



全链路压测核心技术解析
全链路压测核心技术解析
有价值的性能测试需要满足什么
1. 性能测试与性能分析要有明确的数据证明调优的效果。
性能测试人员/团队要有能力给运维一份性能测试报告+配置文档+风险说明。
2. 性能测试与性能分析的价值要体现在有效的节约成本中。
既测又调并且调得有效果,能直观反馈在成本数据上。
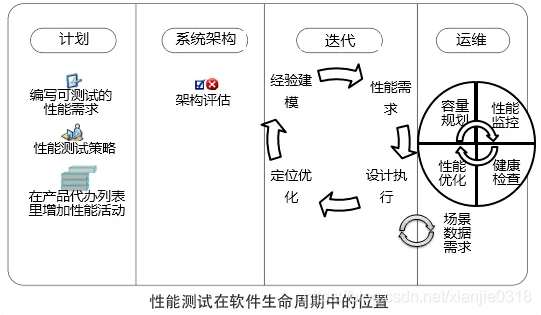
性能测试在软件生命周期中的位置
什么是全链路压测
基于实际的生产业务场景、系统环境,模拟海量的用户请求和数据对整个业务链进行压力测试(流量录制、回放、施压等),并持续调优。
全链路压测试用或解决的问题
全链路压测现在主要用于互联网电商领域如淘宝、京东、有赞、饿了么等等,业务场景越发复杂化、海量的业务数据以及集成系统越来越多、系统集群,因此需要在实际业务场景下考验整个业务系统链的承载能力、可用性、服务能力的瓶颈,预测服务承受压力、流量最大限制,把系统服务的最大价值发挥出来。
全链路压测执行过程和问题
1、业务模型分析
首先分析核心业务、非核心业务,得到业务流量高峰针对的哪些业务场景、模块,然后定位到相关的系统或服务节点,为更快的找到性能瓶颈进行系统优化。这部分工作一般由系统架构师和产品经理定位,然后由总压测负责人进行人员和资源协调;
2、协调压测所需的资源
在全链路压测过程中,最难的工作不是系统压测执行(压测环境搭建、脚本开发、压测执行、调优等),最难的是压测资源的协调工作,。业务越复杂相关系统涉及的越多,相关的人员、部门越多,这样协调的资源包含各部门技术人员、产品经理、系统资源以及架构师等调动起来很困难,需要上级老总进行总动员和授予总压测负责人权利调动。
3、压测环境、压测数据
一般分为三种,第一:单测试环境,按比例缩小搭建测试环境和测试数据脱敏生产;第二:模拟生产测试环境,按同比例搭建测试环境和测试数据脱敏生产;第三:直接使用生产环境进行压测;
第一种:压测风险最低,发现性能瓶颈有偏差较大、漏测较多;
第二种:压测风险低,浪费服务资源成本大,有一定的偏差;
第三种:压测风险大,真实性强,容易对实际业务有影响,性能瓶颈最容易确认;
压测数据考虑几点:
1、数据的真实性和可用性:
可以采用脱敏的生产真实数据作为基础数据,然后基于基础数据,通过分析历史数据增长趋势,预估可能的数据量;
2、数据隔离
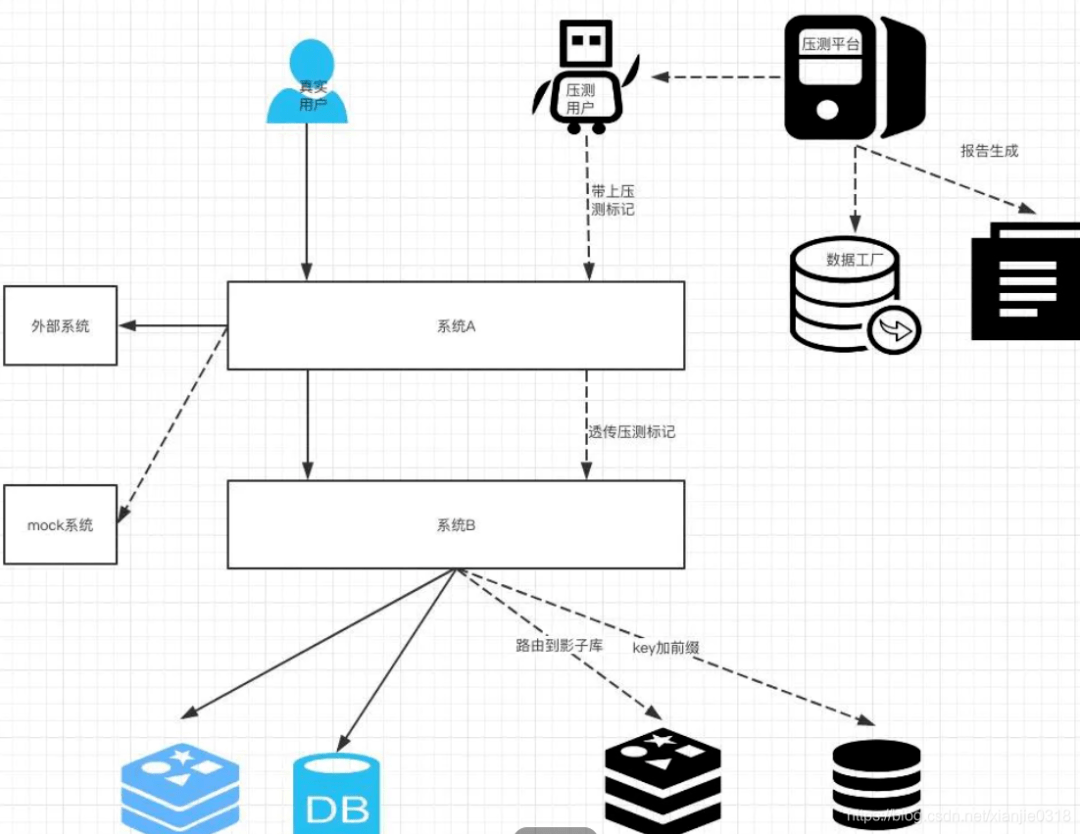
基于生产环境的全链路压测,必须考虑的一点是不能产生脏数据,以免对生产造成影响,影响用户体验等,
因此在数据准备时需要进行数据脱敏,同样为了避免造成脏数据写入,可以考虑通过压测数据隔离出来,落入影子库,mock对象等手段,来防止数据污染;
有赞的数据隔离实现
1)Proxy 访问代理隔离
针对业务方和数据存储服务间已有Proxy代理的情况,可以直接升级 Proxy 层,存储使用方完全无感知,无侵入,下面以 MySQL 为例,说明 Proxy 访问代理对于压测数据隔离的方案;
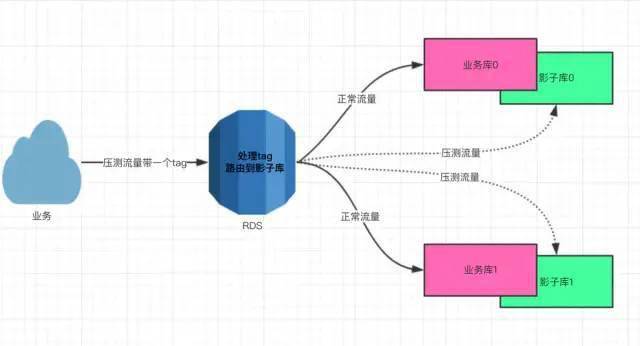
ElasticSearch、KV 对于压测的支持也是通过 Proxy 访问代理的方式实现的
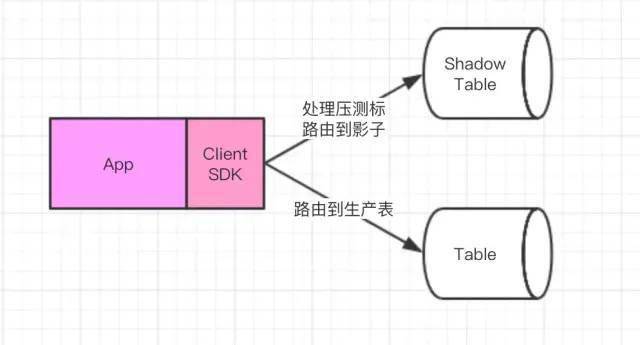
2 )客户端SDK隔离
压测工具选型
全链路压测应对的都是海量的用户请求冲击,可以使用分布式压测的手段来进行用户请求模拟,目前有很多的开源工具可以提供分布式压测的方式,比如jmeter、loadrunner、Ngrinder、locust等。
可以基于这些压测工具进行二次开发,由Contorller机器负责请求分发,agent机器进行压测,然后测试结果上传Contorller机器。
考虑到压测量较大的情况下回传测试结果会对agent本身造成一定资源占用,可以考虑异步上传,甚至事务补偿机制。
也有大公司会开发自己的全链路压测自动化平台,如阿里的PTS等
系统容量规划
在系统容量规划阶段,首先应该对单个接口单个服务进行基准测试,调整配置参数,得到一个基准线,然后进行分布式集群部署,通过nginx负载均衡。
至于扩容,要考虑到服务扩容和DB资源扩容,以及服务扩容带来的递减效应。
至于大流量冲击情况下,可以考虑队列等待、容器锁、长连接回调、事务降级等方式来解决。
测试集群部署
能做全链路压测的业务系统,基本都是分布式系统架构,服务集群部署和负载均衡,就是需要实现和考虑的技术点。
需要解决的问题有:
①、服务间通信问题
一般通信方式有两种:同步和异步。
同步调用:
REST(JAX-RS,Spring Boot)
RPC(Thrift, Dubbo)
异步调用:
(Kafka, Notify, MetaQ)
同步调用一致性强,但是要考虑性能和调用失败的事务处理。
异步调用的话,可以降低服务间的耦合,提升性能体验,但是一致性是需要解决的(分布式架构有个CAP理论,感兴趣的可以查询相关资料看看)。
②、负载均衡问题
需要将大流量冲击均匀的分发给集群上的每台机器,目前比较优秀的负载均衡服务器是nginx,但nginx的部署貌似也存在一些问题,我们公司之前就遇到过订单重复问题。
③、容灾问题
需要确保的一点是:当服务中的某台或者某部分服务宕机,可以及时的进行服务转发,而不至于连锁反应下整个系统链路的服务挂掉
数据监控
压测工具自带的监控功能,其他监控工具如Nmon、Zabbix,全链路监控工具Zipkin、PinPoint以及携程开源的全链路监控工具CAT。
对压测过程中各个系统的cpu、内存、磁盘io都进行系统层面的监控,同时也需要对各个业务节点的耗时进行监控,一方面从业务层面去监控压测事务性能,另一方面从系统层面监控,这样我们可以先从业务层面找到性能瓶颈,再单独分析各个系统的系统层面的瓶颈,最终找到优化方案。
压测执行
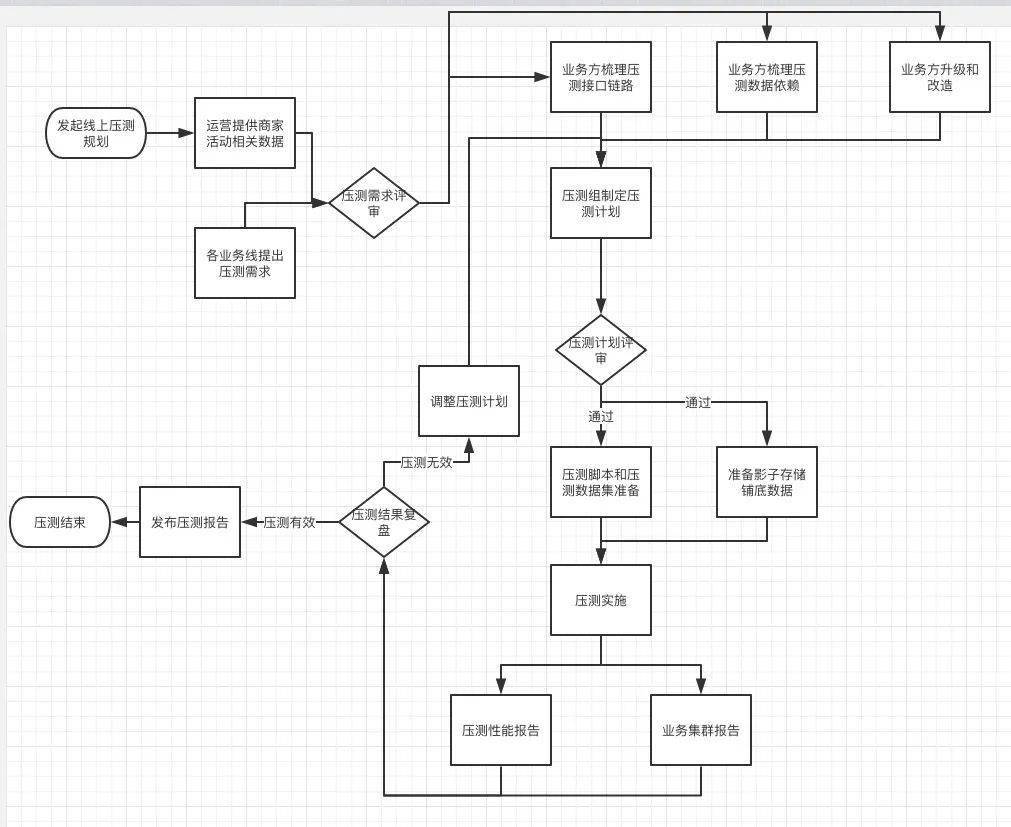
压测分析
整个压测优化过程就是一个不断优化不断改进的过程,通过长期的循序渐进的改进不断发现问题,优化系统,才能让系统的稳定性和性能都得到质的提升。

