



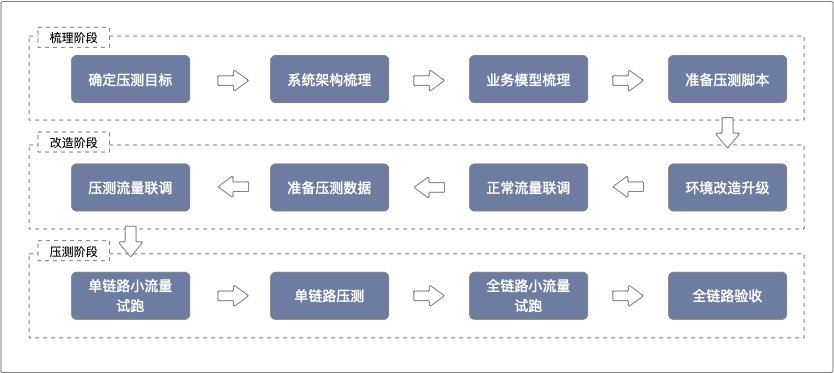
全链路压测的核心流程
全链路压测的核心流程和注意事项。
核心流程
全链路压测实施的核心流程如下:
步骤一:确定压测目标
压测目标主要包括压测范围、策略、目的,往往与业务、技术目标息息相关。例如:
- 压测范围:用户注册加登录,为大规模拉新做准备。
- 压测策略:高仿真生产环境压测,提前经历真实的业务高峰。
- 压测目的:探测业务吞吐极限,验证架构能力、探测性能瓶颈。
步骤二:梳理系统架构
梳理清楚端到端的请求链路、技术架构、分层结构、模块划分,以及RPC、消息、缓存、数据库等中间件的使用情况,分析潜在的瓶颈点,并针对性的增加监控指标、制定应急预案。
本文示例的系统架构图如下:
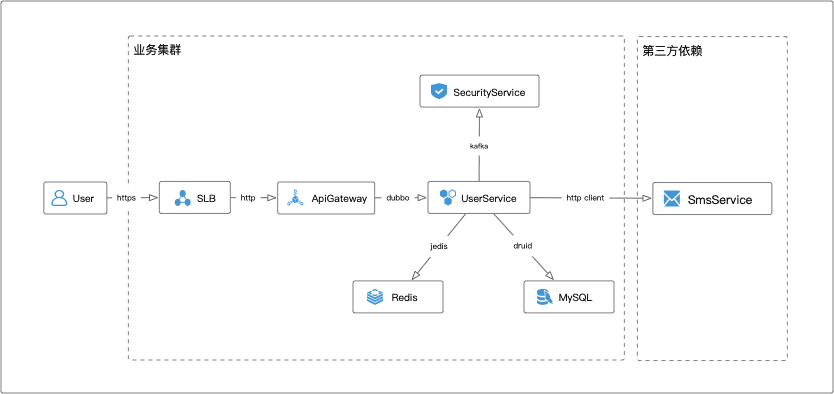
| 组件 | 分类 | 潜在的瓶颈、问题 |
|---|---|---|
| SLB | 负载均衡 |
|
| ApiGateway | API网关 |
|
| UserService | 微服务 |
|
| SecurityService | 微服务 |
|
| Redis | KV缓存 |
|
| MySQL | 数据库 |
|
| Kafka | 消息队列 |
|
| SmsService | 第三方依赖 | 第三方可能会拒绝参与压测 |
步骤三:梳理业务模型
压测的业务模型对压测结果的准确性至关重要。全链路压测的链路代表要压测的业务范围,同一条链路需要构造海量的参数集合代表不同用户的不同行为,系统的基础数据、系统预热情况等代表系统的状态。链路范围、链路的访问量级、链路的参数集合、基础数据、预热情况一起构成了压测的业务模型。
通常从以下维度梳理业务模型:
- 用户行为维度
- 确定业务接口的范围、接口的目标量级、接口的参数集合、压力曲线等。
- 根据业务特性确定压测数据的分布。例如用户的规模和地域、商品的种类和数量、是否制造热点商家和商品等。
- 系统状态维度
- 根据业务和场景的特性,确定各组件(例如缓存)的状态。例如拉新场景,缓存命中率非常低,而日常高峰场景,缓存命中率非常高,需要根据不同的场景来准备不同的缓存预热策略。
- 根据业务和场景的特性,确定基础数据的量级和范围。例如拉新场景,需要考虑老用户召回的情况,而日常高峰场景,一般准备与活跃用户相当量级的基础数据。
总之,业务模型与业务强相关,压测的业务模型对压测结果的准确性至关重要。
步骤四:准备压测脚本
根据业务场景编写压测脚本,也可以直接复用已有脚本,建议将脚本录入PTS场景,便于做场景调试。
步骤五:改造升级环境
在生产环境进行全链路压测,最核心的是线上写操作不能污染正常的业务数据。因此,需要针对存储做影子库表,即正常业务库表的镜像,让压测流量的数据流转到影子库表,正常业务流量流转到正常业务库表,在逻辑上隔离两种流量,使之互不影响。
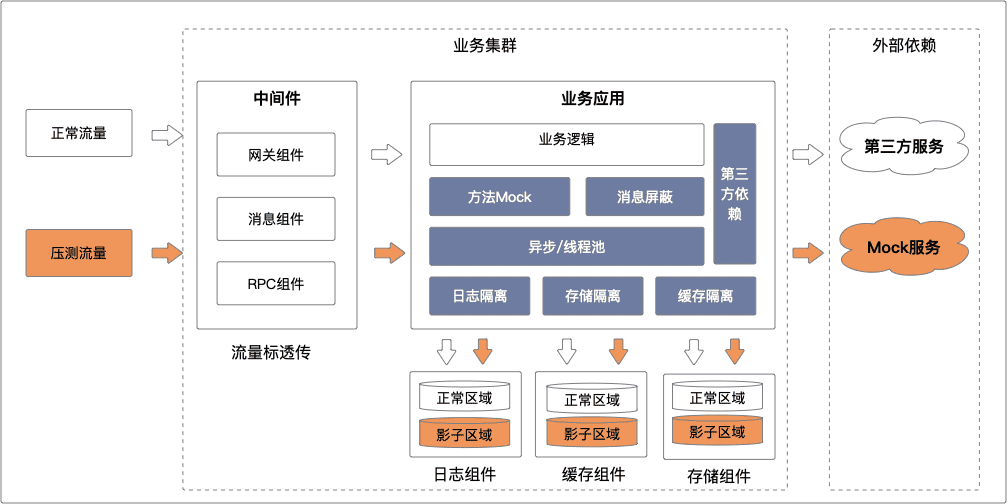
生产环境压测的三大前提:
- 压测标记不丢失
压测流量在任何环节能够被正确的识别出来。在流量入口层带上压测标,中间件识别并继续往下传递压测标,保证整条链路上压测标不丢失,通过这种方式使得下游的应用和存储也能接收到压测标。
- 压测流程不中断
压测流量能够正常的调用下去,整个流程不被阻断,返回符合预期的业务结果。业务的应用层,要支持全链路也需要进行对应的改造。应用层在识别到压测标时,需要绕过参数校验、安全校验等校验逻辑,例如手机号格式校验、用户状态校验、以及一些其它特殊业务校验逻辑。
- 压测数据不污染
压测数据不对线上正常的业务造成数据污染。全链路场景往往包含多个读写场景,为了隔离压测数据,存储中间件识别到压测标之后,将数据写入影子库表,与真实的数据区分开。为了更加真实的模拟真实场景,影子库表中的基础数据(例如买家、卖家、商品、店铺等)是由真实数据加上固定偏移量构造而成,迁移过程中会进行采样、过滤、脱敏等操作保证数据安全,一般在数据量级上和真实数据保持一致。
PTS探针已经具备以上三大能力,仅需在应用上部署好探针、配置好规则即可,无需改动业务代码。
本文示例的架构图升级方案如下:
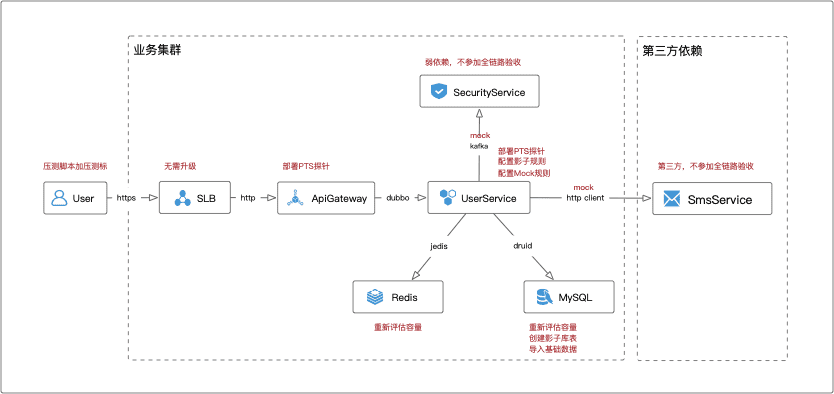
步骤六:正常流量联调
通常通过执行功能回归用例完成联调,是需要将正常回归流量打上流量标(例如在请求中添加Header x-pts-test=2),这样在查找调用链路时可以精准定位。该环节主要关注点如下:
- 验证探针对正常业务逻辑无影响,用例的测试结果均符合预期。
- 验证探针对依赖组件的适配情况,无遗漏的RPC调用、采集的数据准确无误;调用链完整性是全链路压测数据安全的核心。
- 将探针采集的调用链数据进行聚合(建议500+以上),抹平不同参数、不同逻辑分支带来的调用链差异性。使用聚合后的依赖拓扑图辅助梳理组件依赖可以极大程度的避免组件遗漏。
- 根据正常流量联调的结果,需要梳理出影子库表的范围、第三方服务的依赖情况。
步骤七:准备压测数据
压测业务模型对压测结果的准确性至关重要,而压测数据准备是业务模型落地的核心环节。压测数据主要包括基础数据和链路数据两种。
- 基础数据:包括业务运行所需的库表和数据,例如:买家、卖家、商品、优惠等,基础数据的规模一般需要与实际业务数据在量级上保持一致。
- 链路数据:包括需要压测的接口和多样化的接口参数集合,接口请求的参数集合是基于基础数据生成的。例如:商品详情页的接口为https://xxx.com/item?itemId=xxx,参数集合为具体的商品ID的集合。
基础数据的准备方式通常有直接构造和数据迁移两种:
- 直接构造:直接根据业务规则构造出来,一般用在少量数据的准备,例如联调阶段的数据构造。
- 数据迁移:对线上数据做清洗、采样、偏移后迁移到影子库表,数据完备性好,仿真度高,省时省力。建议使用DataX进行数据迁移。
数据准备环节,最核心的原则是需要保证镜像、影子库表的软硬件配置与正常库表一致,同时配置简单易行。这样可以保证在压测的时候充分暴露线上的数据库表的真实问题。
选择数据隔离策略有以下方式:
- 影子表隔离:在生产库建立业务表同结构的影子表,影子表名通常会在正常表名的基础上加上固定的前后缀。表级别的隔离在设计上允许复用一部分只读表,但是梳理难度有所增加。
- 影子库隔离:在用一个实例上创建与源数据库同配置的影子库,影子库名通常会在正常库名的基础上加上固定的前后缀,表名保持不变。库级别的隔离是数据源的隔离,隔离相对比较彻底、安全。
- 影子Key隔离:一般用在KV缓存、存储组件上(例如Redis),探针会拦截对KV缓存、存储组件的所有操作,根据流量标自动修改Key和过期时间,达到隔离数据和数据清理的目的。
其他存储组件的隔离原理基本上与上述三种思路上一致,您可以根据自身业务和架构特性,自行选择最佳的隔离方式。
步骤八:联调压测流量
- 根据步骤七:准备压测数据中梳理的库表情况,在控制台填写影子规则,不同规则需要填写的字段不尽相同。
- 根据步骤六:正常流量联调中梳理的第三方服务依赖情况在控制台配置Mock规则。如果需要使用复杂的动态响应结果,需要申请部署MockServer。
与正常流量联调的方式基本一致,联调过程中需要将压测流量打上流量标(例如在请求中添加Header x-pts-test=1),在查找调用链时可以精准定位。该环节主要关注点如下:
- 验证业务逻辑是否正常,用例的测试结果均需符合预期。此环节受基础数据影响比较大,容易出现某个字段不符合某些校验逻辑而导致业务进行不下去。
- 验证压测流量产生的调用链是否与正常流量一致,如果不一致需要相关人员介入排查原因。
- 验证影子隔离和Mock规则是否有效,如果有正式表存在测试数据写入或者影子表有正常数据写入,则需要相关人员介入排查原因。
步骤九:单链路小流量试压
开始全链路压测。不同的业务、压测目标往往对应不同的压测节奏和方法,不可一概而论。除了注意以下要点之外,还需根据业务、架构、人员等自身情况,制定不同的压测计划,在尽量避免线上故障的前提下,发现更多的线上问题。
- 制定明确的压测计划、压测通过标准,相关人员必须现场支持,分工明确,统一指挥。
- 线上压测应在业务低峰时段进行,并制定应急预案。
- 应当具备监控大盘,密切关注相关监控指标。
- 遵循循序渐进的原则,单链路压测>小流量验收>全链路验收。
对生产环境进行小流量试压,暴露最表层的问题,保证流程的正确性。
步骤十:单链路压测
验证所有接口在无干扰、无竞争的情况下的性能基线数据,确定所有接口的性能SLA。
步骤十一:全链路小流量试压
对生产环境进行小流量试压,暴露最表层的问题,保证流程的正确性。
步骤十二:全链路压测并验收
按生产环境流量配比进行复合场景全链路压测。探测相互干扰、竞争情况下的资源消耗水位和瓶颈。大致上分为以下5个阶段:

