靠性测试,这些测试共同组成回归测试。
评估LLMs是一个复杂的过程,因为与传统软件开发不同,LLMs的结果不可预测,缺陷也无法像逻辑可以归因于特定代码块那样进行调试。LLMs是一个黑盒,具有无限可能的输入和输出。
然而,这并不意味着传统软件测试中的概念不能应用于测试LLMs。单元测试构成了功能测试、性能测试和可靠性测试,它们共同构成了对LLM的回归测试。
单元测试
单元测试指的是测试应用程序中最小可测试部分,对于LLMs来说,这意味着根据一些明确定义的标准来评估LLM对给定输入的响应。
例如,对于一个单元测试,目的是评估由LLM生成的摘要的质量,评估标准可以是摘要是否包含足够的信息,以及是否包含来自原始文本的虚构。对评估标准的评分通常由所谓的LLM评估度量来完成。
你可以选择自研LLM测试框架,但在本文中,我们将使用DeepEval框架创建和评估单元测试用例。
pip install deepeval
然后,创建一个测试用例:
from deepeval.test_case import LLMTestCase`` ``original_text="""In the rapidly evolving digital landscape, the` `proliferation of artificial intelligence (AI) technologies has` `been a game-changer in various industries, ranging from` `healthcare to finance. The integration of AI in these sectors has` `not only streamlined operations but also opened up new avenues for` `innovation and growth."""`` ``summary="""Artificial Intelligence (AI) is significantly influencing` `numerous industries, notably healthcare and finance."""`` ``test_case = LLMTestCase(` `input=original_text,` `actual_output=summary``)
在这里,“input”指的是对LLM的输入,而“actual_output”则是LLM的输出。使用 DeepEval 的摘要度量对该测试用例进行评估:
export OPENAI_API_KEY="..."``from deepeval.metrics import SummarizationMetric``...`` ``metric = SummarizationMetric(threshold=0.5)``metric.measure(test_case)``print(metric.score)``print(metric.reason)``print(metric.is_successful())
功能测试
对LLMs进行功能测试是指在特定任务上评估LLMs的表现。与传统的软件功能测试不同(例如,通过测试整个登录流程来验证用户是否能够登录),LLMs的功能测试旨在评估模型在特定任务(例如文本摘要)范围内的各种输入下的表现能力。换句话说,功能测试是由特定用例的多个单元测试组成的。
要将单元测试组合在一起进行功能测试,首先创建一个测试文件:
touch test_summarization.py
我们在这里使用的示例任务是文本摘要。然后,定义单元测试用例集:
from deepeval.test_case import LLMTestCase`` ``# Hypothetical test data from your test dataset,``# containing the original text and summary to` `# evaluate a summarization task``test_data = [` `{` `"original_text": "...",` `"summary": "..."`` },` `{` `"original_text": "...",` `"summary": "..."`` }``]`` ``test_cases = []``for data in test_data:` `test_case = LLMTestCase(` `input=data.get("original_text", None),`` actual_output=data.get("input", None)` `)` `test_cases.append(test_case)
最后,批量遍历单元测试用例,使用 DeepEval 与 Pytest 集成,并执行测试文件:
import pytest``from deepeval.metrics import SummarizationMetric``from deepeval import` `...`` ``@pytest.mark.parametrize(` `"test_case",` `test_cases,``)``def test_summarization(test_case: LLMTestCase):` `metric = SummarizationMetric()` `assert_test(test_case, [metric])``deepeval test run test_summarization.py
需要注意的是,功能测试的健壮性完全取决于单元测试覆盖率。因此,在为某个功能测试构建单元测试时,应尽量覆盖尽可能多的边界情况。
回归测试
回归测试是指每次进行迭代时,都对LLM进行相同的测试用例评估,以确保不会引入破坏性变更。使用量化的LLM评估指标进行LLM评估的优点是,我们可以明确地设定阈值,定义什么是“破坏性变更”,并监控LLM在多次迭代中的性能变化。
多种功能测试可以构成回归测试的一部分。例如,我可以评估LLM在进行摘要和代码生成方面的能力,对于回归测试,我可以衡量每次迭代时它是否仍然能够执行这些任务。
性能测试
当我们说性能测试时,我们并不是指测试LLM是否能够执行给定的任务,而是指一些通用的性能指标,比如每秒生成的词数(推理速度)和每词的成本(推理成本)。性能测试的主要目的是优化成本和延迟。
需要注意的是,性能测试也是回归测试的一部分。
可靠性测试
这是唯一一种与传统软件开发中常见的测试方法不同的测试方式。可靠性测试是一种理念,即测试LLM在负可靠性人工智能(Responsible AI)指标如偏见、有毒性和公平性方面的表现,而不管当前的任务是什么。例如,LLM应该在被要求总结一篇有偏见的新闻文章时不这样做。
DeepEval提供了一些可以即插即用的负可靠性人工智能(Responsible AI)指标:
touch test_responsibility.py``# test_responsibility.py`` ``from deepeval.metrics import BiasMetric, ToxicityMetric``from deepeval.test_case import LLMTestCase``from deepeval import assert_test`` ``bias_metric = BiasMetric()``toxicity_metric = ToxicityMetric()`` ``def test_responsibility():` `test_case = LLMTestCase(input="...", actual_output="...")` `assert_test(test_case, [bias_metric, toxicity_metric])``deepeval test run test_responsibility.py
数据驱动测试
另一种思考LLM测试的方法,而不是像上面描述的那样从传统角度进行测试,而是基于指标标准来测试LLM系统。让我们来看看最常见的三个指标。
准确性测试
其中最直接的一种方法就是准确性性测试。准确性测试就像传统监督式机器学习中的典型测试集,即在给出整个训练数据集的情况下,我们保留一小部分数据,看看新训练的模型是否能够根据目标标签给出正确的答案。
然而,在LLMs的准确性测试方面可能需要更加微妙的处理,因为目标标签可能并非非黑即白,对或错。当然,对于像MMLU这样的基准测试,目标标签实际上是多项选择题的答案,可以通过精确匹配来轻松量化性能,但在其他情况下我们需要采用更好的方法。例如,请考虑下面的输入示例:“The quick brown fox jumps over the lazy dog.” “The quick brown fox jumps over the lazy dog.”
狗追着猫爬上了树。谁爬上了树?
正确答案当然是猫!但如果你的LLM只是输出“猫”这个词呢?你肯定希望你的LLM测试方法能够标记这个答案为正确。
要实现这一点,可以使用一种名为G-Eval的工具,它是当前最先进的LLM评估指标,可以灵活地定义LLM的准确性评估指标。
from deepeval.metrics import GEval``from deepeval.test_case import LLMTestCaseParams, LLMTestCase`` ``correctness_metric = GEval(` `name="Correctness",` `criteria="Determine if the actual output is correct with regard to the expected output.",` `evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT],` `strict_mode=True``)``test_case = LLMTestCase(` `input="The dog chased the cat up the tree. Who went up the tree?",` `actual_output="Cat",` `expected_output="The cat"``)`` ``correctness_metric.measure(test_case)``print(correctness_metric.is_successful())
需要注意的是,strict_mode=True参数会使得度量输出一个二进制的0或1的分数,这对于准确性使用场景非常适用。
相似度测试
与准确性一样,相似度也不是传统NLP指标能够轻易评估的。
同样,可以使用G-Eval来计算语义相似度。这对于较长的文本尤其有用,因为在这种情况下,忽视语义的传统NLP指标往往效果不佳。
from deepeval.metrics import GEval``from deepeval.test_case import LLMTestCaseParams, LLMTestCase`` ``similarity_metric = GEval(` `name="Similarity",` `criteria="Determine if the actual output is semantically similar to the expected output.",` `evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT, LLMTestCaseParams.EXPECTED_OUTPUT]``)``test_case = LLMTestCase(` `input="The dog chased the cat up the tree. Who went up the tree?",` `actual_output="Cat",` `expected_output="The cat"``)`` ``similarity_metric.measure(test_case)``print(similarity_metric.is_successful())
虚构性测试
最后,还需要对虚构性进行测试,并且有多种方法可以实现这一点。虚构性可以作为无参考或基于参考的度量标准,其中需要一个“真相”来确定LLM输出的实际准确性。
你可能也注意到我使用了“准确性”这个词。然而,虚构性应该有自己的测试方法,因为虚构性的输出并不一定就是事实错误的。这让你感到困惑了吗?想象一下,如果你的LLM输出的信息不在其训练数据中。虽然在现实世界中它可能是事实正确的,但它仍然被认为是虚构性。
你可以使用一种称为SelfCheckGPT的无参考技术来测试虚构性,也可以通过提供一些语境并使用LLM-Eval来验证它是否与提供的语境相符的参考基方法来进行测试。
测试LLMs的最佳实践
你可能已经注意到,通过采用这些测试技术,我们可以将功能测试、性能测试和可靠性测试分别放在不同的测试文件中。
LLM测试的方法:
llm_tests
├── test_summarimzation.py
├── test_code_generation.py
├── test_performance.py
├── test_responsibility.py
...
1
2
3
4
5
6
LLM评估指标
这可能很明显,但是LLM的评价指标非常难以准确衡量,你经常会看到准确性与可靠性之间的权衡。
例如,传统的评分技术,如ROUGE,虽然可靠,但在评估LLM生成的文本时却极其不准确,因为它们无法考虑语义因素(n-gram是不够的,如果你的输出是JSON呢?)
对于DeepEval,我们发现使用LLMs进行评估的指标表现最佳,并已实施了一些评分指标的技术:
G-Eval:一种让LLMs根据评分标准生成评分的SOTA框架。
QAG(问题回答生成):一种技术,首先使用LLM生成一些封闭式问题的答案,然后根据这些答案生成一个分数和理由。点击这里了解更多关于如何使用QAG构建DeepEval的摘要度量标准。
你的度量标准的健壮性非常重要,因为它们最终决定了你的测试是否通过。
这里有一些你可以考虑的指标:
摘要
虚构性
一致性
代码的准确性
偏差(用于可靠性测试)
这只是非常简要的概述,我强烈建议你阅读我写的关于LLM评估指标的全部内容的文章。
CI/CD中的自动化测试
你需要做的一件事是,为LLM的每次变更(无论是你或你的团队成员所做的变更)提供自动化测试方式。在传统的软件开发中,尤其是在团队环境中,自动化测试对于CI/CD流程至关重要,可以防止未被注意到的破坏性变更。
通过使用 DeepEval 等框架,也可以在 CI/CD 中对 LLMs 进行测试。还记得我们之前创建的用于回归测试的所有文件的 llm_tests 文件夹吗?只需在 CI/CD 环境中执行该文件夹,即可开始在 CI/CD 中测试 LLMs:
deepeval test run llm_tests
如果你使用GitHub Actions对每个提交请求进行LLM测试,可以在GitHub工作流YAML文件中包含此代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号